文章目录
- 前言
- 0x1 虚拟机保护技术原理
- 0x1A 关于调用约定
- 0x1B Handler
- 0x1C 指令
- 0x2 vm虚拟机逆向 实战[GKCTF 2020]EzMachine
- 题目分析,花指令去除
- Handler分析
- 脚本编写
前言
关于虚拟机逆向的知识网上很少,我看了几篇感觉都看不太明白,最后还是想起自己有本《加密与解密》(大坑a);书中的第20章 虚拟机的设计,第21章 VMProtect 逆向和还原浅析(完全看不懂还);结合网上的几篇文章特此学习,顺带记录分享一下。
书中暂时还不能理解的诸如20.4托管代码的异常处理的内容我就没有记录下来(留待以后继续探索),希望目前整理的部分笔记可以对你有所帮助,有不明白的地方欢迎评论私信交流,求大佬指定。
**注:**写完文章后,自己又看了一篇0x1的内容,发现好像学不到什么,如果想看VM逆向过程的可以直接看0x2的内容,我写的很详细了,下一篇应该会专门再出几道vm re的详细wp,练习一下,真的累a。
0x1 虚拟机保护技术原理
关于这里讨论的虚拟机和VMware之类的虚拟机是不同的东西,它是一种基于虚拟机的代码保护技术,准确地说,这里讨论的虚拟机是一种解释执行系统(例如Visual Basic 6 中的PCODE编译方式)。现在的一些动态语言(例如Ruby、Python、Lua和.NET等)从某种角度来说也是解释执行的。
Visual Basic 6 中的PCODE(P-Code,也称为Pseudo Code)编译方式是一种中间代码编译方法,用于将Visual Basic代码编译成中间代码,而不是直接生成本机机器代码。这种中间代码可以在运行时由VB6的解释器执行。
Python字节码是Python程序的一种中间表示形式,类似于P-Code或Java字节码。可见python字节码详解,Bytecode反编译过程
虚拟机保护技术就是将基于x86汇编系统的可执行代码转换为字节码指令系统的代码,以达到保护原有指令不被轻易逆向和篡改的目的。
这种指令执行系统和Intel的x86指令系统不在同一个层次中。例如,80x86汇编指令是在CPU里执行的,而字节码指令系统是通过解释指令执行的(这里的字节码指令系统是建立在x86指令系统上的)。
虚拟机执行时的情况:
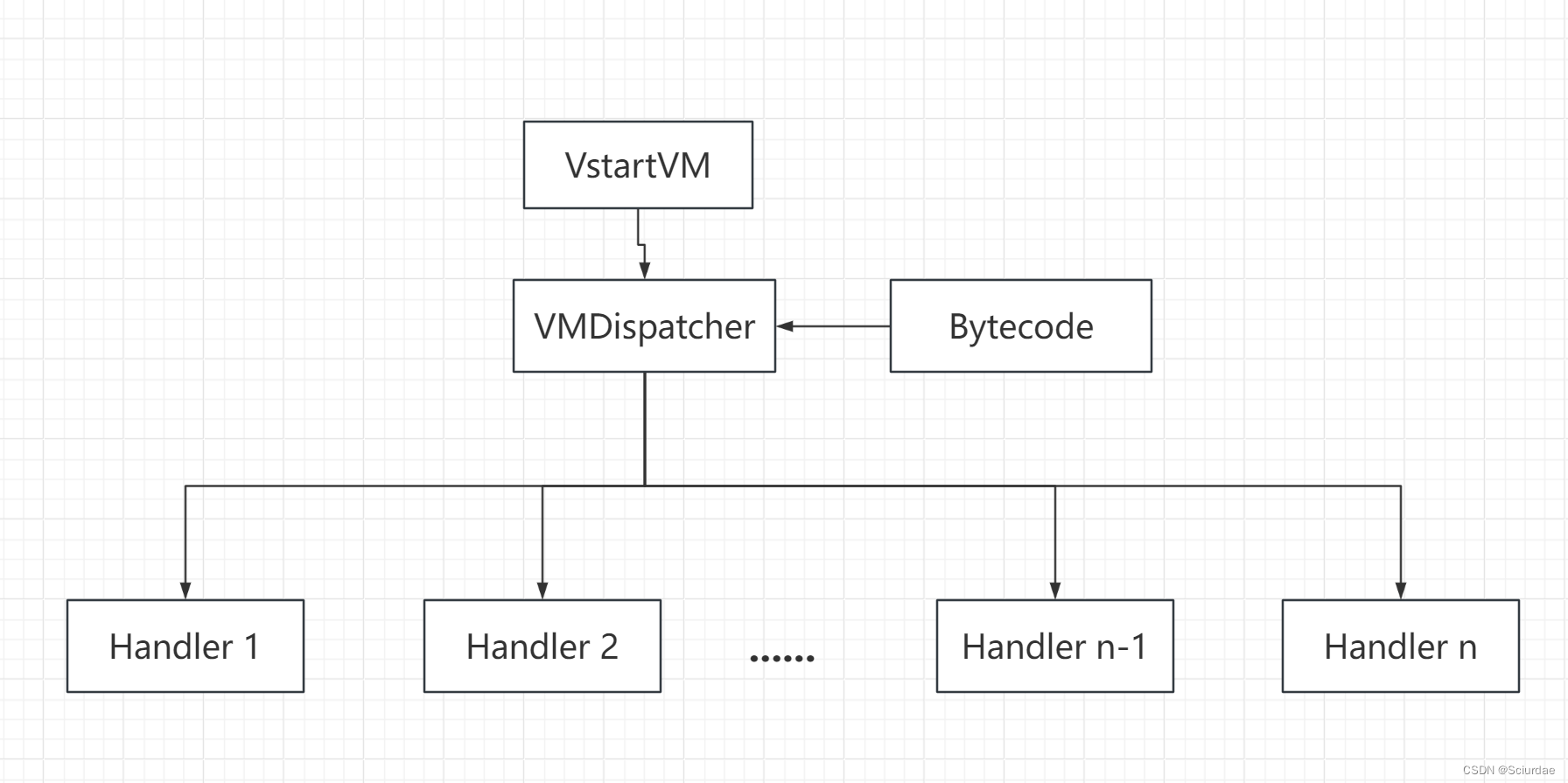
在上图中,有几个组成部分:
- VStartVM部分初始化虚拟机
- VMDispatcher部分调度这些Handler。调度执行完后会返回VMDispatcher,形成循环
- Bytecode是由指令执行系统定义的一套指令和数据组成的一串数据流。
- Handler是一段小程序或者一段过程
如果将上面看作一个CPU,那么Bytecode就是CPU中执行的二进制代码,VMDispatcher就是CPU执行调度器,每个Handler就是CPU所支持的一条指令。
0x1A 关于调用约定
VStartVM的工作是初始化虚拟机,在VStartVM将真实环境压入栈之后会生成一个VMDispatcher标签,当Handler执行完毕就会返回这里,形成一个循环,所以VStartVM也叫做“dispatcher”(调度器)。
在这里dispatcher会获取字节码,然后从JUMP表中寻找相应的Handler并跳转过去继续执行。
调用方法:
push 指向字节码的起始地址
jmp VStartVM
在这个过程中,有着如下的三个约定:
- edi 指向VMContext的起始值
- esi 指向字节码的地址
- ebp 指向VM栈地址
注:这些约定是整个执行循环都要遵守的。
VMContext 即“虚拟环境结构”,其中存放了一些需要使用的值。
具体如:
struct VMContext
{
DOWRD v_eax;
DOWRD v_ebx;
DOWRD v_ecx;
DOWRD v_edx;
DOWRD v_esi;
DOWRD v_edi;
DOWRD v_ebp;
DOWRD v_efl; // 符号寄存器
DOWRD v_esp;
}
0x1B Handler
这里的handler指得是一段小程序或者一段过程,而非windows中的句柄,handler是由dispatcher调度的。
Handler分为俩大类:
- 辅助Handler : 用于执行一些重要的、基本的指令;
- 普通Handler : 用于执行一些普通的x86指令。

如上图所示:
在执行过程中,指令由普通Hadnler处理,源操作数和目的操作数都有栈辅助Handler处理。
这样写有什么好处吗?
