目录
环境
一,安装和部署redis
1,安装
2,部署
编辑 3,允许非本机连接redis
二、主从模式
主从模式搭建:
三,哨兵模式
哨兵模式搭建
四,集群模式
架构细节:
心跳机制
集群模式搭建:
jedis连接集群
最后
环境
centOS7
redis5
vm12
一,安装和部署redis
1,安装
Redis是C语言开发的,安装redis需要先去官网下载源码进行编译,编译需要依赖于GCC编译环境,如果 CentOS上没有安装gcc编译环境,需要提前安装,安装命令如下:(这里我们使用root用户处理这些操 作)
键入命令:
yum install gcc
有一个redis压缩包在/usr/myapps下,至于redis的压缩包是如何放入centos的,我在此就不做演示了(我是使用Mobaterm连接虚拟机,然后传输文件到虚拟机中),然后解压该压缩包
键入命令:
tar -zxvf redis-5.0.5.tar.gz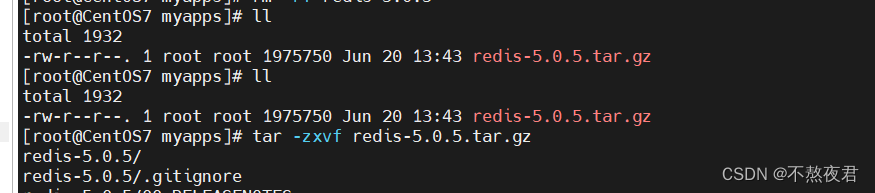
解压后,解压完的文件名为redis.5.0.5,然后我们进入到此文件下,键入如下命令进行安装:
make PREFIX=/usr/myapps/redis install //这里指定了redis的安装目录为/usr/myapps/redis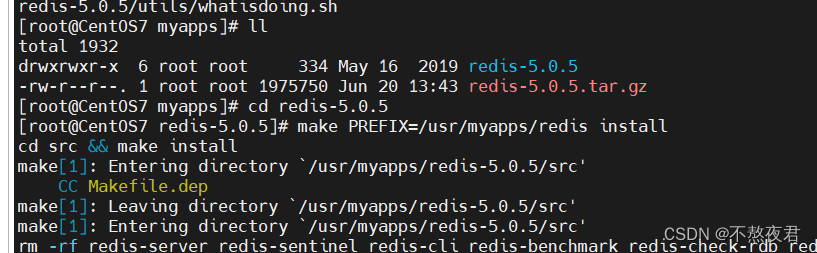
安装完之后,我们还需要将redis的配置文件复制过来,因为在/usr/myapps/redis中,只有bin/文件夹,而没有配置文件,配置文件在redis-5.0.5中,将其复制过来就可以了。
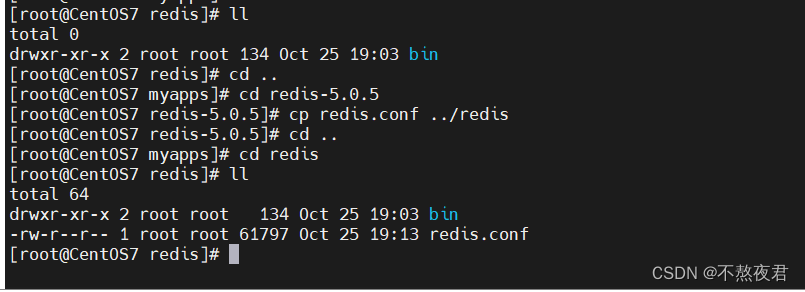
2,部署
redis的启动方式有两种,一种是前端启动,还有一种是端启动,如下:
启动的时候注意要关闭防火墙
systemctl disable firewalld //永久关闭
systemctl stop firewalld //临时关闭
