HuggingFace Diffusers实战
- 1. 环境准备
- 2. DreamBooth
- 2.1 Stable Diffusion简介
- 2.2 DreamBooth
- 3. Diffusers核心API
- 4. 实战:生成美丽的蝴蝶图像
- 4.1 下载数据集
- 4.2 调度器
- 4.3 定义扩散模型
- 4.4 创建扩散模型训练循环
- 4.5 图像的生成
- 方法1.建立一个管线
- 方法2.写一个采样循环
- 5. 模型上传到Hugging Face Hub
- 6. 使用Accelerate库扩大训练模型的规模
- 参考资料
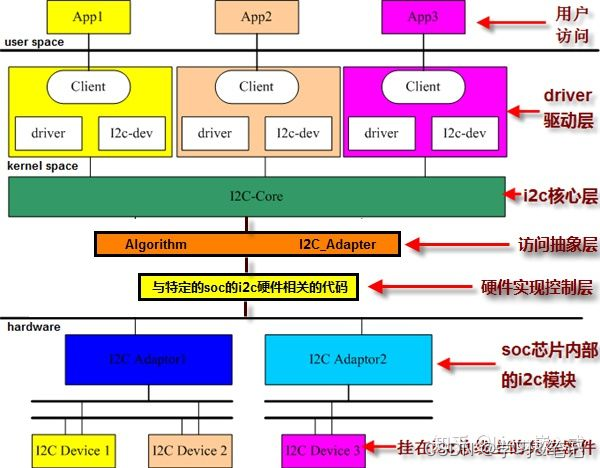
Diffusers是用于生成图像,音频甚至分子3D结构的最先进的扩散模型的首选库。无论是寻找简单的推理解决方案还是训练自己的扩散模型,Diffusers都是一个支持两者的模块化工具箱。该library 的设计侧重于性能,简单的简单性和对抽象的可定制性。
Diffusers提供了三个核心组件:
- 最先进的diffusion pipelines,只需几行代码就可以在推理中运行。
- 适用于不同扩散速度和输出质量的interchangeable schedulers。
- 可以用作构建blocks并与schedulers相结合的预训练模型,用于创建自己的端到端扩散系统。
本文学习如何使用一个功能强大的自定义扩散模型管线(pipeline),并了解如何独立制作一个新版本。学习使用Accelerate库调用多个GPU以加快模型的训练过程,并将最终模型上传到Hugging Face Hub。
1. 环境准备
安装Diffusers库:
!pip install -qq -U diffusers datasets transformers accelerate ftfy pyarrow==12.0
-
ftfy是一个用于修复和清理 Unicode 文本的 Python 软件包。它的全称是 “fixes text for you”,意思是它可以自动检测和纠正常见的 Unicode 文本问题。
Unicode 是一种字符编码标准,用于表示文本中的字符。然而,有时文本中可能会包含一些特殊字符、编码错误、乱码或不一致的字符表示方式,这可能导致文本显示或处理上的问题。ftfy 提供了一系列功能,用于自动修复这些问题,使得文本处理更加准确和一致。通过安装 ftfy 软件包,可以在 Python 中使用它提供的函数和工具来处理和修复文本中的 Unicode 问题,从而确保文本在各种应用中的正确性和可靠性。 -
Apache Arrow是一个用于内存分析的开发平台。它包含一套技术,使大数据系统能够快速存储、处理和移动数据。它提供了一种通用的数据格式,将数据在内存中表示为表格,并支持诸如序列化和分布式读取等功能。
补充:-U就是 --upgrade,意思是如果已安装就升级到最新版;-q提供的输出较少。这个选项是加性的。换句话说,最多可以使用它3次(对应于警告、错误和关键日志记录级别)。
- -q 意味着只显示带有警告、错误、关键日志级别的消息。
- -qq 意味着只显示带有错误、关键日志级别的消息。
- -qqq 意味着只显示具有关键日志级别的消息。
然后访问https://huggingface.co/settings/tokens,创建具有写权限的访问令牌:
运行如下代码使用创建的访问令牌登录Huggingface:
登录成功之后提示:Token is valid (permission: write).Your token has been saved in your configured git credential helpers (store).