- 好处就是不必为指令的每一种形式都写一个模拟的Handler。
执行一个add指令可能有不同的形式,如果先将操作数传给栈辅助Handler,那么当执行到add、指令时,操作数就已经是以一个立即数的形式存放在栈中了,这样add Handler就不必考虑操作数从哪里来,只需要用这个操作数直接加法操作就好了。
0x1C 指令
将需要描述的x86指令分类,按功能可以分为普通指令、栈指令、流指令、不可模拟指令4类。
- 普通指令包括算术指令,数据传输指令等。(add,mov)
- 栈指令主要指push pop等进行栈操作的指令
- 流指令是指jmp、call、retn等会改变程序执行流程的指令
- 不可模拟指令就是无法再次模拟的指令,例如int 3,sysenter,in,out等。
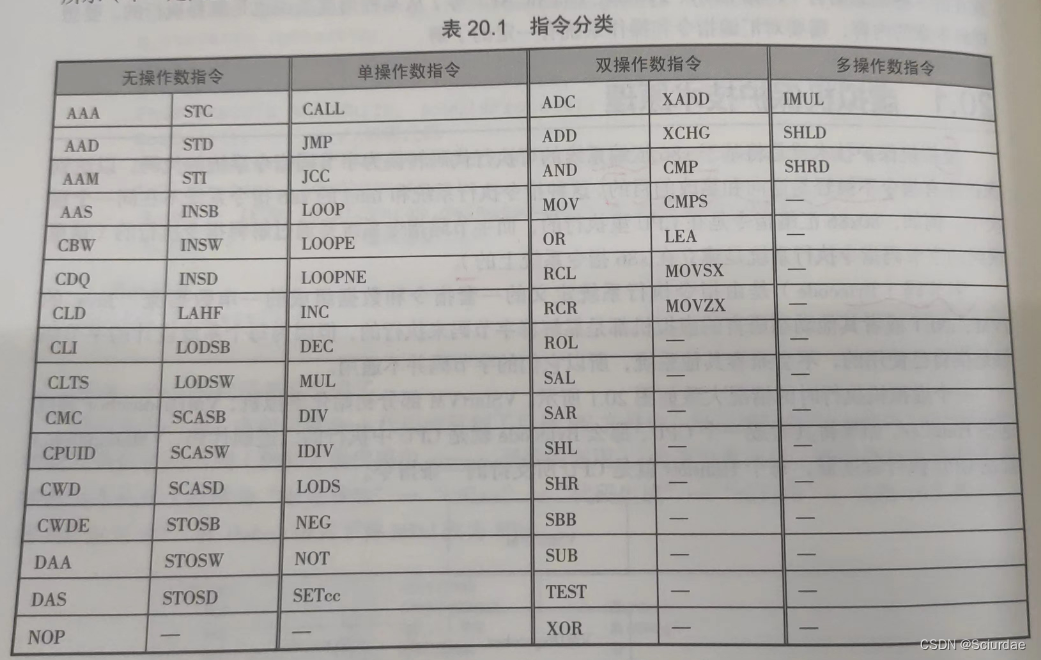
指令按操作数可以分为无操作数指令、单操作数指令、双操作数指令和多操作数指令,如下表:
0x2 vm虚拟机逆向 实战[GKCTF 2020]EzMachine
上面对虚拟机的原理,调用约定,Handler和指令进行了简单的介绍。写完感觉好像对读者也没什么用。。。。
下面总结复现道CTF中虚拟机逆向的实战分析。
关于ctf中虚拟机逆向的思路:
- 先找到虚拟机的入口或者opcode(Bytecode)的位置。
- 分析虚拟机的dispatcher和各个Hadnler
- 逆向各Handler,进一步分析虚拟机的流程
题目分析,花指令去除
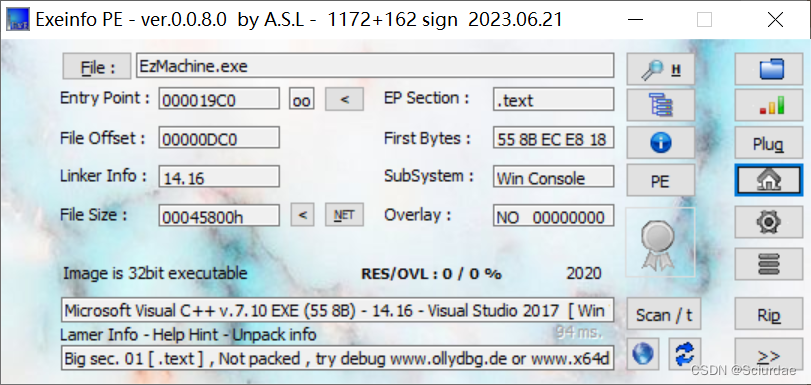
每拿到一个题目总是先查一查文件信息,IDA分析
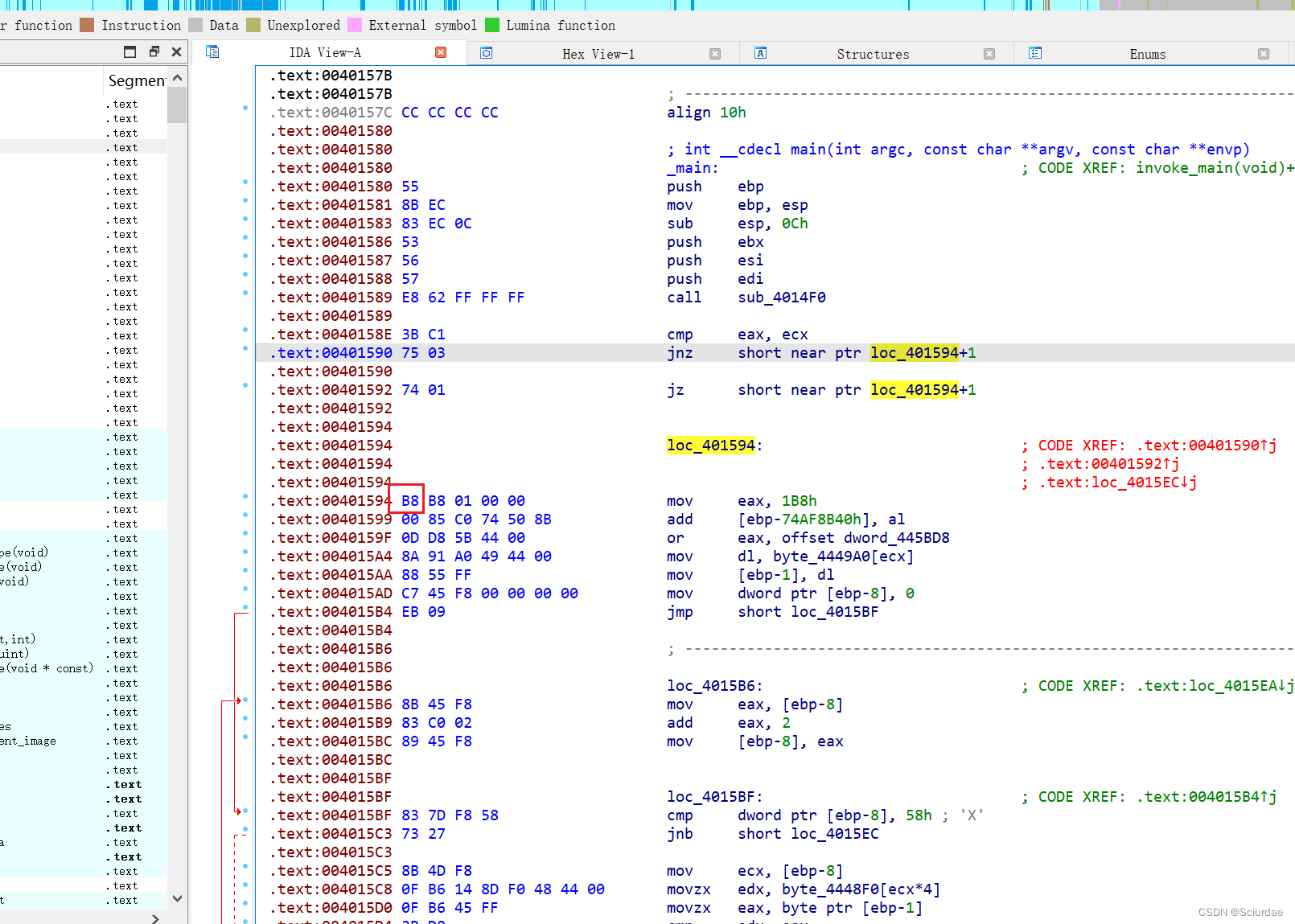
打开来看到个花指令,将B8改为90(nop)掉就好,之后C修复一下代码,用P创建函数 ,反编译一下。
得到main函数:
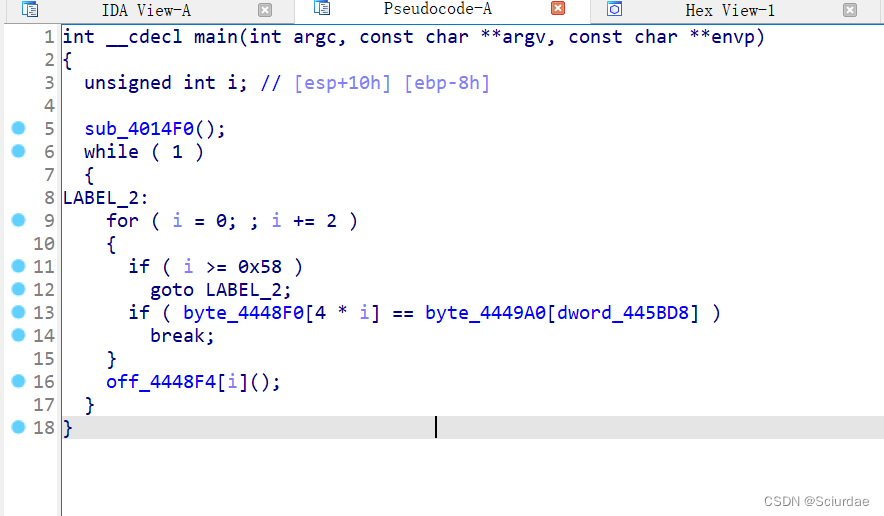
分析main函数,while(1)循环,就像是 dispatcher调度器和Handler之间的循环。 下面俩个地址有一个应该就是存放在内存中的opcode,点进去观察;
发现byte_D49A0 里面存放的就是opcode,全部取出来备用。
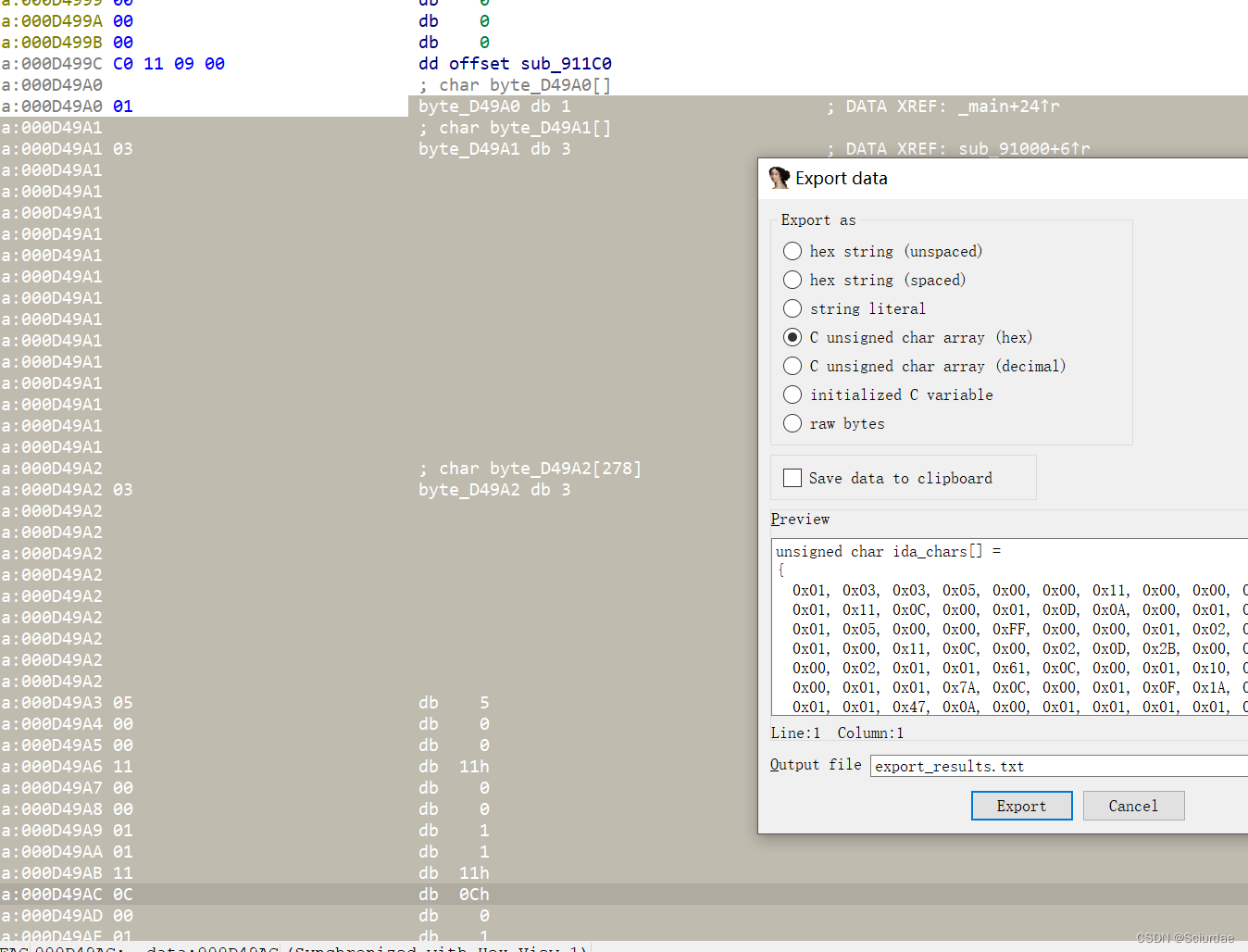
再点开off_D48F4看看,
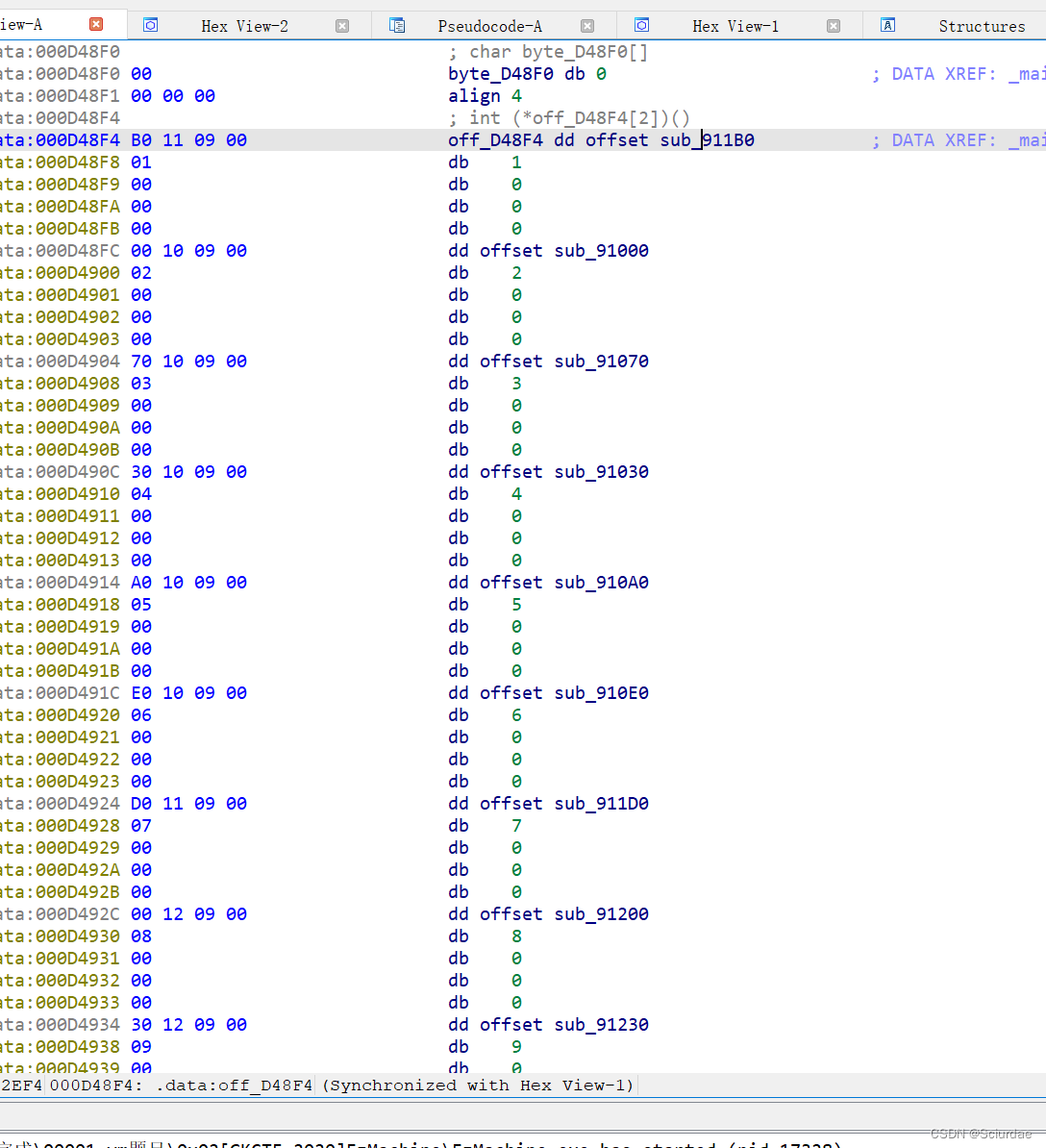
可以发现 它用 i 作为索引,调用了很多函数,推测这个应该就是dispatcher。

Handler分析
现在开始分析各个Handler,也就是dispatcher里面的各个函数指令;
-
第一个
