文章目录
- 教程
- 1. 基本分页存储管理的基本概念
- 1.1 连续分配方式的缺点
- 1.2 把“固定分区分配”改造为“非连续分配版本”
- 1.3 什么是分页存储
- 1.4 如何实现地址的转换?
- 1.5 逻辑地址结构
- 1.6 重要的数据结构——页表
- 1.7 知识回顾与重要考点
- 2. 基本地址变换机构
- 2.1 例题
- 2.2 对页表项大小的进一步探究
- 2.3总结
- 3. 具有快表的地址变换机构
- 3.1局部性原理
- 3.2 什么是快表(TLB)?
- 3.2 引入快表后,地址的变换过程
- 3.3 思考:能否把整个页表都放在TLB中?
- 3.4总结
- 4. 两级页表
- 4.1 单级页表存在的问题
- 4.2 如何解决单级页表的问题?
- 4.3 两级页表的原理、地址结构
- 4.4 如何实现地址变换
- 4.5 如何解决单级页表的问题?
- 4.6 需要注意的几个细节
- 4.7 知识回顾与重要考点
- 5. 基本分段存储管理方式
- 5.1 分段
- 5.2 地址变换
- 5.3 分段、分页管理的对比
- 5.3 总结
- 6. 段页式管理方式
- 6.1分页、分段的优缺点分析
- 6.2 分段+分页=段页式管理
- 6.3 段页式管理的逻辑地址结构
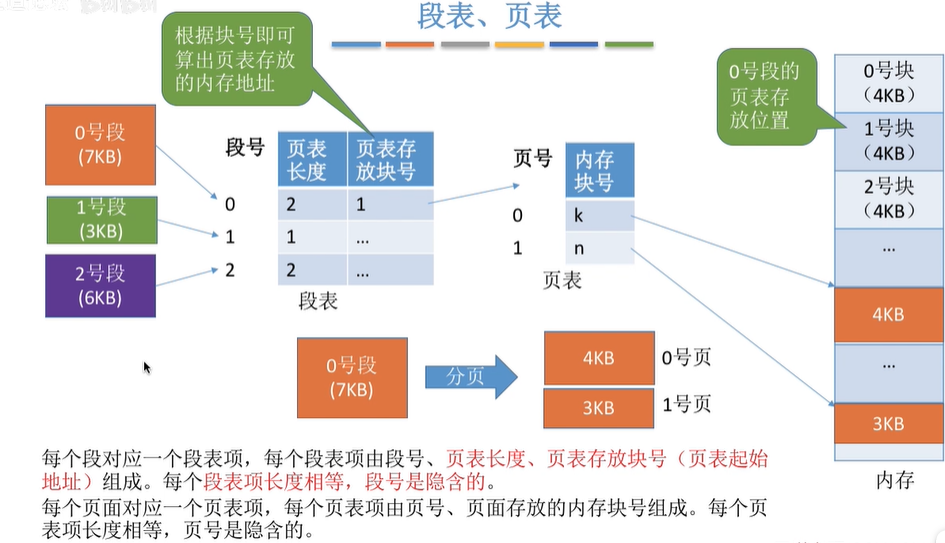
- 6.4 段表,页表
- 总结
教程
- 基本分页存储管理的基本概念
1. 基本分页存储管理的基本概念
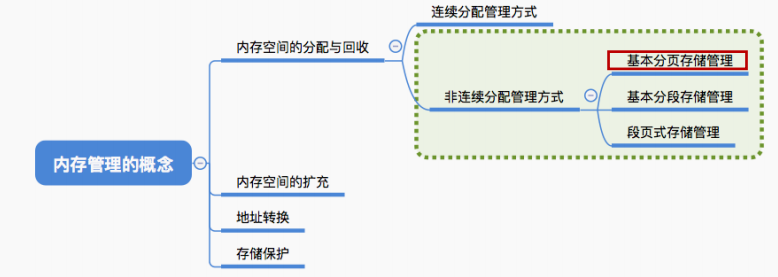
连续分配:为用户进程分配的必须是一个连续的内存空间。
非连续分配:为用户进程分配的可以是一些分散的内存空间。
1.1 连续分配方式的缺点
考虑支持多道程序的两种连续分配方式:
1.固定分区分配:缺乏灵活性,会产生大量的内部碎片,内存的利用率很低。
2.动态分区分配:会产生很多外部碎片,虽然可以用“紧凑”技术来处理,但是“紧凑”的时间代价很高。
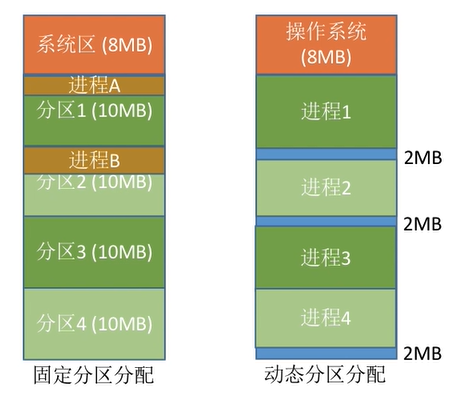
如果允许将一个进程分散地装入到许多不相邻的分区中,便可充分地利用内存,而无需再进行“紧凑”。
1.2 把“固定分区分配”改造为“非连续分配版本”
假设进程A大小为23MB,但是每个分区大小只有10MB,如果进程只能占用一个分区,那显然放不下。
解决思路:如果允许进程占用多个分区,那么可以把进程拆分成10MB+10MB+3MB三个部分,再把这三个部分分别放到三个分区中(这些分区不要求连续)