systemctl status firewalld //查看防火墙状态2.1,前端启动(用的很少)
在/usr/myapps/redis下键入命令:
./bin/redis-server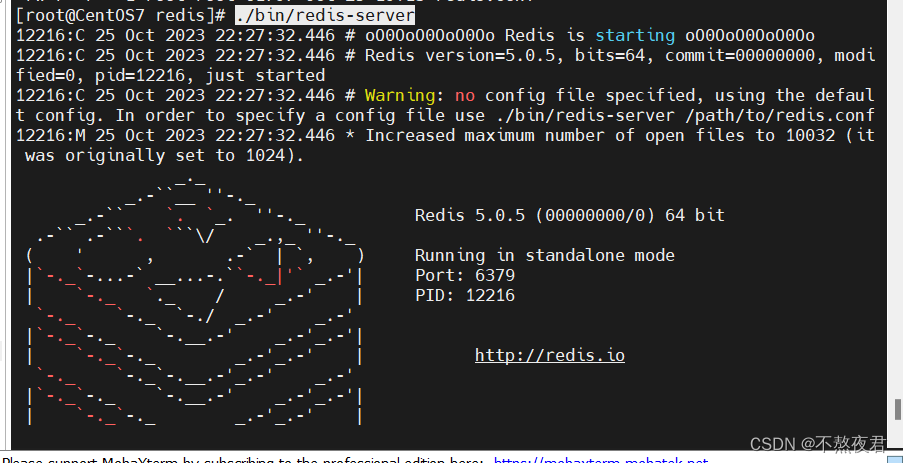 前端启动之后,,不能再进行其他操 作,如果要操作必须使用ctrl+c,同时redis-server程序结束,不推荐此方法。
前端启动之后,,不能再进行其他操 作,如果要操作必须使用ctrl+c,同时redis-server程序结束,不推荐此方法。
2.2,后端启动
在后端启动之前,我们首先要修改redis.conf文件来允许后端启动,在redis.conf的文件中的如下位置修改daemonize,将no改为yes,然后保存退出。
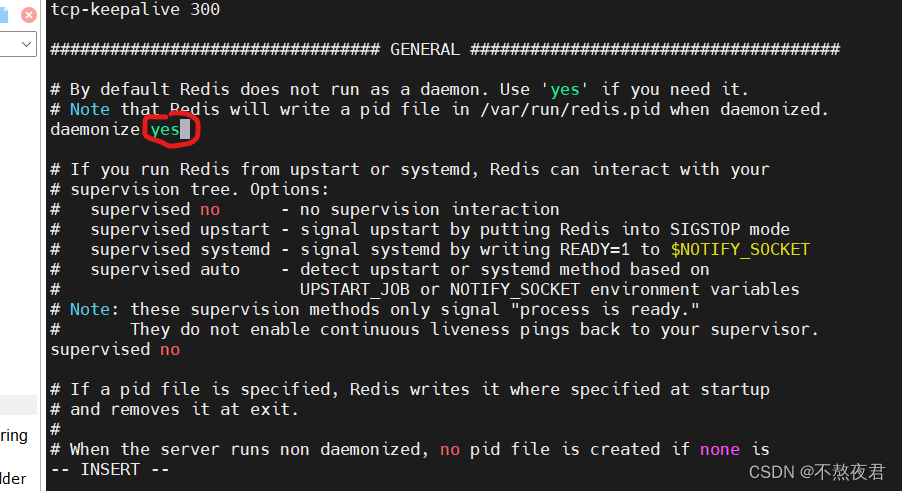
之后,键入命令后端启动redis
./bin/redis-server ./redis.conf键入命令连接redis
./bin/redis-cli -h 127.0.0.1 -p 6379 //默认是127.0.0.1和6379,所以也可以不用写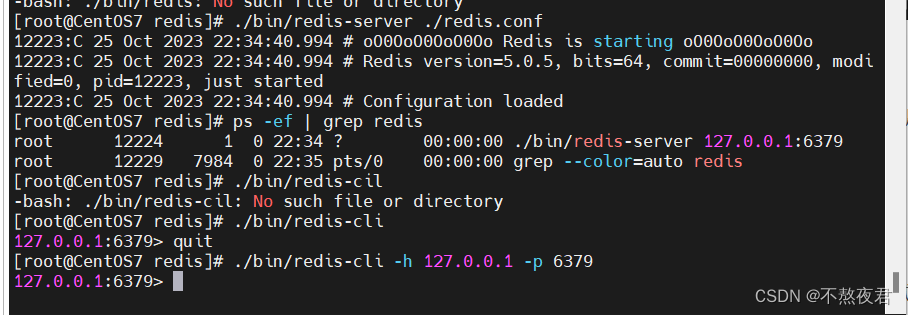
键入一下命令关闭redis连接:
./bin/redis-cli shutdown当然其实也可以使用直接杀死redis进程的方式来结束redis连接。
 3,允许非本机连接redis
3,允许非本机连接redis
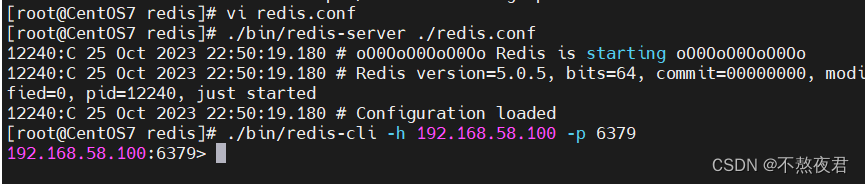
同样我们还是需要来修改redis.conf文件,在redis.conf找到如下地方,修改bind后面的ip,改成允许连接的ip,

修改完之后,可以看到我们可以使用192.168.58.100来连接redis,可以看到连接成功。
 我们也可以使用redis的图形化工具在windows上链接contos上的redis服务器。如下:
