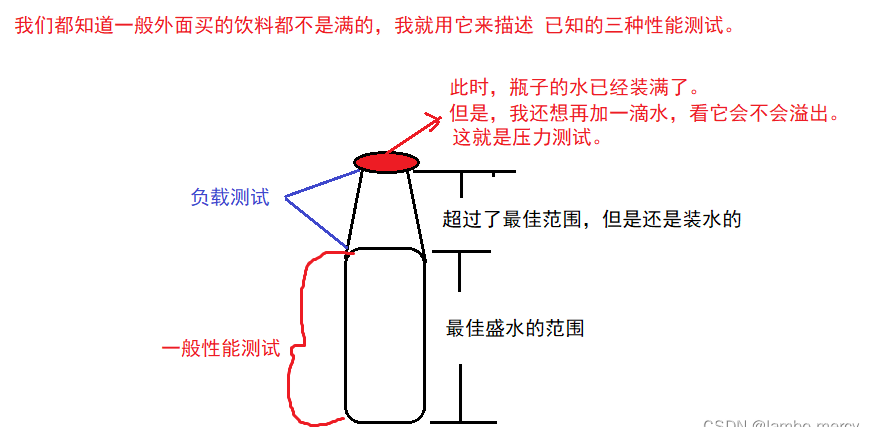
思路
确定url 确定并获取相关参数 构造header 发送请求 解析数据 输出数据 运行结果
代码
import requests
# 获取某个用户的的视频信息,截至20231028,程序可以正常运行。
# 构造请求头header
headers = {'User-Agent':'..........................',
'Cookie':'..........................'
}
# sec_uid很可能是过去常用的某个用来唯一标识用户的参数
# 用戶ID,这个参数以往貌似不太明显,不过现在可以直接从用户主页URL里边获取到,非常直观
# 以刀郎为例,其主页URL为:
# https://www.douyin.com/user/MS4wLjABAAAAUFzOSiuG-bOoOqu4mpk1tEle8XPMTWQwIsoMFuuNOumX7ch94DKEvu5nPUhE7rnN?showTab=post
# 那么他的sec_uid即为:MS4wLjABAAAAUFzOSiuG-bOoOqu4mpk1tEle8XPMTWQwIsoMFuuNOumX7ch94DKEvu5nPUhE7rnN
sec_uid = "MS4wLjABAAAAUFzOSiuG-bOoOqu4mpk1tEle8XPMTWQwIsoMFuuNOumX7ch94DKEvu5nPUhE7rnN"
# 请求数据的地址,count代表需要获取的数目
url = f"https://www.iesdouyin.com/web/api/v2/aweme/post/?sec_uid={sec_uid}&count=100"
# 发送get请求
res = requests.get(url,headers=headers)
# 输出响应数据(仅仅输出状态码)
print(res)
# 输出返回的json数据
print(res.text)
# 将返回的json数据转换为字典
res_dict = res.json()
print(res_dict)
love_num_list = []
# aweme_list存储的是抖音视频列表,aweme代表抖音(视频)
aweme_list = res_dict['aweme_list']
# 分析列表长度
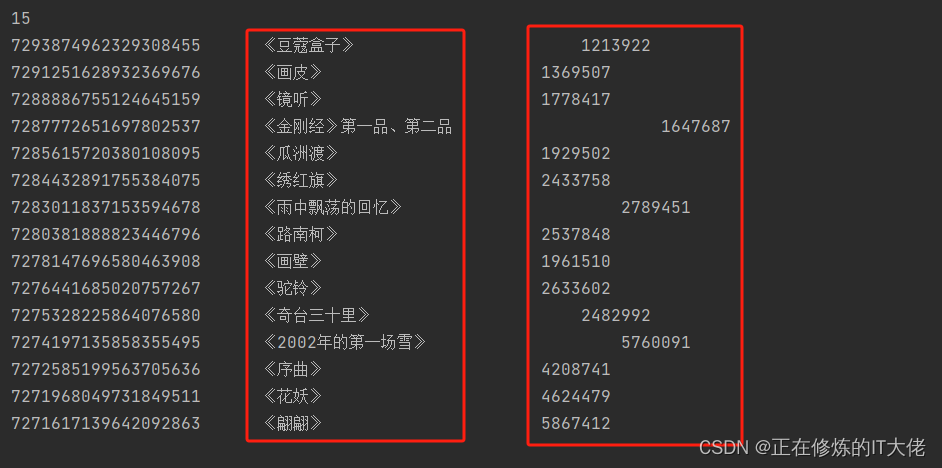
print(len(res_dict['aweme_list']))
# 仅获取抖音视频list前10个
for item in aweme_list:
try:
# aweme_id 存储抖音ID
# desc 存储视频的名称/描述
# statistics 存储视频详细相关的数据
# digg_count 存储点赞数量
print(item['aweme_id'],'\t',item['desc'],'\t\t\t\t\t',item['statistics']['digg_count'])
except:
pass