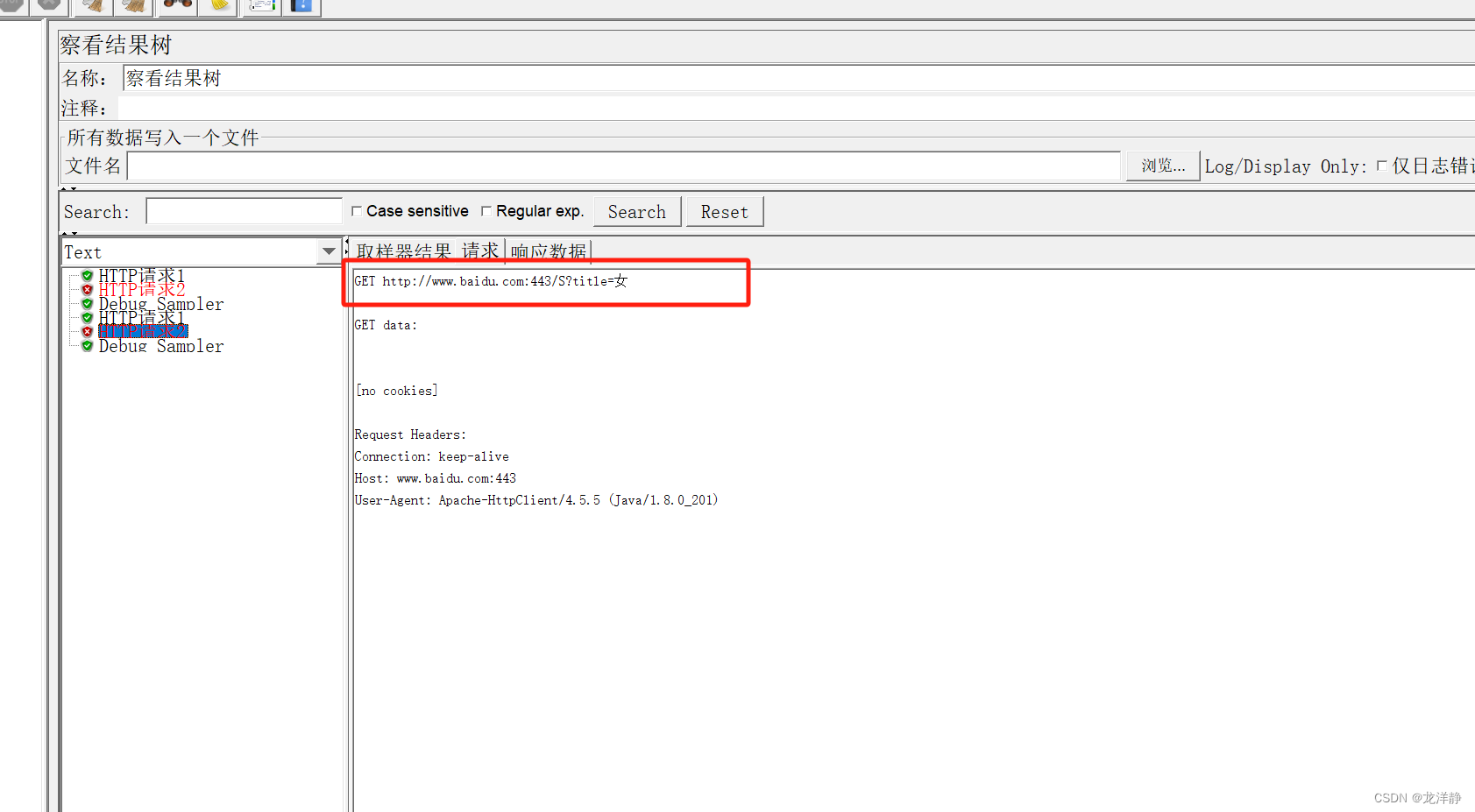
分为两种:有参注意力和无参注意力。
eg:
有参:
import torch
from torch import nn
class EMA(nn.Module):
def __init__(self, channels, factor=8):
super(EMA, self).__init__()
self.groups = factor
assert channels // self.groups > 0
self.softmax = nn.Softmax(-1)
self.agp = nn.AdaptiveAvgPool2d((1, 1))
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
self.gn = nn.GroupNorm(channels // self.groups, channels // self.groups)
self.conv1x1 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=1, stride=1, padding=0)
self.conv3x3 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=3, stride=1, padding=1)
def forward(self, x):
b, c, h, w = x.size()
group_x = x.reshape(b * self.groups, -1, h, w) # b*g,c//g,h,w
x_h = self.pool_h(group_x)
x_w = self.pool_w(group_x).permute(0, 1, 3, 2)
hw = self.conv1x1(torch.cat([x_h, x_w], dim=2))
x_h, x_w = torch.split(hw, [h, w], dim=2)
x1 = self.gn(group_x * x_h.sigmoid() * x_w.permute(0, 1, 3, 2).sigmoid())
x2 = self.conv3x3(group_x)
