RabbitMQ常见面试题
- RabbitMQ架构设计
- RabbitMQ有哪些优点
- RabbitMQ事物机制
- RabbitMQ持久化机制
- 持久化和非持久化
- 什么时候需要持久化?
- 落盘过程
- 文件删除
- RabbitMQ如何保证消息不丢失
- RabbitMQ如何保证消息不被重复消费
- RabbitMQ死信队列,延时队列
- 死信队列
- 延时队列
- 应用场景
- RabbitMQ如何保证消息的顺序
- RabbitMQ高可用
- RabbitMQ跟Kafka区别
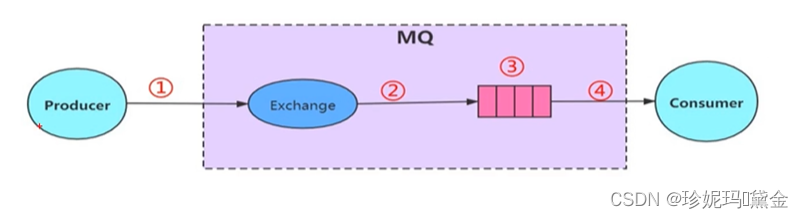
RabbitMQ架构设计
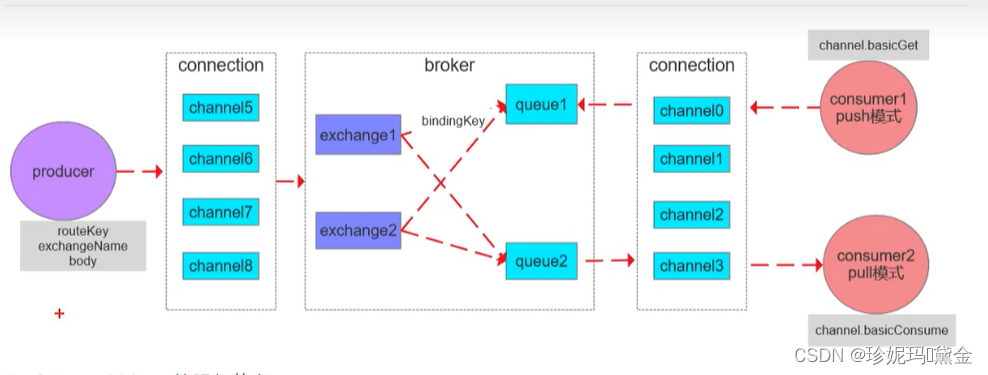
- Message:消息主体包括消息体和消息头组成,包括属性routing-key,priority,delivery-mode等
- Publisher:消息生产者,向交换器发布消息的客户端应用程序
- Exchange:交换器,用来接受生产者发送的消息并将这些消息路由给服务器中的队列,他主要的作业是按照什么规则,路由到哪个队列
- Routing-key:路由关键字,exchange根据这个进行消息投递到哪个队列
- Binding:用于队列和交换器之间的关联,一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则
- Queue:消息的载体,所有消息都会投递到一个或者多个队列,等待消费者连接并消费
- Connection:网络连接,生产者-MQ-消费者,都是通过TCP连接
- Channel:信道,每个客户端连接都会建立对应的channel
- Cconsumer:消费者,和队列连接的客户端程序取出消息
- Virtual Host:虚拟主机
- Broker:MQ的服务节点
RabbitMQ有哪些优点
-
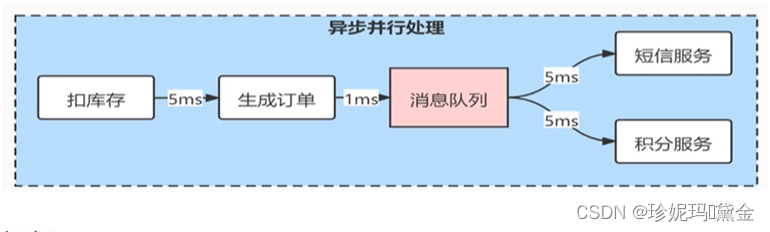
异步
如果一个用户下了个订单,首先会扣减库存,然后生成订单,然后调用短信服务发短信,然后调用积分服务增加积分等等操作;如果这些操作是同步执行的话,例如扣库存5ms,创建订单1ms,发短信3ms,积分增减3ms,一共要花12ms;
如果这个时候使用消息队列的异步操作来实现,用户只需要扣库存和生成订单(6ms),剩余的发短信增减积分的操作交给消息队列来完成,这样就大大提高的请求响应的速度
-
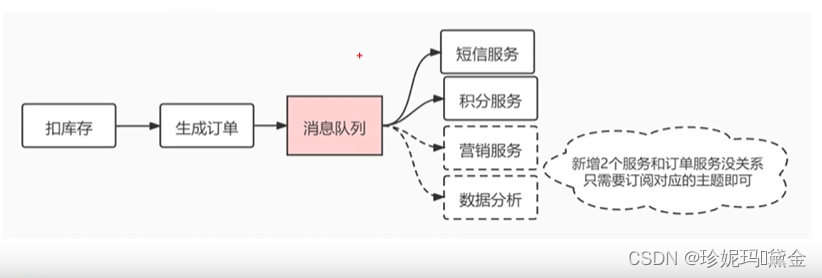
解耦
如果现在我们在下单的时候新增2个功能,例如营销服务和数据分析,那么这个时候就不需要改前面订单处理的那块逻辑,只需要新增2个功能,并作为消息的消费者就可以了,实现的功能的解耦
-
削峰
如果某一个时间段有大量的请求到后端服务,例如有1W个请求,但是后端只能承受1千个请求,那怎么办?此时可以用mq来实现流量削峰,把这1W个请求放在队列里面按顺序执行,用时间换空间,保证请求能正常执行,只不过是按顺序执行,这样就避免了后端压力过大导致服务崩溃。

RabbitMQ事物机制
通过对信道设置事物提交和回滚