Your token has been saved to /root/.cache/huggingface/token. Login successful
安装Git LFS以上传模型检查点
%%capture
!sudo apt -qq install git-lfs
!git config --global credential.helper store
补充:
- **Git LFS(Large File Storage)**是由 Atlassian, GitHub 以及其他开源贡献者开发的 Git 扩展,它通过延迟地(lazily)下载大文件的相关版本来减少大文件在仓库中的影响,具体来说,大文件是在 checkout 的过程中下载的,而不是 clone 或 fetch 过程中下载的(这意味着在后台定时 fetch 远端仓库内容到本地时,并不会下载大文件内容,而是在 checkout 到工作区的时候才会真正去下载大文件的内容)。
%%capture: Jupyter notebook中的%%capture是一個魔術指令,它允許您捕捉單個代碼單元的輸出,以便丟棄它或將其存儲在變量中以供以後使用。例如,您可以使用%%capture防止單元格中的輸出在筆記本中顯示,或捕捉單元格的輸出並將其分配給變量。
导入依赖库:
import numpy as np
import torch
import torch.nn.functional as F
import torchvision
from matplotlib import pyplot as plt
from PIL import Image
补充:PIL(Python Imaging Library)是Pythonn中最常用的图像处理库,PIL支持图像存储、显示和处理,它能够处理几乎所有图片格式,可以完成对图像的缩放、裁剪、叠加以及图像添加线条、图像和文字等操作。根据功能的不同,PIL库共包括21个与图片相关的类,这些类可以被看做是子库或PIL库中的模块,Image是最常用的类
定义两个工具函数,用于图片展示:
def show_images(x):
"""给定一批图像,创建一个网格并将其转换为PIL"""
x = x * 0.5 + 0.5
grid = torchvision.utils.make_grid(x)
grid_im = grid.detach().cpu().permute(1,2,0).clip(0,1)*255
grid_im = Image.fromarray(np.array(grid_im).astype(np.uint8))
return grid_im
def make_grid(images, size=64):
"""给定一个PIL图像列表,将他们叠加成一行"""
output_im = Image.new("RGB", (size * len(images), size))
for i, im in enumerate(images):