进程A的最后一个部分是3MB,放入分区后会产生7MB的内部碎片。
如果每个分区大小为2MB,那么进程A可以拆分成11*2MB+1MB共12个部分,只有最后一部分1MB占不满分区,会产生1MB的内部碎片。
显然,如果把分区大小设置的更小一些,内部碎片会更小,内存利用率会更高。
基本分页存储管理的思想:把内存分为一个个相等的小分区,再按照分区大小把进程拆分成一个个小部分。
1.3 什么是分页存储
将内存空间分为一个个大小相等的分区(比如:每个分区4KB),每个分区就是一个“页框”(页框=页帧=内存块=物理块=物理页面)。每个页框有一个编号,即“页框号”(页框号=页帧号=内存块号=物理块号=物理页号),页框号从0开始。

将进程的逻辑地址空间也分为与页框大小相等的一个个部分,每个部分称为一个“页”或“页面” 。每个页面也有一个编号,即“页号”,页号也是从0开始。(注:进程的最后一个页面可能没有一个页框那么大。因此,页框不能太大,否则可能产牛讨大的内部碎片)

Tips:初学易混——页、页面 vs 页框、页帧、物理页页号、页面号 vs 页框号、页帧号、物理页号
操作系统以页框为单位为各个进程分配内存空间。进程的每个页面分别放入一个页框中。也就是说,进程的页面与内存的页框有一一对应的关系。
各个页面不必连续存放,可以放到不相邻的各个页框中。
(注:进程的最后一个页面可能没有一个页框那么大。也就是
说,分页存储有可能产生内部碎片,因此页框不能太大,否则可能产生过大的内部碎片造成浪费)
1.4 如何实现地址的转换?
将进程地址空间分页之后,操作系统该如何实现逻辑地址到物理地址的转换?

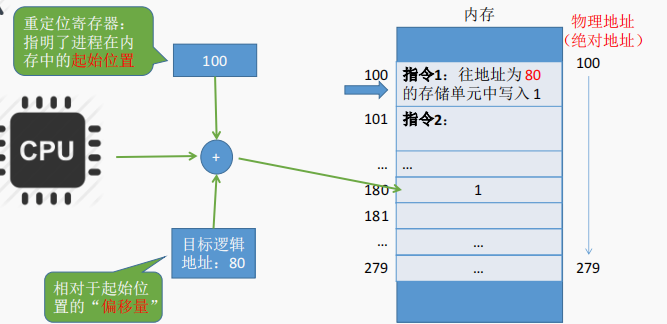
思想:模块在内存中的的“起始地址”+目标内存单元相对于起始位置的“偏移量”
将进程地址空间分页之后,操作系统该如何实现逻辑地址到物理地址的转换?
特点:虽然进程的各个页面是离散存放的,但是页面内部是连续存放的
逻辑地址A 对应的物理地址 = P号页面在内存中的起始地址+页内偏移量W

