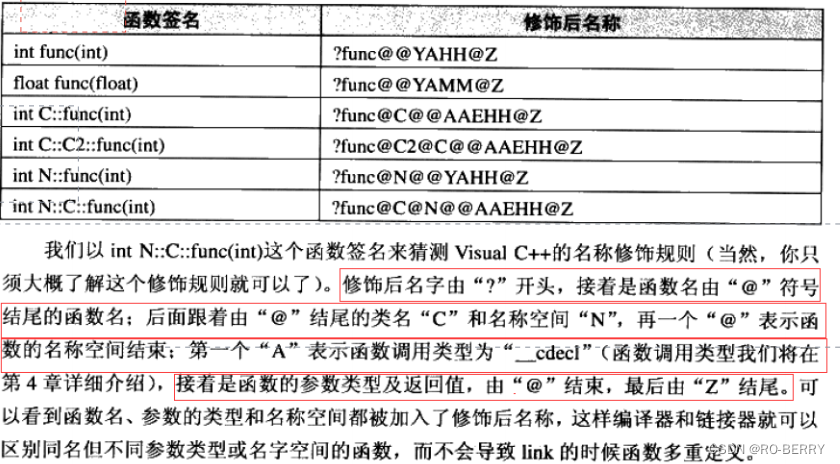
简介
Buffer封装了一个可变长的buffer,支持廉价的前插操作,以及内部挪腾操作避免额外申请空间
使用vector作为缓冲区(可自动调整扩容)
设计图

源码剖析
已经编写好注释
buffer.h
// Copyright 2010, Shuo Chen. All rights reserved.
// http://code.google.com/p/muduo/
//
// Use of this source code is governed by a BSD-style license
// that can be found in the License file.
// Author: Shuo Chen (chenshuo at chenshuo dot com)
//
// This is a public header file, it must only include public header files.
#ifndef MUDUO_NET_BUFFER_H
#define MUDUO_NET_BUFFER_H
#include "muduo/base/copyable.h"
#include "muduo/base/StringPiece.h"
#include "muduo/base/Types.h"
#include "muduo/net/Endian.h"
#include <algorithm>
#include <vector>
#include <assert.h>
#include <string.h>
//#include <unistd.h> // ssize_t
namespace muduo
{
namespace net
{
/// A buffer class modeled after org.jboss.netty.buffer.ChannelBuffer
///
/// @code
/// +-------------------+------------------+------------------+
/// | prependable bytes | readable bytes | writable bytes |
/// | | (CONTENT) | |
/// +-------------------+------------------+------------------+
/// | | | |
/// 0 <= readerIndex <= writerIndex <= size
/// @endcode
class Buffer : public muduo::copyable
{
public:
static const size_t kCheapPrepend = 8;//预留8字节
static const size_t kInitialSize = 1024;//缓冲区初始化大小
explicit Buffer(size_t initialSize = kInitialSize)
: buffer_(kCheapPrepend + initialSize),
readerIndex_(kCheapPrepend),
writerIndex_(kCheapPrepend)
{
assert(readableBytes() == 0);
assert(writableBytes() == initialSize);
assert(prependableBytes() == kCheapPrepend);
}
// implicit copy-ctor, move-ctor, dtor and assignment are fine
// NOTE: implicit move-ctor is added in g++ 4.6
void swap(Buffer& rhs)//交换缓冲区
{
buffer_.swap(rhs.buffer_);
std::swap(readerIndex_, rhs.readerIndex_);
std::swap(writerIndex_, rhs.writerIndex_);
}
size_t readableBytes() const//剩余可读字节大小
{ return writerIndex_ - readerIndex_; }
size_t writableBytes() const//剩余可写字节大小
{ return buffer_.size() - writerIndex_; }
size_t prependableBytes() const//已读字节大小
{ return readerIndex_; }
const char* peek() const//readIndex
{ return begin() + readerIndex_; }
const char* findCRLF() const
{
// FIXME: replace with memmem()?