我们也可以使用redis的图形化工具在windows上链接contos上的redis服务器。如下:

我们在redis客户端上存入数据
 可以看到在redis的图形化工具上也存在我们存入的值。
可以看到在redis的图形化工具上也存在我们存入的值。

系统中只有一台redis服务器是不可靠的,容易出现单点故障。为了避免单点故障,可以使用多台redis服务器组成redis集群。redis支持三种集群模式。
二、主从模式
至少需要两台redis服务器,一台主节点(master)、一台从节点(slave),组成主从模式的Redis集群。通常来说,master主要负责写,slave主要负责读,主从模式实现了读写分离。
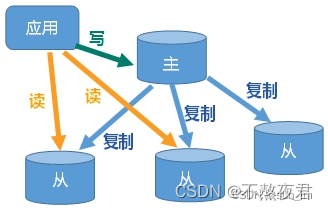
集群中有多台redis节点,就必须保证每个节点中的数据是一致的。redis中,为了保持数据一致性,数据总是从master复制到slave,这就是redis的主从复制。
主从复制的作用:
数据冗余:实现了数据的热备份,是持久化之外的另一种数据冗余方式
故障恢复:master故障时,slave可以提供服务,实现故障快速恢复
负载均衡:master负责写,slave负责读。在写少读多的场景下可以极大提高redis吞吐量
高可用基石:主从复制是redis哨兵模式和集群模式的基础。
主从复制实现原理:
主从复制过程主要可以分为3个阶段:连接建立阶段、数据同步阶段、命令传播阶段。
连接建立阶段:在主从节点之间建立连接,为数据同步做准备。
数据同步阶段:执行数据的全量(或增量)复制(复制RDB文件)
命令传播阶段:主节点将已执行的命令发送给从节点,从节点接收命令并执行,从而实现主从节点的数据一致性
主从模式中,一个主节点可以有多个从节点。为了减少主从复制对主节点的性能影响,一个从节点可以作为另外一个从节点的主节点进行主从复制。
不足之处:主节点宕机之后,需要手动拉起从节点来提供业务,不能达到高可用。
主从模式搭建:
我们将上述使用的redis复制一份到/usr/myapps/redis1中
