文章目录
- 一:DataLoader,、DataSet、Sampler三者的关系
- 二:DataLoader,、DataSet、Sampler详解
- (1)Dataset
- A:基本介绍
- C:Pytroch内置数据集
- (2)Sampler
- A:SequentialSampler(顺序采样)
- B:RandomSampler
- C:SubsetRandomSampler(重要)
- (3)Dataloader
注意:本文会用到一个txt数据,有1372个,5个维度(前4个维度为输入,最后1个维度为预测输出)
- 下载链接
3.6216,8.6661,-2.8073,-0.44699,0
4.5459,8.1674,-2.4586,-1.4621,0
3.866,-2.6383,1.9242,0.10645,0
3.4566,9.5228,-4.0112,-3.5944,0
0.32924,-4.4552,4.5718,-0.9888,0
4.3684,9.6718,-3.9606,-3.1625,0
3.5912,3.0129,0.72888,0.56421,0
....
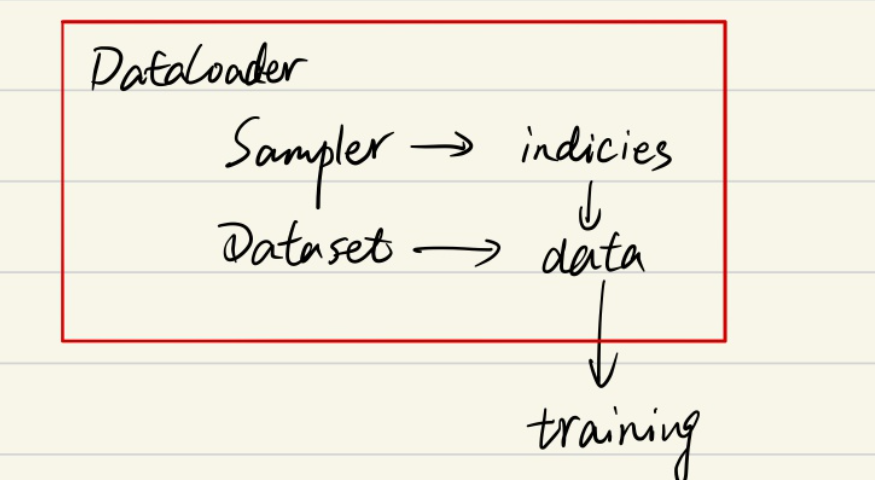
一:DataLoader,、DataSet、Sampler三者的关系
Pytorch对于数据集的处理,有三个非常重要的类,它们都位于torch.utils.data下
-
Dataset:是数据集的类,主要用于定义数据集,也即数据来源- 例如 :你的数据是最简单的txt文件,那么在加载时你必须把这个txt封装为一个类,才可以由
DataLoader加载(后面举例)
- 例如 :你的数据是最简单的txt文件,那么在加载时你必须把这个txt封装为一个类,才可以由
-
Sampler:是采样器,用于从数据集中选出数据(Sampler会返回数据集的索引indicies,然后Dataloader通过indicies选取数据) -
Dataloader:专门用于数据加载的类,其中上面的Dataset和Sampler会作为参数传递给Dataloader。在训练、测试时数据将直接由Dataloader得到,例如- 加载训练集:
trainloader = Dataloader(dataset = trainDataset, sampler = train_sampler) - 加载验证集:
valloader = Dataloader(dataset = valDataset, sampler = val_sampler) - 加载测试集:
testloader= Dataloader(dataset = testDataset, sampler = test_sampler)
- 加载训练集:
三者关系如下图所示
二:DataLoader,、DataSet、Sampler详解
(1)Dataset
A:基本介绍
Dataset 位于 torch.utils.data 下,我们需要通过继承Dataset 类来定义自己的数据集MyDataset。MyDataset这个类至少要重写以下两个方法
-
__getitem__(self, idx):重写该函数后,你的MyDataset的实例mydataset就可以像Python的基本类型那样进行索引操作了,也即mydataset[idx] -
__len__(sef):重写该函数后,你的MyDataset的实例mydataset就可以像Python的基本类型那样由len获取长度,也即len(mydataset)
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self):
...
def __getitem__(self, index):
return ...
def __len__(self):
return ...
