一、题目
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
示例 1:
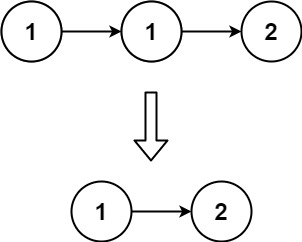
输入:head = [1,1,2] 输出:[1,2]
示例 2:
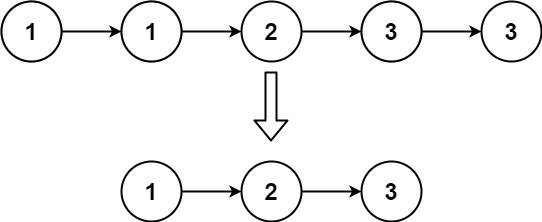
输入:head = [1,1,2,3,3] 输出:[1,2,3]
提示:
- 链表中节点数目在范围
[0, 300]内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序 排列
二、思路解析
首先明确下思路:先判断 head 为空的情况,直接返回 head 即可;
其他均为正常数据,那我们就只要定义个 cur 变量,让他遍历整个链表,找到 cur.next.val == cur.val ,直接把这个元素的 next 域赋值为 该元素.next.next 的值即可,也就是让他绕过一个重复元素的意思。
而不是这种情况的话,就属于数值不相等的,那我们直接让 cur = cur.next 即可,也就是让 cur 变量继续遍历下去,有点类似遍历数组中的 i++。
最后,整个链表就重新串起来了,我们返回 head 即可。
三、完整代码
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode deleteDuplicates(ListNode head) {
if(head == null){
return head;
}
ListNode cur = head;
while(cur.next!=null){
if(cur.next.val==cur.val){
cur.next =cur.next.next;
}else{
cur=cur.next;
}
}
return head;
}
}以上就是本篇博客的全部内容啦,如有不足之处,还请各位指出,期待能和各位一起进步!