煤矿视频监控分析检测利用python基于yolo深度学习架构,对现场画面进行实时分析检测。我们使用YOLO(你只看一次)算法进行对象检测。YOLO是一个聪明的卷积神经网络(CNN),用于实时进行目标检测。该算法将单个神经网络应用于完整的图像,然后将图像划分为多个区域,并预测每个区域的边界框和概率。这些边界框是由预测的概率加权的。要理解YOLO,我们首先要分别理解这两个模型。
我们选择当下YOLO最新的卷积神经网络YOLOv5来进行皮带识别检测。而且这一次的YOLOv5是完全基于PyTorch实现的!在我们还对YOLOv4的各种高端操作、丰富的实验对比惊叹不已时,YOLOv5又带来了更强实时目标检测技术。按照官方给出的数目,现版本的YOLOv5每个图像的推理时间最快0.007秒,即每秒140帧(FPS),但YOLOv5的权重文件大小只有YOLOv4的1/9。
在YOLO系列算法中,针对不同的数据集,都需要设定特定长宽的锚点框。在网络训练阶段,模型在初始锚点框的基础上输出对应的预测框,计算其与GT框之间的差距,并执行反向更新操作,从而更新整个网络的参数,因此设定初始锚点框也是比较关键的一环。在YOLOv3和YOLOv4检测算法中,训练不同的数据集时,都是通过单独的程序运行来获得初始锚点框。YOLOv5中将此功能嵌入到代码中,每次训练时,根据数据集的名称自适应的计算出最佳的锚点框,用户可以根据自己的需求将功能关闭或者打开,具体的指令为parser.add_argument(’–noautoanchor’, action=‘store_ true’, help=‘disable autoanchor check’),如果需要打开,只需要在训练代码时增加–noautoanch or选项即可。
Adapter接口定义了如下方法:
public abstract void registerDataSetObserver (DataSetObserver observer)
Adapter表示一个数据源,这个数据源是有可能发生变化的,比如增加了数据、删除了数据、修改了数据,当数据发生变化的时候,它要通知相应的AdapterView做出相应的改变。为了实现这个功能,Adapter使用了观察者模式,Adapter本身相当于被观察的对象,AdapterView相当于观察者,通过调用registerDataSetObserver方法,给Adapter注册观察者。
public abstract void unregisterDataSetObserver (DataSetObserver observer)
通过调用unregisterDataSetObserver方法,反注册观察者。
public abstract int getCount ()
返回Adapter中数据的数量。
public abstract Object getItem (int position)
Adapter中的数据类似于数组,里面每一项就是对应一条数据,每条数据都有一个索引位置,即position,根据position可以获取Adapter中对应的数据项。
public abstract long getItemId (int position)
获取指定position数据项的id,通常情况下会将position作为id。在Adapter中,相对来说,position使用比id使用频率更高。



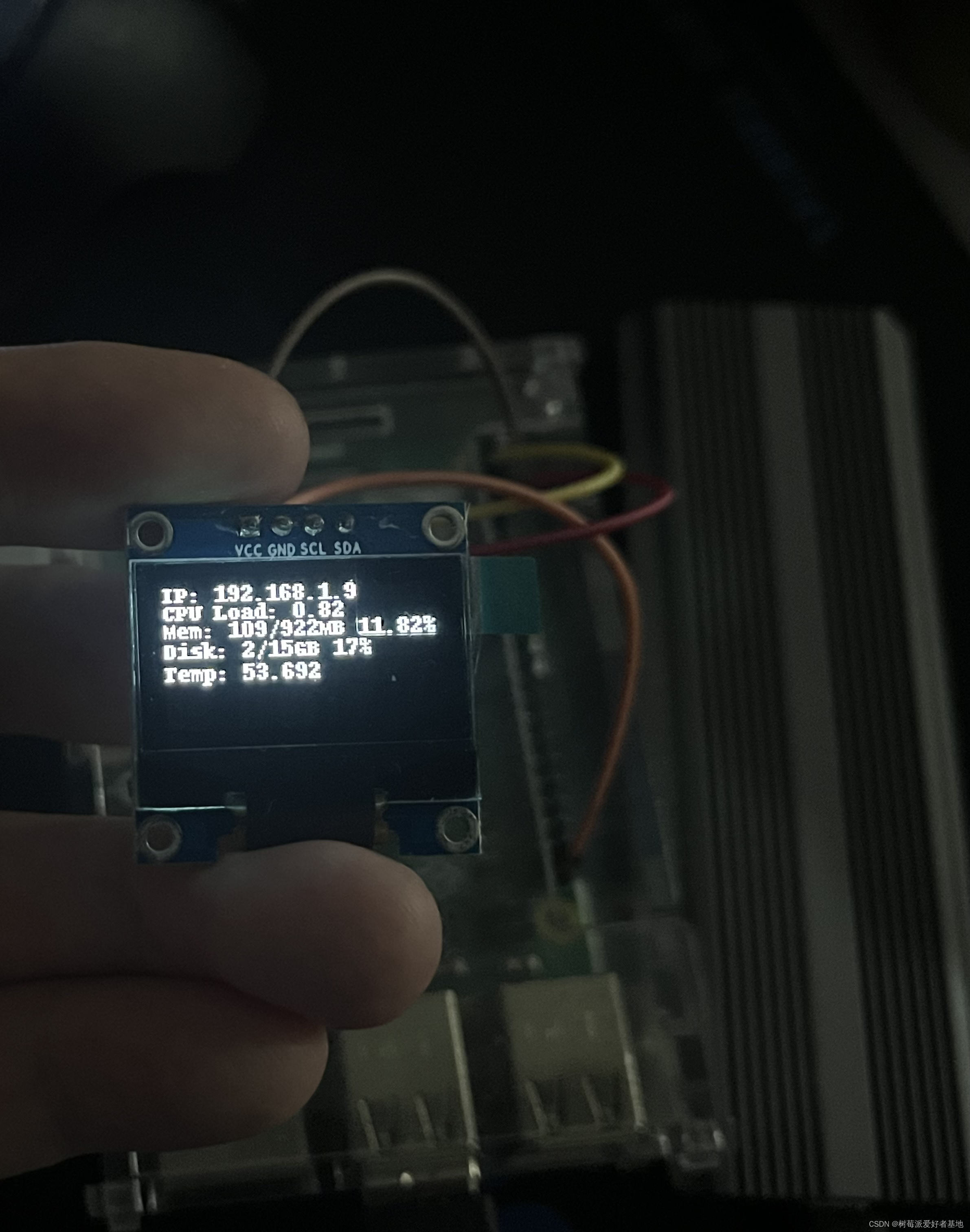


![[python库] base64库的基本使用](https://img-blog.csdnimg.cn/8ce7516a098a4a70bf46a890e67dcef1.png#pic_center)