output_im.paste(im.resize((size, size)), (i * size, 0))
return output_im
查看GPU情况:

2. DreamBooth
2.1 Stable Diffusion简介
Stable Diffusion,是一个 2022 年发布的文本到图像潜在扩散模型,由 CompVis、Stability AI 和 LAION 的研究人员创建的。
Stable Diffusion 技术,作为 Diffusion 改进版本,通过引入隐向量空间来解决 Diffusion 速度瓶颈,除了可专门用于文生图任务,还可以用于图生图、特定角色刻画,甚至是超分或者上色任务。
下图是一个基本的文生图流程,把中间的 Stable Diffusion 结构看成一个黑盒,那黑盒输入是一个文本串“paradise(天堂)、cosmic(广阔的)、beach(海滩)”,利用这项技术,输出了最右边符合输入要求的生成图片,图中产生了蓝天白云和一望无际的广阔海滩。
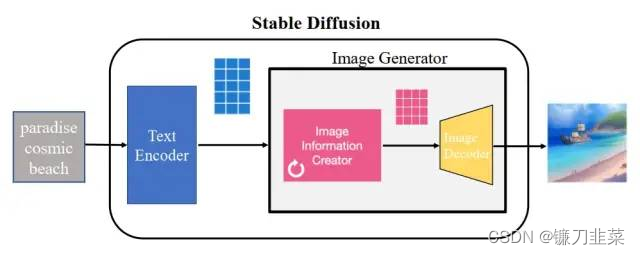
Stable Diffusion 的核心思想是,由于每张图片满足一定规律分布,利用文本中包含的这些分布信息作为指导,把一张纯噪声的图片逐步去噪,生成一张跟文本信息匹配的图片。
2.2 DreamBooth
DreamBooth是一种个性化文生图模型:给定某个物体的几张图片作为输入,通过微调预训练的文生图模型(如Imagen),将一个独特的标识符和该物体进行绑定,这样就可以通过含有该标识符的prompt在不同场景下生成包含该物体的新颖图片。

也就是说,DreamBooth能让我们对Stable Diffusion模型进行微调,并在整个过程中引入特定的面部、物体或风格的额外信息。
首先加载这个管线:
管线加载完之后,使用以下代码生成示例图像:
# 生成示例图像
prompt = "an abstract oil painting of sks mr potato head by picasso"
image = pipe(prompt, num_inference_steps=50, guidance_scale=6.5).images[0]
image

3. Diffusers核心API
Diffusers核心API主要分为三部分:
- 管线:从高层次设计的多种类函数,便于部署的方式实现,能够快速利用预训练的主流扩散模型来生成样本。
- 模型:在训练新的扩散模型时需要用到的网络结构。
- 调度器:在推理过程中使用多种不同的技巧来从噪声中生成图像,同时可以生成训练过程中所需的"带噪"图像
示例:使用管线生成蝴蝶图像:
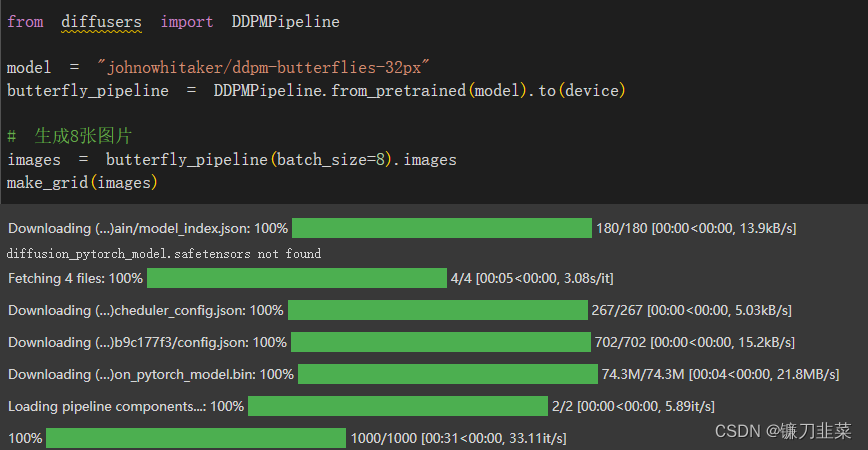
结果如下:

到目前为止,训练扩散模型的流程如下:
- 从训练集中加载图像。
- 添加不同级别的噪声
- 将添加了不同级别噪声的数据输入模型
- 评估模型对这些输入去噪的效果
- 使用得到的性能信息更新模型权重,然后重复上述步骤。