const char* crlf = std::search(peek(), beginWrite(), kCRLF, kCRLF+2);
return crlf == beginWrite() ? NULL : crlf;
}
const char* findCRLF(const char* start) const//在start~writeIndex区间寻找kCRLF
{
assert(peek() <= start);
assert(start <= beginWrite());
// FIXME: replace with memmem()?
const char* crlf = std::search(start, beginWrite(), kCRLF, kCRLF+2);
return crlf == beginWrite() ? NULL : crlf;
}
const char* findEOL() const//在readIndex~writeIndex区间寻找'\n'
{
const void* eol = memchr(peek(), '\n', readableBytes());
return static_cast<const char*>(eol);
}
const char* findEOL(const char* start) const
{
assert(peek() <= start);
assert(start <= beginWrite());
const void* eol = memchr(start, '\n', beginWrite() - start);
return static_cast<const char*>(eol);
}
// retrieve returns void, to prevent
// string str(retrieve(readableBytes()), readableBytes());
// the evaluation of two functions are unspecified
void retrieve(size_t len)//回收len个字节的数据(可读数据)
{
assert(len <= readableBytes());
if (len < readableBytes())
{
readerIndex_ += len;
}
else
{
retrieveAll();
}
}
void retrieveUntil(const char* end)//回收readINdex~len区间的数据
{
assert(peek() <= end);
assert(end <= beginWrite());
retrieve(end - peek());
}
//回收相应类型大小的数据
void retrieveInt64()
{
retrieve(sizeof(int64_t));
}
void retrieveInt32()
{
retrieve(sizeof(int32_t));
}
void retrieveInt16()
{
retrieve(sizeof(int16_t));
}
void retrieveInt8()
{
retrieve(sizeof(int8_t));
}
void retrieveAll()//回收所有空间
{
readerIndex_ = kCheapPrepend;
writerIndex_ = kCheapPrepend;
}
string retrieveAllAsString()//返回缓冲区所有剩余的数据
{
return retrieveAsString(readableBytes());
}
string retrieveAsString(size_t len)//回收len大小的数据,并将这段数据返回
{
assert(len <= readableBytes());
string result(peek(), len);
retrieve(len);
return result;
}
//返回StringPiece类型,该类保存一个char*指针,并保存len长度,并提供一些基础方法(可以理解为低配版std::string)
//保存
StringPiece toStringPiece() const
{
return StringPiece(peek(), static_cast<int>(readableBytes()));
}
void append(const StringPiece& str)
{
append(str.data(), str.size());
}
void append(const char* /*restrict*/ data, size_t len)
{
ensureWritableBytes(len);//确保有可写字节大小的空间
std::copy(data, data+len, beginWrite());//将追加数据加入缓冲区
hasWritten(len);//更新writerIndex_
}
void append(const void* /*restrict*/ data, size_t len)
{
append(static_cast<const char*>(data), len);
}
void ensureWritableBytes(size_t len)//确保有可写字节大小的空间
{
//如果可写空间大于len则什么也不干,小于则调整buffer
if (writableBytes() < len)
{
makeSpace(len);
}
assert(writableBytes() >= len);
}
char* beginWrite()//writeIndex
{ return begin() + writerIndex_; }
const char* beginWrite() const//writeIndex
{ return begin() + writerIndex_; }
void hasWritten(size_t len)//writerIndex_追加移动len个字节
{
assert(len <= writableBytes());
writerIndex_ += len;
}
void unwrite(size_t len)//writerIndex_减少移动len个字节
{
assert(len <= readableBytes());
writerIndex_ -= len;
}
///
/// Append int64_t using network endian
///
//将类型大小的数据转成网络字节数(大端)后放入缓冲区
void appendInt64(int64_t x)
{
int64_t be64 = sockets::hostToNetwork64(x);
append(&be64, sizeof be64);
}