如何计算:
页号=逻辑地址/页面长度(取除法的整数部分)
页内偏移量=逻辑地址%页面长度(取除法的余数部分)
页面在内存中的起始位置:操作系统需要用某种数据结构记录进程各个页面的起始位置。
页号=80/ 50= 1
页内偏移量=80 %50 = 30
1号页在内存中存放的起始位置450
为了方便计算页号、页内偏移量,页面大小一般设为2的整数幂


如果页面大小 刚好是 2 的整数幂,则计算机硬件可以很快速的把逻辑地址拆分成(页号,页内偏移量)

子问题:为何页面大小要取2的整数幂?
1.5 逻辑地址结构
分页存储管理的逻辑地址结构如下所示:

1.6 重要的数据结构——页表
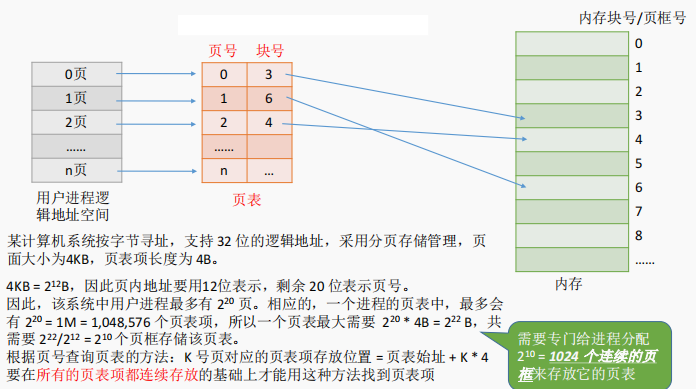
为了能知道进程的每个页面在内存中存放的位置,操作系统要为每个进程建立一张页表。
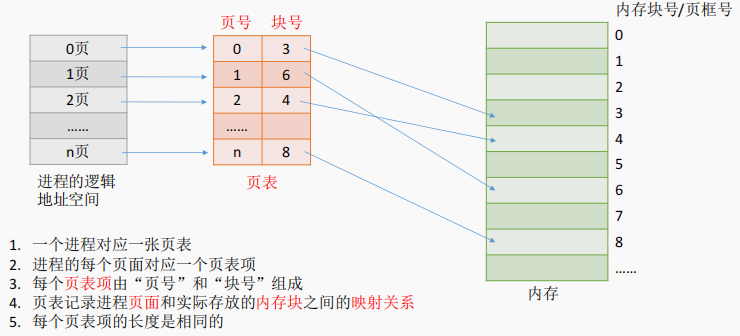
M号内存块的起始地址就是M*内存块
为什么每个页表项的长度是相同的,页号是“隐含”的?