4. 实战:生成美丽的蝴蝶图像
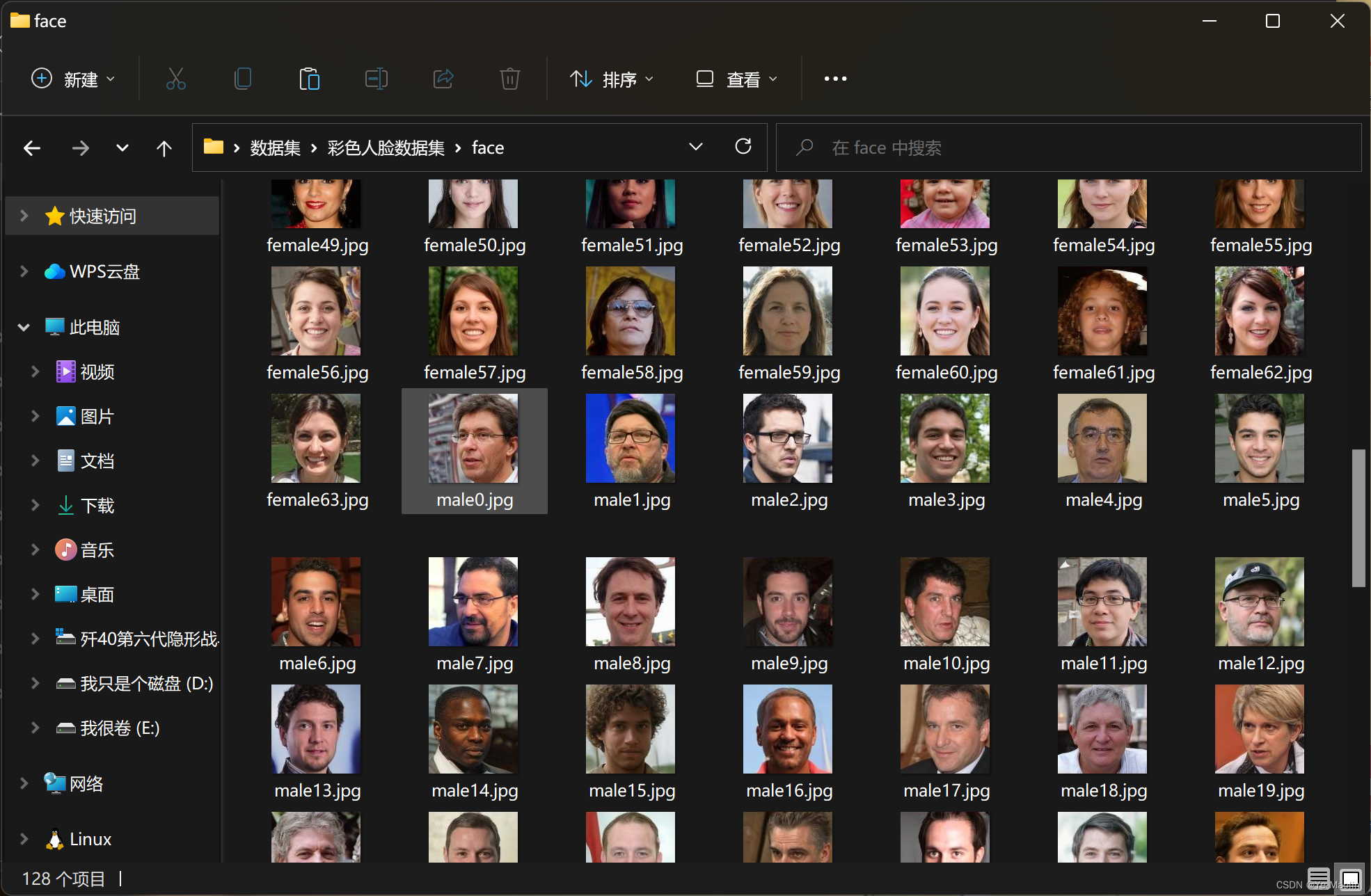
4.1 下载数据集
加载一个来自Hugging Face Hub的包含1000幅蝴蝶图像的数据集。
import torchvision
from datasets import load_dataset
from torchvision import transforms
dataset = load_dataset("huggan/smithsonian_butterflies_subset", split="train")
# 也可以从本地文件夹中加载图像
#dataset = load_dataset("imagefolder", data_dir="path/to/folder")
# 将在32×32的像素的正方形图像上进行训练
image_size=32
batch_size=64
# 定义数据增强过程
preprocess = transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5],[0.5])
])
def transform(examples):
images = [preprocess(image.convert("RGB")) for image in examples["image"]]
return {"images": images}
dataset.set_transform(transform)
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
然后从中取出一部分图像数据并可视化:

4.2 调度器
正如上文所述,在训练扩散模型中,需要获取这些输入图像并添加噪声,然后将带噪的图像输入模型。在推理阶段,使用模型的预测结果逐步消除这些噪声。在扩散模型中,这两个步骤是由调度器(scheduler)处理的。
噪声调度器能够确定在不同迭代周期分别添加多少噪声。
from diffusers import DDPMScheduler
noise_scheduler = DDPMScheduler(num_train_timesteps=1000)
基于论文“Denoising Diffusion Probabilistic Models”
通过设置beta_start、beta_end和beta_schedule 3个参数来控制噪声调度器的超参数beta。
- beta_start为控制推理阶段开始的beta值
- beta_end为控制beta的最终值
- beta_schedule可以通过一个函数映射来为模型推理的每一步生成一个beta值。
(1)仅添加了少量噪声
noise_scheduler = DDPMScheduler(num_train_timesteps=1000, beta_start=0.001, beta_end=0.004)
(2)cosine调度方式,这种方式可能更适合尺寸较小的图像
