NLP预训练模型的架构大致可以分为三类:
1. Encoder-Decoder架构(T5),seq2seq模型,RNN、LSTM网络
2. BERT:自编码语言模型,预测文本随机掩码
3. GPT: 自回归语言模型,预测上/下一个单词,自左向右或自右向左的语言模型
然而,没有任何一个架构能在三个主流NLP任务上都达到最好(自然语言理解、无条件生成、条件生成)
Transformer架构
2017年之前,Encoder-Decoder架构的计算核是由一个或多个循环网络(RNN、LSTM)单元构成,这样的架构存在两个问题:
- 不能进行并行计算:循环网络是顺序结构,必须等待上一时刻完成才能开展下一时刻的计算,使得模型不能进行并行计算;
- 超长序列关系微弱:对于超长序列,前后间隔过远的数据之间的联系很难建立。就文本问题,当前时刻可能受过往N个时刻的影响,而循环网络只对较近时刻信息保持敏感,对较远时刻信息很难提取关联。
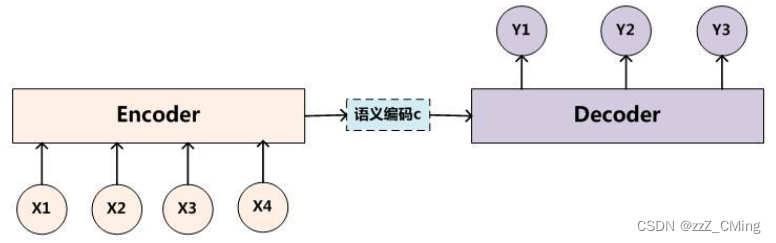
2017年谷歌发表论文《Attention Is All You Need》,就序列问题(机器翻译、语言模型)继续沿用Encoder-Decoder的经典架构,但是将计算核由循环网络改进为Transformer网络架构,这是Transformer网络架构的首次应用,便在序列问题上超越了之前RNN、LSTM等网络,取得更好的结果表现。
一、Transformer的整体结构
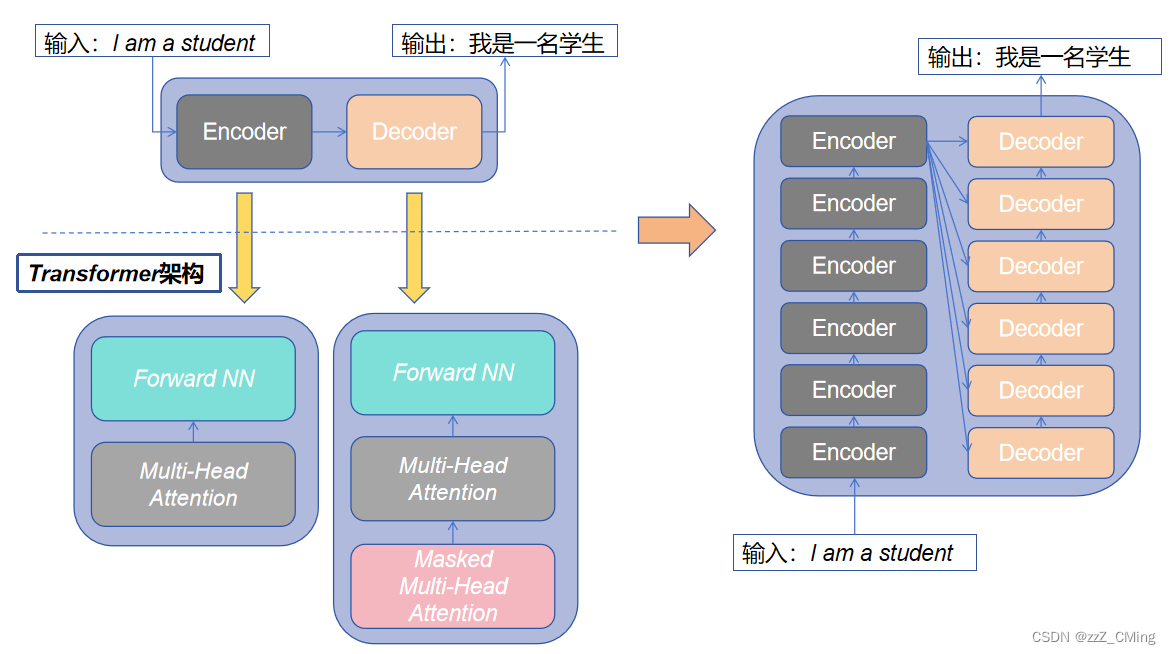
首先介绍Transformer的整体结构,下图是利用Transformer 用于中英文翻译。可以看出Transformer沿用Encoder-Decoder的经典架构,只是将处理元由神经网络换成Transformer处理层。
在Transformer架构中使用的Multi-Head Attention(多头注意力)层中的self-Attention(自注意力)机制是Transformer 架构中最出彩的部分。