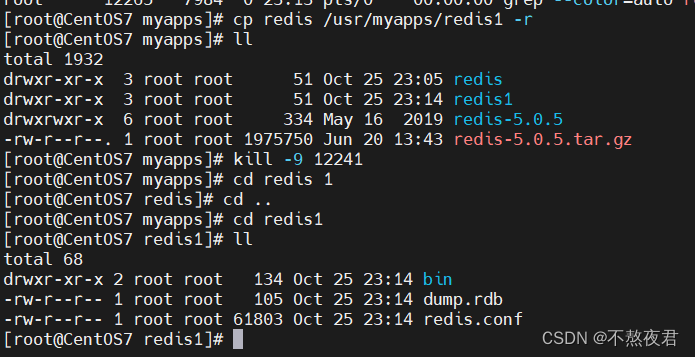
清除redis1中的持久化文件,键入命令:
rm -rf dump.rdb然后修改redis1的配置文件redis.conf,在文件中找到如下内容的位置,然后修改 replicaof <masterip> <masterport>,改为主服务器的ip和端口号。
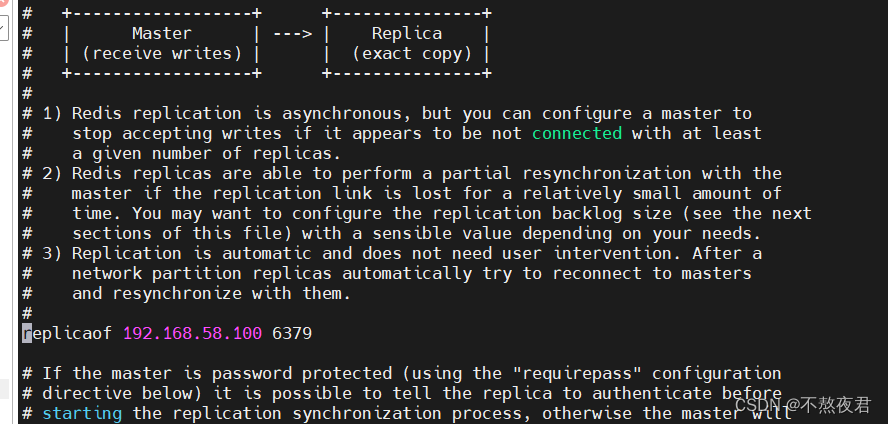
然后再修改从机的监听端口为6380

之后保存并且退出,然后启动从机。连接从机之后,输入info命令
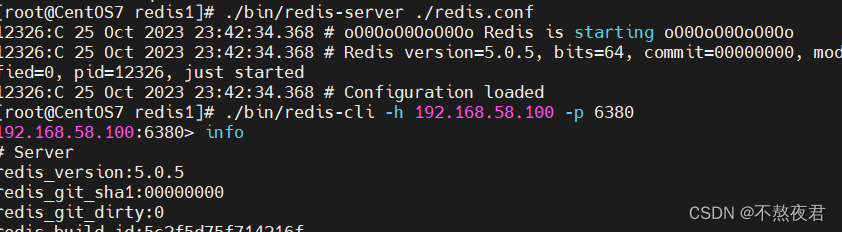
我们可以在info命令下看到此从机的信息。
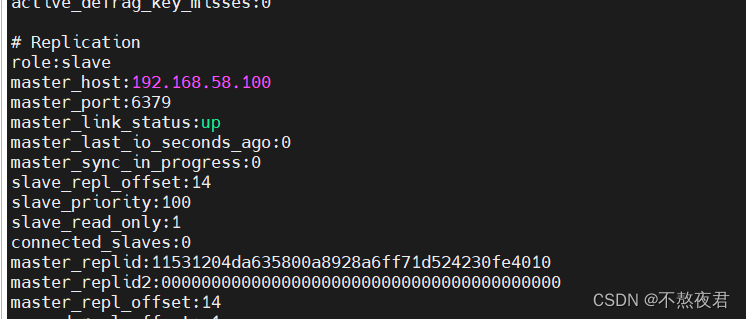
在从机中可以取到主机中的数据,但是自己不可以上传数据。

主从模式的搭建就到这里。
三,哨兵模式
Redis Sentinel是Redis的高可用实现方案,它可以实现对redis的监控、通知和自动故障转移,当redis master挂掉之后,可以自动拉起slave提供业务,从而实现redis的高可用。为了避免Sentinel本身出现单点故障,Sentinel自己也可采用集群模式。
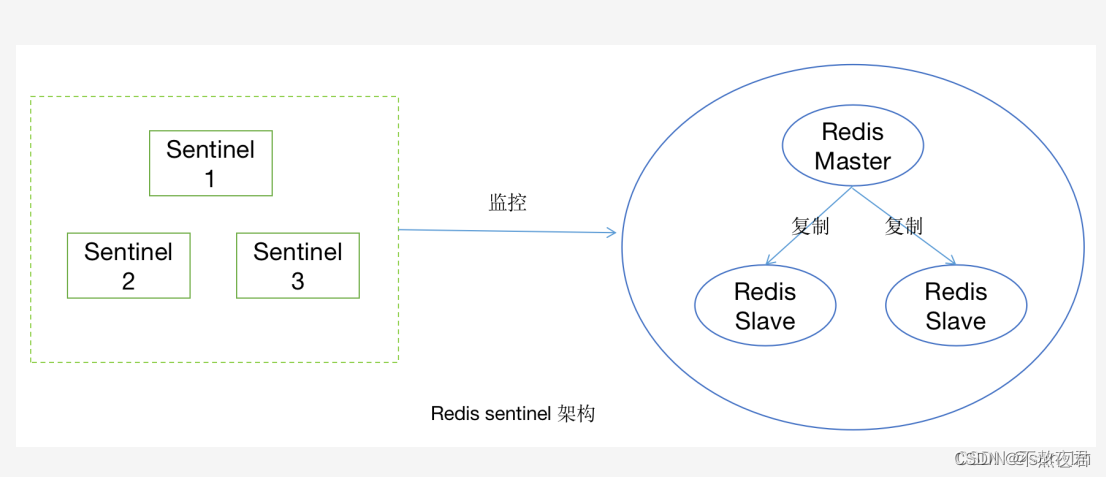
哨兵模式的原理
Sentinel是一种特殊的redis节点,每个sentinel节点会维护与其他redis节点(包括master/slave/sentinel)的心跳。
当一个sentinel节点与master节点的心跳丢失时,这个sentinel节点就会认为master节点出现了故障,处于不可用的状态,这种判定叫作主观下线(即sentinel节点自己主观认为master下线了)
之后,这个sentinel节点会与其他sentinel节点交换信息,如果发现认为主节点发生故障的sentinel节点的个数超过了某个阈值(通常为sentinel节点总数的1/2+1,即超过半数),则sentinel会认为master节点已经处于客观下线的状态,即大家都认为master故障不可用了。