noise_scheduler = DDPMScheduler(num_train_timesteps=1000, beta_schedule='squaredcos_cap_v2')
无论选择哪个调度器,都可以使用noise_scheduler.add_noise为图片添加不同程度的噪声:
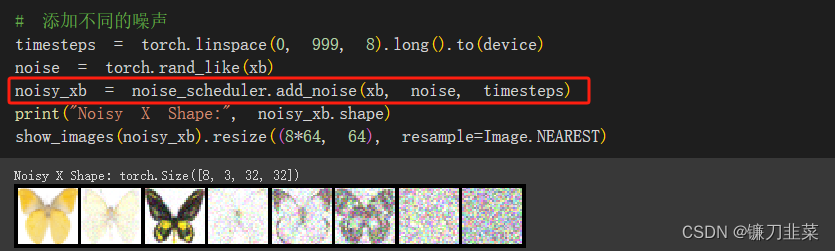
4.3 定义扩散模型
简单来说,UNet模型的工作流程如下:
- 输入UNet模型的图片会经过几个ResNet层中的标准网络模块,并且在经过每个标准网络模块后,图片的尺寸都将减半。
- 同样数量的上采样层则能够将图片的尺寸恢复到原始尺寸。
- 残差连接模块会将特征图分辨率相同的上采样层和下采样层连接起来。
UNet模型的一个关键特征是其输出图片的尺寸与输入图片的尺寸相同,而这正是扩散模型中所需要的。Diffusers提供了一个UNet2DModel类,用于在PyTorch中创建需要的结构。
from diffusers import UNet2DModel
# 创建模型
model = UNet2DModel(
sample_size=image_size,
in_channels=3,
out_channels=3,
layers_per_block=2, # 每一个UNet块中的ResNet层数
block_out_channels=(64, 128, 128, 256),
down_block_types=(
"DownBlock2D",
"DownBlock2D",
"AttnDownBlock2D", # 带有空域维度的self-att的ResNet下采样模块
"AttnDownBlock2D",
),
up_block_types=(
"AttnUpBlock2D",
"AttnUpBlock2D", # 带有空域维度的self-att的ResNet上采样模块
"UpBlock2D",
"UpBlock2D",
),
)
model.to(device);
当处理分辨率更高的图像时,尝试使用更多的上采样模块或下采样模块,并且只在分辨率最低的网络深处保留注意力模块(这是一种很特殊的网络结构,能够帮助神经网络定位特征图中最重要的部分),从而降低内存负担。
输入一批数据和随机的迭代周期数查看输出尺寸与输入尺寸是否相同:

4.4 创建扩散模型训练循环
在模型中逐批(batch)输入数据,并使用优化器一步一步更新模型的参数。每一批数据的训练流程如下:
- 随机地采样几个迭代周期
- 对数据进行相应的噪声处理
- 把”带噪“数据输入模型
- 把MSE作为损失函数,比较目标结果与模型的预测结果。
- 通过调用函数
loss.backward()和optimizer.step()来更新模型参数
# 设定噪声调度器
noise_scheduler = DDPMScheduler(num_train_timesteps=1000, beta_schedule="squaredcos_cap_v2")
