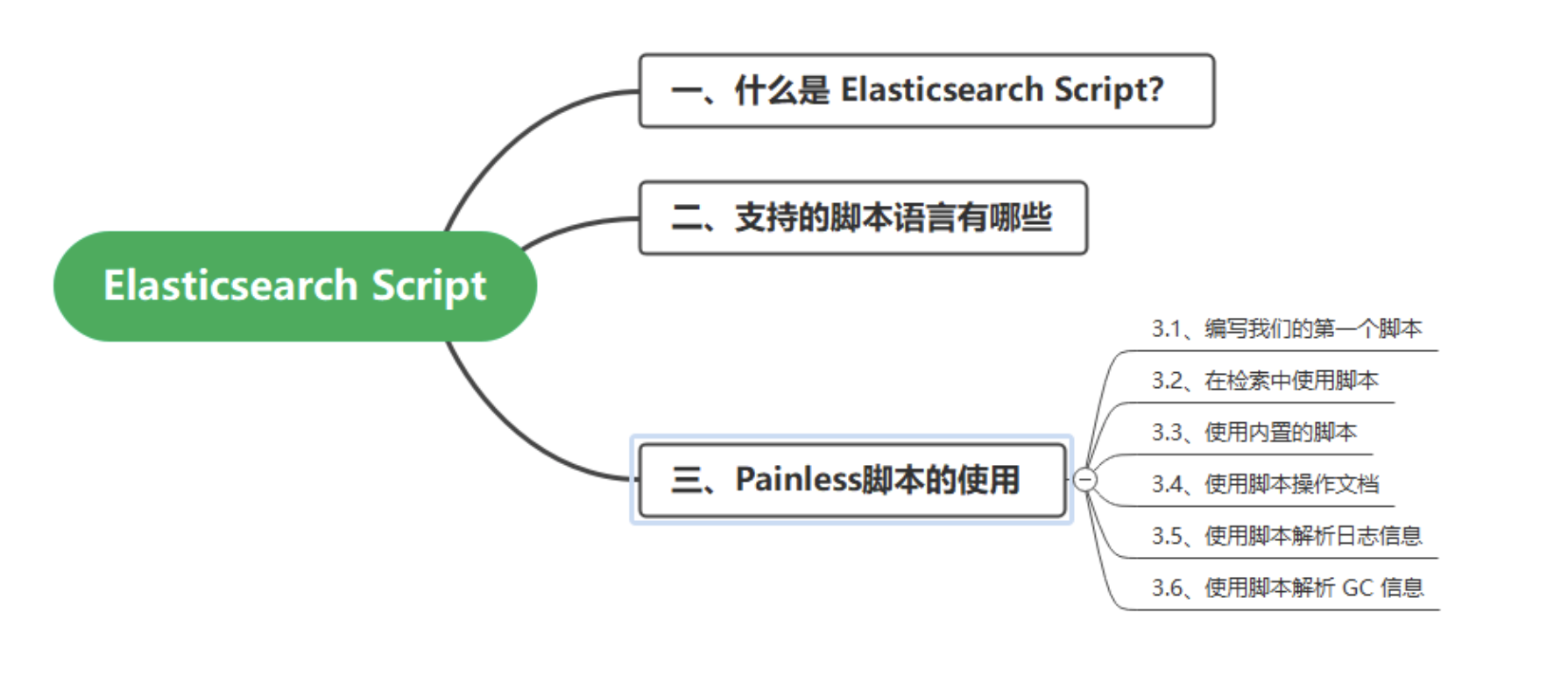
一、什么是 Elasticsearch Script?