之后,sentinel节点中会选举处一个sentinel leader来执行redis主节点的故障转移。
被选举出的 Sentinel 领导者进行故障转移的具体步骤如下:
(1)在从节点列表中选出一个节点作为新的主节点
过滤不健康或者不满足要求的节点;
选择 slave-priority(优先级)最高的从节点, 如果存在则返回, 不存在则继续;
选择复制偏移量最大的从节点 , 如果存在则返回, 不存在则继续;
选择 runid 最小的从节点。
(2)Sentinel 领导者节点会对选出来的从节点执行 slaveof no one 命令让其成为主节点。
(3)Sentinel 领导者节点会向剩余的从节点发送命令,让他们从新的主节点上复制数据。
(4)Sentinel 领导者会将原来的主节点更新为从节点, 并对其进行监控, 当其恢复后命令它去复制新的主节点。
哨兵模式搭建
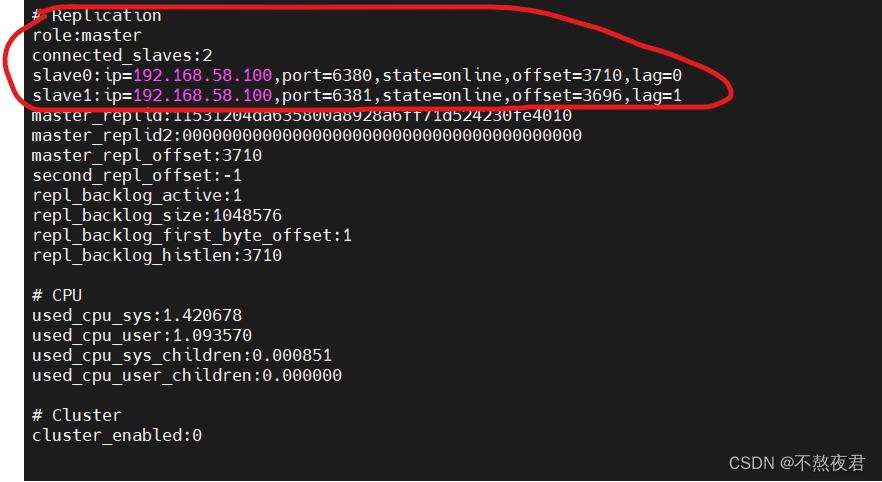
首先我们将上述的redis1复制一份改为redis2,在redis.conf中修改port为6381,所以这个时候,主机redis拥有两个从机一个是redis1,还有一个是redis2,如下图:连接上redis之后输入info,可以看到两个从机的信息,说明主从运行正常。
后面我们在redis2上安装一个哨兵。首先在redis2的bin下创建一个sentinel.conf文件,文件内容含义如下:
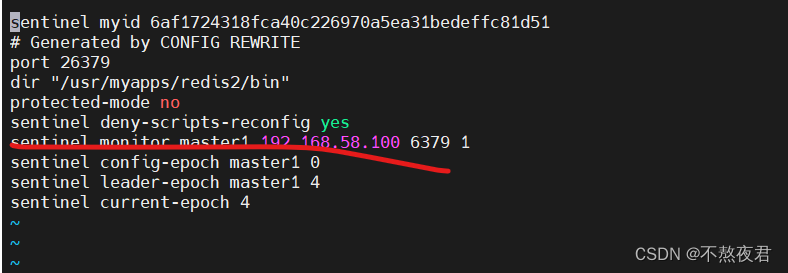
启动哨兵进程,首先需要创建哨兵配置文件vi sentinel.conf,可从源码配置redis5.0.5/sentinel.conf中复制内容,也可以直接自定义该文件到bin目录下 在配置中输入:sentinel monitor mastername 内网IP(127.0.0.1) 6379 1 说明: mastername 监控主数据的名称,自定义 127.0.0.1:监控主数据库的IP; 6379:端口 1:最低通过票数