1.7 知识回顾与重要考点

2. 基本地址变换机构

重点理解、记忆基本地址变换机构(用于实现逻辑地址到物理地址转换的一组硬件机构)的原理和流程。
基本地址变换机构可以借助进程的页表将逻辑地址转换为物理地址。
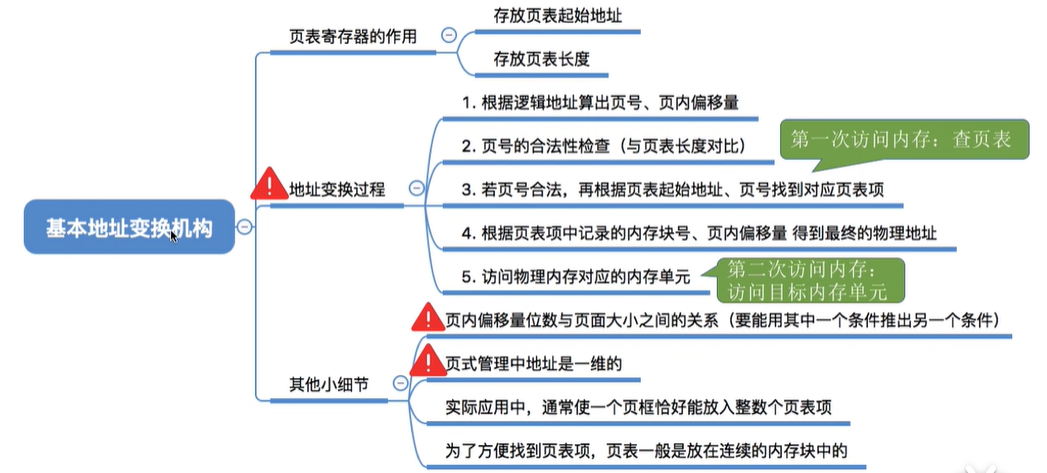
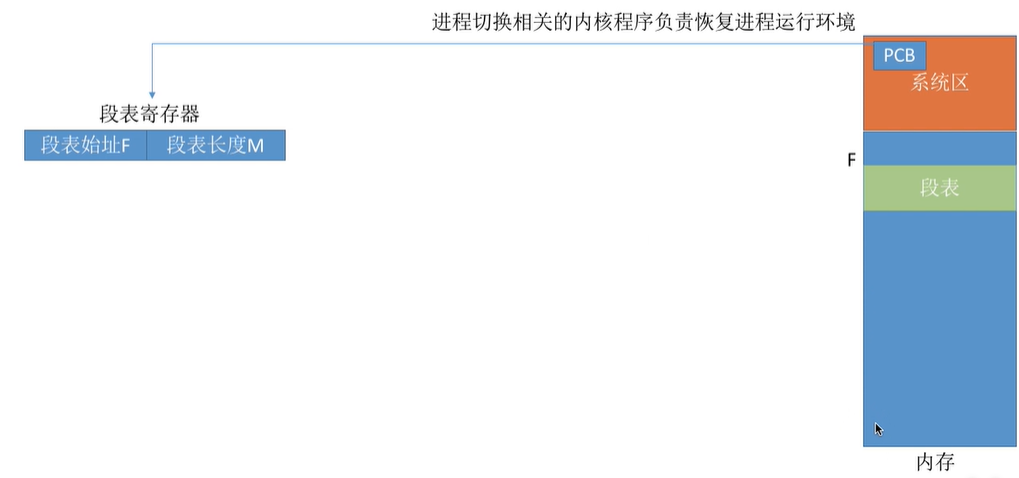
通常会在系统中设置一个页表寄存器(PTR),存放页表在内存中的起始地址F和页表长度M。进程未执行时,页表的始址和页表长度放在进程控制块(PCB)中,当进程被调度时,操作系统内核会把它们放到页表寄存器中。
注意:页面大小是2的整数幂
(重要)设页面大小为L,逻辑地址A到物理地址E的变换过程如下:
①计算页号Р和页内偏移量w(如果用十进制数手算,则P=A/L,W=A%L;但是在计算机实际运行时,逻辑地址结构是固定不变的,因此计算机硬件可以更快地得到二进制表示的页号、页内偏移量)
②比较页号p和页表长度M,若P>=M,则产生越界中断,否则继续执行。(注意:页号是从O开始的,而页表长度至少是1,因此P=M时也会越界)
③页表中页号P对应的页表项地址=页表起始地址F+页号P*页表项长度,取出该页表项内容b,即为内存块号。(注意区分页表项长度、页表长度、页面大小的区别。页表长度指的是这个页表中总共有几个页表项,即总共有几个页;页表项长度指的是每个页表项占多大的存储空间;页面大小指的是一个页面占多大的存储空间)
④计算E= b*L+w,用得到的物理地址E去访存。(如果内存块号、页面偏移量是用二进制表示的,那么把二者拼接起来就是最终的物理地址了)