//通知服务器开启事物模式
channel.txSelect();
//发送消息
channel.basicPublish
//提交事物
channel.txCommit();
//回滚事物
channel.txRollback();
消费者使用事物
//手动提交ack,以事物提交或回滚为准
aotuAck=false
//不支持事物,事物回滚无效,对了已经删除消息了
aotuAck=true
RabbitMQ持久化机制
持久化和非持久化
- 队列持久化:通过设置queueDeclare参数来持久化
- 消息持久化:通过设置MessageProperties.PERSISTENT_PLAIN来实现持久化
- exchange持久化:通过设置exchangeDeclare来实现持久化
什么时候需要持久化?
- 只要有消息生产并发给MQ就需要持久化磁盘
- 内存空间不足,需要将部分内容中的消息持久化到磁盘
落盘过程
- 写入文件前会先写入Buffer,大小为1M,如果Buffer满了,就会把Buffer数据写入文件
- 有个固定的刷盘时间,25ms,不管Buffer是否满了,都会每隔25ms把数据刷到磁盘
- 消息保存在$MNESIA/msg_store_persistent/x.rdq文件中,其中x是一个从1开始的编号,文件大小是16M,超过大小会生成新的文件,文件编号+1,文件格式是
<<Size:64, MsgId:16/binary, MsgBody>>
MsgId:是MQ通过gen生成GUID
MsgBody:包括消息exchange,routing-key,消息内容,消息对应的协议等
文件删除
- 当所有文件中的已经被删除的的消息比例 大于阀值(GARAAGE_FRACTION=0.5)时会触发文件合并操作,把数据都合到一个文件里面,其余的空文件会删除掉,提高磁盘利用率
- 当consumer消费完消息后,返回ack确认后,MQ会从文件中删除这条消息,当这个文件没有数据时,或者都是删除的消息时,会删除该文件
RabbitMQ如何保证消息不丢失
- 确保消息的生产者发送到MQ
- 确保消息路由到正确的队列
- 确保消息在队列正确的存储
- 确保消息从队列中正确的投递到消费者
// 消息发送确认的开关打开
setPublisherConfirms(true);
// 设置消息确认回调方法,发送成功会返回ack
confirmCallback();
//开启消息发送失败通知
setMandatory(true);
//消息路由失败后回调通知
setReturnCallback();
RabbitMQ如何保证消息不被重复消费
先说下哪些情况会造成消息的重复
- MQ收到消息后出问题了,宕机或者网络中断,导致生产者并没有收到确认消息,生产者会再次发送消息给MQ,直到返回确认消息
- MQ因负载过高,返回成功消息的时候超时,这是生产者会再次发送消息
- MQ把消息投递给消费者,此时消费者出问题了,宕机或者网络中断,没有返回确认结果,所以MQ会重复投递,直到消费者返回确认消息
- MQ把消息投递给消费者后,MQ宕机或者网络中断了,此时MQ重启后会重新投递消息造成消息重复
那么如何解决重复消费问题呢?
