2020在CVPR
摘要
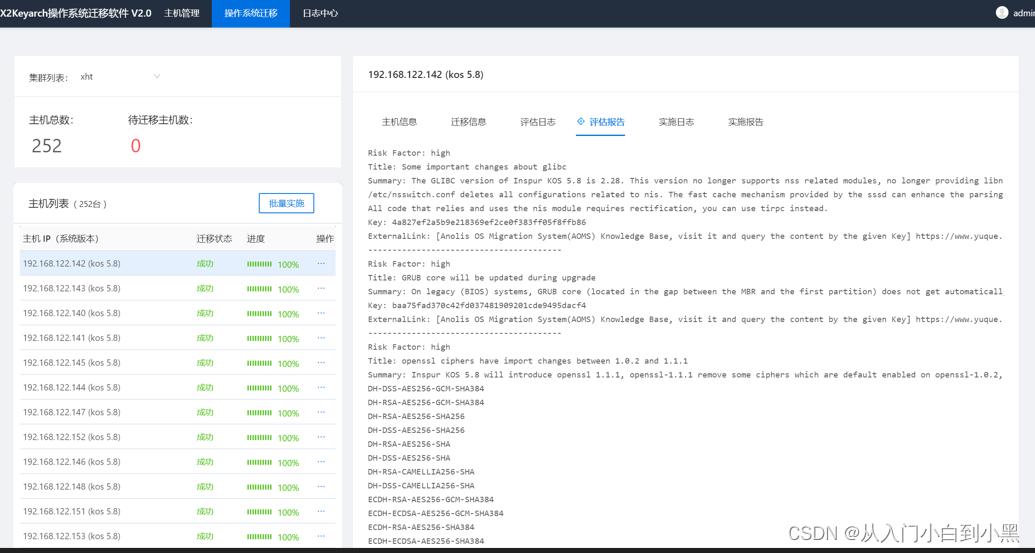
人体的不同部分在行走过程中具有明显不同的视觉外观和运动模式。在最新的文献中,使用部分特征进行人体描述已被证实有利于个体识别。综上所述,我们假设人体的每个部分都需要自己的时空表达。然后,我们提出了一种新的基于部分的模型GaitPart,并获得了提高性能的两个方面效应:一方面,提出了一种新的卷积应用Focal Convolution层来增强部分级空间特征的细粒度学习。另一方面,提出了微运动捕获模块(MCM),GaitPart 中有几个并行的 MCM,分别对应于人体的预定义部分。值得一提的是,MCM 是步态任务的时间建模的新方法,它侧重于短程时间特征,而不是用于周期步态的冗余长程特征。
引言
GaitSet[5]假设轮廓的外观包含位置信息,因此将步态视为提取时间信息的集合
先前的方法将整个人体形状视为一个单元来提取时空信息以进行最终识别
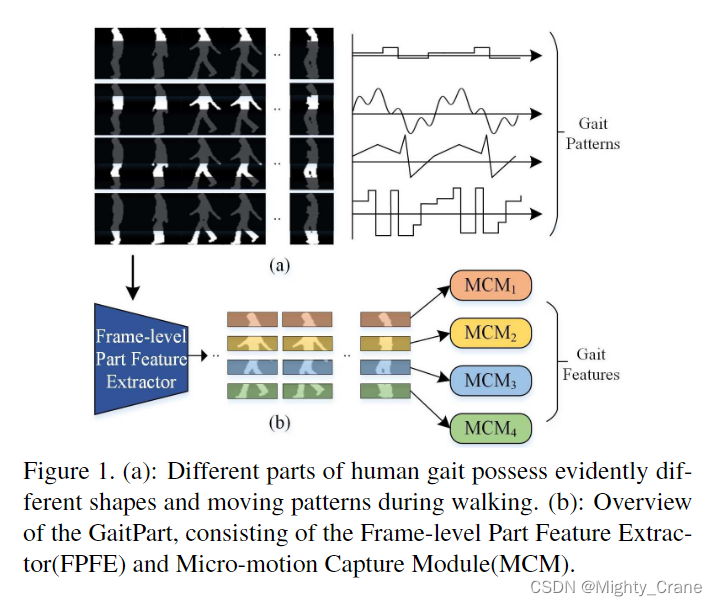
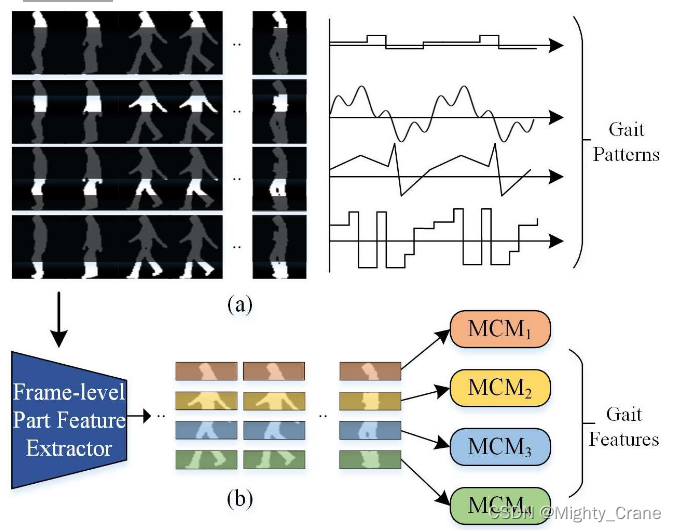
(要么是gei那样压缩成一张图,要么是序列)。然而,我们观察到人体的不同部分在行走过程中具有明显不同的形状和运动模式,如图1(a)所示。[6、15、20、5、12、13、19、28]的更多证据表明,人体描述的部分特征可以提供细粒度的信息,有利于个体识别任务。对于时间变化特征,其中一些最先进的方法没有明确地对时间特征进行建模,这导致时间序列中重要不变特征的损失[23,7,3,26](所有才有后来gaitgl设计的时域池化等操作)。其他一些方法通过深度堆叠 3D 卷积或循环操作 [25,30]来模拟远程依赖来表示步态序列的全局理解。然而,这些方法被认为保留了周期性步态不必要的远程顺序约束,从而失去了步态识别的灵活性[5]。
受上述发现的启发,我们假设人体的每个部分都需要自己的表达,其中局部短程时空特征(微运动模式)是人类步态最具辨别力的特征。因此,我们提出了一种新的基于时间部分的框架GaitPart(也就是说这之前的做法都在使劲憋长程依赖从而专心搞全局,现在gaitpart又开始另一种极端专心搞局部)。如图1(b)所示,GaitPart由两个新颖的设计良好的组件组成,即帧级部分特征提取器(FPFE)和微运动捕获模块(MCM)。
GaitPart的输入是步态轮廓序列。FPFE 是一种特殊但简洁的堆叠 CNN,首先将每一帧作为输入,然后对输出特征图进行预定义的水平划分。这样,我们可以得到图1(b)中彩色的几个部分级空间特征序列,每个序列对应于人体的某个预定义部分,其对应的MCM将捕获其微运动模式。请注意,这些并行MCM中的参数是独立的,这反映了GaitPart是一种独立于部分的方法。最终的步态表示是通过简单地连接这些MCM的所有输出来形成的。(逐帧处理还不共享权重,按说这样时空复杂度都很炸啊)