以前文中给定的那个txt数据为例,进行封装
import torch
from torch.utils.data import DataLoader
from config import parameters # config文件是我用来保存参数的文件,可忽略
import numpy as np
class MyDataset(torch.utils.data.Dataset):
def __init__(self, data_path):
self.dataset = np.loadtxt(data_path, delimiter=',')
# 一般需要把数据集“洗牌”一下
np.random.shuffle(self.dataset)
def __getitem__(self, idx):
item = self.dataset[idx]
# 前四个维度为输入X
# 后1个维度为输出y
X, y = item[:parameters.in_features], item[parameters.in_features:]
"""
在进行返回时需要一些处理,例如
to(parameters.device):会把数据送到CPU或GPU
squeeze():会把维度为1的那个维度去掉
"""
return torch.Tensor(X).float().to(parameters.device), \
torch.Tensor(y).squeeze().long().to(parameters.device)
# 返回数据的个数
def __len__(self):
return np.shape(self.dataset)[0]
将1372条数据按照7:2:1的比例划分为训练集、验证集和测试集,分别对应如下文件
train.txt:路径为parameters.trainset_pathval.txt:路径为parameters.valset_pathtest.txt:路径为parameters.testset_path
import numpy as np
from config import parameters
import os
# 训练集、验证集和测试集划分比例
trainset_ratio = 0.7
valset_ratio = 0.2
test_set = 0.1
# 设置随机种子,读取源数据并打乱
np.random.seed(parameters.seed)
dataset = np.loadtxt(parameters.data_path, delimiter=',')
np.random.shuffle(dataset)
# 样本数量
n_items = np.shape(dataset)[0]
# 划分数据
trainset = dataset[:int(trainset_ratio*n_items), ]
valset = dataset[int(trainset_ratio*n_items):int(trainset_ratio*n_items)+int(valset_ratio*n_items), :]
testset = dataset[int(trainset_ratio*n_items)+int(valset_ratio*n_items):, ]
# 存储
np.savetxt(os.path.join(parameters.data_dir, 'train.txt'), trainset, delimiter=',')
np.savetxt(os.path.join(parameters.data_dir, 'val.txt'), valset, delimiter=',')
np.savetxt(os.path.join(parameters.data_dir, 'test.txt'), testset, delimiter=',')
测试如下,当我们传入的数据不同,就会生成不同的MyDataset实例
if __name__ == '__main__':
myDataset_train = MyDataset(parameters.trainset_path) # 训练数据集
myDataset_val = MyDataset(parameters.valset_path) # 验证数据集
myDataset_test = MyDataset(parameters.testset_path) # 测试数据集
print("训练集长度:", len(myDataset_train))
print("验证集长度:", len(myDataset_val))
print("测试集长度:", len(myDataset_test))
"""
数据集封装好之后,可由Dataloader加载,这里第一个参数dataset便是
你的MyDataset实例,传入即可
bathsize会将你的训练集数组按照每组16个进行分割
每次从traninloader中读取16个数据
(Dataloader其余参数战术不管)