2.1 例题

2.2 对页表项大小的进一步探究


2.3总结
3. 具有快表的地址变换机构

3.1局部性原理


时间局部性:如果执行了程序中的某条指令,那么不久后这条指令很有可能再次执行;如果某个数据被访问过,不久之后该数据很可能再次被访问。(因为程序中存在大量的循环)
空间局部性:一旦程序访问了某个存储单元,在不久之后,其附近的存储单元也很有可能被访问。(因为很多数据在内存中都是连续存放的)
上小节介绍的基本地址变换机构中,每次要访问一个逻辑地址,都需要查询内存中的页表。由于局部性原理,可能连续很多次查到的都是同一个页表项。既然如此,能否利用这个特性减少访问页表的次数呢?
3.2 什么是快表(TLB)?
快表,又称联想寄存器(TLB, translation lookaside buffer ),是一种访问速度比内存快很多的高速缓存(TLB不是内存!),用来存放最近访问的页表项的副本,可以加速地址变换的速度。与此对应,内存中的页表常称为慢表。


3.2 引入快表后,地址的变换过程
① CPU给出逻辑地址,由某个硬件算得页号、页内偏移量,将页号与快表中的所有页号进行比较。
② 如果找到匹配的页号,说明要访问的页表项在快表中有副本,则直接从中取出该页对应的内存块号,再将内存块号与页内偏移量拼接形成物理地址,最后,访问该物理地址对应的内存单元。因此,若快表命中,则访问某个逻辑地址仅需一次访存即可。
③ 如果没有找到匹配的页号,则需要访问内存中的页表,找到对应页表项,得到页面存放的内存块号,再将内存块号与页内偏移量拼接形成物理地址,最后,访问该物理地址对应的内存单元。因此,若快表未命中,则访问某个逻辑地址需要两次访存(注意:在找到页表项后,应同时将其存入快表,以便后面可能的再次访问。但若快表已满,则必须按照一定的算法对旧的页表项进行替换)
由于查询快表的速度比查询页表的速度快很多,因此只要快表命中,就可以节省很多时间。因为局部性原理,一般来说快表的命中率可以达到 90% 以上。
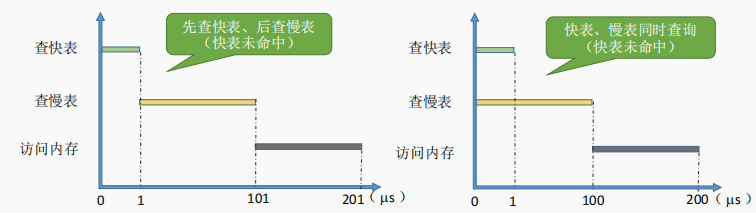
例:某系统使用基本分页存储管理,并采用了具有快表的地址变换机构。访问一次快表耗时 1us,访问一次内存耗时 100us。若快表的命中率为 90%,那么访问一个逻辑地址的平均耗时是多少?
(1+100) * 0.9 + (1+100+100) * 0.1 = 111 us
有的系统支持快表和慢表同时查找,如果是这样,平均耗时应该是 (1+100) * 0.9 + (100+100) * 0.1 =110.9 us
若未采用快表机制,则访问一个逻辑地址需要 100+100 = 200us
显然,引入快表机制后,访问一个逻辑地址的速度快多了。
3.3 思考:能否把整个页表都放在TLB中?