# 训练循环
optimizer = torch.optim.AdamW(model.parameters(), lr=4e-4)
losses = []
for epoch in range(30):
for step, batch in enumerate(train_dataloader):
clean_images = batch["images"].to(device)
# 为图片添加采样噪声
noise = torch.randn(clean_images.shape).to(clean_images.device)
bs = clean_images.shape[0]
# 为每张图片随机采样一个时间步
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bs, ),
device=clean_images.device).long()
# 根据每个时间步的噪声幅度,向清晰的图片中添加噪声
noisy_images = noise_scheduler.add_noise(clean_images, noise, timesteps)
# 获得模型的预测结果
noise_pred = model(noisy_images, timesteps, return_dict=False)[0]
# 计算损失
loss = F.mse_loss(noise_pred, noise)
loss.backward(loss)
losses.append(loss.item())
# 迭代模型参数
optimizer.step()
optimizer.zero_grad()
if (epoch +1)%5==0:
loss_last_epoch = sum(losses[-len(train_dataloader):])/len(train_dataloader)
print(f"Epoch: {epoch + 1}, loss: {loss_last_epoch}")
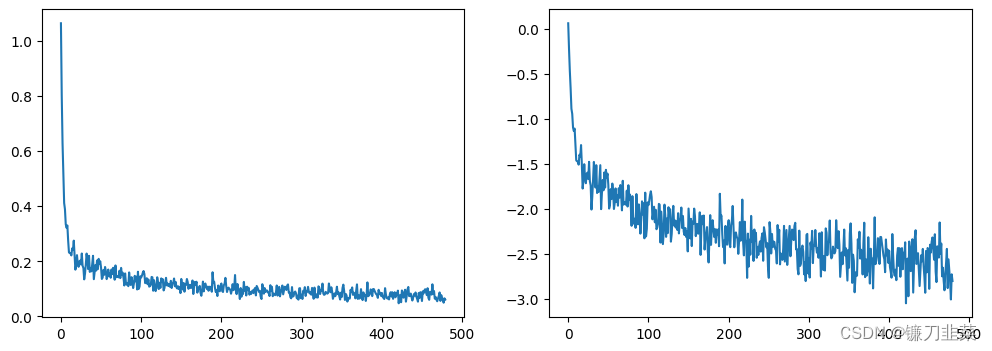
上述代码的输出结果如下:
Epoch: 5, loss: 0.15123038180172443
Epoch: 10, loss: 0.10966242663562298
Epoch: 15, loss: 0.09312395006418228
Epoch: 20, loss: 0.08648758847266436
Epoch: 25, loss: 0.08505138801410794
Epoch: 30, loss: 0.06794926035217941
绘制损失曲线:
fig, axs = plt.subplots(1, 2, figsize=(12, 4))
axs[0].plot(losses)
axs[1].plot(np.log(losses))
plt.show()
另一种使用管线中模型的方法:
model = butterfly_pipeline.unet