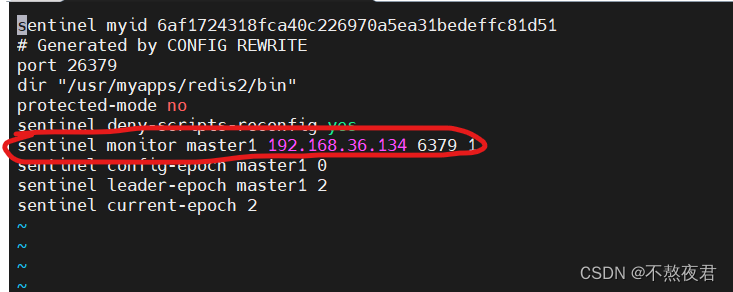
只有画红线的这一行是我们写的其他是我运行之后redis自行生成的。
之后我们创建一个日志文件,用于记录哨兵的日志
./redis-sentinel ./sentinel.conf >sent.log & 之后启动哨兵,键入命令:
之后启动哨兵,键入命令:
./redis-server sentinel.conf --sentinel查看进程可以看到我们的哨兵进程
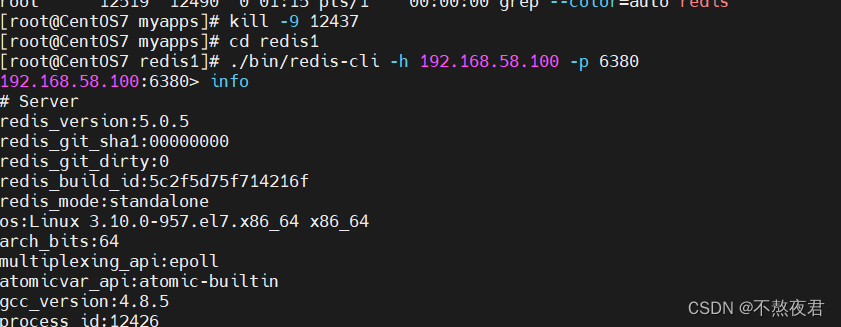
启动之后,我们将我们的redis主机宕机,之后我们查看redis1,我们发现 redis2成为主机了(redis1也可以,是随机的)
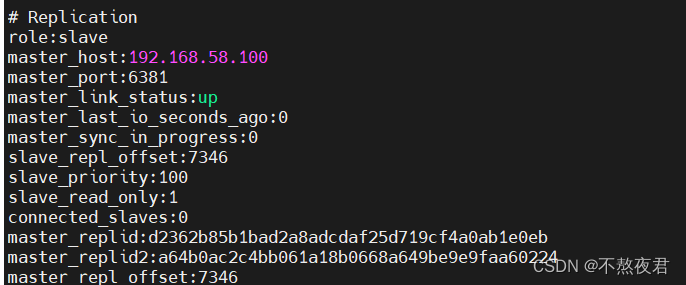 我们重新启动redis以后,查看信息,发现,redis2依然是主机,所以主机不可抢夺。
我们重新启动redis以后,查看信息,发现,redis2依然是主机,所以主机不可抢夺。

四,集群模式
主从模式实现了数据的热备份,哨兵模式实现了redis的高可用。但是有一个问题,这两种模式都没有解决,这两种模式都只能有一个master节点负责写操作,在高并发的写操作场景,master节点就会成为性能瓶颈。
redis的集群模式中可以实现多个节点同时提供写操作,redis集群模式采用无中心结构,每个节点都保存数据,节点之间互相连接从而知道整个集群状态。
如图所示集群模式其实就是多个主从复制的结构组合起来的,每一个主从复制结构可以看成一个节点,那么上面的Cluster集群中就有三个节点。
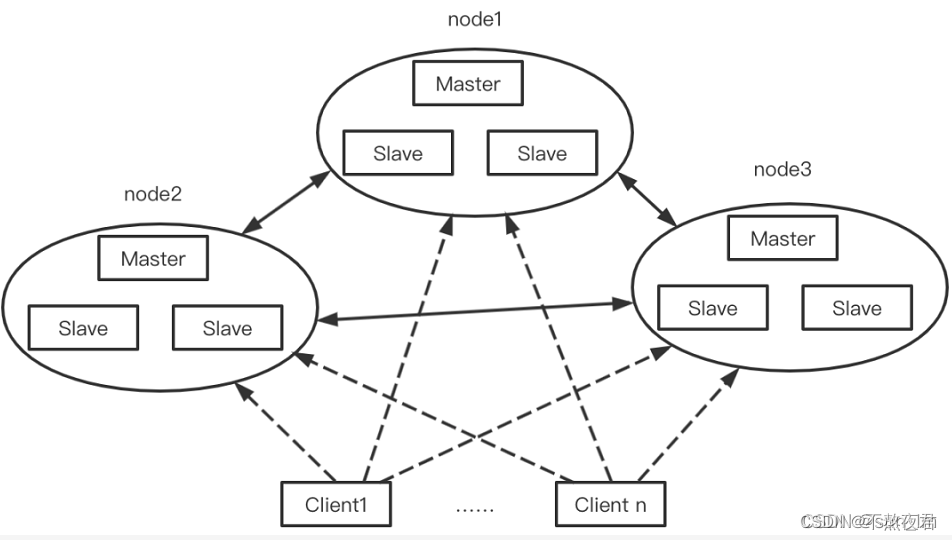
架构细节:
(1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
(2)节点的fail是通过集群中超过半数的节点检测有效时整个集群才生效.
