收藏和点赞,您的关注是我创作的动力
文章目录
- 概要
- 一、 实验设计与结果分析
- 3.1 CACD数据集及图像预处理
- 二、行人属性识别
- 4.2 系统开发环境
- 4.3 功能模块实现
- 4.3.1 图像采集模块
- 结 论
概要
本文提供了一个采用更多消耗函数方法的网络模式,将交叉熵损耗函数和经过修改的监控信息中心损失函数方法结合,对模型参数加以了修改。最后,所提取出的特点将更为明显,使同一个人的特点也更为紧凑。与只用交叉熵损失函数培训的网络比较下,对交叉年龄数据集的检测结果做出了改善,使采用WEB技术开发的行人属性辨识应用领域也能够正常进行。与其他类型的应用程序比较,该应用领域具备了跨平台、轻量化的特性,其功能主体涉及图像采集、行人属性辨识以及数据存储模块等,可广泛应用于日常生活辨识任务。
关键词:深度学习;行人属性识别;多损失函数
一、 实验设计与结果分析
3.1 CACD数据集及图像预处理
CACD数据分析集由Chen等于在2014年发布,是当时数据分析量较大的跨年龄段变化人脸数据集合。在获取该数据集中时,研发人员首先考虑了两点关键的原则,一是数据集中的人必须涵盖了各个年龄段,二是这部分人的面部照片必须可以利用网络方便、大量地收集。针对此研究人员选取了IMDb.com上各个年龄段的名人作为待收录的对象,并最终在从1951年至1990年诞生的名人中,每年选取了排行榜前50位,总共收录了2000位名人。然后使用Google查找这些名人的照片时,将名人"名字+年份"为关键字。每个人可以收集从2004年至2013年的所有照片,因而年龄跨度约为10年。但此方案所收集的图像中也涉及了大量噪声因素,如检索到的图像中涉及多人或一些名人在有的年份发布的照片数量很少等,因此研发人员只对测试集数量进行了人工检测。在对所采集的图像进行了人脸测试、去比重后,在最终的CACD数据集中获得了年龄范围从16至62周岁的共163446张人脸图像,各个年龄图像数量分别如图3所显示,其中以20-60周岁的儿童图像数量为主,而一般每人也有80张以下的儿童图像数量。
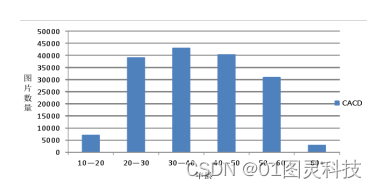
图3 CACD数据集图像年龄分布图
CACD数据集已经涵盖了足够的数量,而且每个人所涉及的图像数量比较统一,因此能够用于训练深度的卷积式神经网络模型。要增强模型的识别效果,就必须在训练之前先对图像数据进行预处理。
为提高模型的泛化能力,可在训练流程中使用影像强化技术建立更多的训练样本,从而更有效地控制过模型拟合过程。对训练样本数据来说,有二个主要影像强化技术:水平反演和随机裁剪。基于人脸的对称性,训练好的模型能够使用水平翻转图形来满足对同一个人不同的视角。图4中显示了CACD中人的脸原图形,以及通过人脸检测对齐处理、水平翻转后的图形。
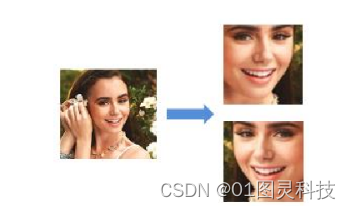
图4 人脸图像检测对齐、水平翻转处理
经检测与对齐处理后人脸区域的图像尺寸约为256×256,再通过随机裁剪至224×224尺寸的图像作为最后练习的入口,如图5所示,能够成倍增加训练样本量,从而使得网络模式对部分区域的平移变化或者是脸部遮盖并不敏感,从而有效提高了模拟的泛化能力。

图5 随机裁剪处理示例
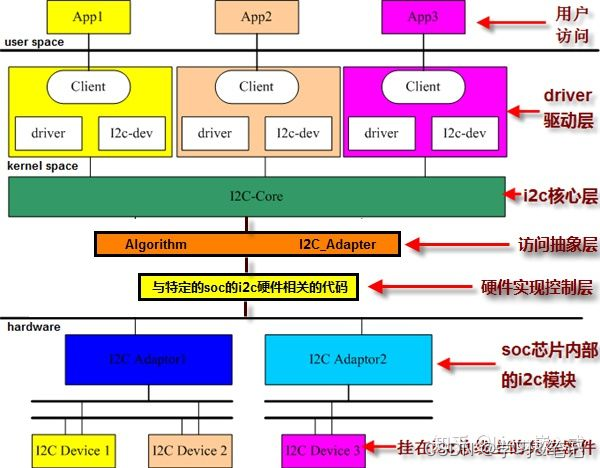
二、行人属性识别