Elasticsearch 中的 Script 是一种灵活的方式,允许用户在查询、聚合和更新文档时执行自定义的脚本。这些脚本可以用来动态计算字段值、修改查询行为、执行复杂的条件逻辑等等。
二、支持的脚本语言有哪些
支持多种脚本语言,包括 Painless、Expression、Mustache、Java等,其中默认的是Painless。

三、Painless 脚本的使用
Painless 是一种专为 Elasticsearch 设计的脚本语言,具有安全、快速、简单的特点,使其在 Elasticsearch 中非常方便入门。
-
安全性: Painless 被设计为一种安全的脚本语言。它采取了一系列的安全措施,如禁止无限循环、禁止访问 Java 类库中的危险类等,以减轻潜在的安全风险。
-
高性能: Painless 是为高性能而设计的,特别是在 Elasticsearch 中。它经过了优化,可以在大规模数据集上快速执行。
-
易学易用: Painless 实现了任何具有基本编码经验的人都自然熟悉的语法。Painless 使用 Java 语法的子集,并进行了一些额外的改进,以增强可读性并删除样板文件。
-
无需编译: Painless 脚本不需要预先编译。它可以在运行时解释,所以我们可以动态调整脚本而无需重新编译整个应用程序。
-
支持参数化: Painless 允许在脚本中使用参数,这可以使脚本更通用,适用于多种情况。参数化脚本可以接受外部传递的值,从而在不修改脚本的情况下改变其行为。
-
支持多种数据类型: Painless 支持多种数据类型,包括数字、字符串、日期、布尔值等。
-
集成性: Painless 被紧密集成到 Java 中,可以用于查询、聚合、脚本字段、脚本排序等各种用例。
3.1、编写我们的第一个脚本
使用的
Elasticsearch版本为8.1,历史文章除非特别说明,最近更文的ES版本都为Elasticsearch的8.1版本
脚本的组成有三个参数,只要是在 Elasticsearch API 支持脚本的地方,都可以使用如下三个参数来使用脚本。
"script": {
"lang": "...",
"source" | "id": "...",
"params": { ... }
}
-
lang:执行脚本语言类型,默认painless -
source,id:脚本的源码本身,或者提前存储的脚本ID -
params:作为变量传递给脚本的参数
下面我们将通过实际的例子来进行说明
3.2、在检索中使用脚本
-
首先我们先往索引中插入一篇文档
PUT zfc-doc-000007/_doc/1 { "sum": 5, "message":"test painless" } -
使用脚本实现
sum的值乘2,此处使用变量multiplier,在脚本的参数中指定参数值为2,其中doc['sum'].value * params['multiplier']的意思就是获取文档中sum的值并乘以脚本中multiplier的值GET zfc-doc-000007/_search { "script_fields": { "my_doubled_field": { "script": { "source": "doc['sum'].value * params['multiplier']", "params": { "multiplier": 2 } } } } } -
在获取脚本的参数中的变量值除了使用
params['参数名']这种方式之外,还可以使用params.get('multiplier')方法获取GET zfc-doc-000007/_search { "script_fields": { "my_doubled_field": { "script": { "lang": "painless", "source": "doc['sum'].value * params.get('multiplier');", "params": { "multiplier": 2 } } } } }
上面我们是在检索请求中使用的脚本字段来使用的脚本,下面我们先内置一个脚本,通过使用脚本ID来使用内置的脚本
3.3、使用内置的脚本
-
创建一个脚本
calculate-score,它可以使用Math.log(_score * 2) + params['my_modifier']修改分数值POST _scripts/calculate-score { "script": { "lang": "painless", "source": "Math.log(_score * 2) + params['my_modifier']" } } -
创建完成的脚本我们可以使用
_scriptAPI查看脚本的内容GET _scripts/calculate-score -
在检索中只需要如下指定
脚本的ID即可进行检索时使用GET zfc-doc-000007/_search { "query": { "script_score": { "query": { "match": { "message": "painless" } }, "script": { "id": "calculate-score", "params": { "my_modifier": 2 } } } } } -
如果想删除脚本只需要调用
DELETE即可DELETE _scripts/calculate-score
下面我们再来演示一下如何使用脚本更新文档中的内容
3.4、使用脚本操作文档
-
先添加一个文档来进行测试
PUT zfc-doc-000007/_doc/1 { "counter" : 1, "tags" : ["red"] } -
使用脚本对文档中的
counter的值与脚本中的count值进行相加POST zfc-doc-000007/_update/1 { "script" : { "source": "ctx._source.counter += params.count", "lang": "painless", "params" : { "count" : 4 } } } -
我们还可以对文档中的数组类型的
tags字段进行增加子对象,比如增加一个bluePOST zfc-doc-000007/_update/1 { "script": { "source": "ctx._source.tags.add(params['tag'])", "lang": "painless", "params": { "tag": "blue" } } } -
使用脚本对文档中的
tags的值进行删除,条件就是当tag的值与脚本中的值相等时删除。如下为当tags的值为blue时,删除bluePOST zfc-doc-000007/_update/1 { "script": { "source": "if (ctx._source.tags.contains(params['tag'])) { ctx._source.tags.remove(ctx._source.tags.indexOf(params['tag'])) }", "lang": "painless", "params": { "tag": "blue" } } } -
