我觉得回答这个问题需要知道3个知识点:
1、multi-head-attention是如何计算的?attention的数学公式? kv cache是如何存储和传递的?
2、kv cache 的原理步骤是什么?为什么降低了消耗?
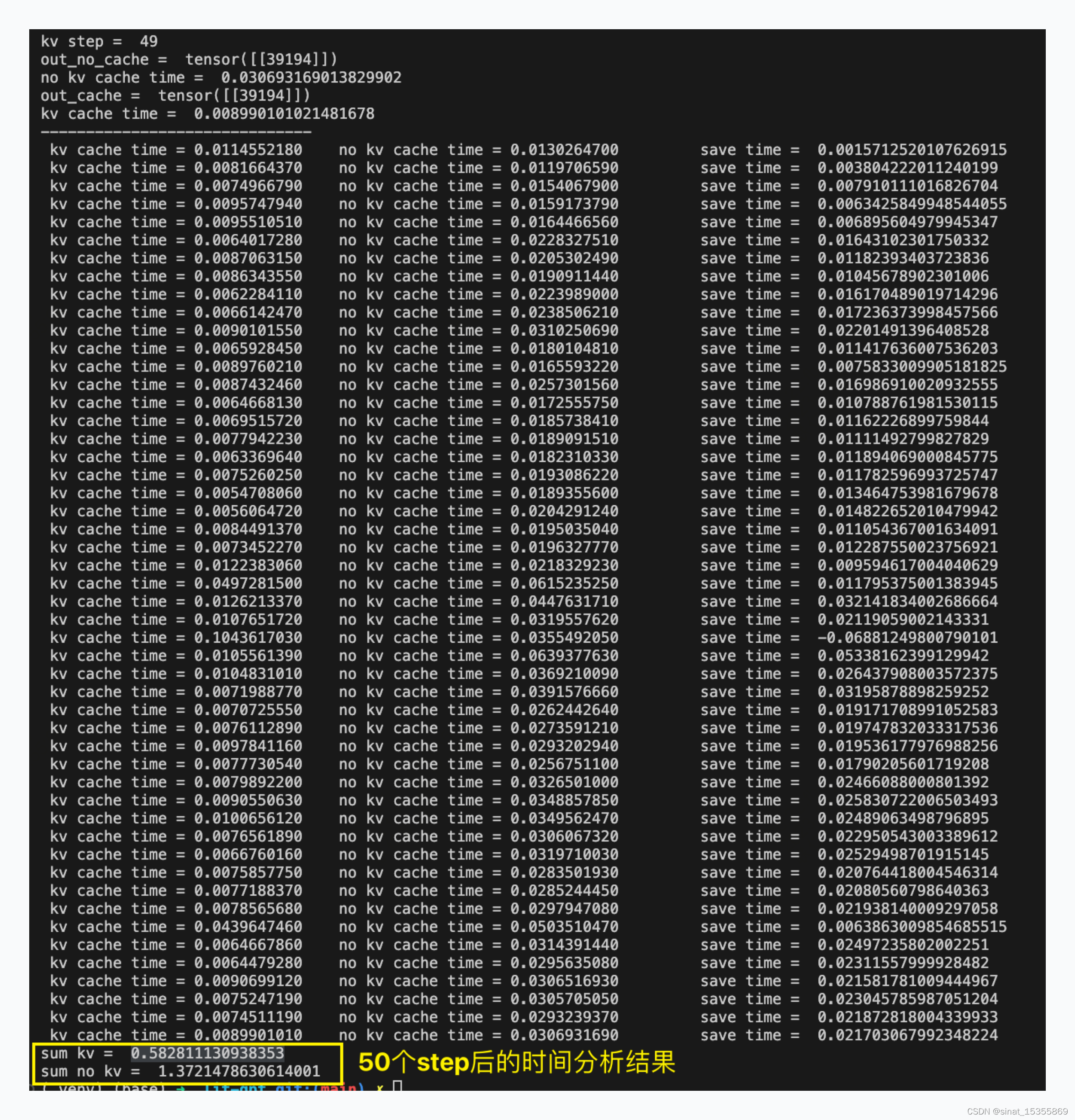
3、kv cache 代码模块有哪些?(使用kv cache 是否影响最后结果?使用kv cache到底提速了多少?)
先贴结论:
kv cache是用于加速自注意力计算的技术。
在自注意力机制中,需要计算查询(query)向量与键(key)向量的内积,以及键向量与值(value)向量的内积。这需要大量的计算资源。
为了加速计算,一些实现会缓存键和值的内积结果。即在第一次计算自注意力时,会将键向量和值向量的内积预先计算出来,存储在kv cache中。
在后续的自注意力计算中,就直接读取kv cache中的结果,而不需要每次都计算键和值的内积,从而减少了大量重复计算。
这种缓存键和值内积的思想就是kv cache。它仅需要计算查询和缓存的内积,极大地减少了自注意力的计算量。
kv cache通常用于训练长序列时的加速。它只需要计算和缓存一次键值内积,就可以重复使用。这对计算资源需求极大的长序列建模带来很大性能提升。
总之,kv cache是自注意力计算的重要优化手段,可以减少大量重复计算,特别适合用于训练长序列的Transformer模型。它已经成为 Transformer 类模型的标准组件之一。

文章首发在“小晨的AI工作室”
因为无法上传高清大图,请公众号回复“kv_cache”进行下载原图。