参考书目:深入浅出Python量化交易实战
学量化肯定要用的上机器学习这种强大的预测技术。本次使用机器学习构建一些简单的预测进行量化交易,使用Python进行回测。
获取数据
import pandas as pd
import tushare as ts
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
import seaborn as sns#首先我们来定义一个函数,用来获取数据
#传入的三个参数分别是开始日期,结束日期和输出的文件名
def load_stock(start_date, end_date, output_file):
#首先让程序尝试读取已下载并保存的文件
try:
df = pd.read_pickle(output_file)
#如果文件已存在,则打印载入股票数据文件完毕
print('载入股票数据文件完毕')
#如果没有找到文件,则重新进行下载
except FileNotFoundError:
print('文件未找到,重新下载中')
#这里制定下载中国平安(601318)的交易数据
#下载源为yahoo
df = ts.get_k_data('601318', start_date, end_date)
df = df.set_index('date')
#下载成功后保存为pickle文件
df.to_pickle(output_file)
#并通知我们下载完成
print('下载完成')
#最后将下载的数据表进行返回
return df #下面使用我们定义好的函数来获取中国平安的交易数据
#获取三年的数据,从2017年3月9日至2022年的12月25日
#保存为名为601318的pickle文件
zgpa = load_stock(start_date = '2017-03-09',
end_date = '2022-12-25',
output_file = '601318.pkl')查看数据前五行
zgpa.head()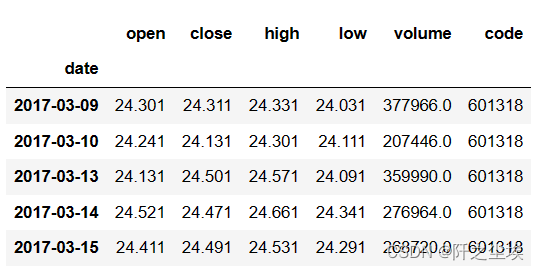
特征构建
#下面我们来定义一个用于分类的函数,给数据表增加三个字段
#首先是开盘价减收盘价,命名为‘Open-Close’
#其次是最高价减最低价,命名为‘High-Low’
def classification_tc(df):
df['Open-Close'] = df['open'] - df['close']
df['High-Low'] = df['high'] - df['low']
#在添加一个target字段,如果次日收盘价高于当日收盘价,则标记为1,反之为0
df['target'] = np.where(df['close'].shift(-1)>df['close'], 1, 0)
#去掉有空值的行
df = df.dropna()
#将‘Open-Close’和‘High-Low’作为数据集的特征
X = df[['Open-Close', 'High-Low']]
#将target赋值给y
y = df['target']
#将处理好的数据表以及X与y进行返回
return(df,X,y)#下面定义一个用于回归的函数
#特征的添加和分类函数类似
#只不过target字段改为次日收盘价减去当日收盘价
#下面定义一个用于回归的函数
#特征的添加和分类函数类似
#只不过target字段改为次日收盘价减去当日收盘价
def regression_tc(df):
df['Open-Close'] = df['open'] - df['close']
df['High-Low'] = df['high'] - df['low']
df['target'] = df['close'].shift(-1) - df['close']
df = df.dropna()
X = df[['Open-Close', 'High-Low']]
y = df['target']
#将处理好的数据表以及X与y进行返回
return(df,X,y)#使用classification_tc函数生成数据集的特征与目标
from sklearn.model_selection import train_test_split
df, X, y = classification_tc(zgpa)
#将数据集拆分为训练集与验证集
X_train, X_test, y_train, y_test =\
train_test_split(X, y, shuffle=False,train_size=0.8)shuffle=False表示安装顺序进行划分,因为股市具有时间性,只能用前面的数据训练后面的数据。
查看数据:
df.head()
这就构建 了一个用于分类的数据,target为响应变量,表示明天股票表示涨或者跌。可以用机器学习的模型去预测准确率。
机器学习建模
采用十分钟常见的机器学习分类算法进行准确率对比
from sklearn.linear_model import LogisticRegression
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost.sklearn import XGBClassifier
from sklearn.svm import SVC
from sklearn.neural_network import MLPClassifier#逻辑回归
model1 = LogisticRegression(C=1e10)
#线性判别分析