- 可以通过乐观锁机制,每次消息消费的时候带上一个版本号,消费者处理的时候每次都会比较版本号
- 去重表:利用数据库的唯一索引来保证数据的唯一性,例如订单ID每次处理订单消息的就存到这个去重表里面,如果有重复的订单ID进来,在去重表里面就重复,就不会执行了,解决了重复消费的问题
RabbitMQ死信队列,延时队列
死信队列
- 消息被consumer消费后,返回了nack信息,并且队列的requeue属性被设置为false,消息就会投递到死信队列
- 消息在队列中的存活时间超过设置的TTL时间
- 消息队列的消息数量已经超过最大队列长度
如果没有妹纸死信队列,那这些消息会被丢弃的
只需要配置一个死信将换机,然后分配单独的routing-key,然后绑定到对应的死信队列,这样死信队列里面的消息就不会被丢弃
延时队列
应用场景
- 购买火车票下单后30分钟支付
- 预定会议室后,提前5分钟发送提醒参会
MQ并没有延时队列的功能,只不过可以通过设置消息的TTL时间,来实现所谓的延时消息,现在有个订单,30分钟后支付成功并扣库存,清空购物车,此时就可以把消息的过期时间设置为30分钟,30分钟过期之后会进入私信队列,然后我们把死信队列提前配置好,对死信队列中的消息进行处理就行,从而实现了延时30分钟处理的功能
RabbitMQ如何保证消息的顺序
例如现在有一个队列,对应3个consumer,那么假如现在有3个消息(msg1,msg2,msg3)投递到3个 consumer上,此时如果msg2被先消费,那么就会造成顺序错乱,这显然是不允许的,那么应该怎么解决呢?
可以创建3个队列,对应3个consumer,那么每个消费者对应固定的队列,也就是1个队列对应一个消费者,然后每个队列的里面消息都是按顺序执行,按照list来排队
RabbitMQ高可用
- 单机模式:就是一个节点,这种基本不会在生产环境中使用
- 普通集群模式:就是所有节点只有其中一个节点的队列会有数据,其他的节点是没有数据的,这样做的优点是节省了存储空间,但是也降低了服务的可用
- 镜像模式:所有节点都会复制队列的数据,这样每个节点的数据都一样,一旦主节点挂了,从节点就会切换成主节点
- 主备模式:一个节点处于服务状态,另一个备用,一旦主服务挂了,备用就切换成主服务
RabbitMQ跟Kafka区别
-
RabbitMQ:是Erlang语言开发,轻量级,开箱即用的特点,非常容易使用和部署,社区活跃,支持编程语音比较多。缺点是消息如果堆积的比较多的话性能会下降,相比于Kafka的处理性能也很一般,每秒只能处理几万到十几万消息,还有就是二次扩展开发成本高,因为是Erlang语言开发的
-
Kafka:依赖Zookeeper,兼容性比较好,性能最高,支持扩展,Scaka和Java开发;缺点是Kafka会有消息延时,就是消息不会立马发送出去,而是攒一波消息一起发送出去