///
/// Append int32_t using network endian
///
void appendInt32(int32_t x)
{
int32_t be32 = sockets::hostToNetwork32(x);
append(&be32, sizeof be32);
}
void appendInt16(int16_t x)
{
int16_t be16 = sockets::hostToNetwork16(x);
append(&be16, sizeof be16);
}
void appendInt8(int8_t x)
{
append(&x, sizeof x);
}
///
/// Read int64_t from network endian
///
/// Require: buf->readableBytes() >= sizeof(int32_t)
//在缓冲区中读Intxx类型大小的数据,转换为主机字节序,并调整缓冲区的下标,然后返回数据
int64_t readInt64()
{
int64_t result = peekInt64();
retrieveInt64();
return result;
}
///
/// Read int32_t from network endian
///
/// Require: buf->readableBytes() >= sizeof(int32_t)
int32_t readInt32()
{
int32_t result = peekInt32();
retrieveInt32();
return result;
}
int16_t readInt16()
{
int16_t result = peekInt16();
retrieveInt16();
return result;
}
int8_t readInt8()
{
int8_t result = peekInt8();
retrieveInt8();
return result;
}
///
/// Peek int64_t from network endian
///
/// Require: buf->readableBytes() >= sizeof(int64_t)
//在缓冲区中读Intxx类型大小的数据,转换为主机字节序,然后返回数据
int64_t peekInt64() const
{
assert(readableBytes() >= sizeof(int64_t));
int64_t be64 = 0;
::memcpy(&be64, peek(), sizeof be64);
return sockets::networkToHost64(be64);
}
///
/// Peek int32_t from network endian
///
/// Require: buf->readableBytes() >= sizeof(int32_t)
int32_t peekInt32() const
{
assert(readableBytes() >= sizeof(int32_t));
int32_t be32 = 0;
::memcpy(&be32, peek(), sizeof be32);
return sockets::networkToHost32(be32);
}
int16_t peekInt16() const
{
assert(readableBytes() >= sizeof(int16_t));
int16_t be16 = 0;
::memcpy(&be16, peek(), sizeof be16);
return sockets::networkToHost16(be16);
}
int8_t peekInt8() const
{
assert(readableBytes() >= sizeof(int8_t));
int8_t x = *peek();
return x;
}
///
/// Prepend int64_t using network endian
///
//转换为网络字节序,在缓冲区中读Intxx类型大小的数据,并调整缓冲区的下标,然后返回数据
//将Intxx类型大小的数据转换为网络字节序,然后以前插的方式加入缓冲区
void prependInt64(int64_t x)
{
int64_t be64 = sockets::hostToNetwork64(x);
prepend(&be64, sizeof be64);
}
///
/// Prepend int32_t using network endian
///
void prependInt32(int32_t x)
{
int32_t be32 = sockets::hostToNetwork32(x);
prepend(&be32, sizeof be32);
}
void prependInt16(int16_t x)
{
int16_t be16 = sockets::hostToNetwork16(x);
prepend(&be16, sizeof be16);
}
void prependInt8(int8_t x)
{
prepend(&x, sizeof x);
}
void prepend(const void* /*restrict*/ data, size_t len)//以前插的方式加入缓冲区,并调整下标
{
assert(len <= prependableBytes());
readerIndex_ -= len;
const char* d = static_cast<const char*>(data);
std::copy(d, d+len, begin()+readerIndex_);
}
//可以抽象理解为将buffer_修改为std::max(kInitialSize(1024),readableBytes()+reserve)大小的空间
void shrink(size_t reserve)
{
// FIXME: use vector::shrink_to_fit() in C++ 11 if possible.
Buffer other;
other.ensureWritableBytes(readableBytes()+reserve);//保证other拥有buffer_未读取数据的大小加上reserve预留空间大小的容量
other.append(toStringPiece());//将buffer_的数据追加到other
swap(other);//调用swap与buffer_交换
}
size_t internalCapacity() const//返回vector实际占用的容量
{
return buffer_.capacity();
}
/// Read data directly into buffer.
