目录
一、函数调用运算符与function类模板
1.函数调用运算符
(1)函数类型
(2)可调用对象
2.function类模板
二、万能引用类型
1.万能引用
2.万能引用资格的剥夺与辨认
(1)const修饰词
(2)类模板成员函数
三、引用折叠
1.编译器合并&的规则
四、std::forward及std::move
1.完美转发std::forward
2.std::move VS std::forward
五、auto类型
1.auto的特点
2.auto类型推断
(1)传值方式(非指针,非引用)
(2)指针或者引用类型但不是万能引用
(3)万能引用类型
3.auto类型std::initializer_list的特殊推断
六、decltype
七、std::function & std::bind
1.详细记录
2.简单说明
八、lambda表达式
1.lambda表达式的特点
2.格式说明
3.捕获列表说明
一、函数调用运算符与function类模板
1.函数调用运算符
函数调用总离不开一对圆括号,“()”就是函数调用的一个明显标记,这个“()”有一个称呼叫函数调用运算符。
int Add(int value)
{
return value + 1;
}如果在类中重载了这个函数调用运算符“()”,就可以像使用函数一样使用该类的对象,或者换句话说就可以像函数调用一样来“调用”该类的对象。写出来这个函数调用运算符后,怎样使用呢?分两步使用即可:
(1)定义一个该类的对象。
(2)像函数调用一样使用该对象,也就是在“()”中增加实参列表。
class TestOperator {
public:
int operator()(int value) const //重载函数调用运算符
{
return value + 1;
}
};
void main()
{
TestOperator test;
std::cout << test(5) << std::endl; //6
}Add函数以及TestOperator类中重载的函数调用运算符,它们的形参和返回值是相同的,这就叫作“调用形式相同” 。
一种调用形式对应一个函数类型,所以因为Add函数以及TestOperator类中重载的函数调用运算符调用形式相同,所以它们函数类型相同。
(1)函数类型
int(int)上面这行代表一个“函数类型”:接收一个int参数,返回一个int值。
(2)可调用对象
“可调用对象”这个概念(“函数对象”“仿函数”都是同一个意思),那么如下两个都是可调用对象:
- Add函数。
- 重载了函数调用运算符“()”的TestOperator类所生成的对象。
2.function类模板
C++11中,标准库里有一个叫作function的类模板,这个类模板是用来包装一个可调用对象的。要使用这个类模板,当然是要提供相应的模板参数,这个模板参数就是指该function类型能够表示(包装)的可调用对象的调用形式:
function<int(int)>上面这种写法是一个类类型(类名就是function<int(int)>),用来代表(包装)一个可调用对象,它所代表的这个可调用对象接收一个int参数,返回一个int值。
如果上面的Add函数有一个重载,那么就无法包装进function中。这也是一个二义性导致的问题,那么这个问题怎样解决?可以通过定义一个函数指针来解决,因为函数指针中含有参数类型和返回类型。
int Add(int value)
{
return value + 1;
}
int Add(int value1,int value2)
{
return value1 + value2;
}
void main()
{
int(*p)(int)= Add; //定义一个函数指针p,不会产生二义性。因为函数指针中含有参数类型和返回类型。
std::function<int(int)> fun = p;
std::cout << fun(5) << std::endl; //6
int(*p1)(int,int)= Add;
std::function<int(int,int)> fun1 = p1;
std::cout << fun1(5,6) << std::endl; //11
}二、万能引用类型
universal reference(后来被称为forwarding reference:转发引用)翻译成中文有好几种翻译方法,取两种最常见的翻译,一种叫“万能引用”,一种叫“未定义引用”,都是一个意思,后续就称为“万能引用”了。
1.万能引用
万能引用是一种类型。就跟int是一种类型一个道理,再次强调,万能引用是一种类型。