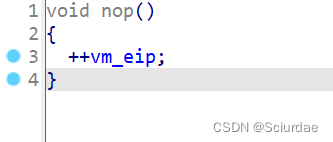
只进行了eip++的操作,说明是 nop指令; -
第二个
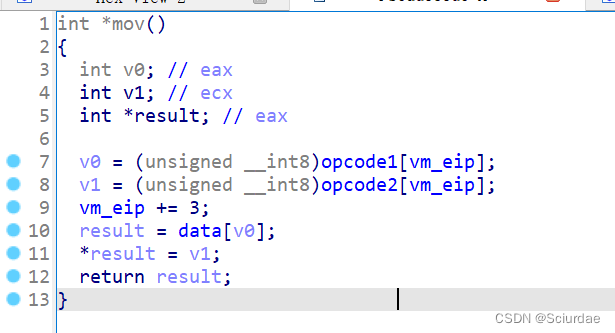
这里取了俩个机器码,然后eip+3说明这条指令占3个字节;data点进去可以看到一些数据
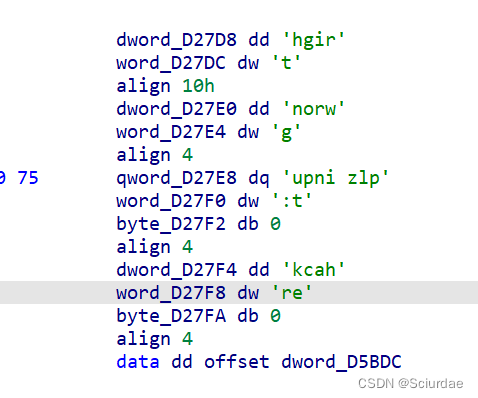
说明这一条指令模拟的应该mov指令,例如 mov reg,data -
第三个和第四个
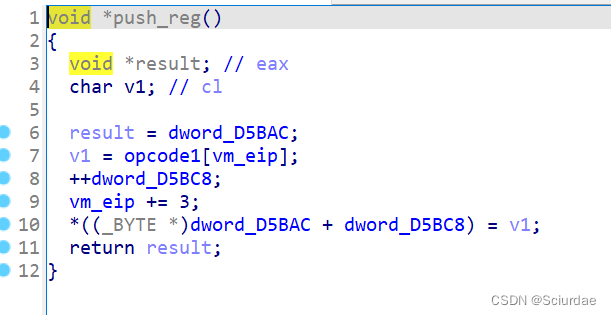
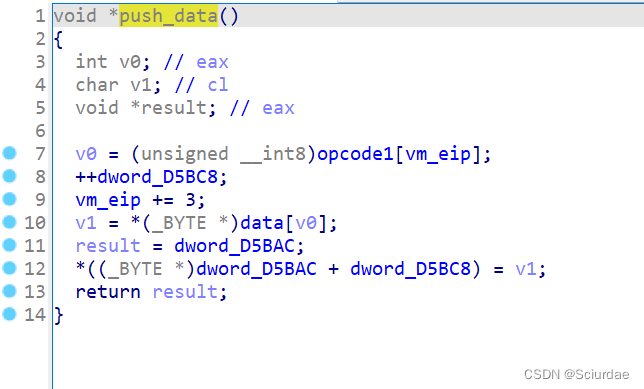
这俩个结合一起看,dword_D5BAC其实就是stack栈,在push_reg中先将result指向stack,再取一个机器码放入v1中,dword_D5BC8是栈中的位置, 然后再将 v1放入 stack栈中 dword_D5BC8处。然后返回栈的指针result。
看push_data,大致上逻辑差不多,就是 这里取的v0不是直接压入栈中,而是作为data的索引,从data中取出一个数据压入栈中,所有这里应该是push_data。 -
第五个
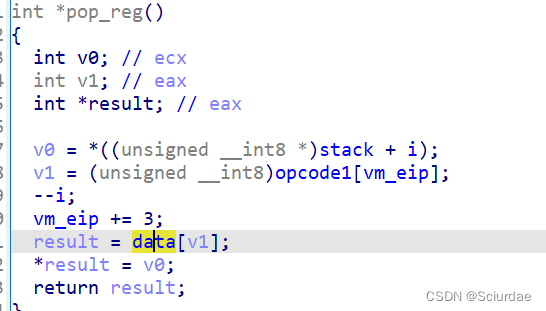
这里先将stack栈顶的值弹出来赋给 v0,取一个机器码存在 v1 里面,-- i 是因为栈顶已经弹出了一个值,然后result从data里面取出一个值,应该是寄存器的地址,最后将弹出来的值 v0 赋给寄存器。所以这里实现的是 pop reg -
第六个
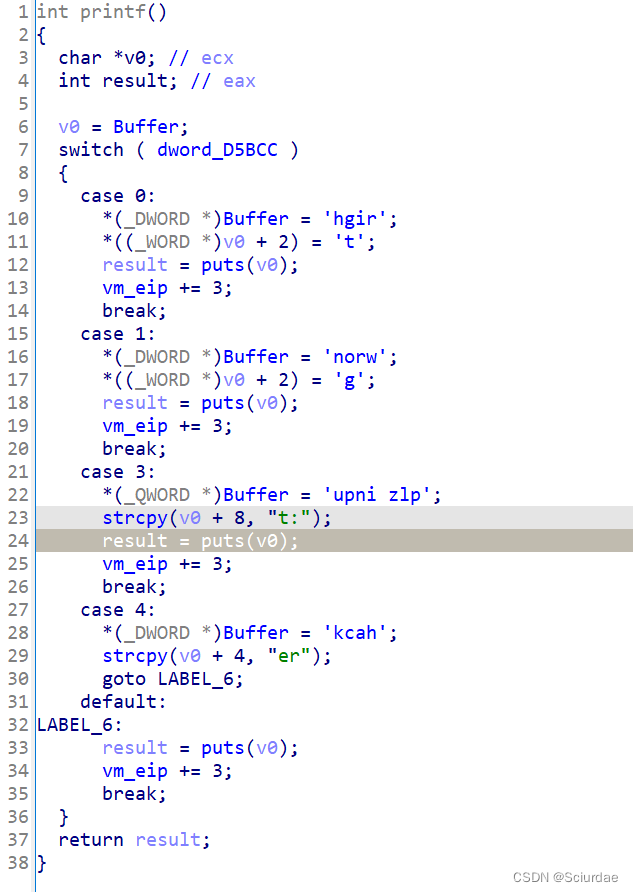
这里有很多put函数,和数据,应该是模拟的printf 函数 -
第七个和第八个九十十一个。都差不多
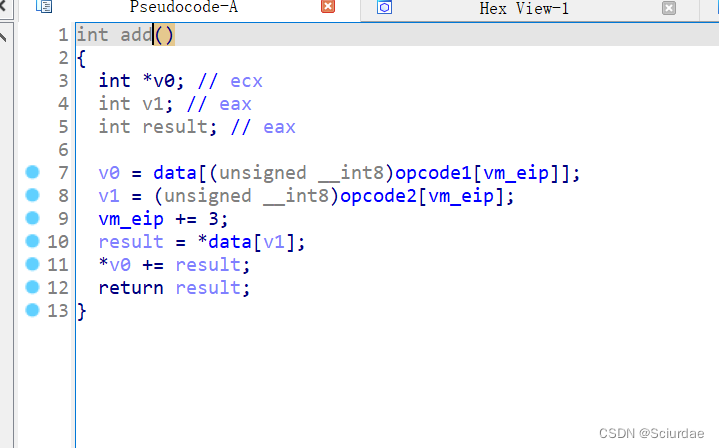
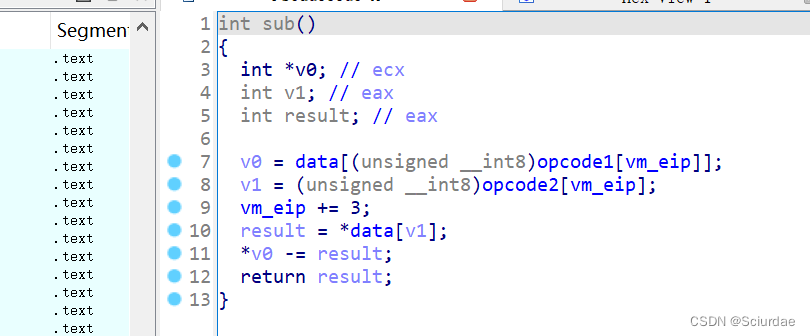
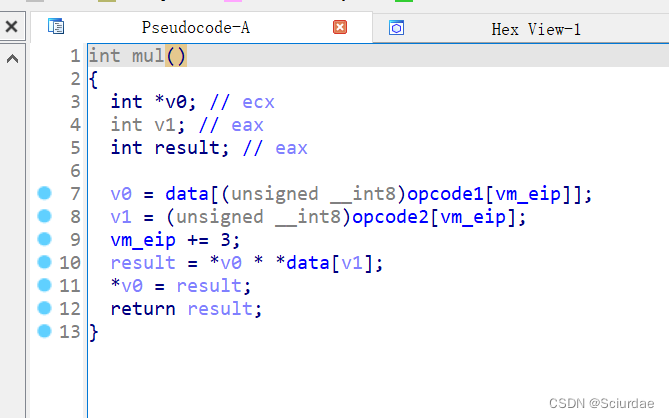
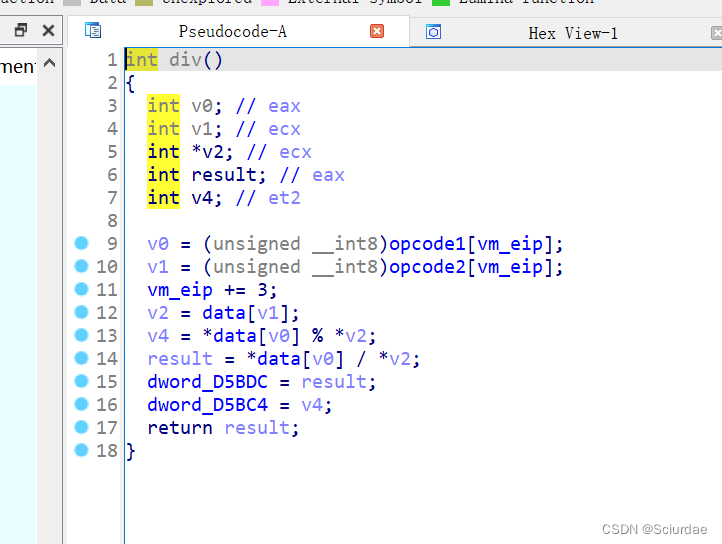
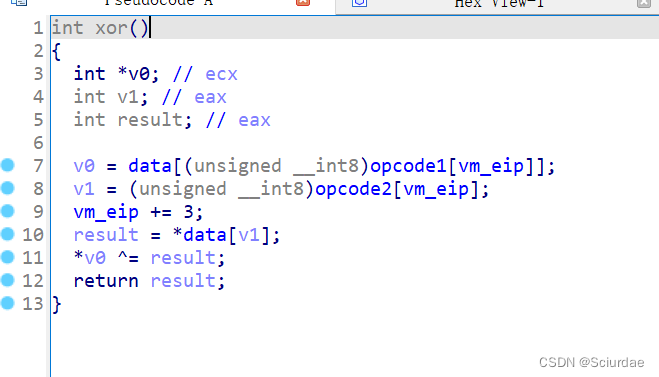
这里几个都差不多,就分析第七个,这里很明显实现的是add的功能,取一个机器码作为data的索引取出了一个数据存放在v0里,后面又取了一次存放在result中,最后俩个相加。后面的同理 -
第十二个
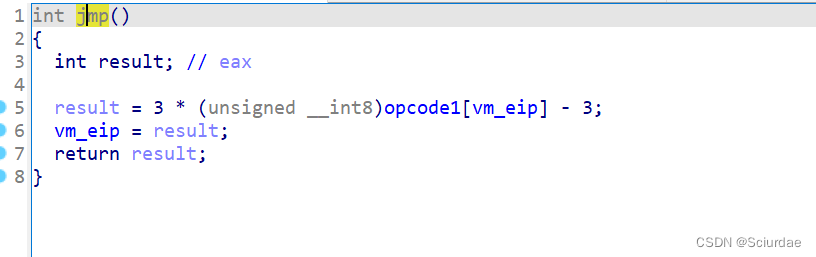
这里eip直接等于result了说明是无条件跳转。 -
第十三个
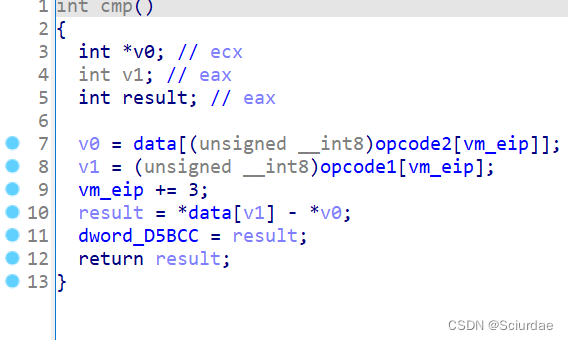
