read_csv读取之后,会返回DataFrame格式的文件
读取去掉头的文件
import pandas as pd
df = pd.read_csv('file.csv', header=None)
按列名读取某一列
pd['列名']
按索引读取n列
如读取前13列所有行的值
pd.iloc[:,:13]
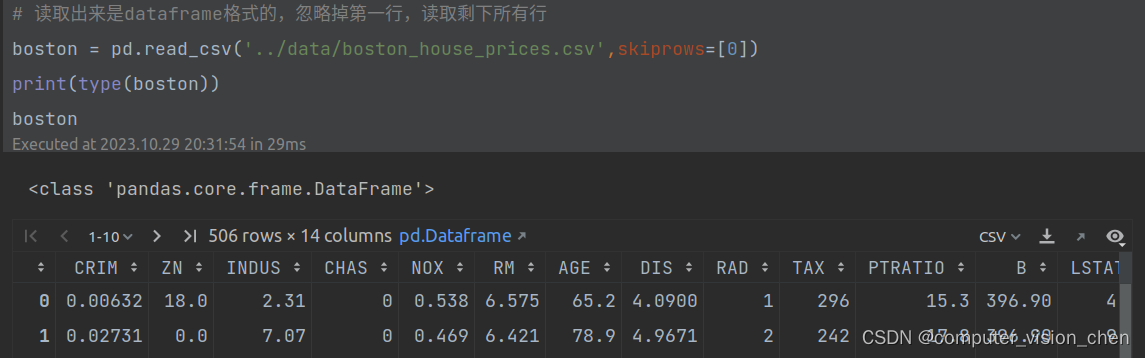
忽略掉第一行,读取剩下所有行
原表格的第一行是统计的行数和列数,剩下的是空值,读取之后变成了 unnamed:
 使用如下代码去掉原文件的第一行
使用如下代码去掉原文件的第一行
# 读取出来是dataframe格式的,忽略掉第一行,读取剩下所有行
boston = pd.read_csv('../data/boston_house_prices.csv',skiprows=[0])
print(type(boston))
boston
删除某列,并返回该列(带列头)
# 从dataframe格式的boston中,删除列为MEDV的列,并返回该列(带列头)
y = boston.pop('MEDV')
统计每一列的NaN和None这种空值
print(boston.isnull().sum())
热力图计算特征和特征之间的相关性
# 13个特征之间的相关性
import seaborn as sns
plt.figure(figsize=(12, 8))
# 第14列是标签,取前13列进行计算
sns.heatmap(boston.iloc[:,:13].corr(), annot=True, fmt='.2f', cmap='PuBu')
plt.show()