4.5 图像的生成
方法1.建立一个管线
代码如下:
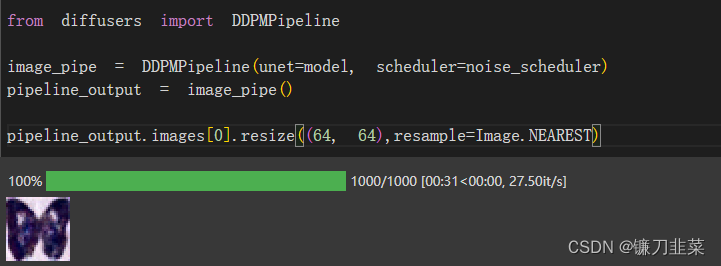
将管线保存到本地文件夹中:
image_pipe.save_pretrained("my_diffusion_pipeline")
检查本地文件夹中的内容:
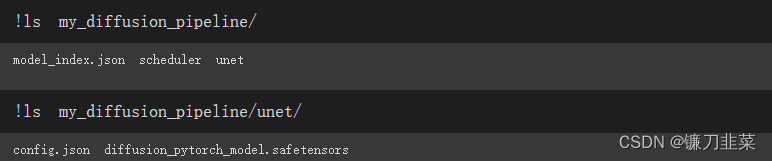
scheduler与unet子文件夹包含了生成图像所需的全部组件。比如在unet子文件夹可以看到模型参数文件diffusion_pytorch_model.safetensors与描述模型结构的配置文件config.json。这两个文件包含了重建管线所需要的所有内容。可以手动将这两个文件上传到Hugging Face Hub,以便和他人共享管线,或者通过API检查代码来实现这个操作。
方法2.写一个采样循环
从完全随机的带噪图像开始,从最大噪声往最小噪声方向运行调度器并根据模型每一步的预测去去除少量噪声:
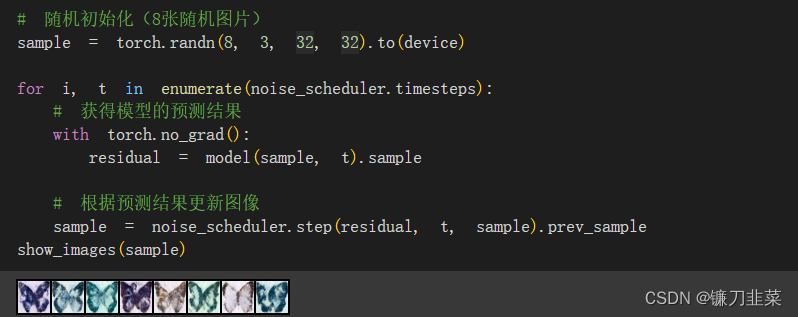
noise_scheduler.step方法可以执行更新“样本”所需的数学运算。
5. 模型上传到Hugging Face Hub
Hugging Face Hub根据指定的模型ID来决定模型存储库的名称,代码如下:
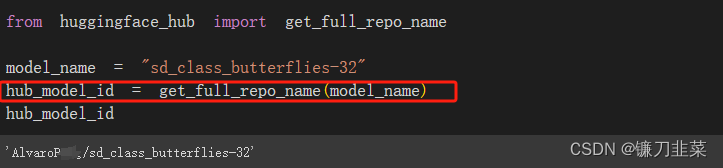
接下来,在Hugging Face Hub上创建一个模型仓库并将其上传,代码如下:
然后还可以通过以下代码创建一个精美的模型卡片:
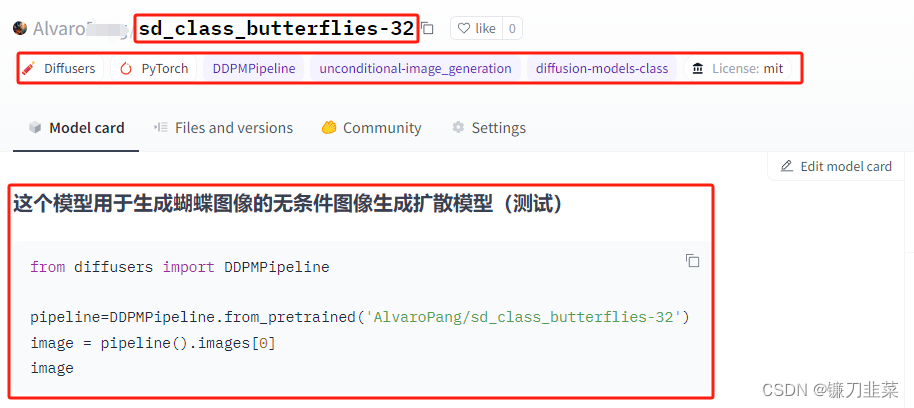
这里,我们登录Hugging Face,查看刚才上传的模型
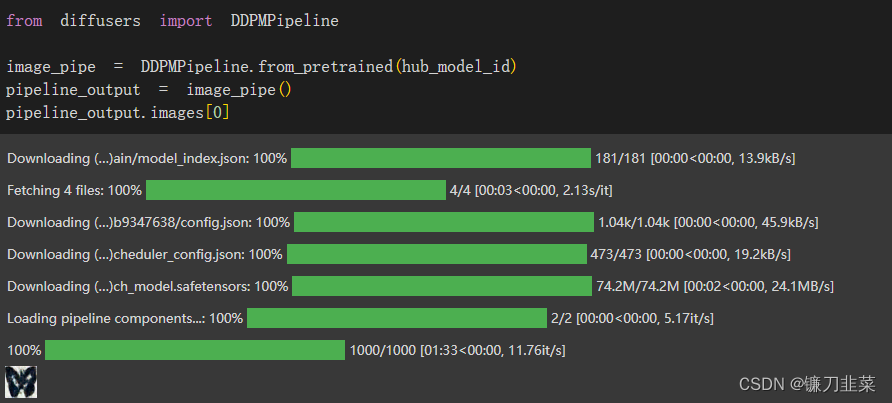
现在通过如下代码从任何地方使用DDPMPipeline的from_pretrained方法来下载该模型:
6. 使用Accelerate库扩大训练模型的规模
Accelerate是一个库,只需添加四行代码,就可以在任何分布式配置中运行相同的PyTorch代码。简而言之,大规模的训练和推理变得简单、高效和适应性强。
给新模型取个名字:

执行以下代码,通过Accelerate库启动这个脚本。Accelerate库可以自动帮助完成诸如多GPU并行训练的训练部署功能:
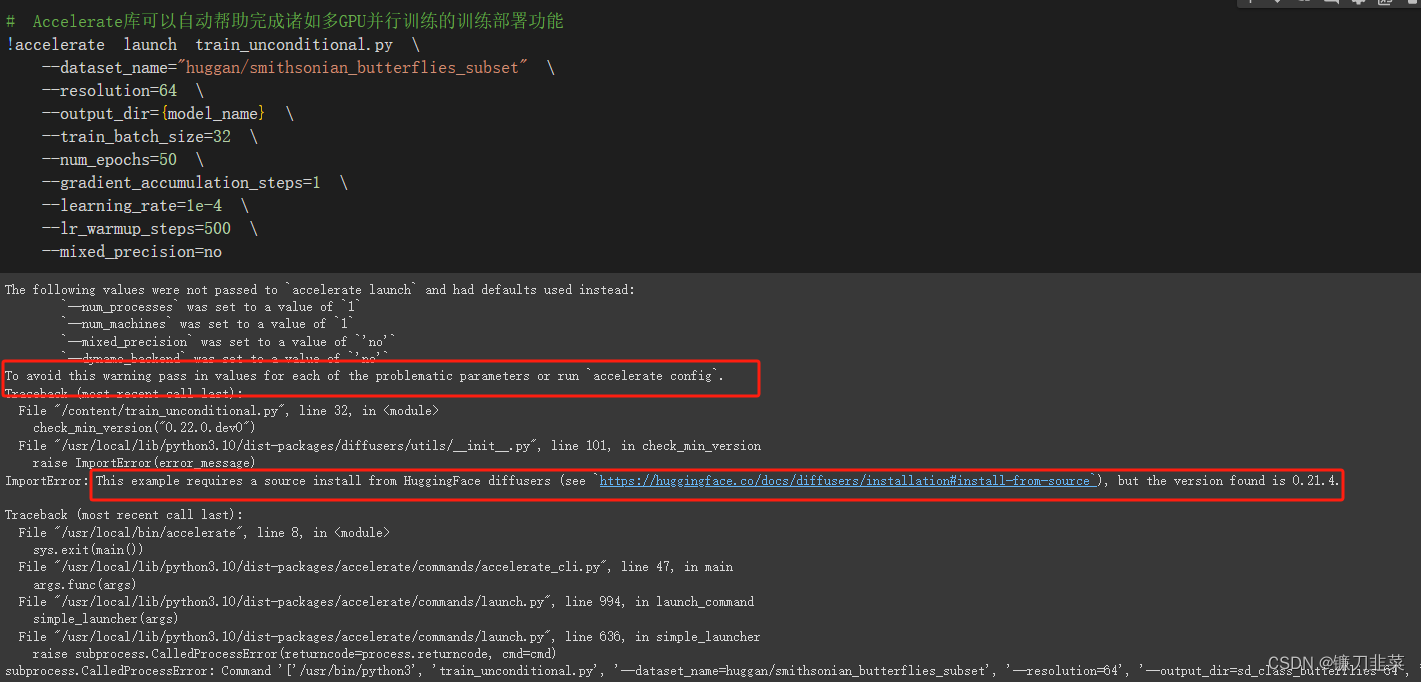
显然,这里报错了,通过分析错误信息,我们可以看到:This example requires a source install from HuggingFace diffusers (see https://huggingface.co/docs/diffusers/installation#install-from-source), but the version found is 0.21.4.