对于这里,取了俩个值,然后做了减法操作,得到result。模拟的是一个比较cmp的操作。 -
第十四个和第十五个。
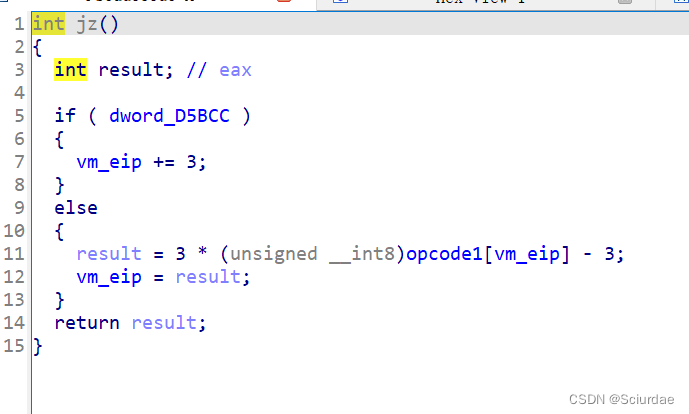
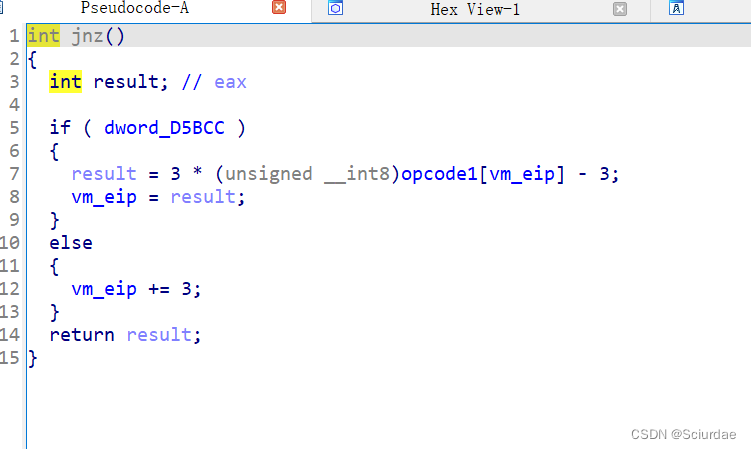
模拟的是一个JZ跳转的的操作,等于0就跳转,不然的话就eip+3接着下一条指令
同理下一条就是JNZ的跳转指令,不等于0就跳转。 -
第十六个十七个
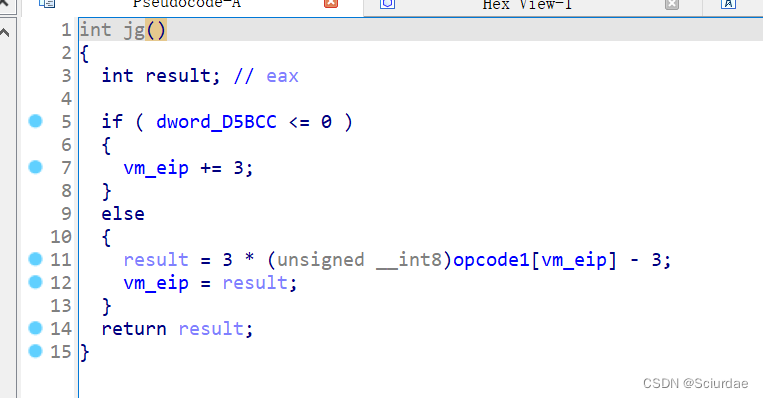
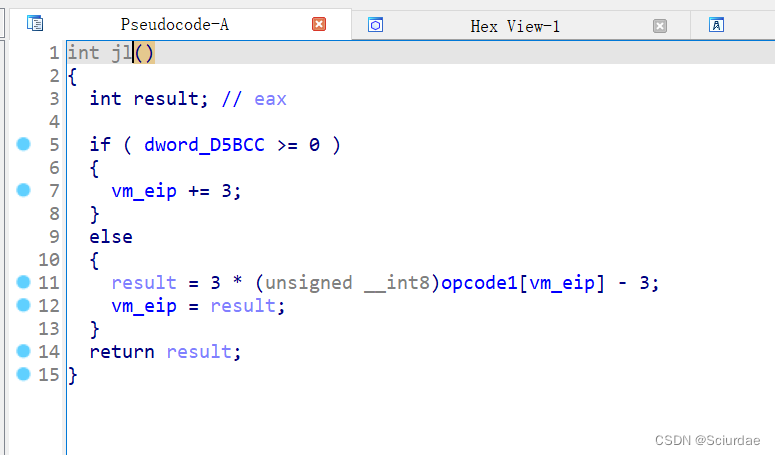
jg指令是大于 0 就跳转。jl指令是小于0就跳转。 -
第十八个
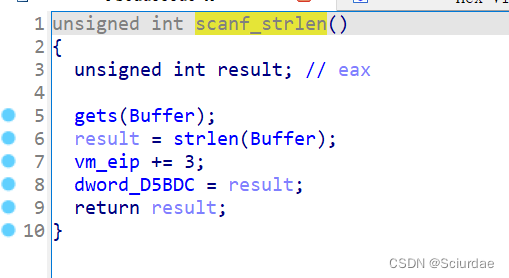
有一个gets和一个strlen,最后返回的是strlen的值,模仿的应该是strlen -
第十九个
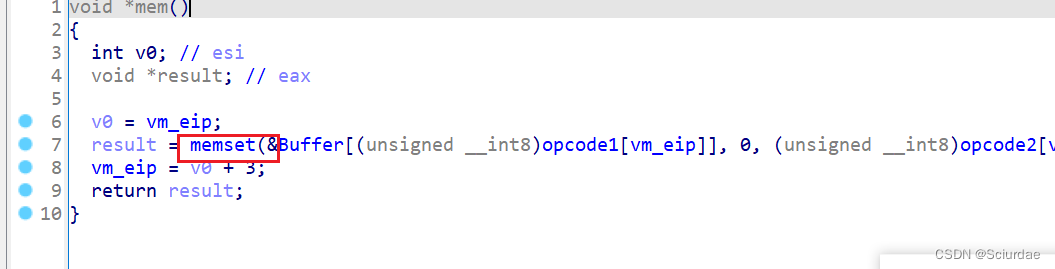
-
最后几个
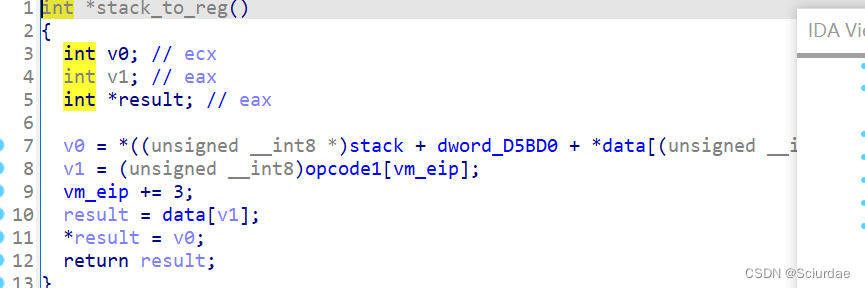
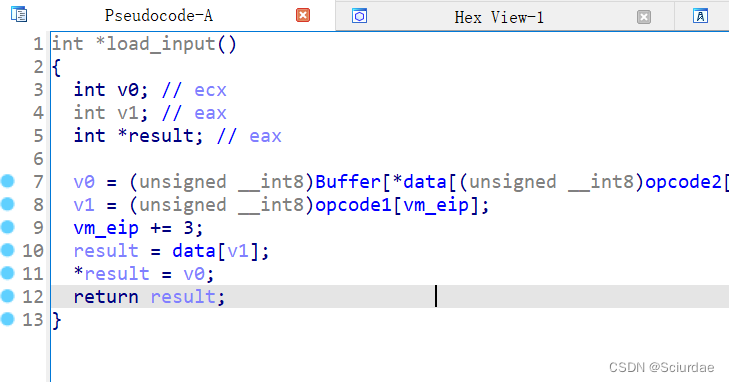
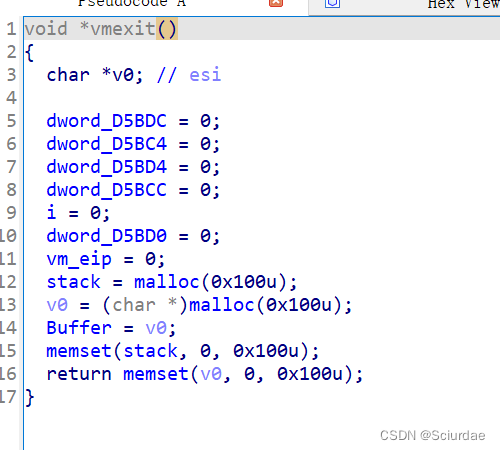
最后一个是exit,前俩个我也不是很理解。全部的分析差不多就是这样。
脚本编写
编写一个脚本,将dispatcher调度器使用起来,也就是通过机器码opcode去调度handler的过程,
opcode = [0x01, 0x03, 0x03, 0x05, 0x00, 0x00, 0x11, 0x00, 0x00, 0x01,
0x01, 0x11, 0x0C, 0x00, 0x01, 0x0D, 0x0A, 0x00, 0x01, 0x03,
0x01, 0x05, 0x00, 0x00, 0xFF, 0x00, 0x00, 0x01, 0x02, 0x00,
0x01, 0x00, 0x11, 0x0C, 0x00, 0x02, 0x0D, 0x2B, 0x00, 0x14,
0x00, 0x02, 0x01, 0x01, 0x61, 0x0C, 0x00, 0x01, 0x10, 0x1A,
0x00, 0x01, 0x01, 0x7A, 0x0C, 0x00, 0x01, 0x0F, 0x1A, 0x00,
0x01, 0x01, 0x47, 0x0A, 0x00, 0x01, 0x01, 0x01, 0x01, 0x06,
0x00, 0x01, 0x0B, 0x24, 0x00, 0x01, 0x01, 0x41, 0x0C, 0x00,