上面只是对已有字段的增加删除修改,下面还可以使用脚本进行新字段的增加,比如增加一个字段
new_field,值是value_of_new_fieldPOST zfc-doc-000007/_update/1 { "script" : "ctx._source.new_field = 'value_of_new_field'" } -
上面是字段的增加,下面就是字段的移除
POST zfc-doc-000007/_update/1 { "script" : "ctx._source.remove('new_field')" } -
除了对字段的删除,数组对象内部值的删除,还可以对文档进行删除。如下,当
tags里面包含blue时,删除当前文档POST zfc-doc-000007/_update/1 { "script": { "source": "if (ctx._source.tags.contains(params['tag'])) { ctx.op = 'delete' } else { ctx.op = 'none' }", "lang": "painless", "params": { "tag": "blue" } } }
3.5、使用脚本解析日志信息
所谓的解析字符串,只是一组固定格式的字符串,提前使用变量的形式编译,在插入文档时,通过脚本进行解析保存,方便后面的检索等请求
假如我们有如下数据
"message" : "247.37.0.0 - - [30/Apr/2020:14:31:22 -0500] \"GET /images/hm_nbg.jpg HTTP/1.0\" 304 0"
那么我们可以使用如下变量的形式解析该字符串
%{clientip} %{ident} %{auth} [%{@timestamp}] \"%{verb} %{request} HTTP/%{httpversion}\" %{status} %{size}
下面我们使用例子来说明脚本解析字符串之后是何种形式的存在
-
创建一个索引保存解析的数据
PUT zfc-doc-000008 { "mappings": { "properties": { "message": { "type": "wildcard" } } } } -
内置一个脚本,实现解析字符串信息,并提取需要的信息,如下为提取当前日志中的
http响应信息response,对于如下脚本的测试API使用详情可以参考官网https://www.elastic.co/guide/en/elasticsearch/painless/8.1/painless-execute-api.html
POST /_scripts/painless/_execute { "script": { "source": """ String response=dissect('%{clientip} %{ident} %{auth} [%{@timestamp}] "%{verb} %{request} HTTP/%{httpversion}" %{response} %{size}').extract(doc["message"].value)?.response; if (response != null) emit(Integer.parseInt(response)); """ }, "context": "long_field", "context_setup": { "index": "zfc-doc-000008", "document": { "message": """247.37.0.0 - - [30/Apr/2020:14:31:22 -0500] "GET /images/hm_nbg.jpg HTTP/1.0" 304 0""" } } }
如果我们还想操作当前解析的数据我们可以使用运行时字段,因为运行时字段不需要进行索引会更加的灵活,可以很方便的修改脚本及运行方式。
-
那么我们现在删除一下刚刚创建的索引,重新添加一下,创建语句如下
DELETE zfc-doc-000008 PUT /zfc-doc-000008 { "mappings": { "properties": { "@timestamp": { "format": "strict_date_optional_time||epoch_second", "type": "date" }, "message": { "type": "wildcard" } } } } -
添加一个运行时字段来保存解析的结果
PUT zfc-doc-000008/_mappings { "runtime": { "http.response": { "type": "long", "script": """ String response=dissect('%{clientip} %{ident} %{auth} [%{@timestamp}] "%{verb} %{request} HTTP/%{httpversion}" %{response} %{size}').extract(doc["message"].value)?.response; if (response != null) emit(Integer.parseInt(response)); """ } } } -
添加几条测试数据用于测试
POST /zfc-doc-000008/_bulk?refresh=true {"index":{}} {"timestamp":"2020-04-30T14:30:17-05:00","message":"40.135.0.0 - - [30/Apr/2020:14:30:17 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"} {"index":{}} {"timestamp":"2020-04-30T14:30:53-05:00","message":"232.0.0.0 - - [30/Apr/2020:14:30:53 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"} {"index":{}} {"timestamp":"2020-04-30T14:31:12-05:00","message":"26.1.0.0 - - [30/Apr/2020:14:31:12 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"} {"index":{}} {"timestamp":"2020-04-30T14:31:19-05:00","message":"247.37.0.0 - - [30/Apr/2020:14:31:19 -0500] \"GET /french/splash_inet.html HTTP/1.0\" 200 3781"} {"index":{}} {"timestamp":"2020-04-30T14:31:22-05:00","message":"247.37.0.0 - - [30/Apr/2020:14:31:22 -0500] \"GET /images/hm_nbg.jpg HTTP/1.0\" 304 0"} {"index":{}} {"timestamp":"2020-04-30T14:31:27-05:00","message":"252.0.0.0 - - [30/Apr/2020:14:31:27 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"} {"index":{}} {"timestamp":"2020-04-30T14:31:28-05:00","message":"not a valid apache log"} -
