目录
- 1.测试代码
- 2.代码介绍
- 3.运行结结果
1.测试代码
#include"ConcurrentAlloc.h"
#include"ObjectPool.h"
#include"Common.h"
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector<std::thread> vthread(nworks);
std::atomic<size_t> malloc_costtime(0);
std::atomic<size_t> free_costtime(0);
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&, k]() {
std::vector<void*> v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
//v.push_back(malloc(16));
v.push_back(malloc((16 + i) % 8192 + 1));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
free(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += (end1 - begin1);
free_costtime += (end2 - begin2);
}
});
}
for (auto& t : vthread)
{
t.join();
}
printf("%u个线程并发执行%u轮次,每轮次malloc %u次: 花费:%u ms\n",
nworks, rounds, ntimes, malloc_costtime.load());
printf("%u个线程并发执行%u轮次,每轮次free %u次: 花费:%u ms\n",
nworks, rounds, ntimes, free_costtime.load());
printf("%u个线程并发malloc&free %u次,总计花费:%u ms\n",
nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}
// 单轮次申请释放次数 线程数 轮次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector<std::thread> vthread(nworks);
std::atomic<size_t> malloc_costtime(0);
std::atomic<size_t> free_costtime (0);
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&]() {
std::vector<void*> v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
//v.push_back(ConcurrentAlloc(16));
v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
ConcurrentFree(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += (end1 - begin1);
free_costtime += (end2 - begin2);
}
});
}
for (auto& t : vthread)
{
t.join();
}
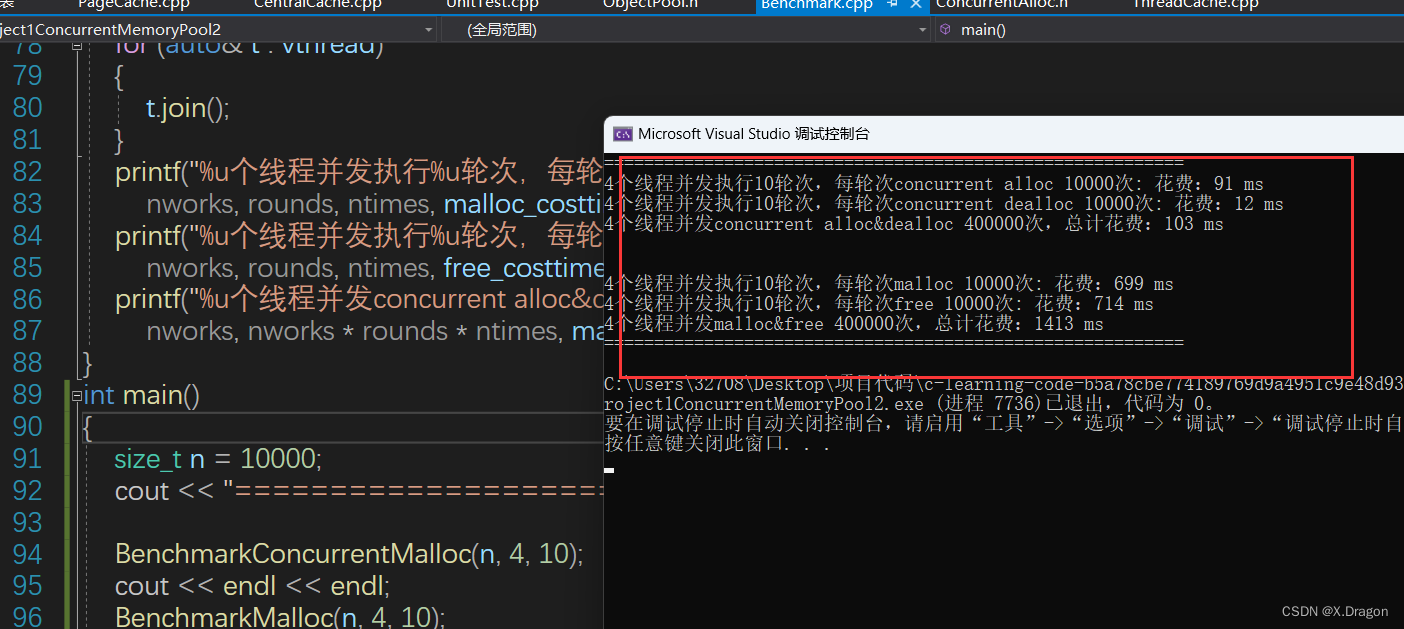
printf("%u个线程并发执行%u轮次,每轮次concurrent alloc %u次: 花费:%u ms\n",
nworks, rounds, ntimes, malloc_costtime.load());
printf("%u个线程并发执行%u轮次,每轮次concurrent dealloc %u次: 花费:%u ms\n",
nworks, rounds, ntimes, free_costtime.load());
printf("%u个线程并发concurrent alloc&dealloc %u次,总计花费:%u ms\n",
nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}
int main()
{
size_t n = 10000;
cout << "==========================================================" << endl;
BenchmarkConcurrentMalloc(n, 4, 10);
cout << endl << endl;
BenchmarkMalloc(n, 4, 10);
cout << "==========================================================" << endl;
return 0;
}
2.代码介绍
这段代码是一个 C++ 程序,主要用于比较并评估使用不同内存分配和释放方式的性能。它包括了两个主要函数 BenchmarkConcurrentMalloc 和 BenchmarkMalloc 以及 main 函数来执行这些性能测试。以下是对这些函数的介绍:
- BenchmarkConcurrentMalloc 函数
这个函数用于执行并比较使用并发内存分配(ConcurrentAlloc 和 ConcurrentFree)的性能。
它创建了一定数量的线程,每个线程会执行一定轮次的内存分配和释放操作。
在每轮次内,每个线程将执行 ntimes 次内存分配和释放。
内存分配操作使用 ConcurrentAlloc 函数,它模拟了并发内存分配器,而内存释放操作使用 ConcurrentFree 函数。
函数会测量并累积每个线程的内存分配和释放的时间开销,并打印出这些结果,包括每轮的分配和释放时间以及总时间。
2. BenchmarkMalloc 函数
这个函数用于执行并比较使用传统的 malloc 和 free 函数的性能。
它也创建了一定数量的线程,每个线程会执行一定轮次的内存分配和释放操作,与 BenchmarkConcurrentMalloc 函数类似。
内存分配操作使用标准的 malloc 函数,而内存释放操作使用 free 函数。
函数同样测量并累积每个线程的内存分配和释放的时间开销,并打印出这些结果,包括每轮的分配和释放时间以及总时间。
3. main 函数
main 函数是程序的入口点。
它首先设置了一些测试参数,如 n(每轮次内存分配次数)、线程数量(nworks)、轮次数量(rounds)。
然后,它调用 BenchmarkConcurrentMalloc 函数和 BenchmarkMalloc 函数来进行性能测试。
最后,它打印出并比较了使用并发内存分配和传统内存分配方式的性能结果。
总的来说,这段代码用于比较并评估使用不同内存分配方式的性能,主要涉及并发内存分配和传统内存分配方式,并通过多线程的方式来模拟并测量性能。
3.运行结结果


![git本地搭建服务器[Vmware虚拟机访问window的git服务器]](https://img-blog.csdnimg.cn/c8af2bfeece34633a743de37031cabaa.png)