(3)客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可 用节点即可
(4)redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护nodeslotvalue Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0- 16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点
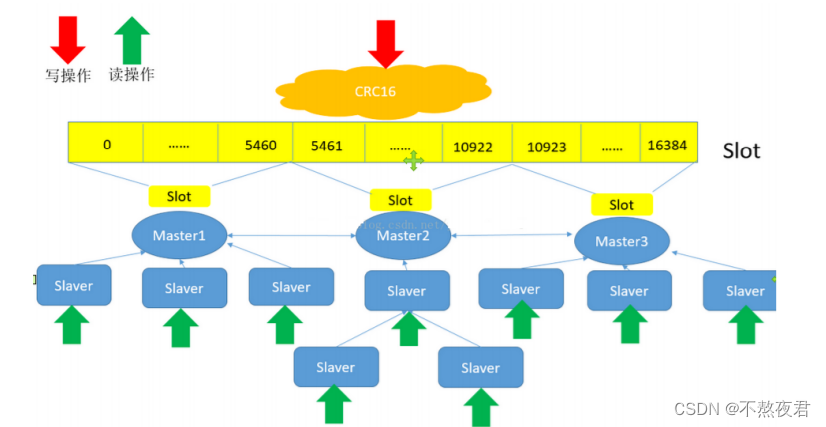
心跳机制
(1)集群中所有master参与投票,如果半数以上master节点与其中一个master节点通信超过(clusternode-timeout),认为该master节点挂掉.
(2):什么时候整个集群不可用(cluster_state:fail)?
如果集群任意master挂掉,且当前master没有slave,则集群进入fail状态。也可以理解成集群的[0- 16383]slot映射不完全时进入fail状态。
如果集群超过半数以上master挂掉,无论是否有slave,集群进入fail状态。
集群模式搭建:
1,创建集群目录:
mkdir redis-cluster
2,创建集群节点
搭建集群最少也得需要3台主机,如果每台主机再配置一台从机的话,则最少需要6台机器。 设计端口如 下:创建6个redis实例,需要端口号7001~7006

3,删除持久化文件
就是删除以rdb或者aof结尾的文件,因为我这里的redis是新装的所以没有持久化文件。
4,修改redis.conf配置文件,打开Cluster-enable yes

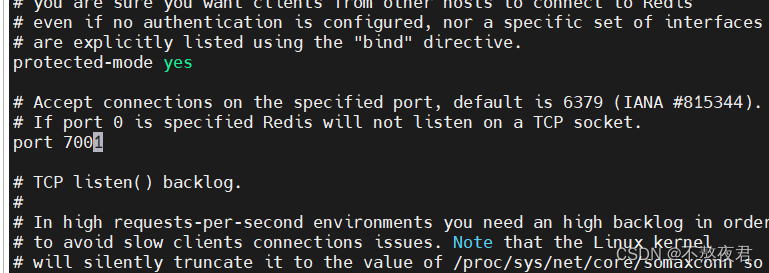
5,修改端口,修改后端启动
6,复制出7002-7006机器
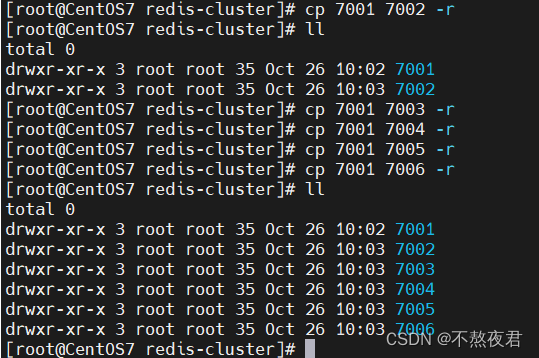
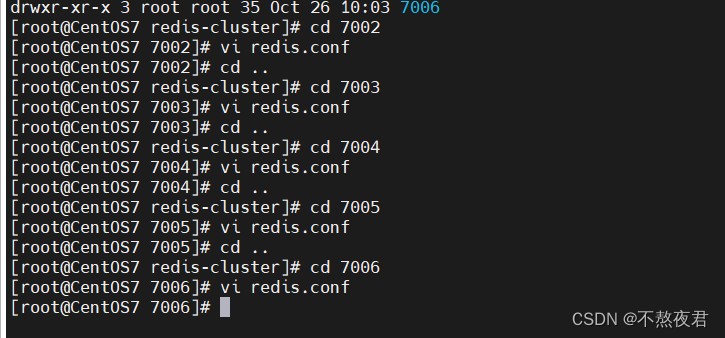
7,修改7002-7006机器的端口
 8,启动7001-7006这六台机器,写一个启动脚本:自定义shel脚本
8,启动7001-7006这六台机器,写一个启动脚本:自定义shel脚本

cd 7001
./bin/redis-server ./redis.conf
cd ..
cd 7002
./bin/redis-server ./redis.conf
cd ..
cd 7003
./bin/redis-server ./redis.conf
cd ..
cd 7004
./bin/redis-server ./redis.conf
cd ..
cd 7005
./bin/redis-server ./redis.conf
cd ..
cd 7006
./bin/redis-server ./redis.conf
cd ..