0x01, 0x10, 0x24, 0x00, 0x01, 0x01, 0x5A, 0x0C, 0x00, 0x01,
0x0F, 0x24, 0x00, 0x01, 0x01, 0x4B, 0x0A, 0x00, 0x01, 0x01,
0x01, 0x01, 0x07, 0x00, 0x01, 0x01, 0x01, 0x10, 0x09, 0x00,
0x01, 0x03, 0x01, 0x00, 0x03, 0x00, 0x00, 0x01, 0x01, 0x01,
0x06, 0x02, 0x01, 0x0B, 0x0B, 0x00, 0x02, 0x07, 0x00, 0x02,
0x0D, 0x00, 0x02, 0x00, 0x00, 0x02, 0x05, 0x00, 0x02, 0x01,
0x00, 0x02, 0x0C, 0x00, 0x02, 0x01, 0x00, 0x02, 0x00, 0x00,
0x02, 0x00, 0x00, 0x02, 0x0D, 0x00, 0x02, 0x05, 0x00, 0x02,
0x0F, 0x00, 0x02, 0x00, 0x00, 0x02, 0x09, 0x00, 0x02, 0x05,
0x00, 0x02, 0x0F, 0x00, 0x02, 0x03, 0x00, 0x02, 0x00, 0x00,
0x02, 0x02, 0x00, 0x02, 0x05, 0x00, 0x02, 0x03, 0x00, 0x02,
0x03, 0x00, 0x02, 0x01, 0x00, 0x02, 0x07, 0x00, 0x02, 0x07,
0x00, 0x02, 0x0B, 0x00, 0x02, 0x02, 0x00, 0x02, 0x01, 0x00,
0x02, 0x02, 0x00, 0x02, 0x07, 0x00, 0x02, 0x02, 0x00, 0x02,
0x0C, 0x00, 0x02, 0x02, 0x00, 0x02, 0x02, 0x00, 0x01, 0x02,
0x01, 0x13, 0x01, 0x02, 0x04, 0x00, 0x00, 0x0C, 0x00, 0x01,
0x0E, 0x5B, 0x00, 0x01, 0x01, 0x22, 0x0C, 0x02, 0x01, 0x0D,
0x59, 0x00, 0x01, 0x01, 0x01, 0x06, 0x02, 0x01, 0x0B, 0x4E,
0x00, 0x01, 0x03, 0x00, 0x05, 0x00, 0x00, 0xFF, 0x00, 0x00,
0x01, 0x03, 0x01, 0x05, 0x00, 0x00, 0xFF, 0x00, 0x00, 0x00]