"""
trainloader = DataLoader(dataset=myDataset_train, batch_size=16, shuffle=True, drop_last=True)
for batch in trainloader :
X, y = batch
print(X)
print(y)
break
如下图
len(myDataset_train):本质是在调用__len__(self)X, y = batch:本质是在调用__getitem__(self, idx)

C:Pytroch内置数据集
在Pytorch中内置了很多常用的数据集,这些数据集已经被封装好了,所以无需你手动封装,直接可以用Dataloader加载。主要有以下几种
-
torchvision.datasets:提供了许多计算机视觉方面的数据集。torchvision是Pytorch的一个图形库,主要用来构建计算机视觉模型,非常重要,会在后续文章中详细介绍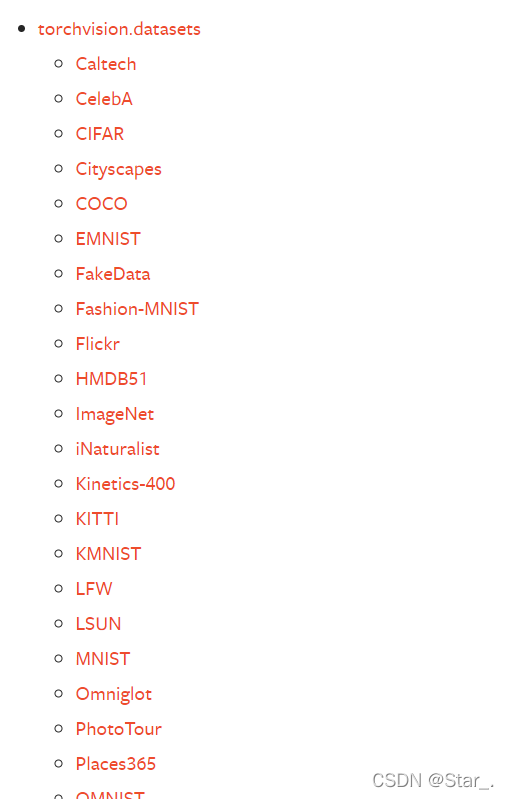
-
torchtext:提供了很多文本处理方向的数据集 -
torchaudio:提供了很多音频处理方向的数据集
例如,以MNIST数据集为例,导入后直接可以被Dataloader加载
- 注意:下面的一些参数如果不了解可以暂时忽略,只看整体逻辑即可
# 原始数据训练数据
train_set = torchvision.datasets.MNIST(
root='./data/',
train=True,
transform=transforms.ToTensor(),
download=False
)
# 测试集
test_set = torchvision.datasets.MNIST(
root='./data/',
train=False,
transform=transforms.ToTensor(),
download=False
)
train_loader = DataLoader(train_set, batch_size=64, drop_last=True)
test_loader = DataLoader(test_set, batch_size=64, drop_last=False)
(2)Sampler
Sampler位于torch.utils.data下,和Dataloader一样,也需要重写Sampler类,但Pytorch中已经为我们实现了很多非常实用的Sampler子类,所以我们使用它们足矣。以下三个较常用
from torch.utils.data import sampler
sampler.RandomSampler:随机采样
sampler.SequentialSampler:顺序采样
sampler.BatchSampler:批采样
Sampler返回的是索引,Dataloader会根据该索引到Dataset中选取数据
A:SequentialSampler(顺序采样)
SequentialSampler会按照顺序进行采样,接受一个可迭代对象作为参数。SequentialSampler在被遍历时,遍历的就是采样后的索引
例如,对于之前的那个txt数据
from torch.utils.data import sampler
myDataset= MyDataset(parameters.data_path)
print(len(myDataset))
SequentialSampler = sampler.SequentialSampler(myDataset)
for index in SequentialSampler :
print(index, myDataset[index])
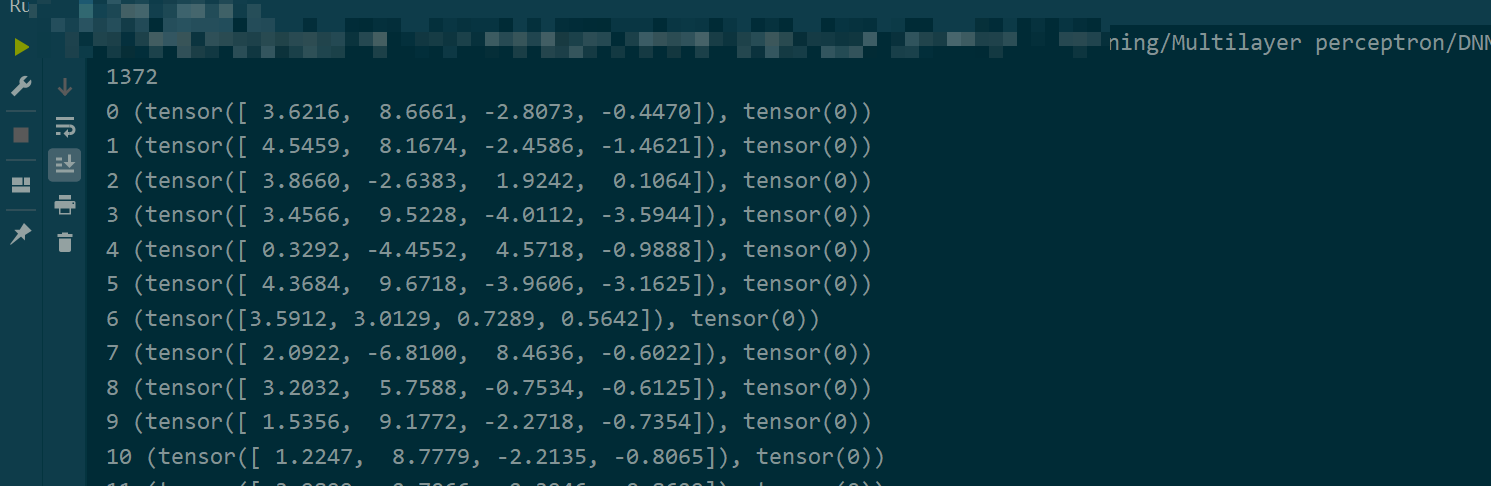
实际使用时,SequentialSampler或其他采样器将作为参数传递到Dataloader中的sampler,所以我们在采样时一般会给一个简单的数字列表,范围为待采样数据集长度
myDataset= MyDataset(parameters.data_path)
# 0 ~ 1371
index_list = list(range(myDataset))
# 采样
SequentialSampler = sampler.SequentialSampler(index_list)
dataloader = DataLoader(bankfakedataset, batch_size=16, sampler=SequentialSampler , drop_last=True)
B:RandomSampler
RandomSampler 进行随机采样,接受一个可迭代对象作为参数,其他参数含义为
replacement:默认为False,表示不放回采样num_samples:当replacement=True时才能设置此参数,表示要采出的样本个数
