文 | 天于刀刀
你最常用的随机种子是哪个?
在刀刀的团队里,关于随机种子的设置主要分化为两派~
玄学派,可能设置为自己的纪念日,又或者是星座预测中的本月幸运数字;
以及,自然派,随机种子是啥其实无所谓,1234或者今天的日期都可以。
深度学习知名学者 ChatGPT 也如下所说:

可是近日我看到了一篇叫做《Torch.manual_seed(3407) is all you need》[1] 的论文,当时看到这个标题的时候我简直眼前一黑。
这篇论文研究了随机种子在深度学习用于计算机视觉时对精度的影响。作者对 CIFAR 10 和 ImageNet 两个数据集进行了实验,结果发现即使方差不是很大,还是很容易找到一个比平均值更好或更差的种子。

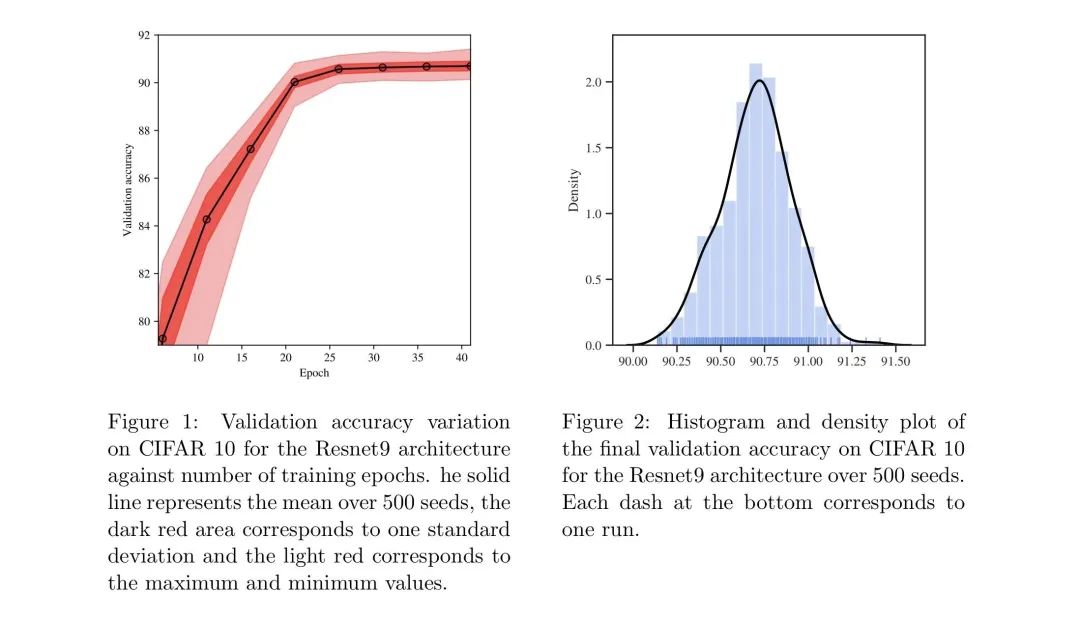
如图所示,作者在 CIFAR10 上对500个不同的种子进行训练,其中黑线是平均值,暗红色表示标准差,浅红色表示最小值和最大值区间。
可以看到,经过 epoch 25 后,精度几乎没有增加,这意味着模型收敛了。但是浅红色的区间范围没有得到减少,意味着随着模型收敛,随机种子的不同依旧会造成最大值和最小值之间巨大的差别。
同时作者还在文中分析道:由于都是基于同一个预训练模型,因此随机种子的效果只和分类层的初始化以及后续的优化过程有关。
让我们先抛开作者在文中申明的 limitation 不谈,他的这篇文章行文结构还挺像模像样的。
(在这里我指的是抛开他只进行了少量训练,且模型最终的结果完全落后于 SOTA 的事实不谈,单独只看他发文章的科研思想)
也就是说,随机种子的选择对结果的影响很大?
虽说觉得有点不靠谱,但事不宜迟,我速速打开了算力平台,新开启了一个训练任务,设置 seed 为3407之后跑了起来。
结果竟然直接 early stop 了!
当我兴致勃勃地打开训练报告时,结果发现关键指标几乎没什么变化,也根本没有发现作者所说的“模型效果获得较大提升”的现象。
结合其缩减了大约 50% 的训练时间的效果(只做了一次实验,无统计学意义),只能说改变随机种子不是完全没作用,但这作用着实不多。

这篇论文让我感到很疑惑,难道我们真的需要研究随机种子的影响吗?
在我的理解中,随机种子的作用主要是为了保证在多次实验中可以重现结果,而不是对结果产生显著影响。
我甚至认为作者是一个行为艺术者,他在嘲讽目前学术界刷论文、比赛刷榜中频频出现的过拟合乱象。
有许多研究者花费了大量的时间精力和算力去撞随机种子,故意过拟合测试集以此来得到 sota 结果,这种行为不能说是毫无意义,只能讲是步入歧途。
作为一名炼丹师,对于随机种子的修改只能是一种缺乏统计学基础知识的表现。
可是转念一想,作为一名算法工程师在工作中总会遇到无论如何绞尽脑汁也难以提分的情况。
在时间紧迫来不及清洗数据、添加数据以及干一些脏活的情况下,面对可解释性极差的 AI 魔法,也许我们选择更改随机种子的时候,心里更多想的是需要一个新的“运气”。
说不定,说不定这样就能提一点点分能让我交差了呢?
作为一名学生,也许我能获得宽裕的时间和资源去支持我按期完成学术研究;
可作为一名员工,也许我在大多数时候只能利用有限的资源去追赶去补完老板口中那个无限的大饼。
“人类是存在极限的”,有的时候并不是我不知道这样没用,但我又能有什么办法呢?
换一个 seed 吧,这就是我最后的波纹了。
# 计算天干地支获取随机幸运种子 [2]
$ pip install randluck
$ python
>>> import randluck
>>> random_seed = randluck.get_random_seed(strategy='bazi')

卖萌屋作者:天于刀刀
注重 WLB 的工业界反卷斗士,未进化的 NLP 咸鱼一条。专注于研究在各个场景中算法模型的落地情况,希望自己编写的算法有朝一日可以改变世界。目前的兴趣点在于:假新闻检测、深度学习模型可解释性等。
作品推荐
1.腾讯薪酬改革来了!晋升≠加薪?员工到底为何工作?
2.从 Google AI 离职了,这里让我爱不起来
3.百万悬赏!寻找“模型越大,效果越差”的奇葩任务!
4.想通这点,治好 AI 打工人的精神内耗
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
[1]torch.manual.seed(3407) is all you need: On the influence of random seeds in deep learning architectures for computer vision, David Picard, https://arxiv.org/abs/2109.08203
[2]Random Luck 基于中国传统玄学自动获取随机种子, https://github.com/Spico197/random-luck