所以,我们要通过git clone安装diffusers源码:
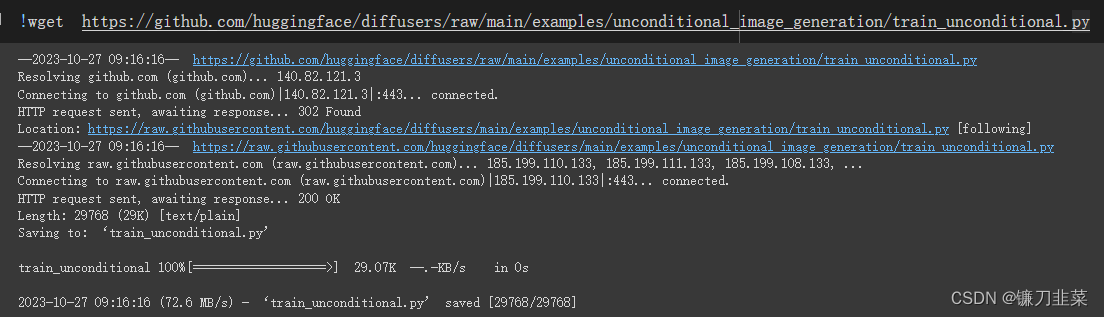
!git clone https://github.com/huggingface/diffusers.git
!pip install diffusers/
!pip install -r diffusers/examples/unconditional_image_generation/requirements.txt
然后再去执行accelerate脚本:
!accelerate config
!accelerate launch train_unconditional.py \
--dataset_name="huggan/smithsonian_butterflies_subset" \
--resolution=64 \
--output_dir={model_name} \
--train_batch_size=32 \
--num_epochs=50 \
--gradient_accumulation_steps=1 \
--learning_rate=1e-4 \
--lr_warmup_steps=500 \
--mixed_precision=no
执行结果:
Epoch 1: 100% 32/32 [00:33<00:00, 1.06s/it, loss=0.402, lr=1.28e-5, step=64]
Epoch 2: 100% 32/32 [00:31<00:00, 1.03it/s, loss=0.152, lr=1.92e-5, step=96]
Epoch 3: 100% 32/32 [00:27<00:00, 1.16it/s, loss=0.0663, lr=2.56e-5, step=128]
Epoch 4: 94% 30/32 [00:28<00:02, 1.22s/it, loss=0.0987, lr=3.16e-5, step=158]
......
然后与之前一样,把模型push到Hugging Face Hub并创建一个模型卡片:
# 把模型push到Hugging Face Hub
create_repo(hub_model_id)
api = HfApi()
api.upload_folder(
folder_path=f"{model_name}/scheduler",
path_in_repo="",
repo_id=hub_model_id
)
api.upload_folder(
folder_path=f"{model_name}/unet/",
path_in_repo="",
repo_id=hub_model_id
)
api.upload_file(
path_or_fileobj=f"{model_name}/model_index.json",
path_in_repo="model_index.json",
repo_id=hub_model_id
)
content=f"""
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image_generation
- diffusion-models-class
---
# 这个一个无条件图像生成扩散模型(测试),用于生成美丽的蝴蝶图像
```python
from diffusers import DDPMPipeline
pipeline=DDPMPipeline.from_pretrained('{hub_model_id}')
image = pipeline().images[0]
image
推动到Hugging Face
card=ModelCard(content)
card.push_to_hub(hub_model_id)
使用这个模型:
pipeline = DDPMPipeline.from_pretrained(hub_model_id).to(device)
images = pipeline(batch_size=8).images
make_grid(images)
在了解各种模型之前,有必须先了解下 safetensors,玩过的应该都认识,就是很多模型的后缀。然而各种模型的后缀五花八门,但是总是能看到 safetensors 的影子,让人有些缭乱。其实主要是因为 safetensors 支持各种 AI 模型,而在 safetensors 出现前,各种 AI 模型都有着自己独特的后缀。这就导致每种模型既可以使用 safetensors 又可以使用自己原有的后缀,所以入门的时候就会让人有点分不清。
其实 safetensors 是由 huggingface 研发的一种开源的模型格式,它有几种优势:
- 足够安全,可以防止 DOS 攻击
- 加载迅速
- 支持懒加载
- 通用性强
所以现在大部分的开源模型都会提供 safetensors 格式。
参考资料
- Diffuser Github
- PyArrow - Apache Arrow Python bindings
- 详解 Git 大文件存储(Git LFS)
- Jupyter notebook裡面的「%%capture」是什麼意思?
- PIL库介绍
- 十分钟读懂Stable Diffusion运行原理
- DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
- 用AI把自己画进动漫里,3天揽获150万+播放量
- Accelerate







](https://img-blog.csdnimg.cn/ab2a850e96a44b7d83ae1ea24ed65386.png)