文章目录
- 概念
- 计算图
- 自动求导的两种模式
- 自动求导-代码
- 标量的反向传播
- 非标量变量的反向传播
- 将某些计算移动到计算图之外
概念
核心:链式法则

深度学习框架通过自动计算导数(自动微分)来加快求导。
实践中,根据涉及号的模型,系统会构建一个计算图,来跟踪计算是哪些数据通过哪些操作组合起来产生输出。
自动微分使系统能够随后反向传播梯度。
反向传播:跟踪整个计算图,填充关于每个参数的偏导数。
计算图
- 将代码分解成操作子,将计算表示成一个无环图
- 将计算表示成一个无环图、
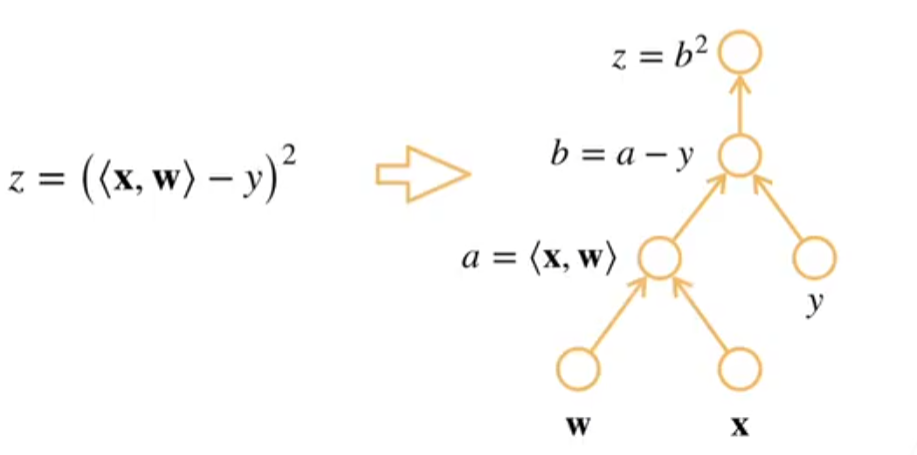
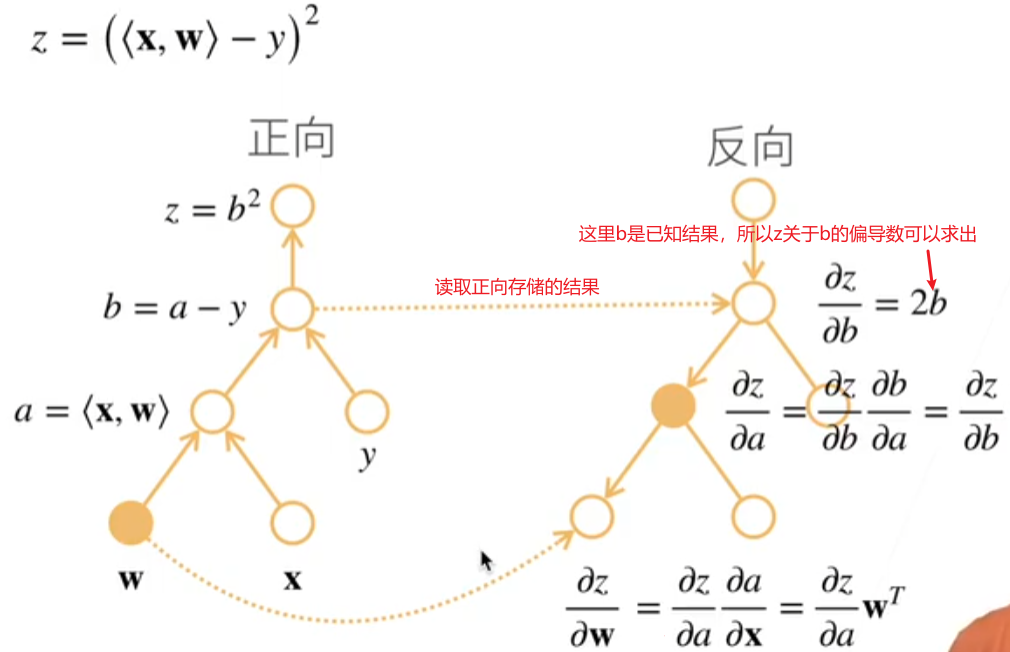
自动求导的两种模式

反向传播
- 构造计算图
- 前向:执行图,存储中间结果
- 反向:从相反方向执行图 - 不需要的枝可以减去,比如正向里的x和y连接的那个枝
自动求导-代码
标量的反向传播
案例:假设对函数 y = 2 x T x y=2x^Tx y=2xTx关于列向量x求导
1.首先初始化一个向量
x = torch.arange(4.0) # 创建变量x并为其分配初始值
print(x) #tensor([0., 1., 2., 3.])