我们认为局部短程时空特征(微运动模式)是周期性步态最具鉴别性的特征,而长程依赖是冗长和低效的
相关工作
步态的时间变化建模方法一般分为三类:基于3DCNN的[25]、基于lstm的[30,14]和基于Set的[5]。其中,基于3DCNN的方法[2,1,22,25]直接提取时空特征进行步态识别,但这些方法通常很难训练,不能带来相当大的性能。
(所以gaitgl相当于把3d卷积和集合思想结合的)基于 LSTM 的方法被认为为周期性步态保留了不必要的顺序约束 [5]。通过假设轮廓的外观包含其位置信息,GaitSet[5]提出将步态视为一个集合,并以时间池化的方式提取时空特征。这样足够简洁有效,但没有明确地对时间变化进行建模。
我们观察到具有相似视觉外观的帧可能在周期性步态中周期性地出现,这表明在完整的步态周期后没有判别信息增益。这种现象意味着远程依赖(例如比完整的步态周期长)对于步态识别可能是多余的和无效的。因此,GaitPart 将注意力转向局部短程时间建模,并提出了微运动捕获模块。
方法
FPFE
由Focal卷积组成,也就是在卷积计算之前先把特征图切条(p个),感受野更聚焦
时间特征聚合器 (TFA)
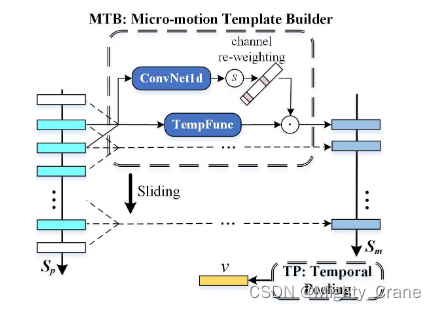
微运动模板构建器
描述。将帧级部分信息特征向量映射到微运动特征向量中。
动机。假设短程时空表示(微运动特征)是周期步态最具鉴别性的特征,认为任意某一时刻的微运动模式应完全由自身及其相邻帧决定。
MTB就像滑动窗口检测器一样。一方面,窗口内的所有帧级特征向量将被 TempFunc 压缩成微运动矢量。另一方面,引入通道注意机制使模型能够根据窗口内的特征重新加权微运动向量,从而突出更具辨别力的运动表达式以进行最终识别。
MCM中有两个MTB,使用不同的窗口大小(3和5),如图5所示。每个MTB中Conv1dNet的确切结构如图Tab所示。2.这种设计的目的是在序列维度上融合多尺度信息,从而收集更丰富的微运动特征。
TP
时间聚合其核心思想是周期步态的完整周期后没有判别信息增益
现实世界步态视频的长度是不确定的,mean(·) 的统计函数似乎是一个糟糕的选择。
(所以再结合公式最后选择了最大池化)
实现
在训练阶段,对于步态视频的长度是不确定的,采样器应该收集固定长度的片段作为输入:首先截取 30-40 帧长度段,然后随机提取 30 个排序帧进行训练。特别是,如果原始视频的长度小于15帧,它将被丢弃。虽然长度超过 15 帧但少于 30 帧,但它将被重复采样。
(30帧采样的开端?)