opcode_key = {
0: 'nop',
1: 'mov reg data',
2: 'push data',
3: 'push_reg',
4: 'pop_reg',
5: 'printf',
6: 'add_reg_reg1',
7: 'sub_reg_reg1',
8: 'mul',
9: 'div',
10: 'xor',
11: 'jmp',
12: 'cmp',
13: 'je',
14: 'jne',
15: 'jg',
16: 'jl',
17: 'scan_strlen',
18: 'mem_init',
19: 'stack_to_reg',
20: 'load_input',
0xff: 'exit'}
count = 0
code_index = 1
for x in opcode: # 读取每一个opcode
if count % 3 == 0:
print(str(code_index) + ':', end='')
print(opcode_key[x], end=' ')
code_index += 1
elif count % 3 == 1:
print(str(x) + ',', end='')
else:
print(str(x))
count += 1
输出结果如下:
1:mov reg data 3,3
2:printf 0,0
3:scan_strlen 0,0
4:mov reg data 1,17
5:cmp 0,1
6:je 10,0
7:mov reg data 3,1
8:printf 0,0
9:exit 0,0
10:mov reg data 2,0
11:mov reg data 0,17
12:cmp 0,2
13:je 43,0
14:load_input 0,2
15:mov reg data 1,97
16:cmp 0,1
17:jl 26,0
18:mov reg data 1,122
19:cmp 0,1
20:jg 26,0
21:mov reg data 1,71
22:xor 0,1
23:mov reg data 1,1
24:add_reg_reg1 0,1
25:jmp 36,0
26:mov reg data 1,65
27:cmp 0,1
28:jl 36,0
29:mov reg data 1,90
30:cmp 0,1
31:jg 36,0
32:mov reg data 1,75
33:xor 0,1
34:mov reg data 1,1
35:sub_reg_reg1 0,1
36:mov reg data 1,16
37:div 0,1
38:push_reg 1,0
39:push_reg 0,0
40:mov reg data 1,1
41:add_reg_reg1 2,1
