题目描述:
编写一个高效的算法来搜索 m*n 矩阵 matrix 中的一个目标值
target。该矩阵具有以下特性:
- 每行的元素从左到右升序排列。
- 每列的元素从上到下升序排列。
示例1:
输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 5 输出:true示例 2:
输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 20 输出:false提示:
m == matrix.lengthn == matrix[i].length1 <= n, m <= 300-10^9 <= matrix[i][j] <= 10^9- 每行的所有元素从左到右升序排列
- 每列的所有元素从上到下升序排列
-10^9 <= target <= 10^9

解题思路:
首先最简单的办法就是暴力法直接遍历数组判断target是否出现,时间复杂度为O(mn),没有利用到这个题目矩阵的特点,显然这不是最优解。
根据矩阵 "每行的所有元素从左到右升序排列,每列的所有元素从上到下升序排列"的特点,容易想到可以利用二分法查找每一行或每一列来判断target是否出现,时间复杂度为O(mlogn)或O(nlogm)。
那么还有没有更好的办法呢?
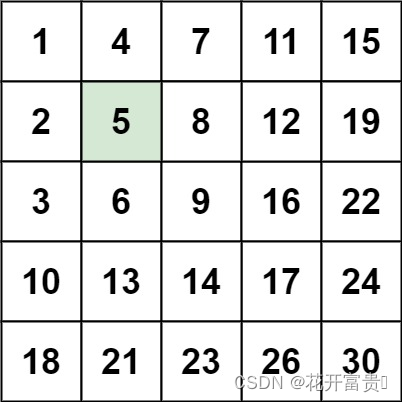
仔细观察示例1中的矩阵,用红线标出每行可能出现target(5)的位置
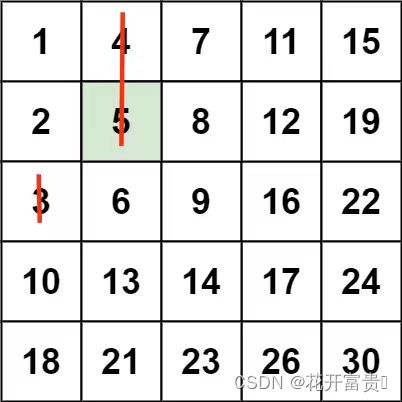
标出示例2矩阵可能出现target(20)的位置

可以发现红线把矩阵分隔成了两块区域,左边区域元素都小于target,右边区域元素都大于target,那么不管是左边区域还是右边区域都不可能会出现target,所以只要想办法遍历矩阵红线标记位置,其他位置就不用去遍历。
算法流程:
1.可以选矩阵的一角作为起点,选右上角(0,n-1)为起点开始遍历,元素matrix[i][j]:
- matrix[i][j]小于target,因为每行元素从左到右是升序,左边元素一定比matrix[i][j]小,所以应该往下搜索,i增加1。
- matrix[i][j]等于target返回true。
- matrix[i][j]大于target,因为每列从上到下是升序,下边元素一定比matrix[[i][j]大,所以应该往左搜索,j减少1。
2.若i或j出界,未查找到target,返回false。
以下是算法Java实现:
class Solution {
public boolean searchMatrix(int[][] matrix, int target) {
int m=matrix.length;
int n=matrix[0].length;
int i=0;
int j=n-1;
while(i<m&&j>=0){
if(matrix[i][j]==target) return true;
if(matrix[i][j]>target){
j--;
} else{
i++;
}
}
return false;
}
}以上算法在官方题解中称为"Z字形查找",Z字形查找每次可以排除一行或一列的元素,时间复杂度为O(m+n),空间复杂度为O(1)。
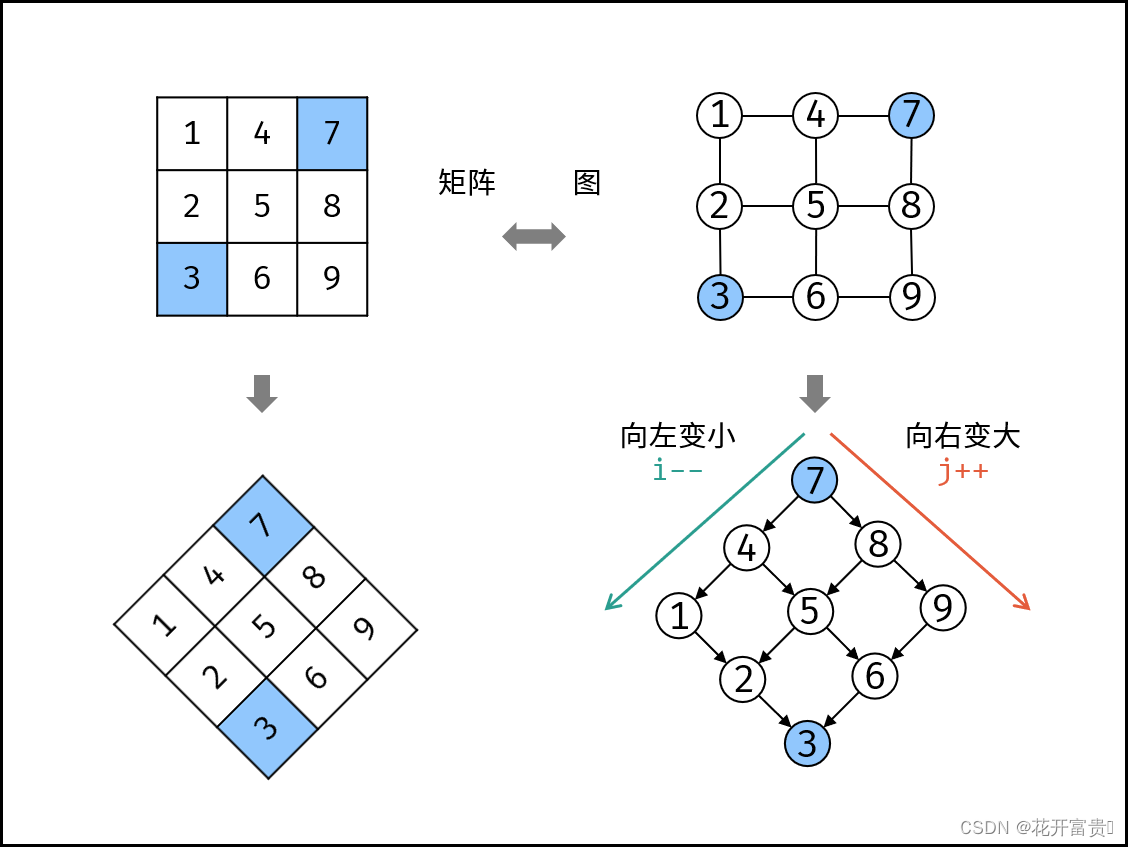
另一种理解方式——二叉搜索树
如下图所示,我们将矩阵逆时针旋转 45° ,并将其转化为图形式,发现其类似于 二叉搜索树 ,即对于每个元素,其左分支元素更小、右分支元素更大。因此,通过从 “根节点” 开始搜索,遇到比 target 大的元素就向左,反之向右,即可找到目标值 target 。