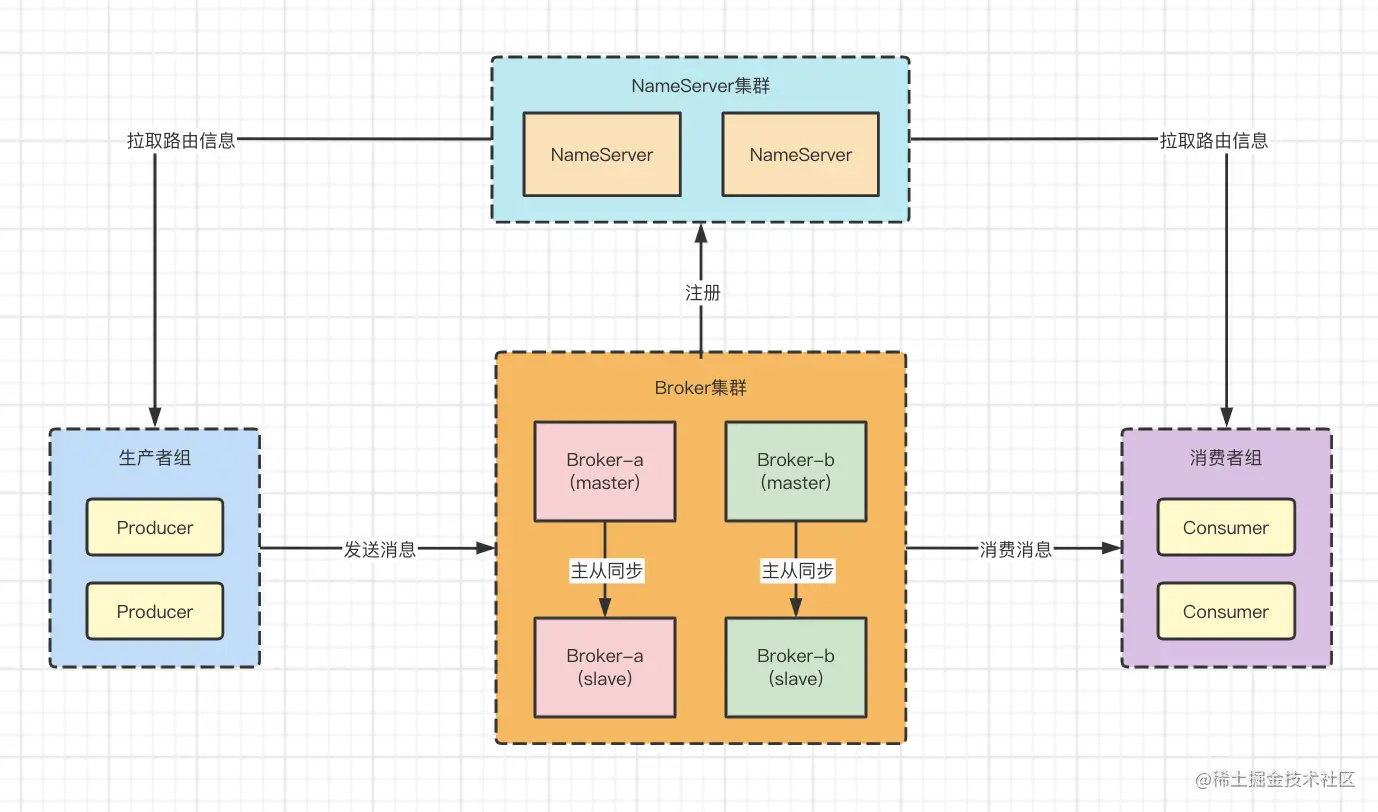
一、源码分析
/**
* 读取ident
* 这里的 ident 指标识符(identifier),也就是通常意义上的变量名
* 这里默认的变量名规则为:由美元符号($)、数字、字母或者下划线(_)构成的字符串
*
* @inner
* @param {Walker} walker 源码读取对象
* @return {string}
*/
function readIdent(walker) {
var match = walker.match(/\s*([\$0-9a-z_]+)/ig, 1)
, 1);
// #[begin] error
if (!match) {
throw new Error('[SAN FATAL] expect an ident: ' + walker.source.slice(walker.index));
}
// #[end]
return match[1];
}
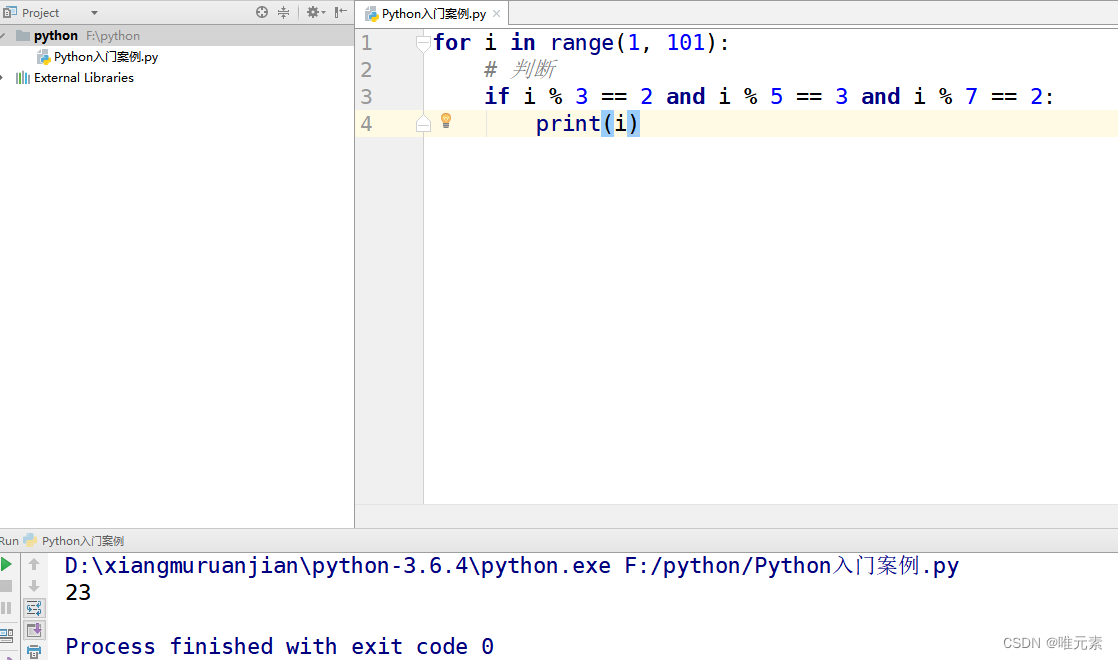
readIdent 函数用来匹配 template 中用到的变量名(如下图)
首先用到了 walk 类中的 match 函数,该函数源码如下(这里不是 walk 类全部代码而是列出了本次用到的代码)
/**
* 字符串源码读取类,用于模板字符串解析过程
*
* @class
* @param {string} source 要读取的字符串
*/
function Walker(source) {
this.source = source; // 存储要解析的模版字符串
this.len = this.source.length; // 获得字符串长度