42:jmp 11,0
43:push data 7,0
44:push data 13,0
45:push data 0,0
46:push data 5,0
47:push data 1,0
48:push data 12,0
49:push data 1,0
50:push data 0,0
51:push data 0,0
52:push data 13,0
53:push data 5,0
54:push data 15,0
55:push data 0,0
56:push data 9,0
57:push data 5,0
58:push data 15,0
59:push data 3,0
60:push data 0,0
61:push data 2,0
62:push data 5,0
63:push data 3,0
64:push data 3,0
65:push data 1,0
66:push data 7,0
67:push data 7,0
68:push data 11,0
69:push data 2,0
70:push data 1,0
71:push data 2,0
72:push data 7,0
73:push data 2,0
74:push data 12,0
75:push data 2,0
76:push data 2,0
77:mov reg data 2,1
78:stack_to_reg 1,2
79:pop_reg 0,0
80:cmp 0,1
81:jne 91,0
82:mov reg data 1,34
83:cmp 2,1
84:je 89,0
85:mov reg data 1,1
86:add_reg_reg1 2,1
87:jmp 78,0
88:mov reg data 3,0
89:printf 0,0
90:exit 0,0
91:mov reg data 3,1
92:printf 0,0
93:exit 0,0
94:nop
大概转换成汇编的样子,加一点注释;
mov reg3, 3
printf (...)
scanf(input)strlen(input) # 输入并计算长度放入reg0中
mov reg1, 17
cmp reg0, reg1 # 等于17
je 10
mov reg3, 1
printf(...)
exit()
mov reg2, 0 # 跳到这里
mov reg0, 17
cmp reg0, reg2
je 43 # 看到43行去,4041是做一个类似于reg2++的操作 je是等于跳转,说明这里是循环17次
reg1 = load_input[ebx] # 循环17次正好读取 17 个输入
mov reg1, 'a'