3.4总结

4. 两级页表
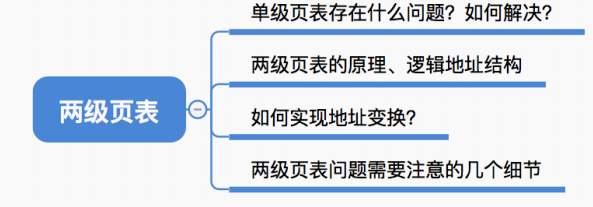
4.1 单级页表存在的问题

4.2 如何解决单级页表的问题?
问题一:页表必须连续存放,因此当页表很大时,需要占用很多个连续的页框。
问题二:没有必要让整个页表常驻内存,因为进程在一段时间内可能只需要访问某几个特定的页面。
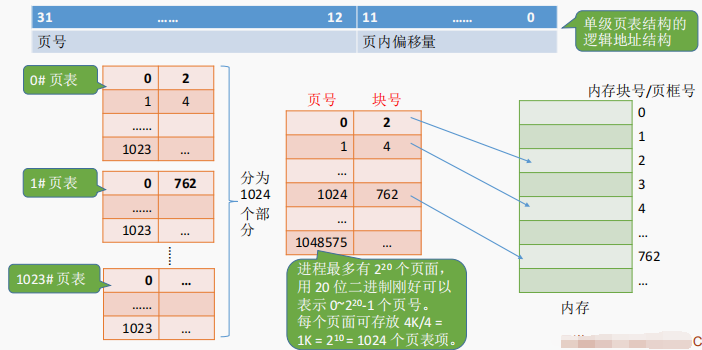
把页表再分页并离散存储,然后再建立一张页表记录页表各个部分的存放位置,称为页目录表,或称外层页表,或称顶层页表
4.3 两级页表的原理、地址结构
32位逻辑地址空间,页表项大小为4B,页面大小为 4KB,则页内地址占12位

4.4 如何实现地址变换

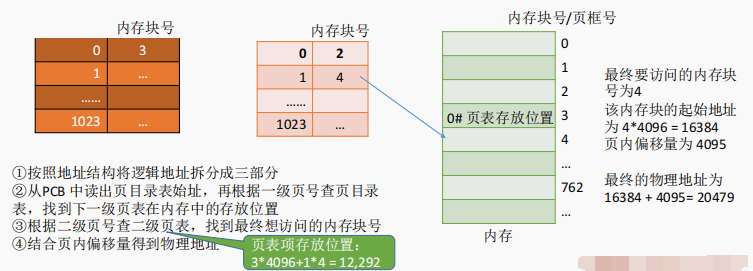
4.5 如何解决单级页表的问题?

4.6 需要注意的几个细节
- 若分为两级页表后,页表依然很长,则可以采用更多级页表,一般来说
各级页表的大小不能超过一个页面
例:某系统按字节编址,采用 40 位逻辑地址,页面大小为 4KB,页表项大小为 4B,假设采用纯页式存储,则要采用()级页表,页内偏移量为()位?

4.7 知识回顾与重要考点

5. 基本分段存储管理方式

5.1 分段
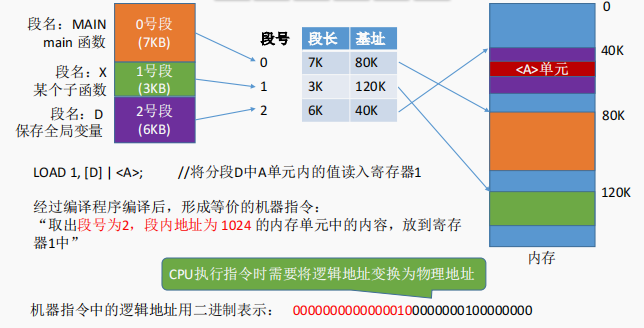
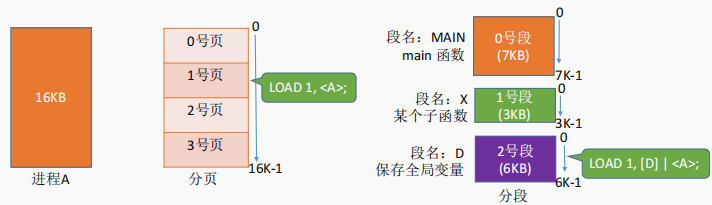
进程的地址空间:按照程序自身的逻辑关系划分为若干个段,每个段都有一个段名(在低级语言中,程序员使用段名来编程),每段从0开始编址
内存分配规则:以段为单位进行分配,每个段在内存中占据连续空间,但各段之间可以不相邻。

分段系统的逻辑地址结构由段号(段名)和段内地址(段内偏移量)所组成。如:

问题:程序分多个段,各段离散地装入内存,为了保证程序能正常运行,就必须能从物理内存中找到各个逻辑段的存放位置。为此,需为每个进程建立一张段映射表,简称“段表”。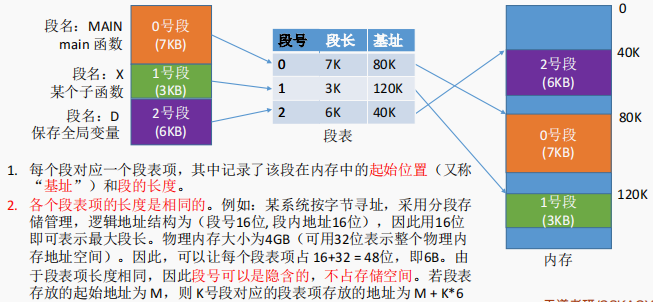
5.2 地址变换