model2 = LinearDiscriminantAnalysis()
#K近邻
model3 = KNeighborsClassifier(n_neighbors=50)
#决策树
model4 = DecisionTreeClassifier(random_state=77)
#随机森林
model5= RandomForestClassifier(n_estimators=1000, max_features='sqrt',random_state=10)
#梯度提升
model6 = GradientBoostingClassifier(random_state=123)
#极端梯度提升
model7 = XGBClassifier(eval_metric=['logloss','auc','error'],n_estimators=1000,use_label_encoder=False,
colsample_bytree=0.8,learning_rate=0.1,random_state=77)
#支持向量机
model8 = SVC(kernel="rbf", random_state=77)
#神经网络
model9 = MLPClassifier(hidden_layer_sizes=(16,8), random_state=77, max_iter=10000)
model_list=[model1,model2,model3,model4,model5,model6,model7,model8,model9]
model_name=['逻辑回归','线性判别','K近邻','决策树','随机森林','梯度提升','极端梯度提升','支持向量机','神经网络']训练测试他们
for i in range(9):
model_C=model_list[i]
name=model_name[i]
model_C.fit(X_train, y_train)
s=model_C.score(X_test, y_test)
print(name+'方法在验证集的准确率为:'+str(s))
可以看到XGboost 的准确率最高,下面使用XG进行训练和预测。
#使用XGboost模型预测每日股票的涨跌,保存为‘Predict_Signal’,将0映射为-1,方便很后面的收益计算。
model7.fit(X_train, y_train)
df['Predict_Signal'] =model7.predict(X)
df['Predict_Signal']=df['Predict_Signal'].map({0:-1,1:1})
#在数据集中添加一个字段,用当日收盘价除以前一日收盘价,并取其自然对数
df['Return'] = np.log(df['close']/df['close'].shift(1))
#查看一下
df.head()
#定义一个计算累计回报的函数
def cum_return(df, split_value):
#该股票基准收益为‘Return’的总和*100
cum_return = df[split_value:]['Return'].cumsum()*100
#将计算结果进行返回
return cum_return#再定义一个计算使用策略交易的收益
def strategy_return(df, split_value):
#使用策略交易的收益为模型‘zgpa_Return’乘以模型预测的涨跌幅
df['Strategy_Return'] = df['Return']*df['Predict_Signal'].shift(1)
#将每日策略交易的收益加和并乘以100
cum_strategy_return = df[split_value:]['Strategy_Return'].cumsum()*100
#将计算结果进行返回
return cum_strategy_return#定义一个绘图函数,用来对比基准收益和算法交易的收益
def plot_chart(cum_returns, cum_strategy_return, symbol):
#首先是定义画布的尺寸
plt.figure(figsize=(9,6))
#使用折线图绘制基准收益
plt.plot(cum_returns, '--',label='%s Returns'%symbol)
#使用折线图绘制算法交易收益
plt.plot(cum_strategy_return, label = 'Strategy Returns')
#添加图注
plt.legend()
plt.xticks(np.arange(0,286,36),rotation=20)
#显示图像
plt.show()计算并且画图
#首先来计算基准收益(预测集)
cum_returns = cum_return(df, split_value=len(X_train))
#然后是计算使用算法交易带来的收益(同样只计算预测集)
cum_strategy_return = strategy_return(df, split_value=len(X_train))
#用图像来进行对比
plot_chart(cum_returns, cum_strategy_return, 'zgpa')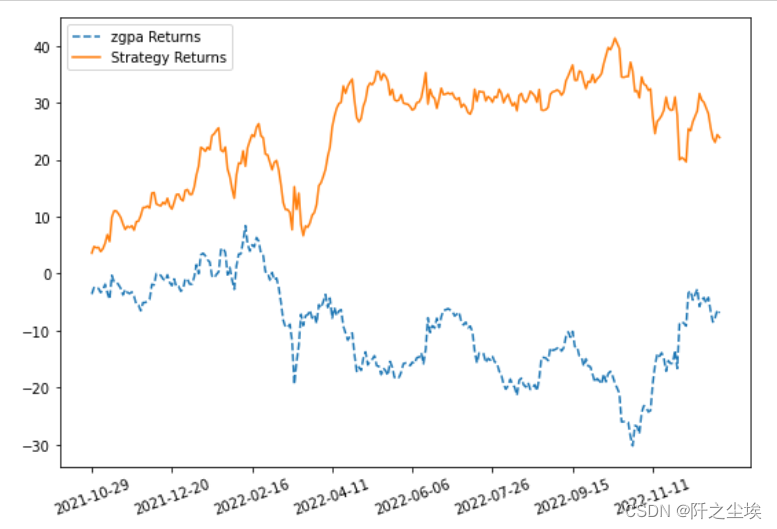
可以看到策略收益还是高不少。
虽然其预测的准确率只有53%,但是作为股市预测,已经让你的胜率从50%上升了3个点已经是很难得了,就可以从随机的买卖变成了一个大概率赚钱的策略。
当然选取更多的特征变量效果说不定会更好。