万能引用(又名未定义引用,英文名universal reference)离不开两种语境,这两种语境必须同时存在:
- 必须是函数模板。
- 必须是发生了模板类型推断并且函数模板形参长这样:T&&。
void Test(int&& data) //形参是一个右值引用,实参需要一个右值
{
std::cout << data << std::endl;
}
void main()
{
int i = 10;
Test(i);//错误,i是左值,而参数需要一个右值
}template <typename T>
void Test(T&& data) //T&&万能引用,参数既可以支持左值,也可以是右值
{
std::cout << data << std::endl;
}
void main()
{
int i = 10;
Test(i); //正确
}万能引用就长这样:T&&(T必须与&&挨着)。它也用两个地址符号“&&”表示,所以万能引用长得跟右值引用一模一样。但是解释起来却不一样(注意语境,只有在语境满足的条件下,才能把“&&”往万能引用而不是往右值引用解释):
(1)右值引用作为函数形参时,实参必须传递右值进去,不然编译器报错,上面已经看到了。
(2)而万能引用作为函数形参时,实参可以传递左值进去,也可以传递右值进去。所以,万能引用也被人叫作未定义引用。如果传递左值进去,那么这个万能引用就是一个左值引用;如果传递右值进去,那么这个万能引用就是一个右值引用。从这个角度来讲,万能引用更厉害:是一种中性的引用,可以摇身一变,变成左值引用,也可以摇身一变,变成右值引用。
T&&才是万能引用,千万不要理解成T是万能引用,其实,data的类型是T&&,所以data的类型才是万能引用类型(或者理解成data才是万能引用),这意味着如果传递一个整型左值进去,data的类型最终就应该被推断成int&类型;如果传递一个整型右值进去,data最终就应该被推断成int&&类型。
下面的两种情况才是万能引用,其他的看到的“&&”的情况都是右值引用:
- 一个是函数模板中用作函数参数的类型推断(参数中要涉及类型推断),形如T&&。
- auto&& tmpvalue=…也是一个万能引用。
2.万能引用资格的剥夺与辨认
(1)const修饰词
const修饰词会剥夺一个引用成为万能引用的资格,被打回原形成右值引用。T&&前后左右都不要加什么修饰符,不然很可能就不是万能引用而直接退化为右值引用了。
template <typename T>
void Test1(const T&& data) //const修饰词会剥夺一个引用成为万能引用的资格,被打回原形成为右值引用。
{
std::cout << data << std::endl;
}
void main()
{
int i = 10;
Test1(i);//错误,i是左值,而参数需要一个右值
}(2)类模板成员函数
如下方代码Test3后面的T&&不是一个万能引用,而是一个右值引用。因为Test3成员函数本身没有涉及类型推断,Test3成员函数是类模板TEST的一部分。
template <typename T>
class TEST {
public:
void Test3(T&& data)//T&&不是万能引用,实参需要一个右值
{
std::cout << data << std::endl;
}
};如果搞不清楚形参类型是否是一个万能引用,则分别传递进去一个左值和一个右值作为实参来调用,就可以验证。
三、引用折叠
引用折叠是一个C++11新标准里出现的概念,同时也是一条规则,英文名字是reference-collapsing rules(引用折叠规则),有人也翻译成引用坍塌,都是一个意思。想一想,“折叠”这个词,从字面分析,就是给鼓捣没一些东西或者折起来一些东西,这里三个&就给鼓捣剩1个了,这就是引用折叠规则的体现。
在C++中,有明确含义的“引用”只有两种,一种是带一个&的左值引用,一种是带两个&&的右值引用。但是,此时此刻竟然出来三个&(&&&),并且这三个&应该是第一个一组,后两个一组,也就是& &&这种感觉。
第一组是一个左值引用,第二组因为已经实例化过了,所以第二组的两个&&就不可能再是万能引用了,所以第二组的两个&&实际是右值引用。现在编译器遇到超过两个&了,第一组一个&,第二组两个&&,编译器就会把超出两个的&合并,实际上合并的原因不仅仅是因为超过两个&,只要是左值之间相遇、左值和右值相遇、右值之间相遇,以及右值和左值相遇,系统都会进行&符号的合并,合并后的&数量肯定比合并之前少,所以才叫“折叠”嘛!
