目录
Java八种数据类型
注意:
四个大类
整型(byte、short、int、long)
注意
浮点型(float、double)
神奇的代码
注意:
字符型(char)
布尔型(boolean)
注意
类型转换
自动类型转换(隐式)
强制类型转换(显式)
类型提升
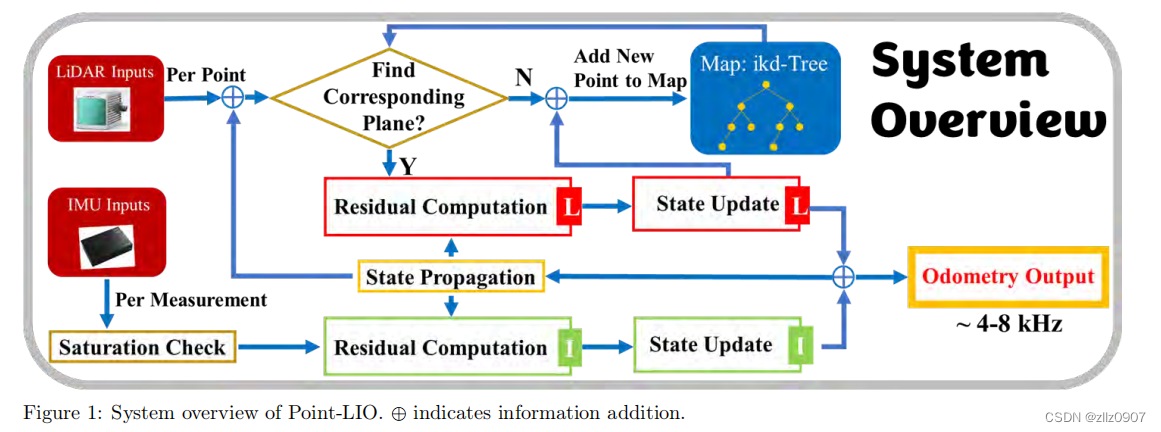
Java八种数据类型
|
数据类型
|
关键字
|
内存占用
|
范围
| 包装类 |
|
字节型
|
byte
|
1
字节
|
-128 ~ 127
| Byte |
|
短整型
|
short
|
2
字节
|
-32768 ~ 32767
| Short |
|
整型
|
int
|
4
字节
| -2147483648~2147483647 | Integer |
|
长整型
|
long
|
8
字节
| -9223372036854774808~9223372036854774807 | Long |
|
单精度浮点数
|
float
|
4
字节
| 3.402823e+38~1.401298e-45 | Float |
|
双精度浮点数
|
double
|
8
字节
| 1.797693e+308~4.9000000e-324 | Double |
|
字符型
|
char
|
2
字节
|
0 ~ 65535
| Character |
|
布尔型
|
boolean
|
没有明确规定
|
true
和
false
| Boolean |
注意:
- 不论是在 16位系统还是 32位系统,int都占用4个字节,long都占8个字节
- 整形和浮点型都是带有符号的
- 整型默认为 int型,浮点型默认为 double
- 字符串属于引用类型
四个大类
我们可以笼统的将这8种数据类型分为4个大类,分别是:
- 整型
- 浮点型
- 字符型
- 布尔型
整型(byte、short、int、long)
他们的数值取值按照从小到大排列
byte 的取值范围:-128~127 (-2^7) ~ (2^7-1)
short 的取值范围:-32768~32767 (-2^15) ~ (2^15-1)
int 的取值范围:-2147483648~2147483647 (2^31) ~ (2^31-1)
long 的取值范围:-9223372036854774808~9223372036854774807 (-2^63) ~ (2^63-1)
当然我们也可以使用代码来展示他们的范围:
// byte型变量所能表示的范围:
System.Out.println(Byte.MIN_VALUE);
System.Out.println(Byte.MAX_VALUE);
// short型变量所能表示的范围:
System.Out.println(Short.MIN_VALUE);
System.Out.println(Short.MAX_VALUE);
// int型变量所能表示的范围:
System.Out.println(Integer.MIN_VALUE);
System.Out.println(Integer.MAX_VALUE);
// long型变量所能表示的范围:这个数据范围远超过 int 的表示范围. 足够绝大部分的工程场景使用
System.Out.println(Long.MIN_VALUE);
System.Out.println(Long.MAX_VALUE);注意
在定义变量时,所赋值不能超过变量的范围,不然编译时会报错
int d = 12345678901234; // 编译时报错,初值超过了int的范围为了区分 int 和 long 类型,一般建议: long 类型变量的初始值之后加 L 或者 l ,一般更加以加大写 L ,因为小写 l 与 1 不好区分
long c = 10L; // 为了区分int和long类型,一般建议:long类型变量的初始值之后加L或者l
long d = 10l; // 一般更加以加大写L,因为小写l与1不好区分浮点型(float、double)
float 和 double 都是表示浮点型的数据类型,它们之间的区别在于精确度的不同, double 类型的数据精度要更高一点,但是这里的精度是相对的, double 类型的内存布局遵守 IEEE 754 标准(和C语言一样), 尝试使用有限的内存空间表示可能无限的小数, 势必会存在一定的精度误差,因此浮点数是个近似值,并不是精确值。我们可以看看下面这段代码,思考输出会是什么?