(论文《Attention Is All You Need》中的Encoder和Decoder各包含6个block。)
二、Transformer的数据流转
2.1、预处理过程:建立词空间矩阵X(n,d)
获取输入句子中每个单词的词向量text embedding、位置向量path embedding,词向量 + 位置向量经过映射得到transformer词空间向量,词空间向量组合形成词空间矩阵X(n,d),n表示句子中单词的个数,d表示词向量的维度。
- 词向量text embedding:有多种方式获取,可用 Word2Vec、Glove 等算法预训练得到,也可以在Transformer中训练得到;
- 位置向量path embedding:位置向量对于NLP来说非常重要,循环网络可直接通过单词的顺序输入得到单词的位置关系,而Transformer 由于不采用循环网络的结构,所以需要单独记录顺序的位置向量path embedding,用于保存单词在序列中的相对或绝对位置;
- Transformer的输入:将词向量text Embedding 和位置向量path embedding经过映射就可以得到transformer词空间向量,词空间向量就是Transformer的输入。
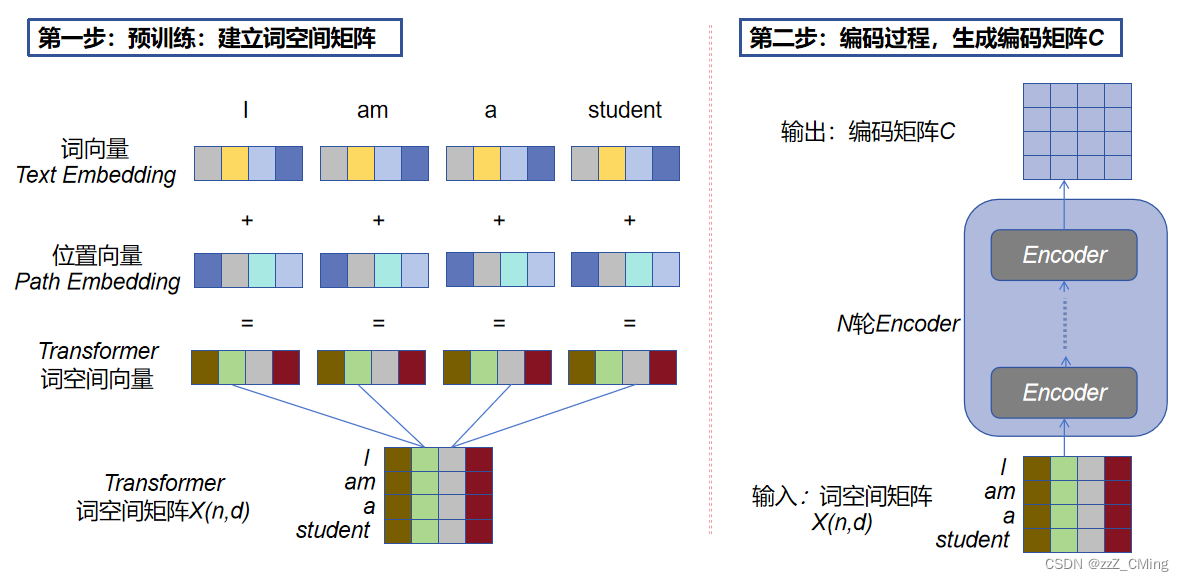
2.2、编码过程:生成编码矩阵C
将得到的词空间矩阵X(n,d)传入Encoder,经过设定的N轮Encoder后生成编码矩阵C。如上右图。
(其中每一个Encoder block中,输入、输出的矩阵维度都完全一致。)
2.3、解码过程:Mask掩码预测
将得到的编码矩阵C传递到Decoder中,在第 i 次解码过程中,会Mask掩盖住 i 之后所有的单词用于预测第 i 位的单词(0 < i < n)。
(预测值与真实值在词空间上构建损失loss,进行梯度更新训练。)