5.3 分段、分页管理的对比
页是信息的物理单位。分页的主要目的是为了实现离散分配,提高内存利用率。分页仅仅是系统管理上的需要,完全是系统行为,对用户是不可见的。
段是信息的逻辑单位。分段的主要目的是更好地满足用户需求。一个段通常包含着一组属于一个逻辑模块的信息。分段对用户是可见的,用户编程时需要显式地给出段名。
页的大小固定且由系统决定。段的长度却不固定,决定于用户编写的程序。
分页的用户进程地址空间是一维的,程序员只需给出一个记忆符即可表示一个地址。
分段的用户进程地址空间是二维的,程序员在标识一个地址时,既要给出段名,也要给出段内地址。
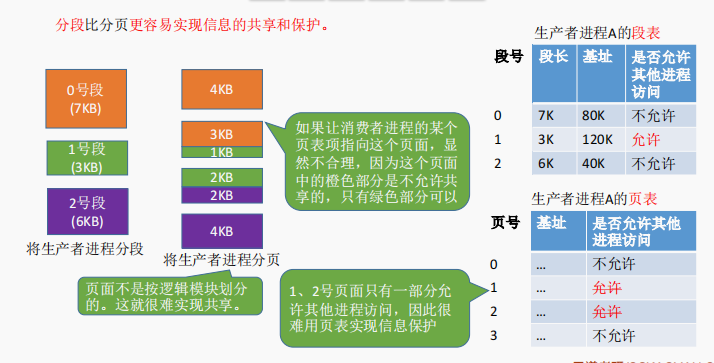
页是信息的物理单位。分页的主要目的是为了实现离散分配,提高内存利用率。分页仅仅是系统管理上的需要,完全是系统行为,对用户是不可见的。
段是信息的逻辑单位。分页的主要目的是更好地满足用户需求。一个段通常包含着一组属于一个逻辑模块的信息。分段对用户是可见的,用户编程时需要显式地给出段名。
页的大小固定且由系统决定。段的长度却不固定,决定于用户编写的程序。
分页的用户进程地址空间是一维的,程序员只需给出一个记忆符即可表示一个地址。
分段的用户进程地址空间是二维的,程序员在标识一个地址时,既要给出段名,也要给出段内地址。
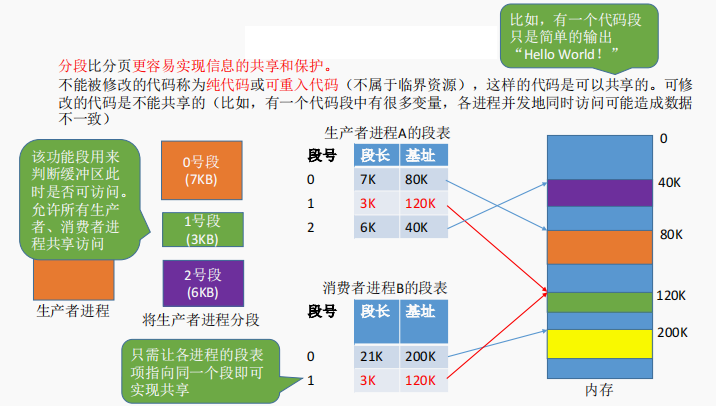
分段比分页更容易实现信息的共享和保护。不能被修改的代码称为纯代码或可重入代码(不属于临界资源),这样的代码是可以共享的。可修改的代码是不能共享的
访问一个逻辑地址需要几次访存?
分页(单级页表):第一次访存——查内存中的页表,第二次访存——访问目标内存单元。总共两次访存
分段:第一次访存——查内存中的段表,第二次访存——访问目标内存单元。总共两次访存
与分页系统类似,分段系统中也可以引入快表机构,将近期访问过的段表项放到快表中,这样可以少一次访问,加快地址变换速度
5.3 总结