x11 = self.softmax(self.agp(x1).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x12 = x2.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
x21 = self.softmax(self.agp(x2).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x22 = x1.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
weights = (torch.matmul(x11, x12) + torch.matmul(x21, x22)).reshape(b * self.groups, 1, h, w)
return (group_x * weights.sigmoid()).reshape(b, c, h, w)
无参:
import torch
import torch.nn as nn
class SimAM(torch.nn.Module):
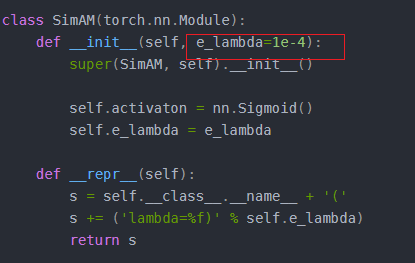
def __init__(self, e_lambda=1e-4):
super(SimAM, self).__init__()
self.activaton = nn.Sigmoid()
self.e_lambda = e_lambda
def __repr__(self):
s = self.__class__.__name__ + '('
s += ('lambda=%f)' % self.e_lambda)
return s
@staticmethod
def get_module_name():
return "simam"
def forward(self, x):
b, c, h, w = x.size()
n = w * h - 1
x_minus_mu_square = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2)
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2, 3], keepdim=True) / n + self.e_lambda)) + 0.5
return x * self.activaton(y)
1、在nn文件夹下新建attention.py文件,把上面俩代码放进去
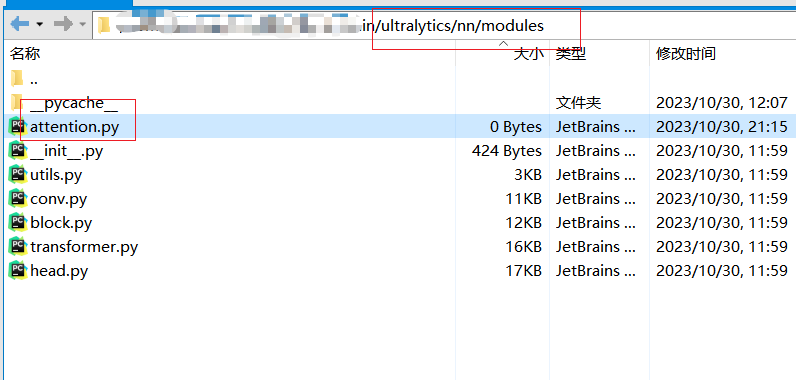
2、在tasks.py文件里面导入俩函数
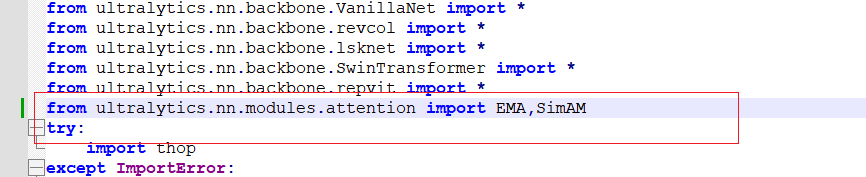
3、在解析函数里面添加解析代码

c1:上一层的输出通道数,也是这一层的输入通道数
C2:该层的输出通道数,即将成为下一层的输入通道数
args[]:每个带参数的模块,都要指定这个东西,这个包括[c1,c2,剩下的参数],然后传给该层的模块,有些模块不需要额外参数,就只传一个输出通道数给这一层就行
切记!!!C2是这一层的输出通道数,而args[]里的输入输出通道数是给模块的
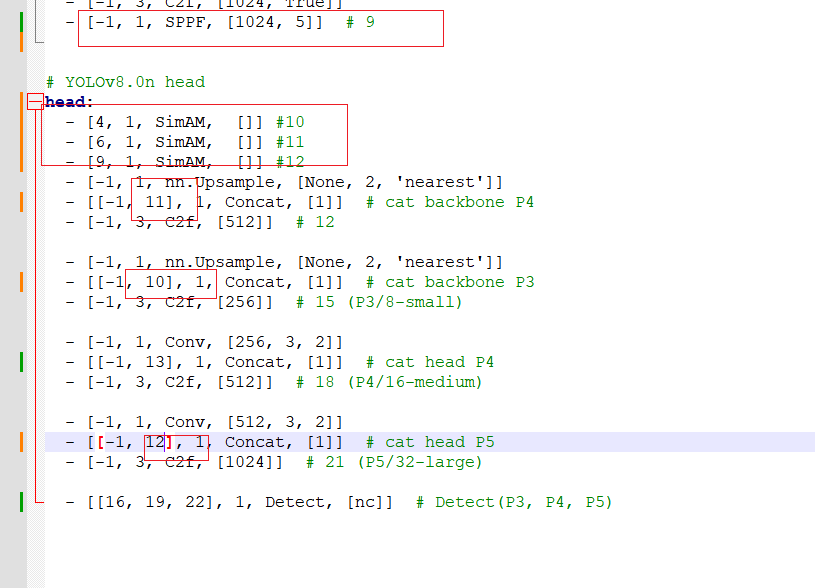
4、新建模型配置文件
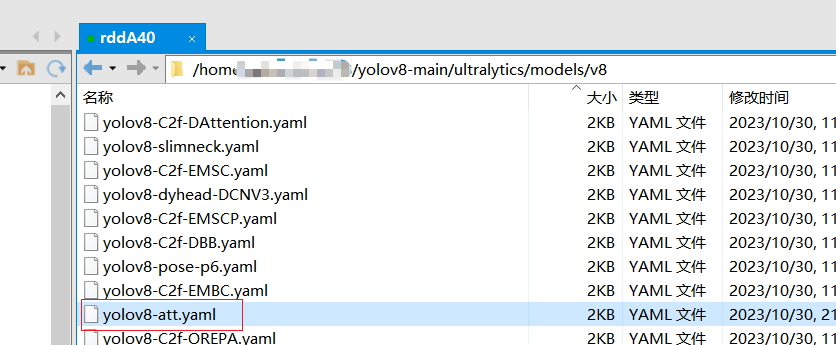
4、快速验证配置文件,新建main.py文件,然后运行
from ultralytics import YOLO
if __name__=='__main__':
print('11111111111')
model=YOLO('/home/xxxxxxxx/v8/yolov8-main/ultralytics/models/v8/yolov8-att.yaml')
5、如果想修改这个参数,传进来
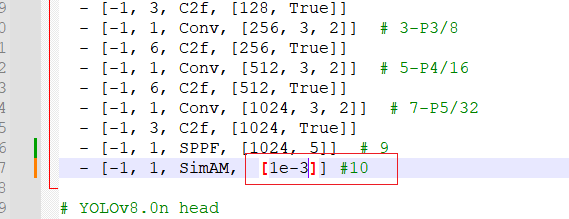
6、配置文件改也行,传进去
7、总结:放进attention.py,接着在tasks.py里注册,接着解析函数添加(有通道无通道),模型配置文件替换
8、第二种:在4、6、9后面加



![[BUUCTF NewStarCTF 2023 公开赛道] week4 crypto/pwn](https://img-blog.csdnimg.cn/2434140bc5bf4cb1a22ce7b8e95f37dd.png)