///
/// It may implement with readv(2)
/// @return result of read(2), @c errno is saved
ssize_t readFd(int fd, int* savedErrno);
private:
char* begin()
{ return &*buffer_.begin(); }
const char* begin() const
{ return &*buffer_.begin(); }
void makeSpace(size_t len)
{
// 可写空间 + 已读空间 ==除去缓冲区未读数据外的空间大小
//len(需要的空间大小)+kCheapPrepend(8字节预留内存)
//小于则直接resize,大于则将数据移到前端
if (writableBytes() + prependableBytes() < len + kCheapPrepend)//
{
// FIXME: move readable data
buffer_.resize(writerIndex_+len);
}
else
{
// move readable data to the front, make space inside buffer
assert(kCheapPrepend < readerIndex_);
size_t readable = readableBytes();
std::copy(begin()+readerIndex_,//将可读数据移动到前端,在缓冲区内部腾出空间
begin()+writerIndex_,
begin()+kCheapPrepend);
readerIndex_ = kCheapPrepend;
writerIndex_ = readerIndex_ + readable;
assert(readable == readableBytes());
}
}
private:
std::vector<char> buffer_;
size_t readerIndex_;
size_t writerIndex_;
static const char kCRLF[];
};
} // namespace net
} // namespace muduo
#endif // MUDUO_NET_BUFFER_H
buffer.cc
// Copyright 2010, Shuo Chen. All rights reserved.
// http://code.google.com/p/muduo/
//
// Use of this source code is governed by a BSD-style license
// that can be found in the License file.
// Author: Shuo Chen (chenshuo at chenshuo dot com)
//
#include "muduo/net/Buffer.h"
#include "muduo/net/SocketsOps.h"
#include <errno.h>
#include <sys/uio.h>
using namespace muduo;
using namespace muduo::net;
const char Buffer::kCRLF[] = "\r\n";
const size_t Buffer::kCheapPrepend;
const size_t Buffer::kInitialSize;
ssize_t Buffer::readFd(int fd, int* savedErrno)
{
// saved an ioctl()/FIONREAD call to tell how much to read
char extrabuf[65536];
struct iovec vec[2];
const size_t writable = writableBytes();
vec[0].iov_base = begin()+writerIndex_;
vec[0].iov_len = writable;
vec[1].iov_base = extrabuf;
vec[1].iov_len = sizeof extrabuf;
// when there is enough space in this buffer, don't read into extrabuf.
// when extrabuf is used, we read 128k-1 bytes at most.
//1.如果buffer_::size大于extrabuf::size,那我们则只用buffer_存取数据
//2.如果小于,则两块内存都使用,根据下标顺序先将数据写入buffer_,再将数据写入writable
//在这个表达式下,一次性最多能读取的数据大小为writable==65535,65535+65536=131071,也就是128k-1的大小,而一次性最少的空间为extrabuf(64k)+buffer_(初始化最少空间为1k+8byte)
const int iovcnt = (writable < sizeof extrabuf) ? 2 : 1;
const ssize_t n = sockets::readv(fd, vec, iovcnt);
if (n < 0)
{
*savedErrno = errno;
}
//如果读取的数据小于writable,则直接更新buffer_下标就行了,
//因为上述无论是第一种情况还是第二种情况,数据都是先写入buffer_
else if (implicit_cast<size_t>(n) <= writable)
{
writerIndex_ += n;
}
//如果是第二种情况则直接把下标设置在末尾,然后调用append函数并将extrabuf的数据写入buffer_(内部会调整buffer_大小并追加数据)
else
{
writerIndex_ = buffer_.size();
append(extrabuf, n - writable);
}
// if (n == writable + sizeof extrabuf)
// {
// goto line_30;
// }
return n;
}







![[Linux]线程池](https://img-blog.csdnimg.cn/img_convert/796966d796bdf42634d4542336a0a776.png)