6. 段页式管理方式
6.1分页、分段的优缺点分析

分段管理中产生的外部碎片也可以用“紧凑”来解决,只是需要付出较大的时间代价
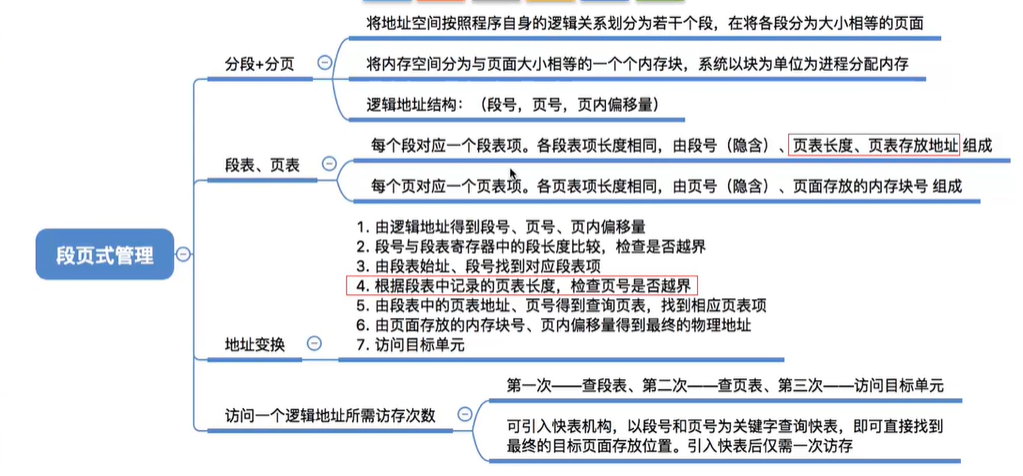
6.2 分段+分页=段页式管理

6.3 段页式管理的逻辑地址结构
分段系统的逻辑地址结构由段号和段内地址(段内偏移量)组成。如:


6.4 段表,页表
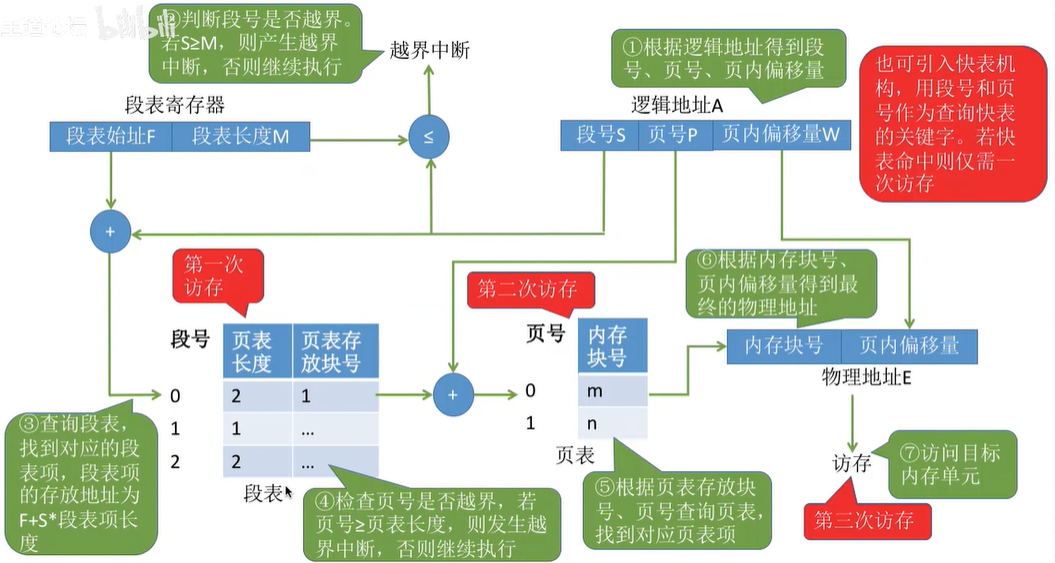
总结