2.计算y关于x的梯度之前,需要一个地方来存储梯度。
x.requires_grad_()等价于x=torch.arange(4.0,requires_grad=True),这样PyTorch会跟踪x的梯度,并生成grad属性,该属性里记录梯度。
通常用于表示某个变量或返回值“有意为空”或"暂时没有值",已经初始化但是没有值
x.requires_grad_(True)
print(x.grad) # 默认值是None,存储导数。
3.计算y的值,y是一个标量,在python中表示为tensor(28., ),并记录是通过某种乘法操作生成的。
y = 2 * torch.dot(x, x)
print(y) # tensor(28., grad_fn=<MulBackward0>)
4.调用反向传播函数来自动计算y关于x每个分量的梯度。
y.backward()
print(x.grad) # tensor([ 0., 4., 8., 12.])
我们可以知道根据公式来算, y = 2 x T x y=2x^Tx y=2xTx关于列向量x求导的结果是4x,根据打印结果来看结果是正确的。
5.假设此时我们需要继续计算x所有分量的和,也就是 y = x . s u m ( ) y=x.sum() y=x.sum()
在默认情况下,PyTorch会累计梯度,我们需要调用grad.zero_清空之前的值。
x.grad.zero_()
y = x.sum() # y = x₁ + x₂ + x₃ + x₄
print(y)
y.backward()
print(x.grad) # tensor([1., 1., 1., 1.])
非标量变量的反向传播
在深度学习中,大部分时候目的是 将批次的损失求和之后(标量)再对分量求导。
y.sum()将 y的所有元素相加,得到一个标量 s u m ( y ) = ∑ i = 1 n x i 2 sum(y)=\sum_{i=1}^n x_i^2 sum(y)=∑i=1nxi2
y.sum().backward()等价于y.backward(torch.ones(len(x)):
x.grad.zero_()
y = x * x # y是一个矩阵
print(y) # tensor([0., 1., 4., 9.], grad_fn=<MulBackward0>) 4*1的矩阵
# 等价于y.backward(torch.ones(len(x)))
y.sum().backward()
print(x.grad) # [0., 2., 4., 6.]
将某些计算移动到计算图之外
假设 y = f ( x ) , z = g ( y , x ) y=f(x),z=g(y,x) y=f(x),z=g(y,x),我们需要计算 z z z关于 x x x的梯度,正常反向传播时,梯度会通过 y y y和 x x x 两条路径传播到 x x x: ∂ z ∂ x = ∂ g ∂ y ∂ y ∂ x + ∂ g ∂ x \frac{\partial z}{\partial x} = \frac{\partial g}{\partial y} \frac{\partial y}{\partial x} +\frac{\partial g}{\partial x} ∂x∂z=∂y∂g∂x∂y+∂x∂g。但由于某种原因,希望将 y y y视为一个常数,忽略 y y y对 x x x的依赖: ∂ z ∂ x ∣ y 常数 = ∂ g ∂ x \frac{\partial z}{\partial x} |_{y常数} =\frac{\partial g}{\partial x} ∂x∂z∣y常数=∂x∂g。
通过 detach() 方法将 y y y从计算图中分离,使其不参与梯度计算。
z . s u m ( ) 求导 = ∂ ∑ z i ∂ x i = u i z.sum() 求导 = \frac{\partial \sum z_i}{\partial x_i} = u_i z.sum()求导=∂xi∂∑zi=ui
x.grad.zero_()
y = x * x
print(y) # tensor([0., 1., 4., 9.], grad_fn=<MulBackward0>)
u = y.detach() # 把y看成一个常数从计算图中分离,不参与梯度计算,但值还是x*x
print(u) # tensor([0., 1., 4., 9.])
z = u * x # z是一个常数*x
print(z) # tensor([ 0., 1., 8., 27.], grad_fn=<MulBackward0>)
z.sum().backward()
print(x.grad == u) # tensor([True,True,true,True])
执行y.detach()返回一个计算图之外,但值同y一样的tensor,只是将函数z中的y替换成了这个等价变量。
但对于y本身来说还是一个在该计算图中,就可以在y上调用反向传播函数,得到 y = x ∗ x y=x*x y=x∗x关于 x x x的导数 2 x 2x 2x
x.grad.zero_()
y.sum().backward()
print(x.grad == 2 * x) # tensor([True,True,true,True])