myDataset = BankfakeDataset(parameters.data_path)
print(len(myDataset))
index_list = list(range(myDataset))
RandomSampler = sampler.RandomSampler(index_list )
for index in RandomSampler:
print(index, myDataset[index])
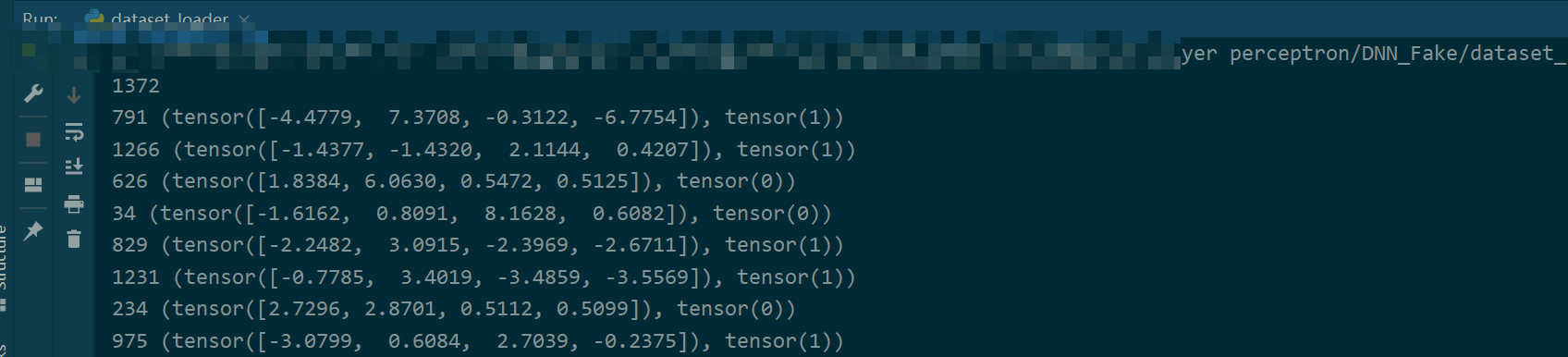
C:SubsetRandomSampler(重要)
SubsetRandomSampler可以设置子集的随机采样
# 100个数据的索引
index_list = list(range(10))
# 切片,分为0~6和7-9这两个部分
index_list1 = list(index_list[:7])
index_list2 = list(index_list[7:])
subRandomSampler1 = sampler.SubsetRandomSampler(index_list1)
subRandomSampler2 = sampler.SubsetRandomSampler(index_list2)
for index in subRandomSampler1:
print(index, end=' ')
print()
for index in subRandomSampler2:
print(index, end=' ')

SubsetRandomSampler多用于数据集的划分,例如划分为训练集、验证集和测试集,使用非常频繁
例如对于之前的那个txt数据,我们在加载之前是直接把原始数据分为了3个文件。这里我们改用采样的方式进行,直接在原始数据集上进行SubsetRandomSampler
myDataset = BankfakeDataset(parameters.data_path)
myDataset_num = len(myDataset)
print('原数据集长度', myDataset_num)
index_list = list(range(myDataset_num))
# 按照7:2:1的比例进行划分
train_num = int(0.7 * myDataset_num)
val_num = int(0.2 * myDataset_num)
train_index = index_list[: train_num]
val_index = index_list[train_num : train_num + val_num]
test_index = index_list[train_num+val_num :]
# 分别采样
train_sampler = sampler.SubsetRandomSampler(train_index)
val_sampler = sampler.SubsetRandomSampler(val_index)
test_sampler = sampler.SubsetRandomSampler(test_index)
# 查看区间范围
print('(', min(train_sampler), max(train_sampler), ')')
print('(', min(val_sampler), max(val_sampler), ')')
print('(', min(test_sampler), max(test_sampler), ')')
# 通过原数据根据sampler加载数据
trainloader = DataLoader(myDataset, batch_size=16, sampler=train_sampler, drop_last=False)
valloader = DataLoader(myDataset, batch_size=16, sampler=val_sampler, drop_last=False)
testloader = DataLoader(myDataset, batch_size=16, sampler=test_sampler, drop_last=False)
print(len(trainloader)) # 960 / 16
print(len(valloader)) # 274 / 16
print(len(testloader)) # 138 / 16

这里还要补充一点,对于torchvision.datasets下的数据集,它只会给你训练集和测试集。如下,以MNIST数据集为例,如果train=True则加载训练集,反之加载测试集。但有时我们还需要一个验证集,所以可以通过采样的方式对测试集再次划分,示例如下
from torch.utils.data import sampler
from torch.utils.data import DataLoader