系统的整体设计重点,是通过系统分析应用情景下行对人属性识别任务和对其子模块的系统要求,并提出了具体的系统结构、业务流程等,是构建体系的首要基础。在本文的行人属性识别系统中,主要是利用web前端收集图像,并将图像数据以及相关的请求信号发送到服务器进行处理,然后再将识别的结果反馈给前端。系统总体结构如图八所述,大致上包括了三部分,包括图片收集模块、行人属性辨识模块、数据存储模块,其之间联系流程如图8所示。
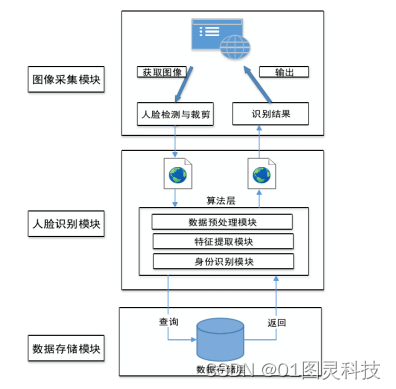
图8 系统整体架构图
4.2 系统开发环境
本系统在Ubuntu环境下开发,采用Python语言进行开发,具体软硬件环境如表1所示:
表1 软硬件开发环境
硬件环境 AMD A8 PRO-7600B R7 CPU, 8G 内存
AMD Radeon™ R7 Graphics (1024MB) 显卡
软件环境 Microsoft Windows 10 专业版 (64位) 系统,Dlib,Flask,Keras
4.3 功能模块实现
4.3.1 图像采集模块
(1)图像数据采集显示
首先需要上传图片或接入视频流,并实时展示在网页端。对于视频流可以是已有的视频,也可以来自于摄像头实时视频流。这一任务在过去针对前端技术人员来说是很难以实现的,但是HTML五标准的推出却为前端人员在多媒体交互使用上提供了很多方便。HTML五的新特点WebRTC(Web Real TimeCommunication)提供了 MediaDevices.GetUserMedia()接口,可以在各种设备上直接向用户申请捕获流媒体输入内容的授权,这里还包括视频源,也可以利用设备上的摄像机捕获。进一步,当收集到视频流对象时,如果想要直接把该视频流导入到前端网页上,则必须先给该视频流建立一个对象URL,并赋于网页的video标签以进行即时播放。
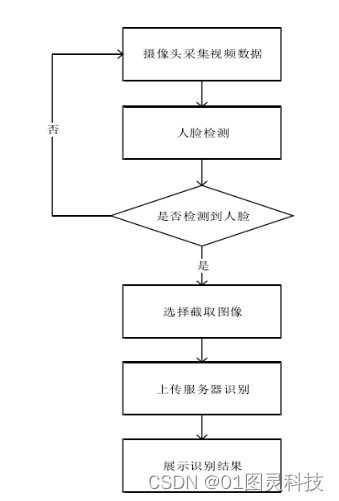
图9 图像采集模块流程
(2)人脸检测
想要提供良好的人机交互体验,有需要使用画布技术对输出视频的人脸进行测量,以及在视频上进行渲染测量到的人脸区域。人脸检测通过引入一种轻量级的javascript库tracking.Js来辅助,该库还在网页端实现了Viola-Jones人脸检测算法。通过视频流绑定检测的监控事件,不断反馈视频中人脸区域的位置,以确定人脸有没有被侦测到。
(3)图像截取
当侦测到人脸后即返回的区域位置不为空的情形下,用户也可以选择进行对人脸照片的截取,以降低数据传输时的图片尺寸,从而增加速度。视频本身并不能提供截图接口,但是我们可以使用Canvas技术实现这一功能,并利用了Canvas的drawImage()方法。
捕获视频流之后,捕获的视频图片也将展现在网页上。Web应用程序也将自动开启基于视频流的实时人脸侦测。

图13 视频人脸检测识别界面
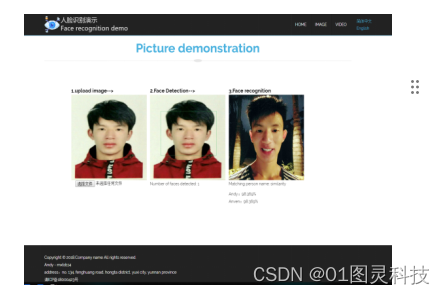
图14 图像人脸检测识别界面
结 论
对于这样的应用场景,行人属性识别已经引起了许多研究人员的注意。同时,行人属性辨识的正确性也受许多因素的影响。本文主要研究了基于深度学习的知识方法对年龄有关的认识问题的有效性。行人属性辨识应用程序都是使用web技术设计并完成的。阐述了应用流程设计目标和开发环境。详尽说明了应用程式中所有主要模块的具体实现方法,并对其功能提供了测试。该应用程序是轻量级和跨平台的,以满足行人属性识别的日常生活的要求。