一、说明
在本文中,我们将讨论以下主题:1为什么文本预处理很重要?2 文本预处理技术。这个文对预处理做一个完整化、程序化处理,这对NLP处理项目中有很大参考性。
二、为什么文本预处理很重要?
数据质量显着影响机器学习模型的性能。数据不足或质量低下可能会导致模型的准确性和有效性降低。
一般来说,源自自然语言的文本数据是非结构化的且有噪声。因此,文本预处理是将杂乱的非结构化文本数据转换为可有效用于训练机器学习模型的形式的关键步骤,从而获得更好的结果和见解。
三、文本预处理技术
3.1 预处理流程
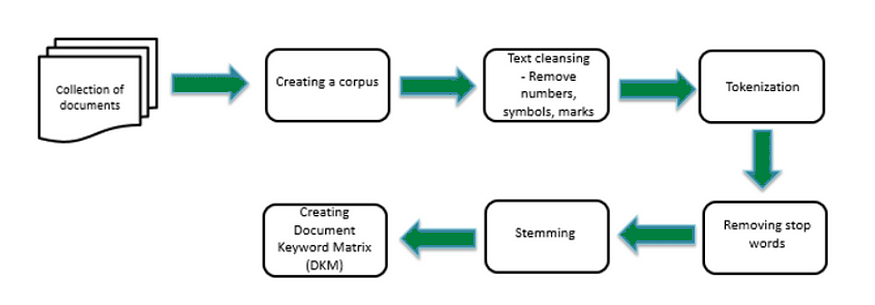
文本预处理是指用于将原始文本数据清理、转换和准备为适合 NLP 或 ML 任务的格式的一系列技术。文本预处理的目标是提高文本数据的质量和可用性,以供后续分析或建模。
文本预处理通常涉及以下步骤:
- 小写
- 删除标点符号和特殊字符
- 停用词删除
- 删除 URL
- 删除 HTML 标签
- 词干提取和词形还原
- 代币化
- 文本规范化
NLP 系统通常使用部分或全部这些文本预处理技术。应用这些技术的顺序可能会根据项目的需要而有所不同。
让我们按顺序解释一下文本预处理技术。
3.2 Lowercasing
Lowercasing 是一个文本预处理步骤,将文本中的所有字母转换为小写。执行此步骤是为了使算法不会在不同情况下对相同的单词进行不同的处理。
text = "Hello WorlD!"
lowercased_text = text.lower()
print(lowercased_text)Output:
hello world!3.3 删除标点符号和特殊字符
标点符号删除是一个文本预处理步骤,您可以从文本中删除所有标点符号(例如句号、逗号、感叹号、表情符号等)以简化文本并专注于单词本身。
import re
text = "Hello, world! This is?* 💜an&/|~^+%'\" example- of text preprocessing."
punctuation_pattern = r'[^\w\s]'
text_cleaned = re.sub(punctuation_pattern, '', text)
print(text_cleaned)Output:
Hello world This is an example of text preprocessing3.4 停用词删除
停用词是对句子的含义没有贡献的词。因此,可以将它们删除而不会导致句子含义发生任何变化。NLTK 库有一组停用词,我们可以使用它们从文本中删除停用词并返回单词标记列表。删除这些可以帮助您专注于重要的单词。
from nltk.corpus import stopwords
# remove english stopwords function
def remove_stopwords(text, language):
stop_words = set(stopwords.words(language))
word_tokens = text.split()
filtered_text = [word for word in word_tokens if word not in stop_words]
print(language)
print(filtered_text)
en_text = "This is a sample sentence and we are going to remove the stopwords from this"
remove_stopwords(en_text, "english")
tr_text = "bu cümledeki engellenen kelimeleri kaldıracağız"
remove_stopwords(tr_text, "turkish")english
['This', 'sample', 'sentence', 'going', 'remove', 'stopwords']
turkish
['cümledeki', 'engellenen', 'kelimeleri', 'kaldıracağız']如果仔细检查输出,您会注意到在第一句中,单词“this”被删除,但“This”未被删除。因此,在应用此步骤之前,有必要将句子转换为小写并删除标点符号。
3.5 删除 URL
此预处理步骤是删除数据中存在的任何 URL。
def remove_urls(text):
url_pattern = re.compile(r'https?://\S+|www\.\S+')
return url_pattern.sub(r'', text)
text = "I hope it will be a useful article for you. Follow me: https://medium.com/@ayselaydin"
remove_urls(text)Output:
I hope it will be a useful article for you. Follow me: 3.6 删除 HTML 标签
删除 HTML 标签是一个文本预处理步骤,用于清除 HTML 文档中的文本数据。当处理从网页或其他 HTML 格式源获取的文本数据时,文本可能包含 HTML 标签,这对于文本分析或机器学习模型来说是不可取的。因此,从文本数据中删除 HTML 标签非常重要。
import re
text = """<html><div>
<h1>Aysel Aydin</h1>
<p>Text Preprocessing for NLP</p>
<a href="https://medium.com/@ayselaydin">Medium account</a>
</div></html>"""
html_tags_pattern = r'<.*?>'
text_without_html_tags = re.sub(html_tags_pattern, '', text)
print(text_without_html_tags)Output:
Aysel Aydin
Text Preprocessing for NLP
Medium account四、结论
这些只是自然语言处理的一些技术。一旦使用这些方法从非结构化文本中提取信息,就可以直接在聚类练习和机器学习模型中使用或使用它,以提高其准确性和性能。