import torchvision.datasets as dataset
import torchvision.transforms as transforms
# 按照80%的训练数据和20%的验证数据拆分原始训练数据,得到sampler
split_num = int(60000 * 0.8)
index_list = list(range(60000))
train_index, val_index = index_list[:split_num], index_list[split_num:]
train_sampler = sampler.SubsetRandomSampler(train_index)
val_sampler = sampler.SubsetRandomSampler(val_index)
# 原始数据训练数据
train_set = dataset.MNIST(
root='./data/',
train=True,
transform=transforms.ToTensor(),
download=False
)
# 测试集
test_set = dataset.MNIST(
root='./data/',
train=False,
transform=transforms.ToTensor(),
download=False
)
if __name__ == '__main__':
train_loader = DataLoader(train_set, sampler=train_sampler, batch_size=1, drop_last=True)
val_loader = DataLoader(train_set, sampler=val_sampler, batch_size=1, drop_last=False)
print(len(train_loader))
print(len(val_loader))

(3)Dataloader
Dataloader对Dataset、Sampler等进行打包,完成数据的读取和执行工作,其参数如下,其中dataset为必须参数,其余为可选参数
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)
常用参数含义如下
-
dataset:传入一个Dataset实例 -
batch_size:指定每一个batch包含的样本数量- 什么是
batch?:训练时不能把整个数据集全部送入模型中训练,那样内存和显存会吃不消,所以对于我们会将其分为多个batch,一次只送入一个batch进行训练,这里的batch数目最好为2的n次方,例如16,表示一个batch中有16条样本数据 - 类型:
int - 默认:1
- 什么是
-
shuffle:在每个epoch开始时,会对数据集进行“洗牌”操作,也即重新打乱顺序- 什么是epoch?:当数据集中的全部数据样本通过神经网络一次并且返回一次的过程即完成一次训练称为一个
epoch - 类型:
bool - 默认值:
False
- 什么是epoch?:当数据集中的全部数据样本通过神经网络一次并且返回一次的过程即完成一次训练称为一个
-
sampler:传入一个自定义的Sampler实例,定义从Dataset中取数据的策略,Sampler会返回一个索引- 默认值:
None
- 默认值:
-
batch_sampler:也是传入一个自定义的Sampler实例,但与sampler参数不同的是,它接受的Sampler是一次返回一个batch的索引- 默认值:
None
- 默认值:
-
num_workers:定义有多少个线程来处理数据,数值越大,训练速度越快- 注意:此参数要根据你CPU、GPU、内存等信息来设定,性能不行,值再高也没效果
- 类型:
int - 默认:0,此时意味着所有的数据都会被加载进主进程
-
collate_fn:传入一个函数,其作用是将一个batch的样本打包为一个大的tensor,该tensor的第一维就是这些样本。没有特殊需求此参数无需设置 -
pin_mermory:如果为True,表示将加载的数据拷贝至CUDA的固定内存中,可以提升模型的训练速度- 类型:
bool - 默认:
False
- 类型:
-
drop_last:设置batch_size往往会导致数据集无法完整分为若干个batch,比如数据集长度为1000,如果batch_size设置为了64,那么前15个batch中每个batch都有64条数据,最后一个batch只有40条数据。因此如果drop_last设置为了true,那么Dataloader将不会加载最后一个batch -
注意:对于训练集一般会设置为
True,对于验证集和测试集一般会设置为False- 类型:
bool - 默认:
False
- 类型:
-
timeout:表示加载一个batch的最大等待时间,如果超出该时间还没有加载完毕,就放弃这个batch- 类型:
int(>=0) - 默认:0
- 类型: