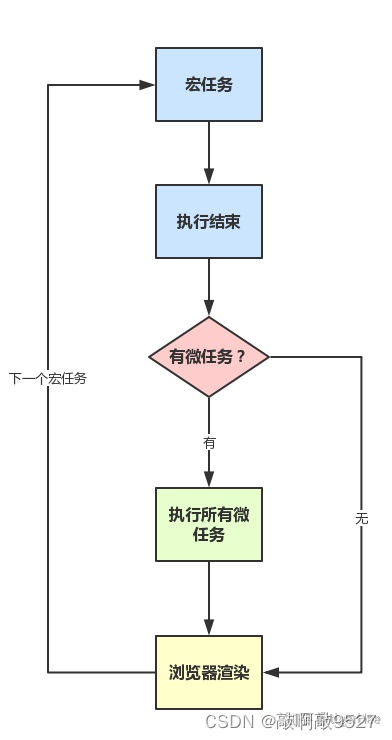
#pic_center
R 1 R_1 R1
R 2 R^2 R2
目录
- 知识框架
- No.1 数据预处理
- 一、N维数组样例
- 二、创建数组
- 三、访问元素
- 四、数据操作
- 五、数据预处理
- 六、D2L注意点
- No.2 线性代数
- 一、标量
- 二、向量
- 1、基本操作
- 2、空间表示
- 3、乘法
- 三、矩阵
- 1、基本操作
- 2、乘法
- 3、空间表示
- 4、乘法
- 5、范数
- 6、特殊矩阵
- 7、特征向量
- 四、D2L注意点:
- 1、矩阵克隆
- 2、矩阵降维
- 五、QA
- No.3 矩阵计算
- 一、标量导数
- 二、亚导数
- 三、梯度
- 1、y是标量,x是向量
- 2、y是向量,x是标量
- 3、y和x均是向量
- 4、y和x均是矩阵
- 四、QA
- 1、导数作用
- 2、自动微分和计算图
- No.4 自动求导
- 一、向量链式法则
- 二、自动求导
- 三、计算图
- 四、自动求导的两种模式
- 五、反向累积
- 六、D2L注意点
- 1、梯度存储问题
- 2、求导问题
- 七、QA
知识框架
No.1 数据预处理
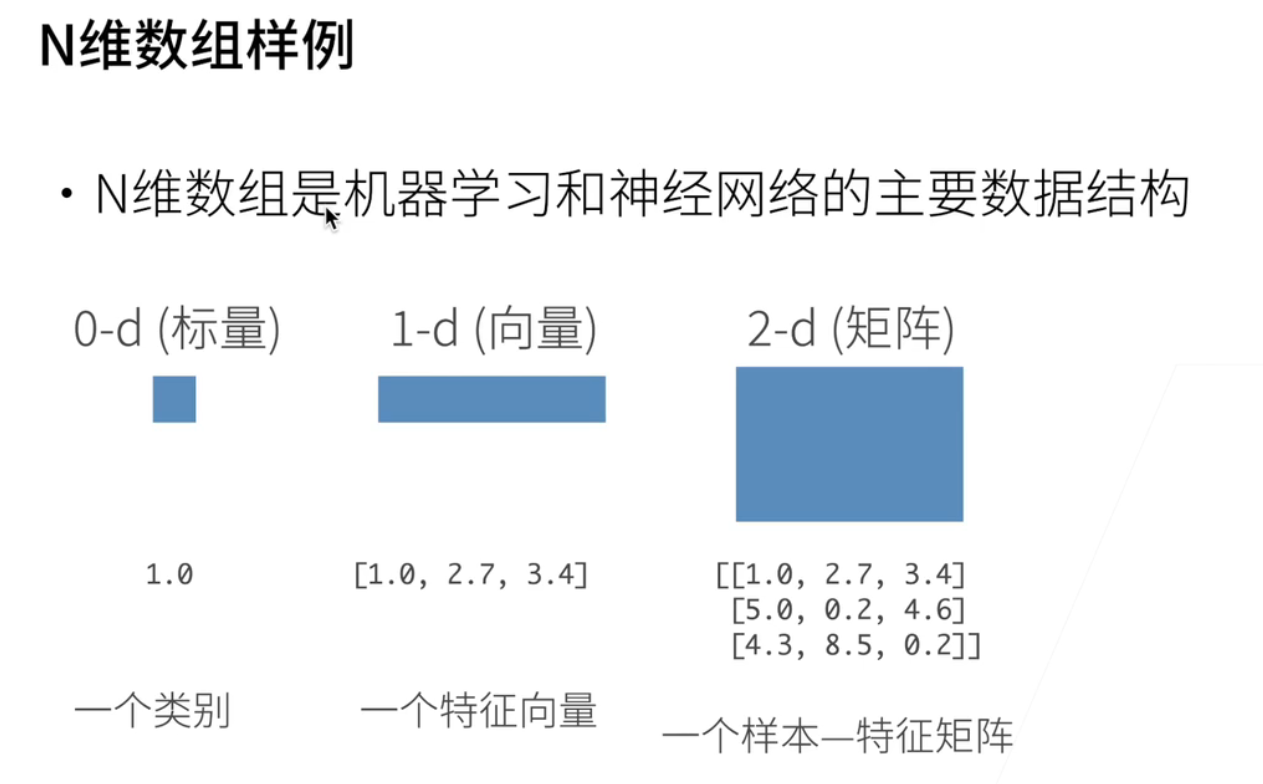
一、N维数组样例
最基础的数据操作;就说最基础的数据结构;我们真的是从0开始;这一次我们来从基础开始数据操作;就是说机器学习最用的最多的;数据结构是n维数组;这是所有的机器学习,神经网络;以及深度学习用的主要的数据结构;就是说我们举几个例子;最简单是一个0位的啊;数字叫做标量;比如说最简单就是一个1.0;一个浮点运算;它可能表示一个物体的类别;一维的数组叫做向量;比如说这有三个数字;它是一个特征;比如说是一个特征向量就是一个样本;我把它抽象成一行数字;2D呢2D就是一个矩阵;这里有3行有3列;就说我们可以是一个样本的特征矩阵;这样子的话我们要是三个样本;每一行表示一个样本;每一列就表示它不同的特征;当然我们会解释什么呀是样本;什么是特征;在之后解释;
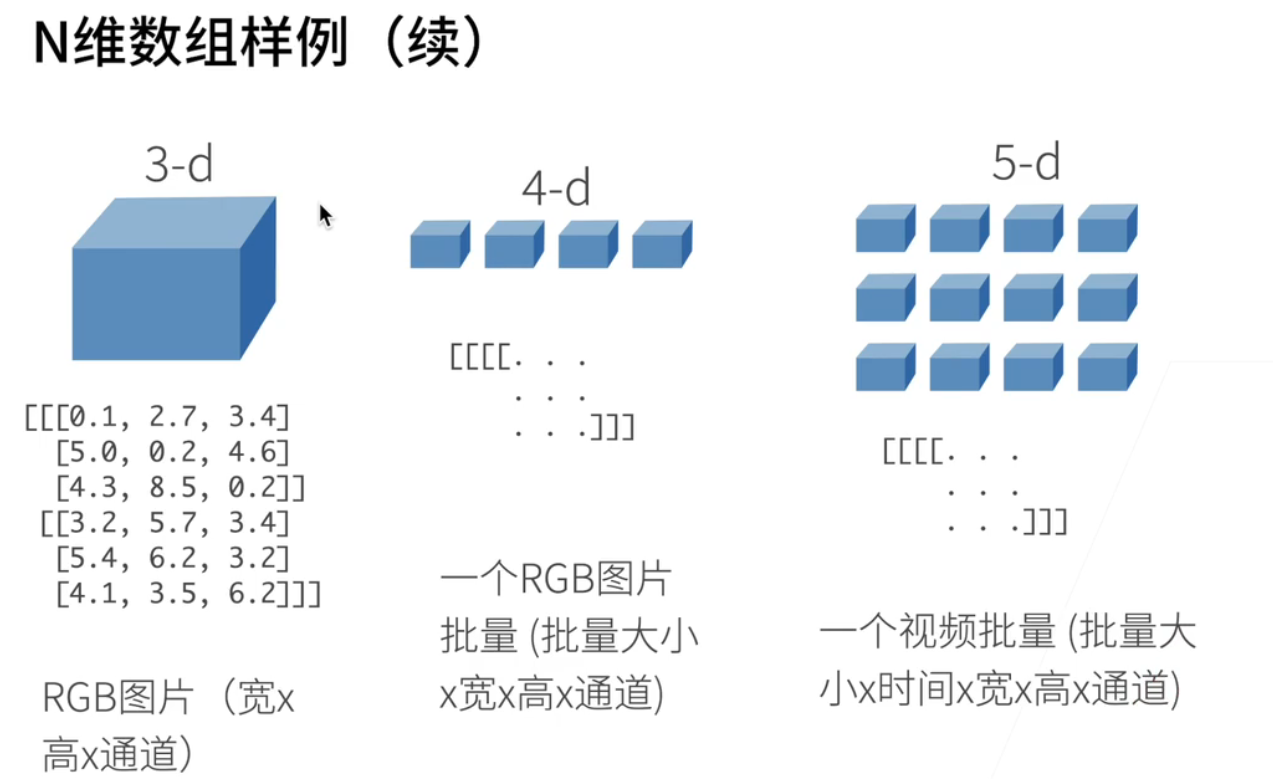
当我们往下走;该做到3D;3D的话最简单就是一张图片;你的RGB的图片是一个三维的数字;因为它有宽度;就是你的一行一行你有高啊;宽其实是列的个数和高;就是你的有多少行;还有你有r g b三个通道;所以它是一个三维的一个数字;当四维呢;四维的话就是啊;n个三维的数组放在一起;比如说一个RGB图片的批量;我们在深度学习的啊;训练的时候;通常是不是一张一张图片去读;我们通常是;比如说每次读128张图片;那就是一个batch一个批量;就是一个四维的一个数啊;数组我们可以做到五维;我们啊现在用的会比较少;我们这堂课用的不多;比如说一个视频的批量;做视频其实是说你就是以很多图片;但是你还有个时间的维度;所以你的是一个啊;批量大小乘以时间;乘以宽高和通道的一个5D的数字;
二、创建数组
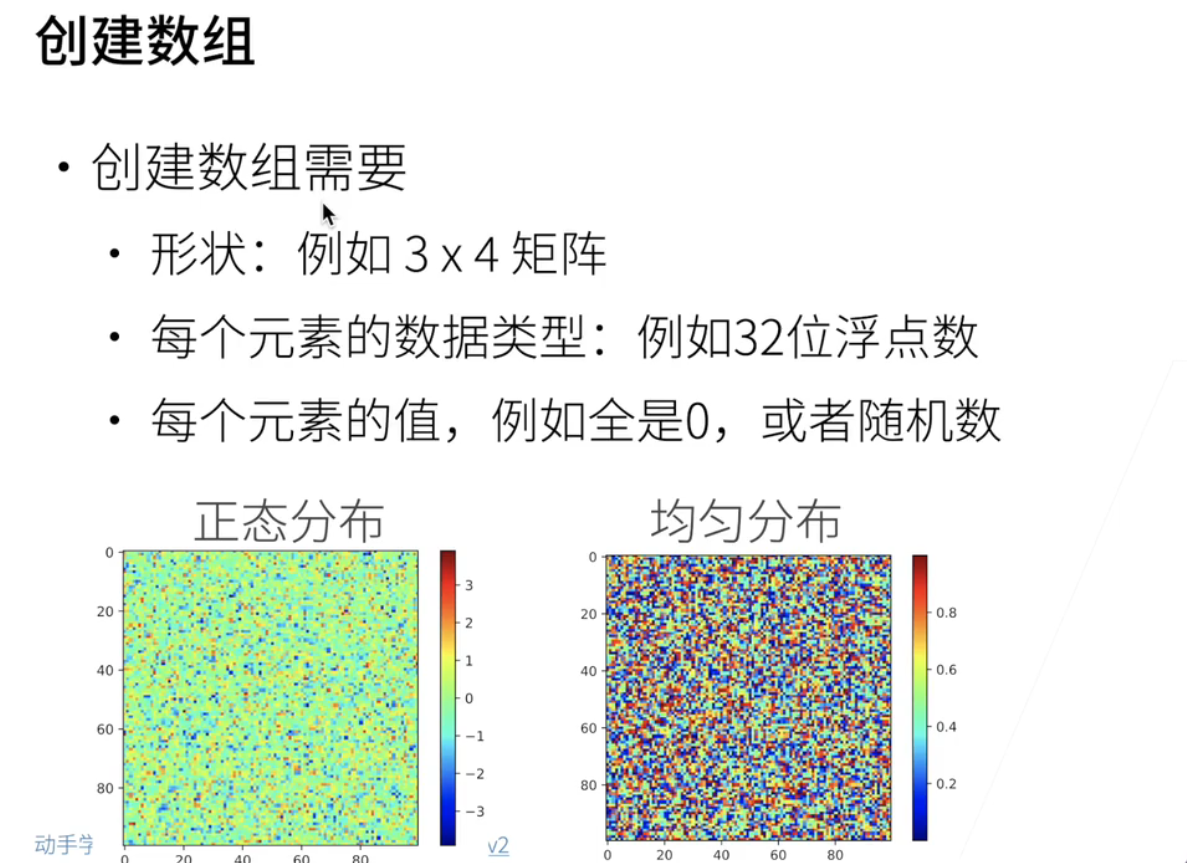
然后我们可以创建一个数组;创建数组我们需要给三个东西;一个是说我要什么样的形状;比如说我要一个3*4的一个矩阵;我要指定说每一个元素的数据类型啊;比如说我要一个32位的浮点运算啊;32位的浮点数;然后我要告诉你说每个元素的值;比如说我可以全是0;或者可以全是一个随机数啊;下面这两张图表示啊;左边是说;我所有的元素的值;是按照一个正态分布表示的;一个normal distribution;我的右边是一个按照均匀分布;就是在0-1之间均匀可以给我出一些值;
三、访问元素
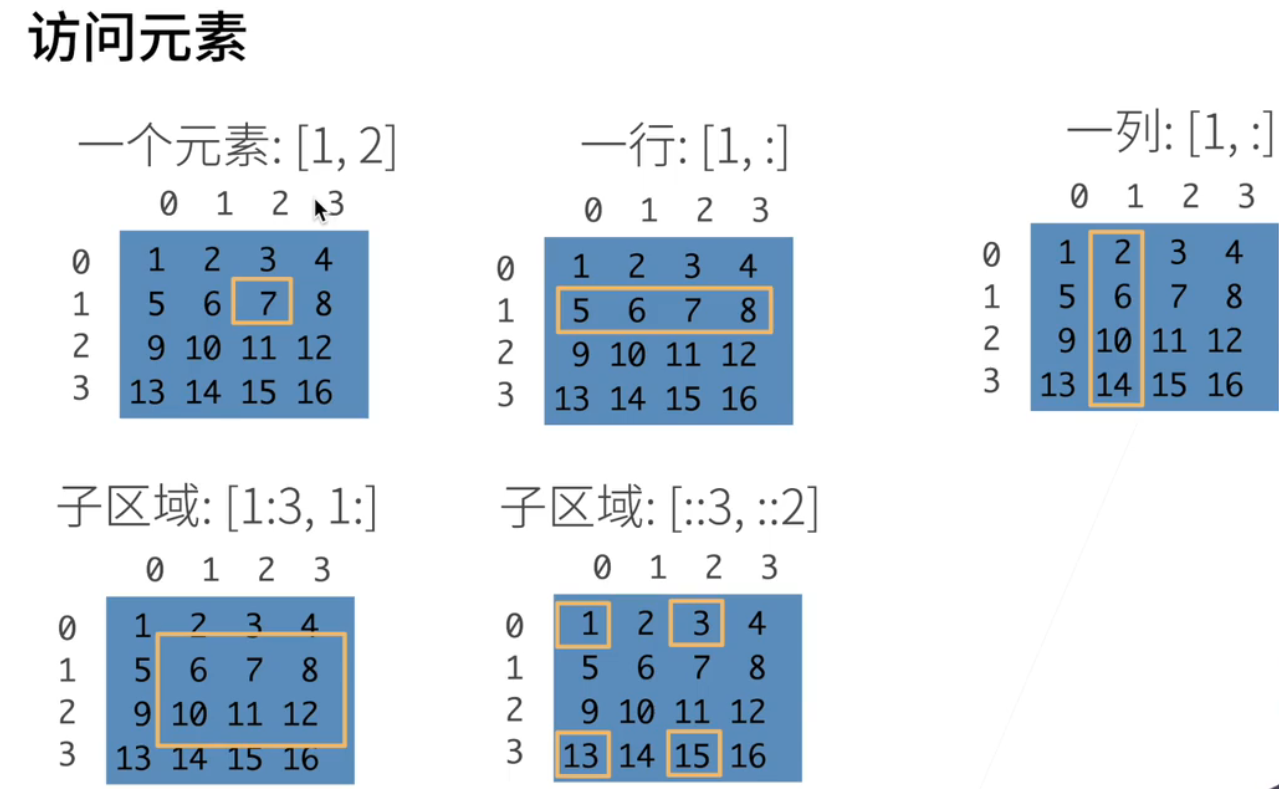
那我们可以访问它的元素啊;这里给了几个例子;第一个是说我要访问第一行;它其实是说行是从0开始的;叫零一就是第二行;其实它的下标是一和;它的;第三列就是它的下标的index是2的;这一个数字是7;当我也可以说我要访问啊一行啊;第一行就是说和;通过冒号表示;说我要把这一列所有的元素访问出来;就是说一啊;逗号冒号就是把5678啊出来;当我们可以访问一列;就是我要访问第一列;把所有的行这一块;啊这里是有一个type啊;这个东西应该是啊冒号一;要把这一列拿出来;但是我可以拿一个子域;就是说我说我要访问这是第;这是行从从第一行开始到;第三行的开区间结束;就说我是拿到的一和2两个;就虽然它是3结尾但是它是个开区键;所以是拿到第一行和第二行;然后呢第一冒号后面不打的话;那就是表示拿到所有;就是从第一列开始拿到所有的一列;啊最后一个例子是说我要跳的访问;则说从第0行到最后一行;但是每每3行一跳;就说把第0行拿出来把第3行拿出来;列的话是每两列一跳;就是把第一0列和第2列拿出来;这就是访问一个带跳转的一个子区;这是一个最简单的访问元素;;
四、数据操作
"""
首先,我们导入torch。请注意,虽然它被称为PyTorch,但我们应该导入torch而不是pytorch
我们要import Pytorch;就是我们叫做Pytorch;但实际上导入的是torch就是Python;
就是说大家去安装的时候也要去安装torch啊;不要去安装Pytorch在import的时候也要import torch;
"""
import torch
"""
张量表示一个数值组成的数组,这个数组可能有多个维度
我们举个例子;就是说在torch里面;生成arrange就是从0到12;
我们把所有的0到12之间从0开始到12前的11结束的所有的东西拿出来;它是一个向量;
就是我们复制给x然后把x print出来;那我们可以运行一下啊;
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
"""
x = torch.arange(12)
print(x)
"""
我们可以通过它的shape来访问这个张量的形状;就是你x.shape;你看到它是一个向量它就是一个维度;
就是说这个维度的长为12;它是一个以维数元素为一的一个数组;
然后它的;number of elements(缩写numel)就是说你里面元素的总数;它永远是个标量就是12;
torch.Size([12])
12
"""
print(x.shape)
print(x.numel())
"""
如果我们想改变一个数组或者一个张量的形状;但不改变元素的数量和元素值的话;
我们可以用reshape;这个函数;刚刚我们是以12个元素对吧;长为12的向量;
然后我们可以把它reshape成是有3行和4列;看到它是元素是说它在每一行是连续的;然后把它掐成三行;
这样子我们就是说在0123;然后这样子一个3*4的一个矩阵;
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
torch.Size([3, 4])
12
"""
X = x.reshape(3, 4)
print(X)
print(X.shape)
print(X.numel())
"""
我们可以创建一些全0的一些函数;就是给形状是234;元素为全0;
然后当然是我们可以元素为全1对吧;可以看到元素为全1;就是形状是234;
tensor([[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]])
"""
Y = torch.zeros((2, 3, 4))
print(Y)
Y = torch.ones((2, 3, 4))
print(Y)
"""
要特定的一些值;我也可以通过一个Python的列表来复制;我们这里再创建一个二维的一个数组;
这个告诉你是第一行的元素是2143;第二行的元素是1234;然后第三行的元素是啊4321;
然后这是一个列表;然后列表嵌套列表就是一个;list of list单子;我会创建一个二倍的东西出来;
这是一个二维的数字;当然我可以创造一个三维对吧;我再打一个框;放括号就会变成一个三维的数字;
你看到这是一个啊;你可以可以有两个框在这里对吧;如果我要打印它的shape的话;看到是说是一个三维的是134;
"""
print(torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]]))
"""
当然是说我能创建数组的后;我可以做一些比较常见的标准算数运算;加减乘除和指数;
所有的这些运算都是按元素进行的;所以我们先从比如说我们创建一个;
我们特别给了一个1.0;就是说这样子;我们创建的是一个浮点运算啊;就是如果你不你把这个0.1去掉的话;它变成整数了;
其实然后呢我做x加y;他就会按元素全部加起来;你可以认为是3460;
然后做减法按元素做减法;
按元素做乘法;
按元素做除法;
然后按元素求幂;就是对每一个x元素求二次方;
当然是说我还可以做更多计算了;就说我可以做指数对吧;就说按元素来;每个元素做一些指数的运算;
tensor([ 3., 4., 6., 10.])
tensor([-1., 0., 2., 6.])
tensor([ 2., 4., 8., 16.])
tensor([ 1., 4., 16., 64.])
tensor([0.5000, 1.0000, 2.0000, 4.0000])
tensor([2.7183e+00, 7.3891e+00, 5.4598e+01, 2.9810e+03])
"""
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
print(x + y)
print(x - y)
print(x * y)
print(x ** y)
print(x / y)
print(torch.exp(x))
"""
我们要把可以做一些张量之间的;或多元素组之间的一些操作啊;
比如说我们用一个;我们还是一样的生成一个;跟之前一样;
就说生成一个从0到11的元素;长为12的向量;把它reshape到3和4;
这里我们特别指定说你用float 32;就不要给我生成一个integer了
然后呢y也是一个啊;跟刚刚是一样的;是一个3*4的一个运算啊;他们两个的形状是一样的;
然后我们用cat;就是说我把这两个元素合并在一起;然后在第0维合并;定理位;就是在行就是你可以认为是在堆起来;
那这看到是说这个;就是说这是我们的第一个生成x;这是我们生成的y;然后我们是在按行上面合并起来;
然后我们可以说dimension等于1;就是按列;
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[ 2., 1., 4., 3.],
[ 1., 2., 3., 4.],
[ 4., 3., 2., 1.]])
tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],
[ 4., 5., 6., 7., 1., 2., 3., 4.],
[ 8., 9., 10., 11., 4., 3., 2., 1.]])
"""
X = torch.arange(12, dtype=torch.float32).reshape((3, 4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
print(torch.cat((X, Y), dim=0))
print(torch.cat((X, Y), dim=1))
"""
然后我们可以通过说;逻辑运算符来构建一个二维的张量;
就说我判一下y是不是等于x;
它就是按元素所谓的按元素值进行判;就说啊就这一个元素;
这两个元素是相等的;别的元素等于是都不相等;
tensor([[False, True, False, True],
[False, False, False, False],
[False, False, False, False]])
"""
print(X == Y)
"""
tensor(66.)
"""
print(X.sum())
"""
从numpy过来的;就是说一个叫广播机制;
这也是最容易出错的一个地方;就说如果你代码没写好啊;
看上去一切都在运行;实际上可能不是你想象那样子;
比如说;创建一个a;它是一个二维的数组;但是它是一个向量其实它是有三行;它有一列;
然后我创建一个b;它有一行两列你可以打印下去找;这样子对吧;这是a这是b;
我在做a加b;按照我们刚刚的定义;我们是按;a的每个元素和b的每个元素相加;
但它形状不一样啊;不一样怎么加呢;就是说在这个情况下;他有一个特殊的机制来帮你+;
就是说如果当我看到两个张量;有两个多元数组;就我们;其实张量和多元数组是混着用的;
好这两个张量形状不一样;但是呢;我可以有办法把它变成形状一样;为什么呢;
是因为你这里;首先我们的尾数是一样的啊;都是一个纬度等于2都是一个数组;如果你维度不一样就没戏了;因为纬度一样;然后呢第一个纬度我是3但你是一啊;第二个纬度虽然我们不一样;但是我是2你是一;所以的一个半是说;一个办法师说;我可以把我这个一的这一维度;复制一下;复制成两个;然后把我这个跟你不一样的地方;因为我是一嘛;我就可以把我复制成3下;这样子就会把;a复制成一个3*2的一个矩针;把b复制成一个啊3*2的矩针;然后再它相加;这样你可以看到是说;而我们加出来就是一个3*2的矩阵;了这就是一个广播机制;所以是说;很多时候;你如果可能没有想到说我要做广播;就说我就想把两个项链一加;但是你没想到一个项链没弄好;就是加了一个不小心;加了一个纬度和加了一个纬度;它就变成一个矩阵;相加就变成一个矩阵出来了;就不是你想象的那样子;所以这一块就是虽然它很方便;但是大家一定要注意说;有这个机制的存在啊;导致如果有问题的话;大家可能会;去想;这个事情是不是因为广播机制造成的;
tensor([[0],
[1],
[2]])
tensor([[0, 1]])
tensor([[0, 1],
[1, 2],
[2, 3]])
"""
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
print(a)
print(b)
print(a + b)
"""
然后我们来做一下元素的访问;我们之前有说过说;元素可以做哪些访问啊;
最简单X负1 就说把最后一行访问出来;;x 1-3就是说啊把第一行和啊第二行给拿出来就是x 1-3;
然后我们当然可以是说我要写值;我怎么写呢;我把第一行;就是它其实行还是从0开始啊;
所以第一行其实是说这个是第一行;然后第二列列是从0开始;所以你是写的是这个;是;你把这个元素的值写成9;
然后把x打印出来;你会发现啊别的值呢都没有变;就9就变化了;
tensor([ 8., 9., 10., 11.])
tensor([[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
"""
print(X[-1])
print(X[1:3])
"""
最后大概就是说;Python里面最常见的其实既不是pytorch;也不是Tensorflow;其实是numpy;
多元数组的运算框架;就是说;可能大家如果学Python数据编程的话;可能是从numpy学起的;
所以呢当然是所有的;不管是所有的框架;它都能够很方便的从numpy进行转换;
比如说x等于numpy;它会得到一个numpy的一个多元数组;当然你可以torch Tensor;
从一个numpy a拿回来;可以构建一个pytorch的一个Tensor;
你可以看到是说a的type;就是它的类型;它是一个numpy NDRA;
然后它的b是从numpy构建的;所以它是一个torch的一个Tensor;
所以这个是numpy 数据类型;这个是torch的数据类型;
当然如果你是大小唯一的张量的话;我可以变成一个Python的标量;
就是创建一个大小唯一的啊torch的Tensor啊;a当然它就是一个torch的Tensor啦;
OK把a点item拿出来它就是一个啊;number;的一个辅点数啊;当我可以说float a;也是变成一个Python的辅点数
int a;它就变成一个integer就是也是Python的;这就是转变;
<class 'numpy.ndarray'>
<class 'torch.Tensor'>
tensor([3.5000])
3.5
3.5
3
"""
A = X.numpy()
B = torch.tensor(A)
print(type(A))
print(type(B))
a = torch.tensor([3.5])
print(a)
print(a.item())
print(float(a))
print(int(a))
五、数据预处理
"""
数据预处理是说;如果我有一个原始数据;我怎么样把它读取进来;
使得我们通过;机器学习的方法能够处理;
我们这里给一个;几个非常简单的预处理;当之后我们随着课程的加深;我们会介绍更多的一些课程的处理;
首先我们创建一个人工的数据集;存在一个CSV文件里面;这是一个很小很小的文件;
然后呢;接下来就是说;我们把它存在一个CSV文件里面的话;
"""
import os
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每⾏表⽰⼀个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
"""
我们可以把它读取进来;一般读取CSV文件的话;一般用的是叫做pandas;
这个库也是说啊;作为数据科学家最常使用的一个库;可能它的;使用频率在跟numpy是差不多的频率;
OK我们如果你没有装pandas的话;是一个很小的Python的包;
然后我们import pandas;然后pandas的话;它提供了一个很简单的函数;叫做read CSV;
我们就把刚刚我们读取的文件读取进来;我们就可以打印在print在这个地方;
你会发现这里给你的你的第一行就是你每一个列的名字;接下来是说这有4行;我们运行一下;然后你当然可以print;
NumRooms Alley Price
0 NaN Pave 127500
1 2.0 NaN 106000
2 4.0 NaN 178100
3 NaN NaN 140000
"""
import pandas as pd
data = pd.read_csv(data_file)
print(data)
"""
接下来是说;注意到我们有一些数据是缺失的;
所以对于数据科学家来说;最重要的一件事情是说;怎么样处理缺失的数据;
或者说整个机器学习就是处理;缺失数据;就是你要预测未来;未来是什么样子;
我们不知道这是一个缺失的数据;当然这这里的话我们先不做预测;我们先说用很简单的方法;
我们把一些缺失的数据补起来啊;补的方法有很多种;最常见的包括如果有一个数据是缺失的话我们就把它丢掉;
把整个这一行丢掉;这是一个最常用的方法;当然很多时候我们说我们丢掉也太可惜了;
然后呢最常用的;这也是一个叫插值的方法;比如说我们这里怎么样进行插值;
首先呢我们数据我们先把它分成一个;输入的特征和输出;但我们现在没有讲;输入特征和输出是什么样子;
那没关系;我们就是说啊对一个data;它是一个;刚刚我们注意到是一个;4乘以3的一个表;
然后我们通过iloc就是index location;来把第一个的第0和第一列;和所有的行拿出来放在input里面;然后把最后一列拿出来放在output里面;
"""
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean())
"""
好那么接下来就是说;因为我们先把所有的缺失的值和所有的字符串全部变成了一个数值;
那么我们就可以变成一个;pytorch的Tensor了;然后我们input torch;
然后;到Tensor我们就把input values放进来;output values放进来;大家可以看到是说OK;
现在我们把一个CSV文件;转成了一个纯的;我们昨天提到过的一个张量了;
注意到这里是float 64;这个传统的Python一般会;默认浮点数会用float 64;但是64为浮点数啊一般计算比较慢;
对深度学习来讲;我们通常用32为浮点数;在这个就是一个非常简单的一个样例;
教大家怎么样把一个;CSV文件读取进来;做一定的特征预处理;然后变成一个pytorch的用的一个Tensor;
(tensor([[3., 1., 0.],
[2., 0., 1.],
[4., 0., 1.],
[3., 0., 1.]], dtype=torch.float64),
tensor([127500, 106000, 178100, 140000]))
"""
import torch
X, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
print(X,y)
六、D2L注意点
import torch
a = torch.arange(12)
b = a.reshape((3,4))
b[:] = 2
print(a)
"""
tensor([2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
"""
No.2 线性代数
一、标量
如果是标量的话我们做些简单的操作; 比如说c等于a加b; 然后c等于a乘b; 然后然后取个sin; 长度的话我们标量有长度; 它就是它绝对值; 如果大于0的话是a; 如果小于0的话就是负a; 长度我们有一些公式; a加b的绝对值小于等于a的绝对值加b的绝对值; a乘以b的绝对值; 等于a的绝对值乘b的绝对值; 这是标量的长度;

二、向量
1、基本操作
把标量拓展到向量; 标量就是一个数值; 向量就是我们刚刚提到的就是一行值; 你可以既既是行向量也是列向量; 但数学上我们并不太区分行和列啊; 这里a和b都是向量里面很多元素; c等于a加b那就; 是说c的第 i个元素等于a的i个元素加上b的i个元素; α是标量; b是向量的话那就α乘以b; 就是说啊; c的每一个元素等于i的元素; 等于α乘以bi; 如果做Sin的话也是每个元素做Sin;
好接下来是一个数学的概念; 长度; 就是向量的长度; 就是向量的每个元素的平方求和; 再开根号这它的长度; 就说a的长度原来是大于等于0的; 然后呢; 两个向量的长度小于等于a的长度加上b的长度; 就是三角定比; a乘以b; 就是说它等于啊; 如果a是一个标量的话; 那么它等于a的绝对值乘以b的向量的长度;

2、空间表示
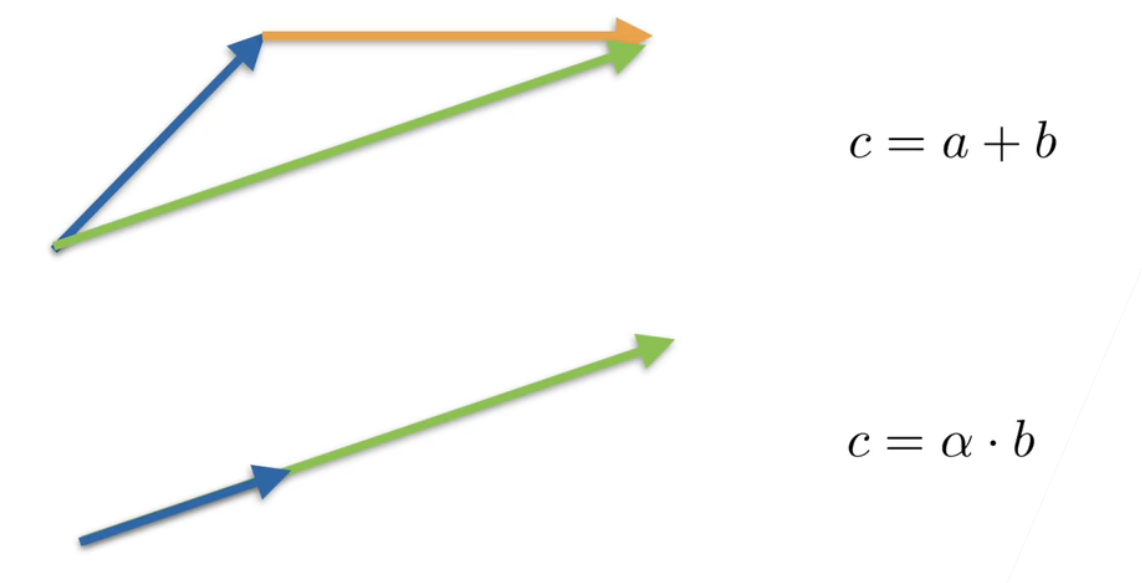
这向量; 向量可以给一个直观上理解; 这个是蓝色的是a的话; 黄色是b的话; a加b; 就是把这个两个向量接起来就是c; 就绿色c等于a加b; 如果a还是这个蓝色的;α是一个长度是个标量的话; 那就是说可以把它拉长;
3、乘法
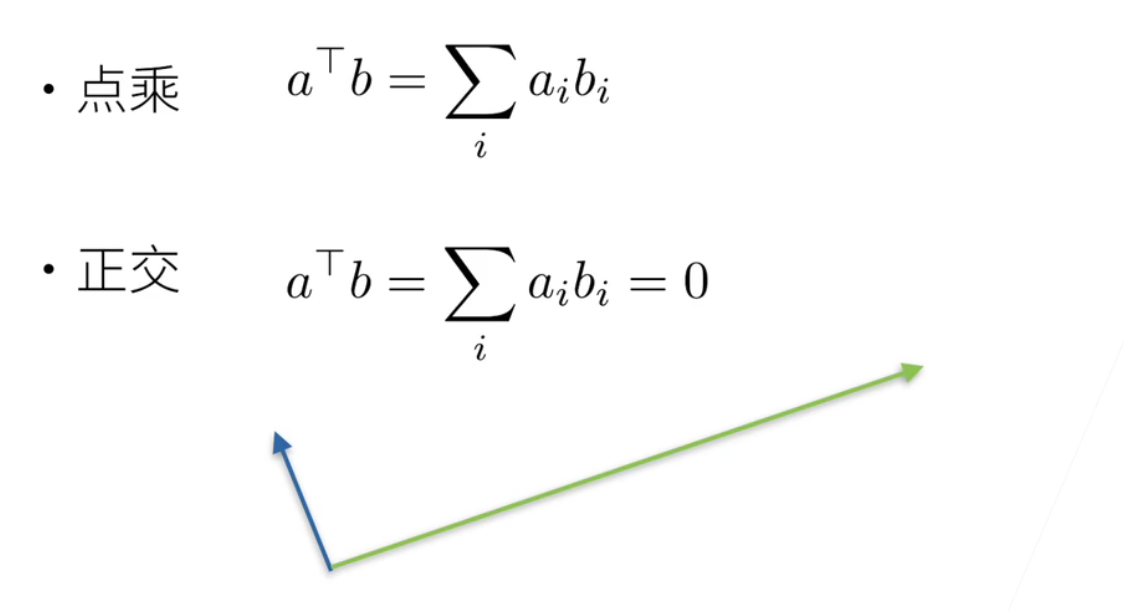
当我们可以做点积向量的话;就a的转置乘以b就等于把a的元素; i的元素乘以第一b的i的元素; 然后求和; 如果这两个向量是正交的话; 就是垂直的话; 那么他的求和是等于0的; 这是他这是正交向量
三、矩阵
1、基本操作
看到矩阵; 就说n行与n列; c等于a加b; 那就是也是每个元素相加; α标量乘以矩阵那就每个元素相乘; sin也是每个元素求sin; 这是一样的;
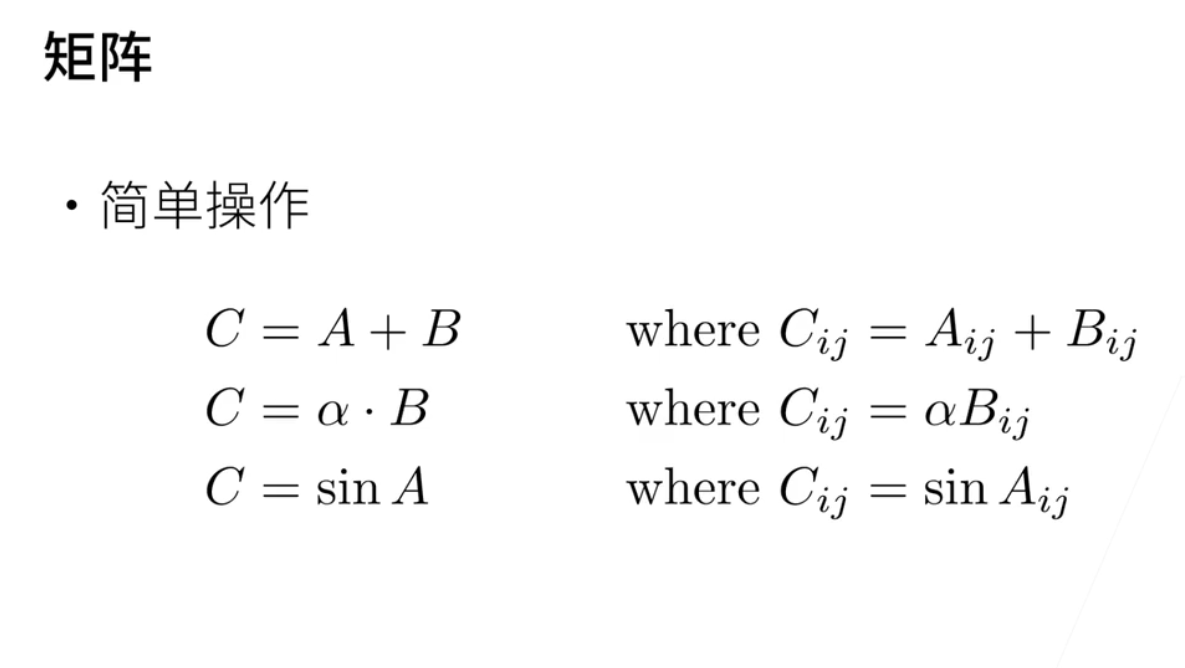
2、乘法
但是说矩阵会乘法会有一点的不一样; 矩阵a乘以b就是a是一个矩阵; b是一个向量; 那怎么乘呢; 就是说对 a的每一行; 乘以; b我们做一个列向量; 就是每一行和这个列像量做内积; 就是每一个元素; 乘起来然后求和; 写到第一行; 然后呢; 这一行第二行再跟他列向量做内积; 写到第二行; 第三行跟列向量做内积写到第三行; 这是矩阵的乘法; 因为之后的机器学习所有的模型; 矩阵乘法是最基础的;
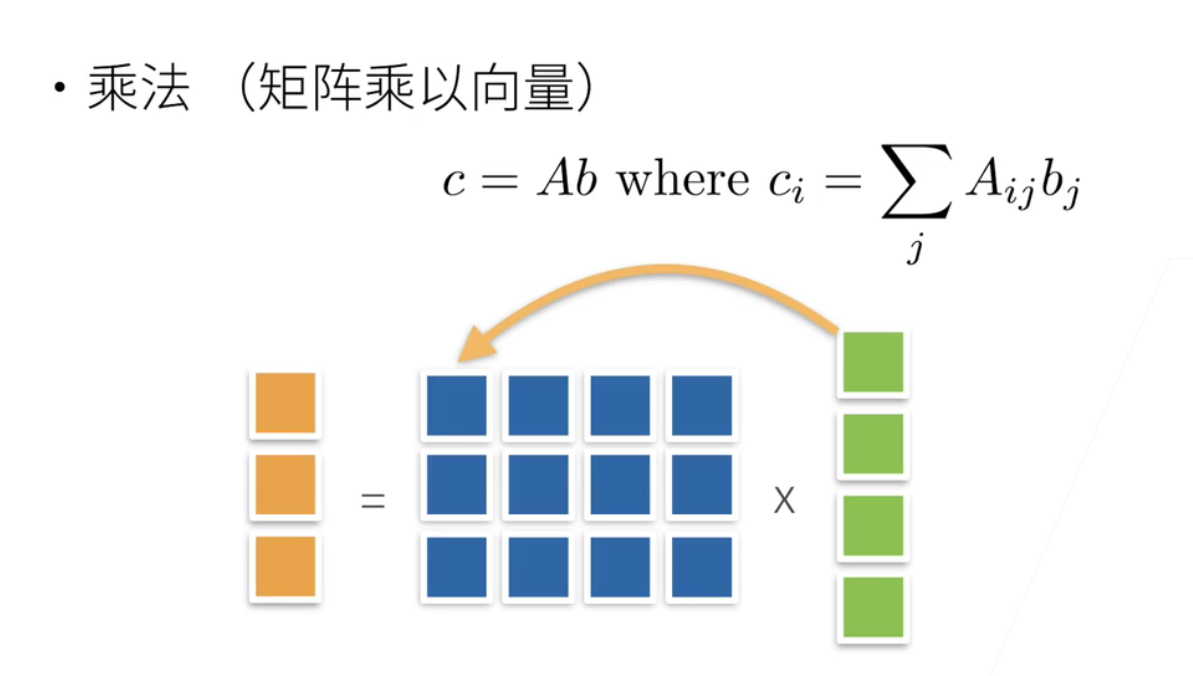
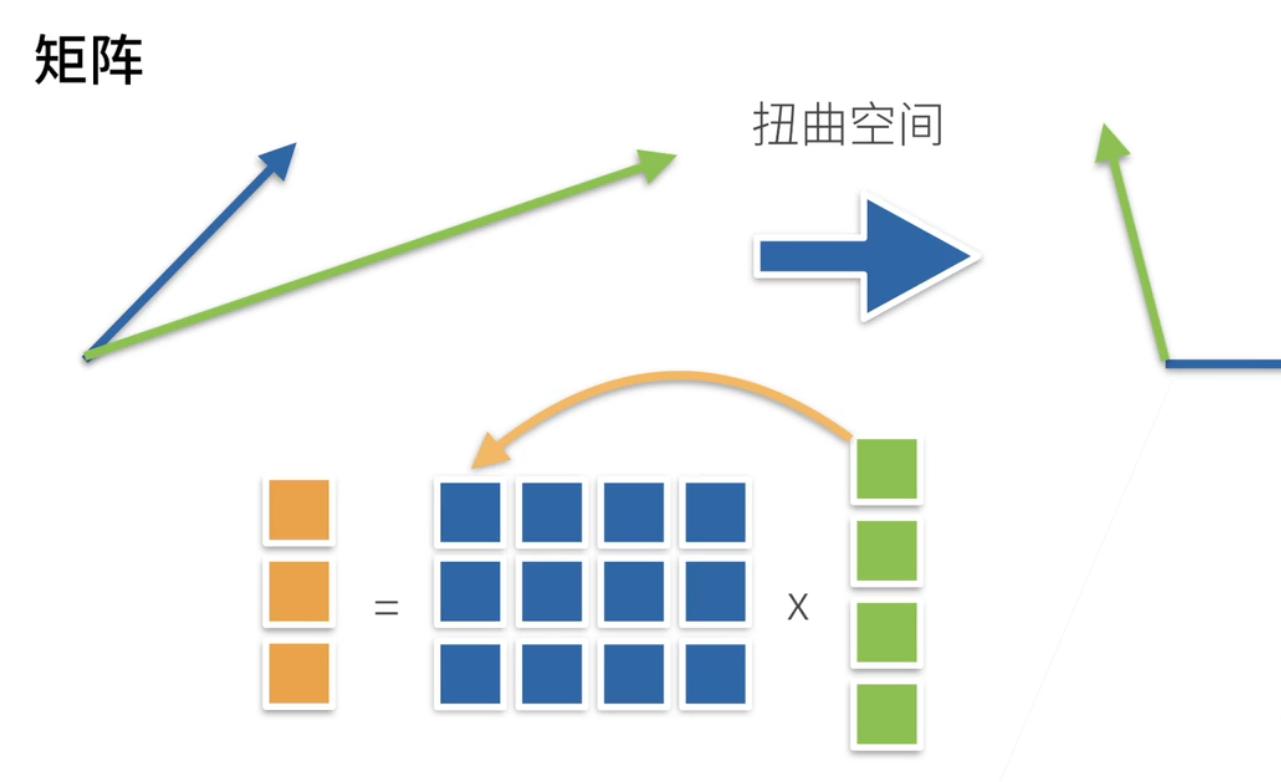
3、空间表示
然后矩阵乘法从直观上来说; 它是一个扭曲空间; 就说你可以认为是说我一个向量; 通过一个矩阵乘法; 变成了另外一个向量; 就是我这个矩阵; 其实是把一个空间进行了扭曲; 比如说这个是原始的两个向量; 通过矩阵乘法之后这个向量蓝向量变成这个蓝向量; 这个绿向量变成这个绿向量; 就说这个矩阵; 就是把整个空间进行到一个扭曲; 这是线形代数里面要讲的事情; 我们当然知道就行了;
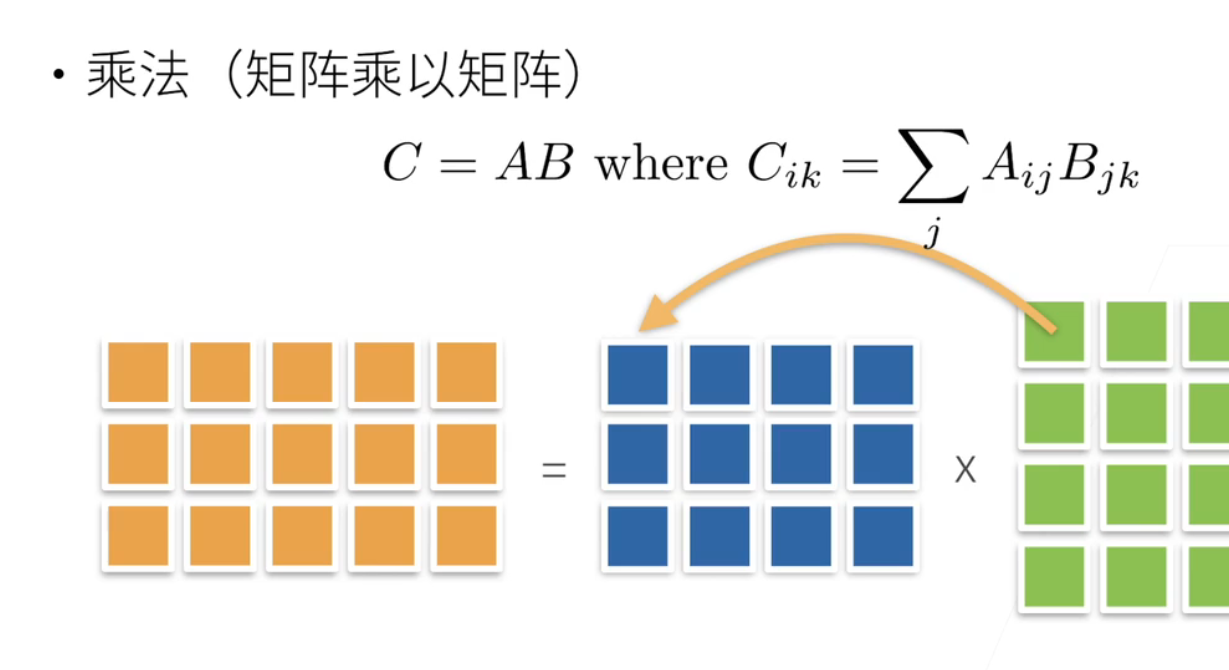
4、乘法
简单的矩阵乘法!
5、范数
然后当然矩阵一样的; 要长度就说我们叫做范数; 因为c和b都是向量的话; 因为c等于a乘以b; c的长度就向量的长度; 根据我们刚刚的定义一定会小于等于a的范数乘以b的范数; 然后这个取决于怎么衡量b和c的长度了; 就说常见的范数有矩阵范数; 就说最小的满足上面公式的值; 就说对于a的矩阵啊; f范数的话; 其实就是; 等着把这个矩阵拉成一条向量; 然后做一个向量的范数;就说把a的所有的元素乘平方全部加起来; 然后开根号就是啊f范数; 因为它f范数比较简单; 所以我们一般会用f范数; 就矩阵范数会算起来会比较麻烦一点; 我们一般是不去算的;

6、特殊矩阵
但有些特殊的矩阵就是说我是对称的; 和反对称; 就是说对称矩阵是说以这条线啊划一条线啊; 它在这条线上; 是一个对称的; 就说这两个元素是一样的; 这两个绿色是元素的是一样的; 就是Aij等于Aji; 反对称呢就说Aij等于负的Aji; 就是一个一是一半变成一个负数; 另外一个说正定; 正定是说啊如果一个矩阵是正定的话; 那就是说它这个矩阵乘任何一个行啊; 一个列向量和一个横向量; 它都大于等于0; 就是它是一个正定矩阵; 但我们不会用到太多正定矩阵啊; 这是一件啊深度学习比较好的事情;


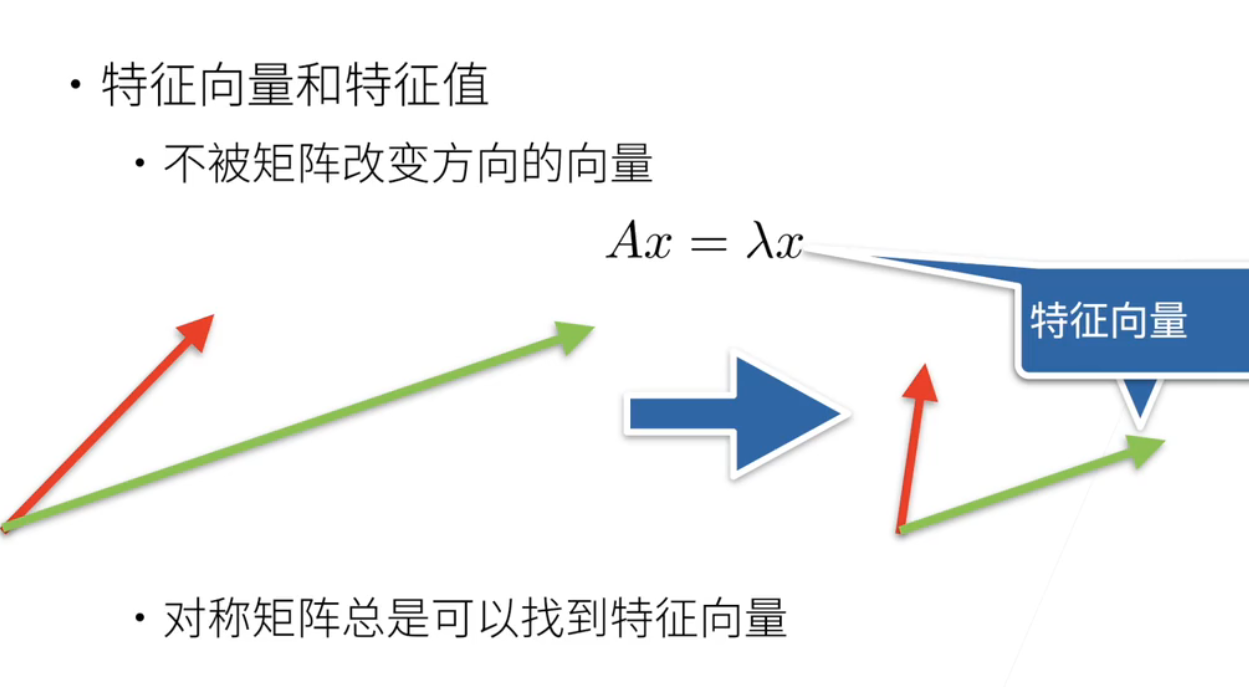
7、特征向量
就是特征向量和特征值; 就是说特征向量; 是说不被矩阵改变方向的向量; 我们说; 矩阵就是把一个空间进行一个扭曲; 但有一些特殊的一些向量不管; 被这个矩阵作用之后它不会改变; 就说比如说啊; 这个红色和一个蓝色的向量; 被a作用之后; 做到这里; 红色被改变了; 但绿色没有被改变; 就绿色的方向没有变; 但是大小变了没关系; 那么这个绿色就是特征向量; 这个就是一个直观上的理解啊; 对称矩阵总是能找到特征向量; 但不是每个矩阵都有特征向量;
四、D2L注意点:
1、矩阵克隆
在这里使用克隆的话;更改B的数值并不会影响到A的数值;如果使用B = A;这样只是给的索引;
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
B = A.clone() # 通过分配新内存,将A的一个副本分配给B
A, A + B
2、矩阵降维
关于2.3线性代数中的6降维需要重点理解;如何按照特定的轴做sum
举个例子;假设我们有个矩阵:5行4列;那么它的shape是[5,4]的list;它的维度就是2;并且它的axis:即它的轴;第一个轴是0;第二个轴是1;就是你的shape是一个list,那么第0轴就是第一个元素;2轴就是第二个元素;那么按照行就是轴为0;按照列就是轴为1;
如果按照axis=0来做sum的话,那么步骤就是按照第一列求sum;然后第二列求sum;以此类推得到的是一个长为4的行向量;
如果按照axis=1来做sum的话,同理;
如果是三维的话, shape[2,5,4] ;
如果按照axis=1来做sum的话,
五、QA
很多的东西啊~
No.3 矩阵计算
本节就说矩阵计算;其实是讲矩阵怎么求导数;因为对于机器学习;或者是说对于深度学习来讲;我们要知道怎么求导数;因为你的所有的优化模型的求解;都是通过求导数来进行的;
一、标量导数
首先回忆一下高中数学标量的导数;y是一个函数;对函数y在x上求导;a不是x函数的话;那么它对于x的导数呢;是0;如果y是x的n次方的话;那么它的导数;那就是n乘以x的n减一次方;如果y是x的指数的话;那么它的导数不变;如果它是log的话;它会变成了x分之一;sin变成cos
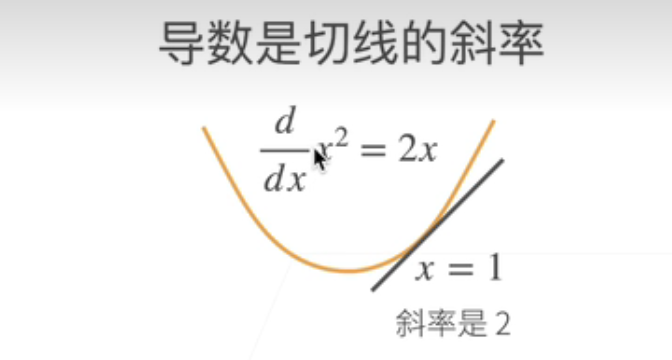
导数就是切线的斜率;就说比如说我有一个函数;y等于x的平方;那么画出来就是个黄线对吧;那么这个它的导数那就是2 x;然后呢在x等于1点的导数;那么把x等于一带进去那么它就是2;那么在x等于一这个点;我们可以画一个啊切线;那么切线这个斜率它就是2;就是导数的意义;
当然还有一些导数的一些基本的计算;就是说运算规则;就是说如果y是一个;u函数加上一个v函数的话;那么对x求导的话;那就是分别对u求导和对v求导;啊如果y是u乘以v的话;那么就是说啊对u求导;然后乘以v加上对v求导啊乘以啊u;我们对于y如果是一个u的函数;u是一个啊x的函数的话;那么y对x求导就是先对;啊问y是u的函数先对u求到;然后对u对x求到;它可以做一个分解就是一个链式法则;
在这里插入图片描述

二、亚导数
不一定存在导数的话会怎么办;就说我们将导数;拓展到不可微的导数的情况下;怎么办啊;这里举个简单例子;y是x的绝对值;那黄线就是这样子;在零点的时候它的切线不为一;就说你可以斜率等于0.5也行;等于-0.3也行;它都在这个线在这个函数的下面;那么就是说;我们可以通过一个叫亚导数;就是它的数学符号就是一个啊;那就说x大于0的话它是一;x小于0的话它是-1;但是在x等于0的时候;它可以在-1和一之间取任意的值;
另外一个例子是说你用的是最大化;这是Max x等于0;如果呢如果你x大于0的话那就是一;啊因为它就等于x的本身;如果你小于0的话它就等于0;因为它是一个常数;但如果x等;于0的话你可以a可以在;0和一之间都可以选择;都没关系;


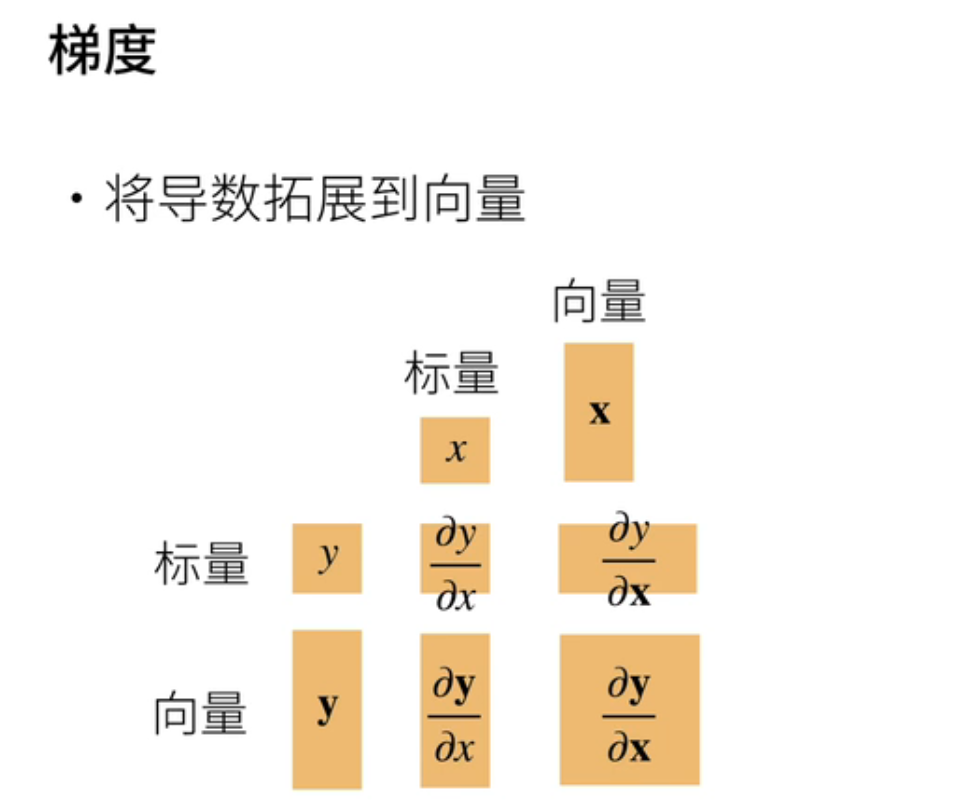
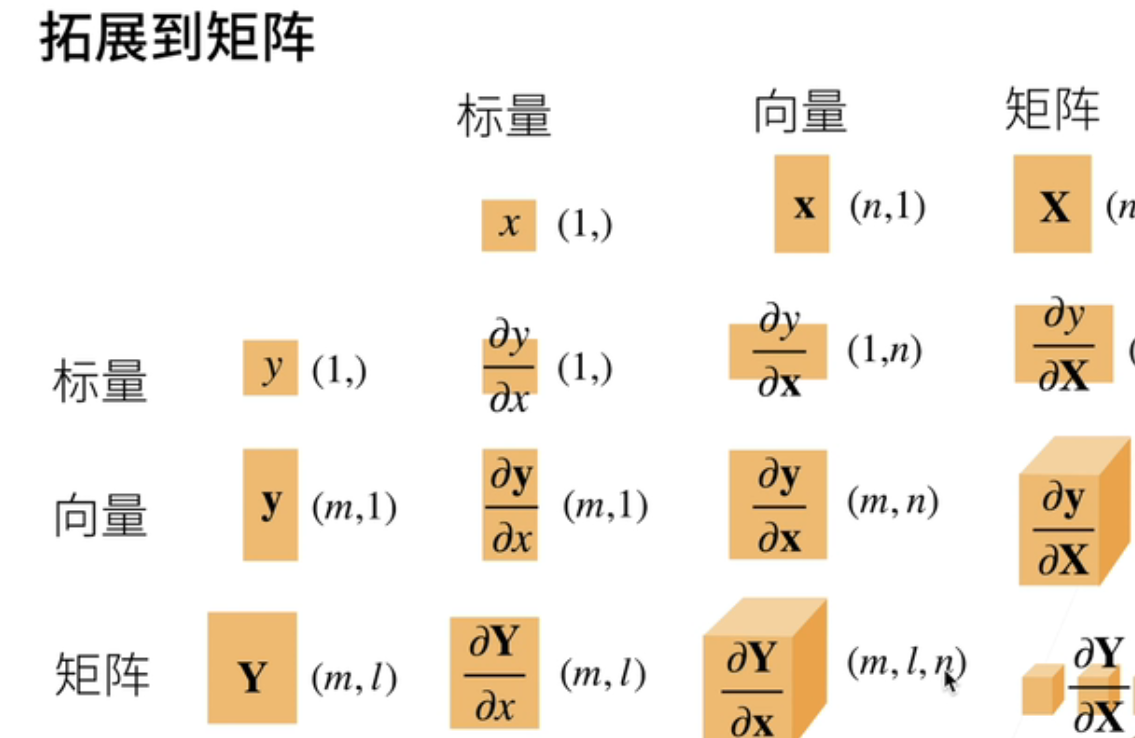
三、梯度
导数拓展到向量;通常我们叫梯度;就是说这里画了一张图;就是说最关键的是说你要搞得清形状;当你拓展到向量啊矩阵的时候;你要把形状搞对你形状;形状搞对了的话通常也就对了;就是说当你y是x的函数;y是标量;x是标量的话;它的求导当然是一个标量;当你如果是y是一个向量;x是标量的话它会变成一个向量;同样的话你y是一个标量;你x是向量的话;它也是一个向量;那如果两个都是向量的话;它会变成一个矩阵;
1、y是标量,x是向量
首先说我们考虑第一个情况;y是一个标量;x是一个向量;就X这是一个列向量;那么它的导数关于列向量的导数;它是一个行向量;就是大家理解一下就列会变行;它的第i个元素;那就是y是一个标量;关于x的第i个元素的导数;因为这两个都是标量对吧;我们知道怎么求了;
好举个例子啊;举个例子;那就是说x是一个长为2的一个向量;y呢;就是定义为第一个元素的平方加上2;乘以第二个元素的平方;那么就是说它的导数就是一个;那就是说;首先我们第一个元素那就是说X1;它要求导那就是2乘X1;第二个元素呢就是对X2求导;那就是4倍乘X2;这就它的导数它是一个行向量;
就是我们怎么理解这个东西呢;关键是一个理解;因为就是说大家可以不知道;导数怎么求;但是一定要需要他是怎么理解的;理解上来说就是说;这个东西我可以画成一个等高线;就是说这个函数X1的平方加上二乘以X2的平方;我可以做等高线;就是一个一个这样子椭圆的形状;那么呢对于X1和X2等于一和一这个点;我可以做等高线做切线;然后它的做一个正交方向出来;这个方向的值是一个2和4;它就跟你的梯度是一样的;你把X1和X2带值进去的话就变成24;就是说你的梯度就是跟你的等高线是正交的;意味着是说你的梯度指向呢;是你的值变化最大的那个方向;这是一个核心的概念;就是说;梯度一定指向你那一个值变化的最大的方向;通常是往大的直走;这个也是我们今后所有的;机器学习求解的一个核心思想;

好我们举个例子;还是刚刚那样的例子;首先y是一个标量;x是一个向量;当标量是一个跟x无关的函数的话;那么它是一个全零的一个向量;它是一个行向量;就是我们要转置来表示;如果是a乘以u的话;那么就是说你把a拿出来;然后对u对x求导;如果是求和的话;对x求和的话;那么就会变成一个全一的一个向量;
如果是它的;那就变成2乘以x的转置;同样的话我们之前如果是u加v的话;那么同样的话;我先对u就求导数和对v求导数;然后加起来;乘法的话是一样;就是说;关于u关于x的导数乘以v加上v;关于x的导数;再乘以u;如何累计的话;这也是比较有意思的情况;那就是啊;首先是u的转置乘以它关于啊v的;关于x的导数我们这里还没讲啊;就说两个向量;关于向量的导数它是一个矩阵;就是一个;行向量乘一个矩阵;再加上另外一个横向量乘一个矩阵;这就是一个;所以它的导数出来也是一个行向量;

2、y是向量,x是标量
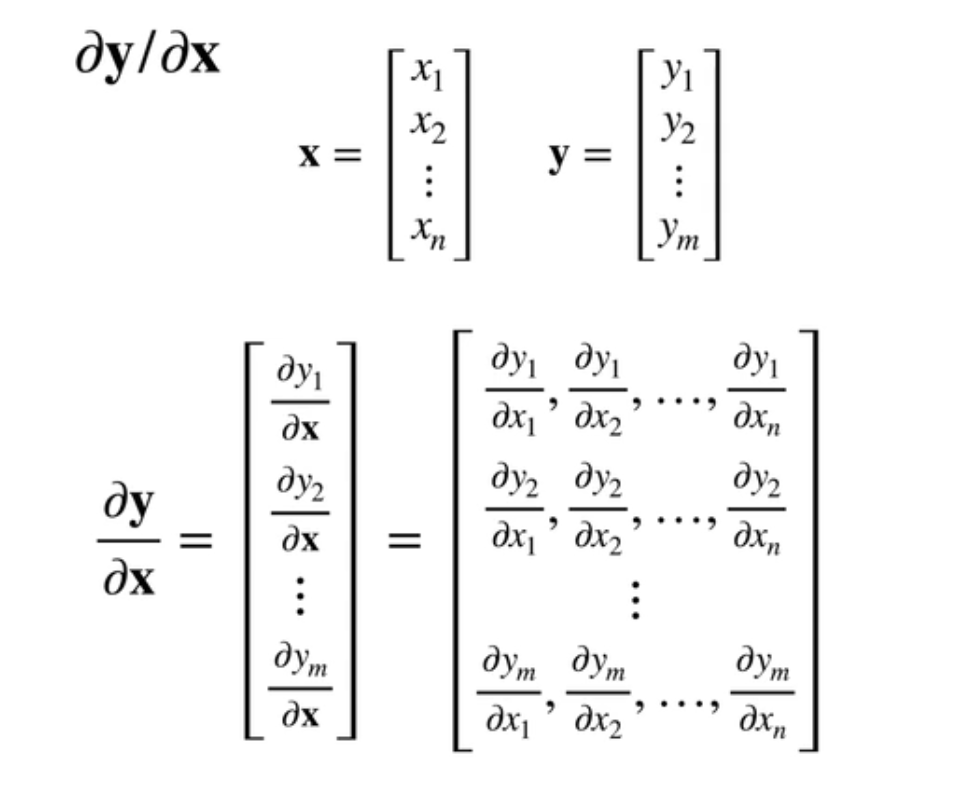
反过来讲;如果当你的上面的函数是一个向量;下面的函数是一个标量的话;假设y是一个列向量;那么关于列向量关于标量的导数;它也是一个列向量;就说刚刚是要会变现在是不变了;所以可以看到这个图;所以是说当你x是一个列向量;y是一个标量;那么它的导数是一个很怪的行向量;如果y是一个列向量;x是标量的话;那么它是一个跟它一样长的一个列向量;所以说这个被称之为分子啊;分子布局符号你可以反过来;你可以把它就是说它们行列可以交换;那就叫分母布局;就说你有哪个布局的没关系;只是说你必须要用一个布局;这样子你的形状是能对上的;所以我们这里一般是用分子布局方法;

3、y和x均是向量
那就是说我们刚刚提过啊;向量关于向量是一个矩阵;具体其实也挺简单的;就是说;y是一个向量;x是一个向量;那么呢因为y是一个向量对吧;所以啊;我先把它拆解成一个列的向量;然后每一列的那一个元素;第i个元素就是y的第i个元素;关于x的一个导数;它是一个横向量;那最后会变成一个矩阵;大家可以体会一下啊;就是说这里面每一个是一个行的;因为我们之前讲过;但是呢如果y作为本身的话;它是一个向量的话;那么它本身是一个列向量;所以最后会拉成一个矩阵出来;
举几个例子;就是说同样的话;你a是一个跟x无关的一个向量的话;那么它的输出是一个全0的一个向量;矩阵如果是啊;不然的话如果是本身的话;那他就会变成一个对角;就一个identity;矩阵;啊如果是a乘以x的话;y等于x乘以x的话;它的导数是a这个矩限的本身;如果你是反过来的话;你是一个x导啊转制成a的话;那么它导数就是a的转制的本身;这两个是非常有用的;我们之后可能会讲到的一个东西;然后呢同样的道理是说;如果是标量乘以u的话;那么呢就是我标量可以拎出来;如果是矩阵乘以u的话;矩阵而且是跟x无关的话;那么我可以把a拿出来;啊如果是u加上v的话;分别对u和对v求了;

4、y和x均是矩阵
这里基本不会;
输入拓展到矩阵;就是大家不要求全部能弄懂是怎么回事啊;首先说我们当你的y是一个标量;这是一个矩阵的话;刚刚记得吗;我们如果是向量的话;我们就把它其实转置了一下;我们可以把一个通过一个刚刚提到过;可以通过用一个二维的数组来区分行向量和列向量;如果你的项量是在下面的话;那么它的结果会要转一下;如果你矩阵的话;你会被和k和n会转至一下;同样的话;如果你矩阵在上面的话;你其实不会变化的;就是m乘l是不会变化的;当这里比较好玩的是说;当你的y是一个矩阵;你x是一;个向量的话;那等于是说你要把n放到后面;然后拎到最后这个地方;如果你的y和x都是一个矩阵的话;那就是更好玩了;就是说我们绕开一点啊;就是说前面两项是来自于y的m乘以l;但是呢后面两项是来自于x;但是你要把x给翻过来;就是k要放到这里然后n要放到最后;它就会变成一个四维的一个丈量啊;就是说你当然可以做到更高位的情况;就是说以此类推;可以做到更高位的情况;这就是我们的矩阵的技巧;
四、QA
1、导数作用
导数的作用主要是进行梯度下降;但容易陷入局部最优解;请问是不是可以通过Leap PROF函数;或者其他方法来使得下降得到全局最优解;这个问题就是说;如果你是凸函数的话你可以拿到最优;如果你不是突函数的话;其实你不管用;几乎是拿不到最优解的;就说当然你可以;理论上你数学是可以但从计算上来说;几乎是拿不到最优解的;这个真的是;啊一个不幸的消息啊;
而且机器学习几乎是不会处理凸函数就是说;如果你这个问题能得到最优解的话;那就是一个P的问题;我们机器学习不关心P问题;我们只关心NP的问题;所以大家不要去纠结最优解这个事情;
2、自动微分和计算图
pytorch和M开头的;采用的是自动微分和计算图;对的;我们马上就会讲自动微分和计算图;就说不会让你自己去求导;大家能够知道;导数大概是怎么算的;至少你的形状能够搞清楚;就说你必须要知道整个是怎么算出来的;但是你能大概理解导数的形状跟你的input的形状是;什么样一个变化的关系;我觉得这个比较重要;
No.4 自动求导
一、向量链式法则
标量的链式法则;就y是一个u的一个函数;u是关于x的一个函数;那么y对x求导的话;那就是说我先把y;把u做成一个变量进来求导;然后然后把u做成一个函数关于x的导数;你要拓展到向量;拓展到向量;最大的问题说你要把形状搞对;就说当你的y是一个标量;x是一个向量;那么呢首先u也是一个标量;那么呢这个当然是个标量;u关于x;它就是一个一乘以n的一个东西;那么一乘它就变成一乘n;就是这个形状不发生变化;那假设u是一个向量那怎么办呢;那就y关于u;那还是一个一乘k;假设u是一个k尾的一个向量;那是一乘k;那么呢;u关于x它是一个k乘n的一个矩阵;那么它一乘还会变成一乘n;然后你的y是一个向量;x是一个向量u也是一个向量;同样的道理;假设你的是一个m乘n的话;那么它就是u是一个长为k的话;那么它是一个m乘k;然后它是一个k乘n这样子矩阵;两个矩阵一乘;它还是变成一个m乘n的一个矩阵

我们举两个例子具体是怎么计算的这几个;这就是一个我们之后要讲的线性回归的一个例子;首先;假设x和w它都是一个长n的向量;y是一个标量;那么的函数z是说x和w做内积;减去y然后做平方;那我们要计算z关于w的一个导数;那我们怎么做呢;那我们就是先分解吧;我们先把它写开;首先说我记一个a中间变量a;它是x和w的内积;b是a减去y;然后z是等于b的平方;这样子我们把它分解成三个步骤;然后我们用链式法则;
那z关于w的导数那就是说;z关于b的导数;b关于a的导数a关于w的导数;然后我们把这个z b a的定义展开;那就b的平方关于b;a减y关于a;x和w的内积关于w;那么第一项我们知道就是2b对吧;那么这一块就是因为它是一个;就是一;这一块我们之前有讲到;它就是x的转置;那么再把b的定义拆开;就b是怎么定义的;然后它长成这个样子;那么就会得到说z关于w的导数;那就是;w和x的内积减去y然后乘以x的转置;这是一个标量;所以它是说因为它是一个;它的向量在下面;所以它出来的是一个转置的一个向量;
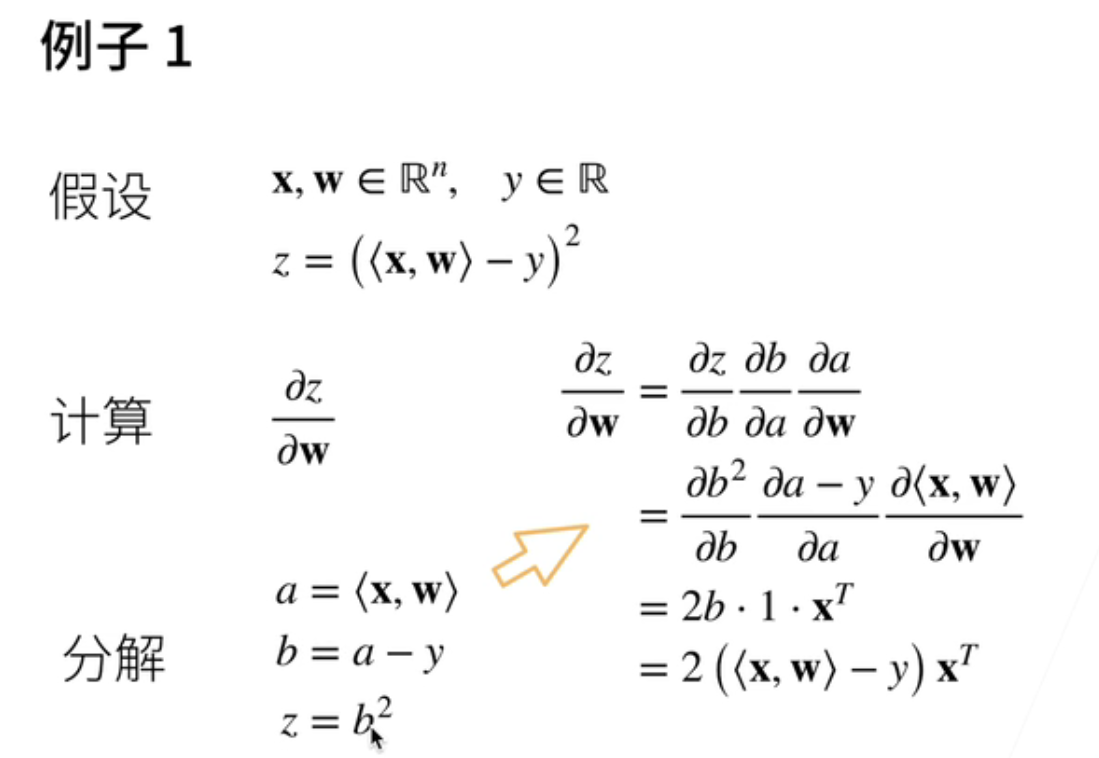
涉及到矩阵了;x是一个m乘以n的一个矩阵;乘以w;一个向量减去另外一个向量做;同样的道理它是一个标量对吧;所以我要对标量对于向量求导;其实这个跟之前是一样的;我们就是说;首先我就运用中间变量;a是一个向量等于x乘以w;b等于a减去y;z就等于b的||;同样的话我们用这个展开;好我们就不详细讲了;那么就说它的本身是一个2的;b的转质;乘以它是一个ident;那就是说一个identity Matrix;它呢我们刚刚讲过它就是x的本身;那么最后的把b展开的话那就是;x乘以w减去y的转值乘以x然后乘2;

二、自动求导
到现在是说我们能够做一个;如果你真的给我一个函数;我能够通过链式法则;和一些很基础的导数的;我可以帮你一个一个展开;但是呢最大的问题是说;神经网络动不动就几百层;几乎是你手写是很难的一件事情;所以呢我们需要说能够自动求导;意思是说;一个函数在指定值上我要做求导数;
它其实还有两种不一样的定义;一个叫符号求导;如果大家用过mathematic卡的话;就是我给你个函数;我能把你的导数求出来;而且这是个显示的计算;另外一个是叫数字值求导;就是说我给你任何一个f x;我不需要知道f本身长什么样子;然后我能通过数值去拟合这个导数;就是说我用一个很小很小的h减去f x除以h;所以我们来讲一下;自动求导是怎么做出来的;
这个涉及到一个叫计算图的概念;就是说虽然我们就说用了pyTorch;不需要去大家去理解计算图;但是我觉得大家有必要去知道下;它的内部的一个是怎么样工作原理;就说这样子的话;你如果用Tens或用别的话;你大概能够理解计算图是什么样子;

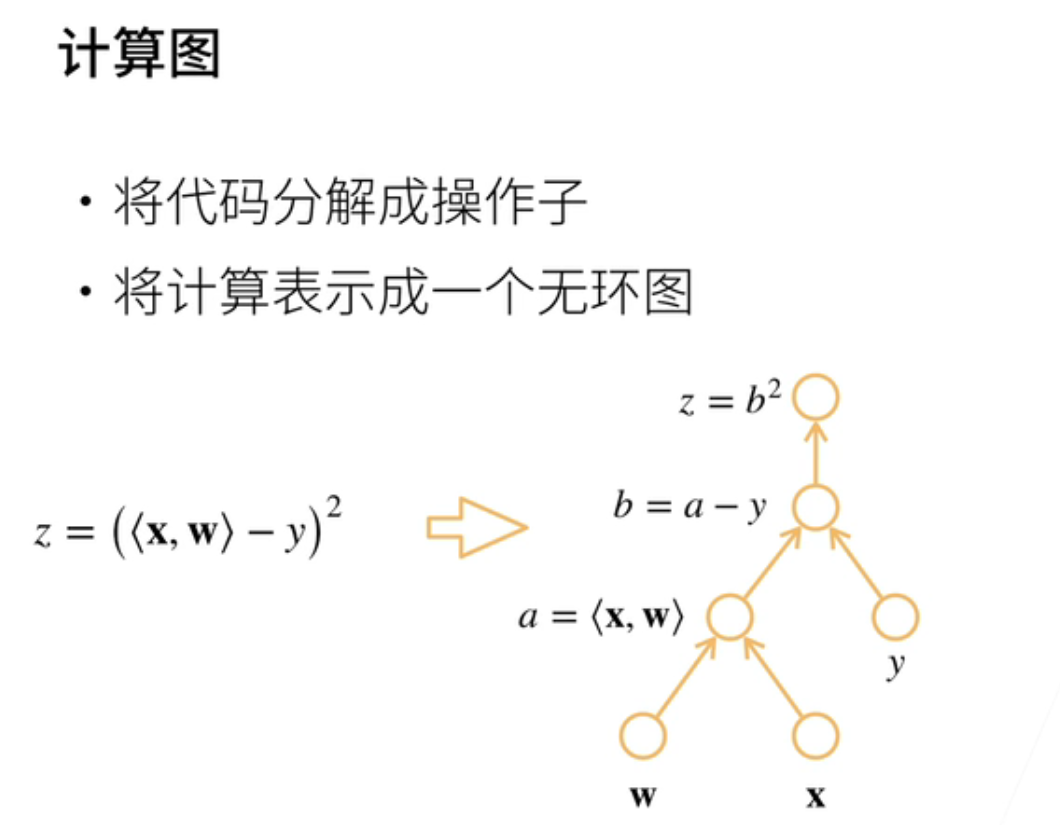
三、计算图
就计算图;其实本质上就等在于我们刚刚用链式法则的一个求导的一个过程;首先我们将代码分解成操作子;就是说一步一步把它展开;然后我们再将;计算表示成一个无环的图;就是我们还是用刚刚那个样例;那就是说z等于x w;内积减去y然后求平方;那我们怎么做呢;就是按照刚刚的做法;我们把一步一步做成;加入两个中间变量a和b;把它每一个这样子做成很基本的计算值;所以每个圈就表示一个操作;但也可以表示一个输入对吧;这个圈表示w;这个圈表示x;然后这个圈表示a;是在这里做计算呢;y再把a 和y输入进去就会得到b;最后输入b得到z;这就是计算图了;就计算图就是一个无环的一个图;
这个~~~

四、自动求导的两种模式
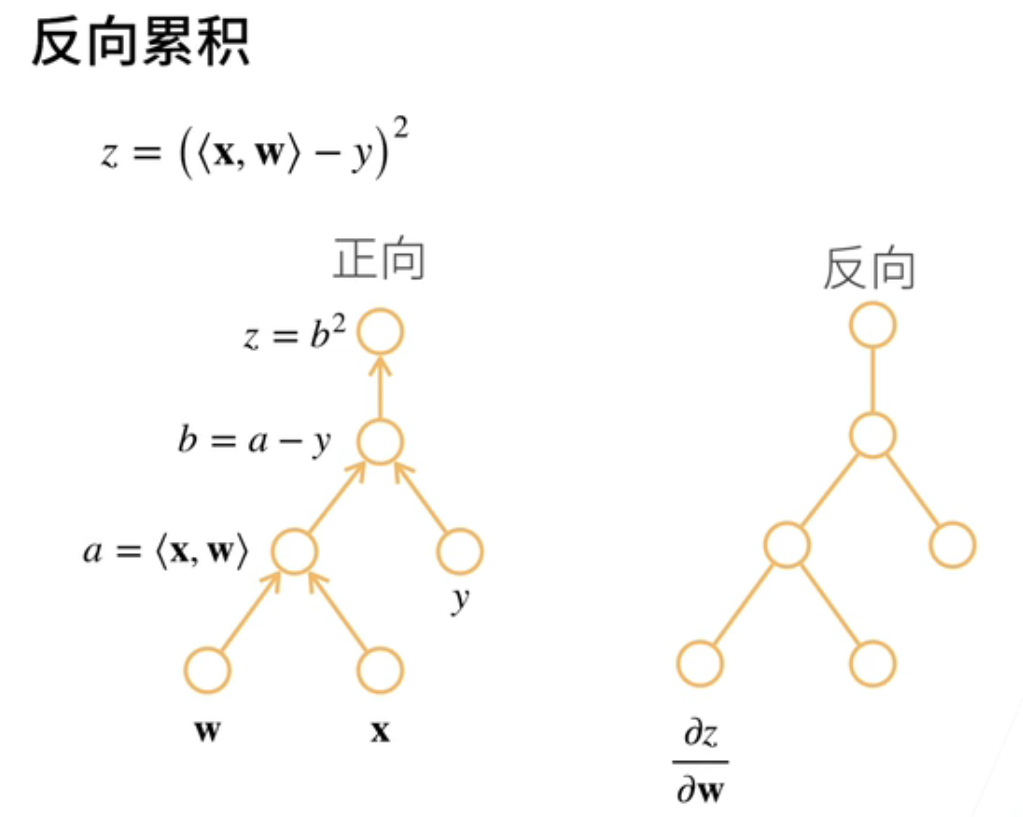
有两种自动求导的方式;就说回一下链式法则;要假设我y是关于x的一个函数;那么我要计算这个整个过程的话;我有两种方法;一个是正着计算或者一个反着计算;正的计算就是说我先把我从x出发;U1关于x的导数求出来;U2关于X1的导数求出来然后一乘;再往下往下往下往下最后算出来;
我也可以反过来;反过来怎么做呢;就是说我先计算;y就是最终的函数;关于最后的中间变量的一个导数;它乘以倒数第二个;然后再往前往前往前;一直算到最最前面;这个又叫反向传递;就是说;自动求导是一个很古老的一个领域;然后呢;它这个反向累积在人工智能里面;它是大名鼎鼎叫做Back;叫反向传递;其实是一个东西;

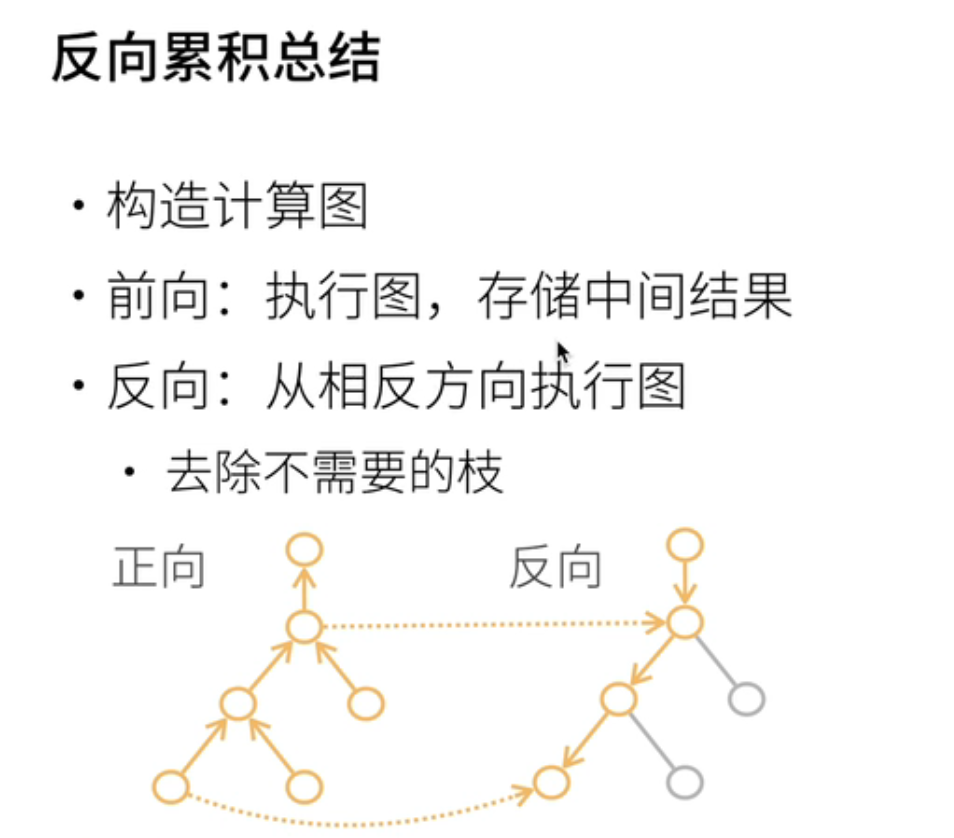
五、反向累积
反向传递是到底是怎么样计算的;好我们首先说正向是这样子算的;我们刚刚讲过了正向;好我们来看一下反向;反向是说我先来算z关于b的导数;那就是我需要去;他就等于2乘以b对吧;根据那个然后呢;因为b是我们之前的计算的结果;就是说你;我需要在那;我需要把之前的b的计算给你;存在那个地方;然后把它读出来;就说我需要读取之前的结果;同样的话;我可以计算z关于a的一个导数;它就等于是说我们之前有这个结果了;可以算出来;最后我们计算z关于w的一个导数;我需要既需要知道这个值;也需要知道w这个值;就说从这里过来;就说我需要两个值都需要知道;然后所以的话;反向累积的话;就是说我前向计算的时候;我需要把所有的中间的值给你存下来;但反向执行的话;我就是说我就沿着反方向进行;如果我这两个值的导数不需要的话;我就不计算了;但是呢我需要把这些;中间结果全部拿过来用;
所以的话它的复杂度是什么样子呢;假设我有n个这样子操作子的话;就说比如说我有我的神经网络有n层;那么正向和反向的代价其实差不多的;就是你正的跑一遍反的跑一遍;就是说你到之后我们看到;神机网络的forward和backward;它的计算复杂度差不多;但是比较;重要的是说它的内存复杂度是O(n);就是说你需要把;正向计算里面;所有的中间结构给你存起来;这个是给我们说;深度神经网络特别耗GPU资源;这是因为做;求梯度的时候;需要把前面的结果全都给你存下来;
另外一个我们提到是说正向累积;正向累积的好处是说;它的内存复杂度是ON ;就是说不管我要有多深;我我不需要存任何的结果;但他的问题是说;我计算一个遍了梯度需要扫一遍;这个的话我还是需要再扫一遍;所以是说;这个我们通常在神经网络里面不会用;因为我们需要对每一层计算梯度;所以这个计算复杂度太高;

六、D2L注意点
1、梯度存储问题
在计算梯度之前,需要一个地方来存储梯度,
x.requires_grad_(True) # 等价于x=torch.arange(4.0,requires_grad=True)
x.grad #通过这个就可以以后访问梯度了;即y关于x的导数是放在了这个地方的;
2、求导问题
其实深度学习中大部分y都是标量;即之前学的向量对向量的求导在深度学习中是用的很少的