神奇的代码
double num = 1.1;
System.out.println(num * num); // 输出1.21吗?很可惜的是,它的输出和我们预期的并不一样,小数末尾多了个2,这就是我们所说的精度的误差1.2100000000000002
注意:
带小数点的字面量默认属于double类型,所以声明一个float类型的变量时,都要在数字后面加上 F 或 f
字符型(char)
关于字符型,Java和C语言最大的区别就在于:C 语言中使用 ASCII 表示字符,而 Java 中使用 Unicode 表示字符,因此一个字符占用两个字节, 表示的字符种类更多
因此,我们有一下初始化方式:
// 大写字母
char c1 = 'A';
// 数字字符
char c2 = '1';
//中文字符
char c3 = '帅';
//数字
char c4 = 1010; 布尔型(boolean)
boolean 型只有两个取值 true 和 false
注意
boolean value = true;
System.out.println(value + 1);代码编译会报错: 二元运算符 '+' 的操作数类型错误第一个类型 : boolean第二个类型 : int
类型转换
int a = 10;
long b = 100L;
b = a; // 可以通过编译
a = b; // 编译失败- 自动类型转换(隐式)
- 强制类型转换(显式)
自动类型转换(隐式)
- 自动类型转换即:代码不需要经过任何处理,在代码编译时,编译器会自动进行处理
- 特点:数据范围小的转为数据范围大的时会自动进行
System.Out.println(1024); // 整型默认情况下是int
System.Out.println(3.14); // 浮点型默认情况下是double
int a = 100;
long b = 10L;
b = a; // a和b都是整形,a的范围小,b的范围大,当将a赋值给b时,编译器会自动将a提升为long类型,然后赋值
a = b; // 编译报错,long的范围比int范围大,会有数据丢失,不安全
float f = 3.14F;
double d = 5.12;
d = f; // 编译器会将f转换为double,然后进行赋值
f = d; // double表示数据范围大,直接将float交给double会有数据丢失,不安全
byte b1 = 100; // 编译通过,100没有超过byte的范围,编译器隐式将100转换为byte
byte b2 = 257; // 编译失败,257超过了byte的数据范围,有数据丢失强制类型转换(显式)
- 强制类型转换:当进行操作时,代码需要经过一定的格式处理,不能自动完成
- 特点:数据范围大的到数据范围小的
int a = 10;
long b = 100L;
b = a; // int-->long,数据范围由小到大,隐式转换
a = (int)b; // long-->int, 数据范围由大到小,需要强转,否则编译失败
float f = 3.14F;
double d = 5.12;
d = f; // float-->double,数据范围由小到大,隐式转换
f = (float)d; // double-->float, 数据范围由大到小,需要强转,否则编译失败
a = d; // 报错,类型不兼容
a = (int)d; // int没有double表示的数据范围大,需要强转,小数点之后全部丢弃
byte b1 = 100; // 100默认为int,没有超过byte范围,隐式转换
byte b2 = (byte)257; // 257默认为int,超过byte范围,需要显示转换,否则报错
boolean flag = true;
a = flag; // 编译失败:类型不兼容
flag = a; // 编译失败:类型不兼容类型提升
int a = 10;
long b = 20;
int c = a + b; // 编译出错: a + b==》int + long--> long + long 赋值给int时会丢失数据
long d = a + b; // 编译成功:a + b==>int + long--->long + long 赋值给long