下面我们进行运行时字段检索响应为
304的数据GET zfc-doc-000008/_search { "query": { "match": { "http.response": "304" } }, "fields" : ["http.response"] } -
刚才是属于提前内置好运行时字段,我们也可以直接在检索时指定运行时字段来使用,但下面所示的仅在运行时有效。如下所示
GET zfc-doc-000008/_search { "runtime_mappings": { "http.response": { "type": "long", "script": """ String response=dissect('%{clientip} %{ident} %{auth} [%{@timestamp}] "%{verb} %{request} HTTP/%{httpversion}" %{response} %{size}').extract(doc["message"].value)?.response; if (response != null) emit(Integer.parseInt(response)); """ } }, "query": { "match": { "http.response": "304" } }, "fields" : ["http.response"] }
我们也可以根据特定的值进行拆分,获取所需要的信息
3.6、使用脚本解析 GC 信息
-
例如如下
Elasticsearch的GC信息[2021-04-27T16:16:34.699+0000][82460][gc,heap,exit] class space used 266K, capacity 384K, committed 384K, reserved 1048576K -
下面我们根据
GC信息编写一个解析模式[%{@timestamp}][%{code}][%{desc}] %{ident} used %{usize}, capacity %{csize}, committed %{comsize}, reserved %{rsize} -
然后在检索时就可以使用如下语句来提交信息到运行时字段,首先添加测试数据,注意索引名称已经更换,解析模式不匹配会报错
POST /zfc-doc-000010/_bulk?refresh {"index":{}} {"gc": "[2021-04-27T16:16:34.699+0000][82460][gc,heap,exit] class space used 266K, capacity 384K, committed 384K, reserved 1048576K"} {"index":{}} {"gc": "[2021-03-24T20:27:24.184+0000][90239][gc,heap,exit] class space used 15255K, capacity 16726K, committed 16844K, reserved 1048576K"} {"index":{}} {"gc": "[2021-03-24T20:27:24.184+0000][90239][gc,heap,exit] Metaspace used 115409K, capacity 119541K, committed 120248K, reserved 1153024K"} {"index":{}} {"gc": "[2021-04-19T15:03:21.735+0000][84408][gc,heap,exit] class space used 14503K, capacity 15894K, committed 15948K, reserved 1048576K"} {"index":{}} {"gc": "[2021-04-19T15:03:21.735+0000][84408][gc,heap,exit] Metaspace used 107719K, capacity 111775K, committed 112724K, reserved 1146880K"} {"index":{}} {"gc": "[2021-04-27T16:16:34.699+0000][82460][gc,heap,exit] class space used 266K, capacity 367K, committed 384K, reserved 1048576K"} -
使用检索语句展示解析数据到运行时字段中
GET zfc-doc-000010/_search { "runtime_mappings": { "gc_size": { "type": "keyword", "script": """ Map gc=dissect('[%{@timestamp}][%{code}][%{desc}] %{ident} used %{usize}, capacity %{csize}, committed %{comsize}, reserved %{rsize}').extract(doc["gc.keyword"].value); if (gc != null) emit("used" + ' ' + gc.usize + ', ' + "capacity" + ' ' + gc.csize + ', ' + "committed" + ' ' + gc.comsize); """ } }, "size": 1, "aggs": { "sizes": { "terms": { "field": "gc_size", "size": 10 } } }, "fields" : ["gc_size"] }
通过上面的查询测试可以知道,Elasticsearch 中的 script 默认的时 painless 语言,功能已经非常强大可以满足我们的日常需求,如果还想更高级的脚本,可以使用 Java 语言来编写自己的脚本。关于 Expressions 的表达式的使用就参与官网吧,本文的所有例子均来自官网,并自测完成。如有错误欢迎指出,共同进步。
后面有机会会出现一片使用Java编译脚本的使用,等后面时间吧,最近这段时间听尴尬的,也托更很久了,以后慢慢的都要补上。
2023 最后俩月了,加油。
原文链接
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/modules-scripting.html
本文由 mdnice 多平台发布