cmp reg0, reg1
jl 26 # 小于 ‘a’ 就跳到26
mov reg1 'z'
cmp reg0, reg1
jg 26 # 大于’z'就跳到26
mov reg1, 'G'
xor reg0, reg1 # reg0 ^ ‘G’
mov reg1 1
add reg0, reg1 # reg0 + 1
jmp 36
mov reg1 'A'
cmp reg0, reg1
jl 36 # 小于 ‘A'就跳到 36
mov reg1 'Z'
cmp reg0, reg1 # 大于 ‘Z'就跳到 36
jg 36
mov reg1, 'k'
xor reag0, reg1 # ^ 'k'
mov reg1, 1
sub reg0, reg1 # -1
mov reg1, 16 #
div reg0, reg1 # reg0 / 16
push reg1 # 压入整除的数字
push reg0 # 再压入余数
mov reg1, 1
add reg2, reg1 # reg2++
jmp 11
压入一长串数据
mov reg2 1
stack to reg 1,2 # 不太理解这里什么意思 , 好像是拆成
pop reg0
cmp reg0, reg1 # 比对
jne 91 # 不等于就失败
mov reg1 34 # 将 17个拆成了 34个 包括整数和余数
cmp reg2 reg1
je 89
mov reg1 1
add reg2 reg1
add reg2, reg1
jmp 78
mov reg3 0 # 返回值为0
printf(...) # 失败
exit # 退出
mov reg3 1 # 返回值为1
pintf(...) # 成功
exit() # 退出
data = [0x7,0xd,0x0,0x5,0x1,0xc,0x1,0x0,0x0,0xd,0x5,0xf,0x0,0x9,0x5,0xf,0x3,0x0,0x2,0x5,0x3,0x3,0x1,0x7,0x7,0xb,0x2,0x1,0x2,0x7,0x2,0xc,0x2,0x2,]
data = data[::-1]
flag = ''
for i in range(0, 34, 2):
temp = data[i] + data[i+1]*16
x = ((temp+1) ^ 75)
y = ((temp-1) ^ 71)
if 65 <= x <= 90: # 'A'-'Z'
flag += chr(x)
elif 97 <= y <= 122: # 'a' - 'z'
flag += chr(y)
else:
flag += chr(temp) # 没有处于'a'-'z'或'A'-'Z'之间
print(flag)
# flag{Such_A_EZVM}
累死了。。。。
、