this.index = 0; // 初始话当前指针位置
}
/**
* 向前读取符合规则的字符片段,并返回规则匹配结果
*
* @param {RegExp} reg 字符片段的正则表达式
* @param {boolean} isMatchStart 是否必须匹配当前位置
* @return {Array?}
*/
Walker.prototype.match = function (reg, isMatchStart) {
reg.lastIndex = this.index; // 指定下一次匹配的起始索引
// 如果匹配成功,exec() 方法返回一个数组,并更新正则表达式对象的 lastIndex 属性。完全匹配成功的文本将作为返回数组的第一项,从第二项起,后续每项都对应一个匹配的捕获组。
var match = reg.exec(this.source);// exec() 可用来对单个字符串中的多次匹配结果进行逐条的遍历(包括捕获到的匹配),而相比之下, String.prototype.match() 只会返回匹配到的结果。
if (match && (!isMatchStart || this.index === match.index)) {
this.index = reg.lastIndex; // 更新下次匹配的起始索引
return match;
}
};
match 函数中主要用到了 exec 函数来进行正则表达式匹配,match 函数中需要注意一下几点
- 开始匹配之前对 lastIndex 进行赋值,在进行循环匹配时就形成了向前移动的指针。在每次匹配时开始的位置,
- isMatchStart 是一个必须匹配当前位置标识。当 isMatchStart 为 false 时,或者通过取反操作为 false时,就进行当前index和match.index进行相等比较,只有两者相等才可以是匹配当前位置,而其中 match.index 为‘匹配到的字符位于原始字符串的基于 0 的索引值’,this.index 在匹配的过程中也是动态更新的,所以可以使用两个值做比较。
在san中变量名由美元符号($)、数字、字母或者下划线()构成,为了匹配变量名给出如下正则表达式
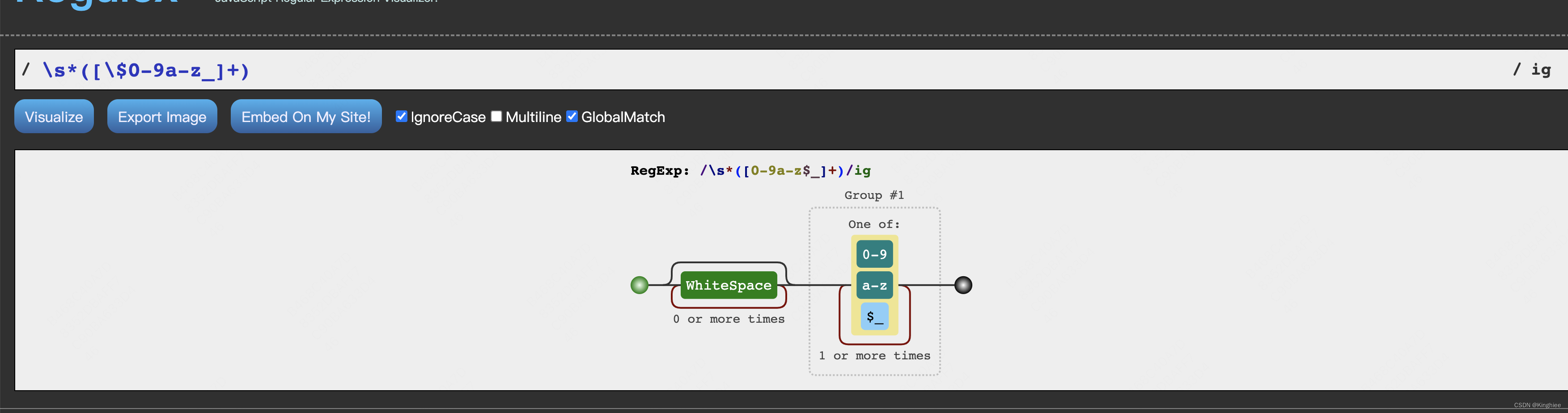
上图可以看出变量名是如何匹配的,在 match 中 isMatchStart 表示为已经开启。为啥开启呐?下面看一下/\s*([$0-9a-z]+)/ig,正则表达式如何匹配变量的
正确的变量命名
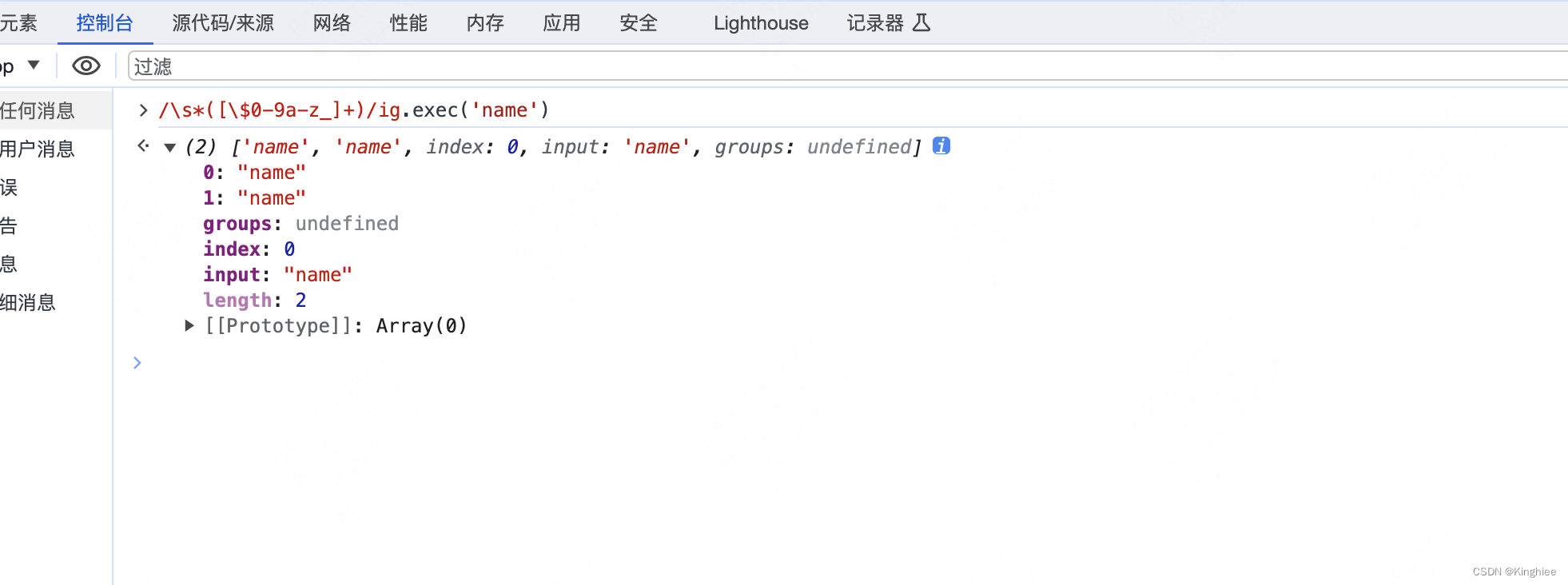
正确的变量命名它的index是从 0 开始的

不正确的变量命名是不是从 0 开始,也就是说 match.index 和 this.index 不相等。
注意:本例子中index是从0开始,在其他相关中可能不一样,但是如果isMatchStart标识开启了,那么match.index 和 this.index 必须相等
如果没有匹配到,则报错。如果匹配到就返回 match[1]即匹配到的值。
这里需要知道的是为啥是match[1] 而不是 match[0] 或者 [2]?这是因为 当exec 函数匹配成功,exec() 方法返回一个数组,并更新正则表达式对象的 lastIndex 属性。完全匹配成功的文本将作为返回数组的第一项,从第二项起,后续每项都对应一个匹配的捕获组。那么什么是捕获组呐?可以简单为正则表达式中使用括号‘()’括起来的就是一个捕获组,在匹配变量名表达式中可以看出([$0-9a-z_]+)是。所以是 match[1]