写程序的时候不能写出三个&&&,否则是语法错误。
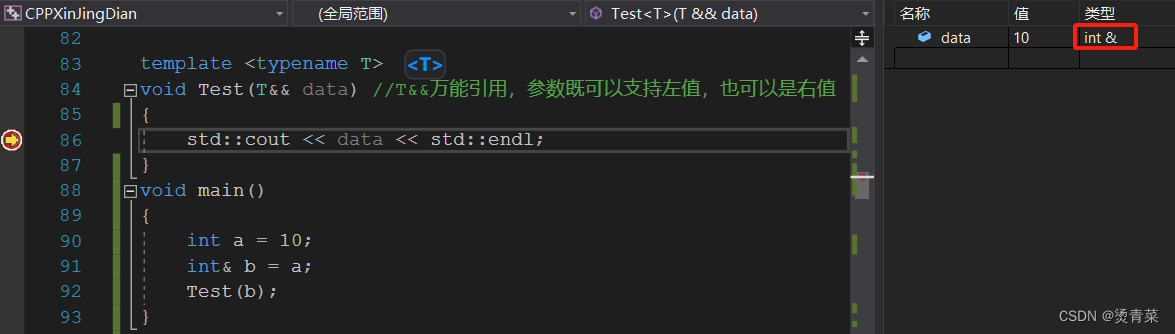
template <typename T>
void Test(T&& data) //T&&万能引用,参数既可以支持左值,也可以是右值
{
std::cout << data << std::endl;
}
void main()
{
int a = 10;
int& b = a;
Test(b);
}
1.编译器合并&的规则
左值引用是一个&表示,右值引用是两个&&表示,如果任意一个引用为左值引用,结果就为左值引用(左值引用会传染),否则结果为右值引用。所以这两种引用组合一下就会有四种可能的组合:
- 左值&-左值&:左值引用&
- 左值&-右值&&(这是上面范例当前的情形):左值引用&
- 右值&&-左值&:左值引用&
- 右值&&-右值&&:右值引用&&
四、std::forward及std::move
注意:形参总是左值,即使其类型是右值引用。如下代码:num是一个左值,但它的类型是右值引用。
void Function(int&& num)
{
}对于一个变量:
- 如果从左值还是右值这个概念/角度来讲,它要么是左值,要么是右值,不可能是其他东西。当这个变量作为实参传递给某个函数的形参时,如果这个变量是左值,那么这个函数的形参必须得是一个左值引用;如果这个变量是右值,那么这个函数的形参必须得是一个右值引用。否则就会报语法错。
- 如果从类型这个概念/角度来讲,它要么是一个左值引用,要么是一个右值引用(万能引用不算,因为万能引用只出现在类型推导中,不在讨论范围之内)。它到底是左值引用还是右值引用,看它是怎样定义的。如果它这样定义:“int &ta …;”,显然,ta是一个左值引用,如果它这样定义:“int &&ta…;”,显然,ta是一个右值引用。所以左值引用只能绑到一个左值上去(例如左值引用作函数形参时,实参只能是左值),右值引用只能绑到一个右值上去(例如右值引用作函数形参时,实参只能是右值)。
template <typename F,typename T1,typename T2>
void Test(F fun,T1&& data1,T2&& data2) //data1和data2都是万能引用类型,那么从实参中来的左值或者右值信息、const信息就都会保存在data1和data2参数中
{
//fun(data1, data2);//报错 无法将参数 1 从“T1”转换为“int &&” ,因为data1和data2都是左值,而Function的第一个参数需要一个右值
fun(std::forward<T1>(data1), std::forward<T2>(data2));
}
void Function(int&& num1, int& num2) //第一个参数需要右值,第二个参数需要左值;num1的类型是右值引用,但num1本身是左值 ;右值引用作函数形参时,实参只能是右值
{
std::cout << num1<<","<<num2 << std::endl;
}
void main()
{
int num2 = 20;
Test(Function,10, num2); //10是右值,num是左值
}有个实参是一个值(10),传递到一个函数模板(Test)中之后,这个模板中有个形参(data1),专门接这个右值,所以这个形参是一个右值引用,但是这个形参本身是一个左值。试想,原来是一个右值,接收到后变成了左值,那如果另外一个函数(Function的num1参数)正好需要一个右值绑定过来,那就得把这个左值再变回右值去,这就用到std::forward函数。
注意:万能引用中,给一个int类型的左值,T推导出来的类型为int &;给一个int类型的右值,T推导出来的类型为int。即:T1是int类型,T2是int&类型。当T推导为int &类型时还发生了引用折叠。
1.完美转发std::forward
完美转发比较好地解决了参数转发的问题,通过一个函数模板,可以把任意的函数名、任意类型参数(只要参数个数是确定的)传递给这个函数模板,从而达到间接调用任意函数的目的。std::forward的能力就是保持原始实参的左值或者右值性。
对这个函数有两种理解:
- 实参原来是一个左值(j),到了形参中还是左值(data2)。forward能够转化回原来该实参的左值或者右值性,所以std::forward之后还是一个左值。
- 实参原来是一个右值(10),到了形参中变成了左值(data1)。forward能够转化回原来该实参的左值或者右值性,所以std::forward之后还是一个右值。
所以,从现在的情形看,forward有强制把左值转成右值的能力。所以,看起来std::forward这个函数只对原来是一个右值这种情况有用。
回顾上述代码:“Test(Function,10, num2);”,这里的10本来是一个右值,到了void Test(F fun,T1&& data1,T2&& data2)里面去之后,向Funciton转发的时候“fun(data1, data2);”中的data1变成了一个左值,是std::forward使它恢复了右值身份:std::forward<T1>(data1),所以这里可以把forward看成是强制把一个左值转换成了一个右值。
std::forward就是通过“<>”里面的类型决定把变量转成左值还是右值,当forward的尖括号里是int时,表示转成右值;当forward的尖括号里是int&,表示转成左值。
2.std::move VS std::forward
- std::move是属于无条件强制转换成右值(如果原来是左值,就强制转成右值;如果原来是右值,那就最好,保持右值不变)。std::forward是某种条件下执行强制转换。例如原来是右值,因为某些原因(如参数传递)被折腾成左值了,此时forward能转换回原来的类型(右值);如果原来是左值,那forward就什么也不干。
- std::forward总感觉用起来方便性不够,因为既得为其提供一个模板类型参数,又要提供一个普通参数。而std::move只需要一个普通参数,不需要模板类型参数。
- 从具体书写代码的角度谈:
- std::move后面往往是接一个左值,std::move是把这个左值转成右值,转成右值的目的通常都是做对象移动(所以这个对象应该支持移动,前面讲过移动构造函数)的操作。不然平白无故地转成右值也没多大意义。
- std::forward往往是用于参数转发,所以不难发现,std::forward后面圆括号中的内容往往都是一个万能引用(如std::forward<T>(t)中的t就是一个万能引用)。
五、auto类型
1.auto的特点
- auto的自动类型推断发生在编译期间。
- auto定义变量必须立即初始化,这样编译器才能推断出它的实际类型。编译的时候才能确定auto的类型和整个变量的类型,然后在编译期间就可以用真正的类型替换掉auto这个类型占位符。
- auto的使用比较灵活,可以和指针、引用、const等限定符结合使用。
- auto不能用于函数参数,如void myfunc(auto x,inty)不可以。
- 非静态数据成员不能具有包含auto的类型。静态数据成员可以使用auto。
2.auto类型推断
(1)传值方式(非指针,非引用)
传值方式针对auto类型:会抛弃引用、const等限定符。
auto num = 10; //num为int类型
const auto num1 = num; //num1为const int类型
auto num2 = num1; //num2为int类型,会抛弃const限定符
const auto& num3 = num; //不属于传值方式。num3为const int&类型
auto num4 = num3; //属于传值方式。num4为int类型,会抛弃引用、const等限定符(2)指针或者引用类型但不是万能引用
指针或者引用方式针对auto类型:不会抛弃const限定符,但是会抛弃引用。
auto num = 10; //num为int类型
auto &num1 = num; //num1为int&类型
const auto* num2 = # //num2为const int*类型
auto num3 = num2; //num3为const int*类型
auto* num4 = &num1; //num3为int*类型,会抛弃引用限定符(3)万能引用类型
和万能引用模板推理类似:给一个int类型的左值,auto推导出来的类型为int &;给一个int类型的右值,auto推导出来的类型为int。
3.auto类型std::initializer_list的特殊推断
std::initializer_list也是C++11引入的一个新类型(类模板),表示某种特定类型的值的数组。当用auto定义变量并初始化时如果用“={}”括起来,则推导出来的类型就是std::initializer_list了。
std::initializer_list其实是一个类模板,它包含一个类型模板参数用来表示其中的成员类型(也就是这个数组里面所保存的成员类型),这个成员的类型也需要推导(这是第二次推导),如果“{}”中的成员类型不一致,则成员类型的推导会失败。
auto num = 10; //num为int类型
auto num1 = { 10 }; //num1为std::initializer_list<int>类型
auto num2 = { 10,20,30 }; //num1为std::initializer_list<int>类型
//auto num3 = { 10,20,30.1f }; //错误,无法推导auto类型对象的初始化方式五花八门,有用“()”的,有用“{}”的,也有用“={}”的等。为了统一对象的初始化方式,在C++11中,引入了“统一初始化”的概念,英文名就是Uniform Initialization,试图努力创造一个统一的对象初始化方式 。
当编译器看到这种大括号括起来的形如{"aa","bb","cc"}的内容,一般就会将其转化成一个std::initializer_list。所以可以这样认为,所谓的“统一初始化”,其背后就是std::initializer_list进行支持的。
六、decltype
decltype和auto有类似之处,两者都是用来推断类型的。decltype有如下特点:
- decltype的自动类型推断也发生在编译期,这一点和auto一样。
- decltype不会真正计算表达式的值。
- const限定符、引用属性等有可能会被auto抛弃,但decltype一般不会抛弃任何东西。
固定规则:①decltype后面是一个非变量的表达式(*p);②且该表达式能够作为等号左边的内容(*p=20;);那么decltype得到的类型就是一个形如“类型名&”的左值引用类型:
auto num = 10;
int *p = #
*p = 20;
decltype(*p) num1 = num; //num1为 int& 类型decltype((变量))的结果永远是引用。注意这里是双层括号。而decltype(变量),除非变量本身是引用,否则整个decltype的类型不会是引用。
decltype后的“()”里本来是一个变量,但如果这个变量名上额外加了一层括号或者多层括号,那编译器就会把这个变量当成一个表达式,又因为变量名可以放在等号左侧(左值),所以会推断出引用类型。
auto num = 10;
int temp = 30;
decltype(num) num1 = 20; //num1为 int 类型
decltype((num)) num2 = temp; //num2为 int& 类型 int temp = 30;
auto &num = temp; //num为 int& 类型
decltype(num) num1=temp; //num1为 int& 类型七、std::function & std::bind
1.详细记录
boost | 函数与回调(一)ref与bind_boost::bind ref-CSDN博客
【精选】boost | 函数与回调(二)function_function回调函数_烫青菜的博客-CSDN博客
2.简单说明
std::bind能将对象以及相关的参数绑定到一起,绑定完后可以直接调用,也可以用std::function进行保存,在需要的时候调用。
std::bind有两个意思:
- 将可调用对象和参数绑定到一起,构成一个仿函数,所以可以直接调用。
- 如果函数有多个参数,可以绑定部分参数,其他的参数在调用的时候指定。
因为有了占位符(placeholder)这种概念,所以std::bind的使用就变得非常灵活。可以直接绑定函数的所有参数,也可以仅绑定部分参数。
绑定部分参数时,就需要通过std::placeholders来决定bind所在位置的参数将会属于调用发生时的第几个参数。
- std::bind的思想实际上是一种延迟计算的思想,将可调用对象保存起来,然后在需要的时候再调用。
- std::function一般要绑定一个可调用对象,类成员函数不能被绑定。而std::bind更加强大,成员函数、成员变量等都能绑定。现在通过std::function和std::bind的配合,所有的可调用对象都有了统一的操作方法。
八、lambda表达式
1.lambda表达式的特点
[捕获列表](参数列表)->返回类型 {
函数体;
};- 它是一个匿名函数,也可以理解为可调用的代码单元或者是未命名的内联函数。
- 它也有一个返回类型、一个参数列表、一个函数体。
- 与函数不同的是,lambda表达式可以在函数内部定义(上面范例就是在main主函数中定义的lambda表达式),这个是常规函数做不到的。
2.格式说明
- 返回类型是后置的这种语法(lambda表达式的返回类型必须后置,这是语法规定)。因为很多时候lambda表达式返回值非常明显,所以允许省略lambda表达式返回类型定义——“->返回类型”都省略了,编译器能够根据return语句自动推导出返回值类型。
- 没有参数的时候,参数列表可以省略,甚至“()”也可以省略。
- 捕获列表[]和函数体不能省略,必须时刻包含。
- lambda表达式的调用方法和普通函数相同,都是使用“()”这种函数调用运算符。
- lambda表达式可以不返回任何类型,不返回任何类型就是返回void。
- 函数体末尾的分号不能省。
3.捕获列表说明
lambda表达式通过捕获列表来捕获一定范围内的变量。捕获这个概念,只针对在创建lambda表达式的作用域内可见的非静态局部变量(包括形参)。即:捕获是不包括静态局部变量的,也就是说,静态局部变量不能被捕获,但是可以在lambda表达式中使用。另外,静态局部变量保存在静态存储区,它的有效期一直到程序结束。
- []:不捕获任何变量。
- [&]:捕获外部作用域中所有变量,并作为引用在函数体内使用。
- [=]:捕获外部作用域中所有变量,并作为副本(按值)在函数中使用,也就是可以用它的值,但不能给它赋值。
- [this]:一般用于类中,捕获当前类中this指针,让lambda表达式拥有和当前类成员函数同样的访问权限。如果已经使用了“&”或者“=”,则默认添加了此项(this项)。也就是说,捕获this的目的就是在lambda表达式中使用当前类的成员函数和成员变量。注意,针对成员变量,[this]或者[=]可以读取,但不可以修改。如果想修改,可以使用[&]。
- 按值捕获和按引用捕获。
- [变量名]:按值捕获(不能修改)变量名所代表的变量,同时不捕获其他变量。
- [&变量名]:按引用捕获(可以修改)变量名代表的变量,同时不捕获其他变量。
- 上面的变量名如果是多个,之间可以用逗号分隔。当然对于按引用捕获,多个变量名的情况下,每个变量名之前也都要带有&。
- [=,&变量名]:按值捕获所有外部变量,但按引用捕获“&”中所指的变量(如果有多个要按引用捕获的变量,那么每个变量前都要增加“&”),这里“=”必须写在开头位置,开头这个位置表示“默认捕获方式”。也就是说,这个捕获列表第一个位置表示的是默认捕获方式(也叫隐式捕获方式),后续其他的都是显式捕获方式。
- [&,变量名]:按引用捕获所有外部变量,但按值捕获变量名所代表的变量。这里这个“&”必须写在开头位置,开头这个位置表示“默认捕获方式”。
void main(){
auto function= [](int a)->int{ //lambda表达式创建的匿名函数
return ++a;
};
//或者写成:
std::function<int(int)> function= [](int a)->int{
return ++a;
};
//或者写成:
int(*function)(int)=[](int a)->int{
return ++a;
};
std::cout << function(10) << std::endl;
}
![dbeaver查看表,解决证书报错current license is non-compliant for [jdbc]](https://img-blog.csdnimg.cn/8c4d00e372bc426e881f9aba7cf58bf8.png)