9,修改文件权限
为拥有者加上可执行的权限·。
chmod u+x startall.sh
10,启动所有实例


11,配置集群关系
随便进入一个服务器的配置文件执行如下命令
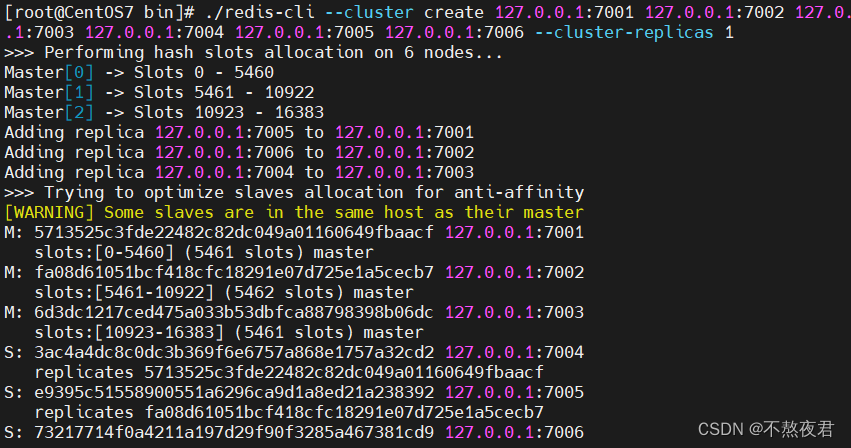
./redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 执行完之后,由弹出的信息 可以看到redis的主从关系已经配置好了。
11,连接集群
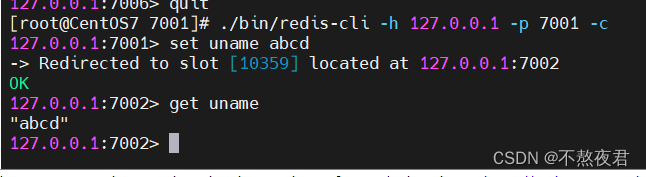
注意,连接集群和普通连接不同,加上-c代表以集群的方式连接
./bin/redis-cli -h 127.0.0.1 -p 7001 -c可以看到,连接上7001后,我们存入7001的uname却被重定向存入到时槽10359中,而这个时槽是交由7002管理的,所以,uname实际存入了7002。
由上我们就可以知道。只要连接了集群其中的一个服务器,就相当于连接了整个集群。
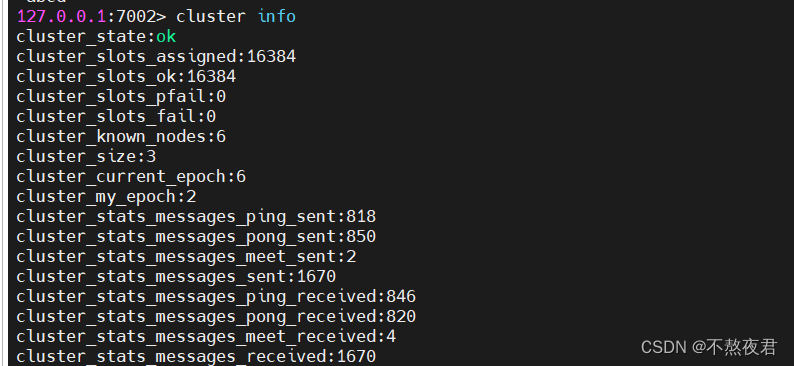
12,查看集群信息
jedis连接集群
1,创建一个maven项目大家都会吧,这里就不演示了。
2,导入jedis依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>3,创建类
package jedis;
/*
*@Author:天动万象
*@Date:2023/10/27
*@Description:
*@VERSION: 1.8
*/
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.JedisCluster;
import java.io.IOException;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class cluster {
public static void main(String[] args) throws IOException {
// 创建一连接,JedisCluster对象,在系统中是单例存在
Set<HostAndPort> nodes = new HashSet<HostAndPort>();
nodes.add(new HostAndPort("192.168.197.132", 7001));
nodes.add(new HostAndPort("192.168.197.132", 7002));
nodes.add(new HostAndPort("192.168.197.132", 7003));
nodes.add(new HostAndPort("192.168.197.132", 7004));
nodes.add(new HostAndPort("192.168.197.132", 7005));
nodes.add(new HostAndPort("192.168.197.132", 7006));
JedisCluster cluster = new JedisCluster(nodes);
// 执行JedisCluster对象中的方法,方法和redis指令一一对应。
cluster.set("test1", "test111");
String result = cluster.get("test1");
System.out.println(result);
//存储List数据到列表中
cluster.lpush("site-list", "java");
cluster.lpush("site-list", "c");
cluster.lpush("site-list", "mysql");
// 获取存储的数据并输出
List<String> list = cluster.lrange("site-list", 0 ,2);
for(int i=0; i<list.size(); i++) {
System.out.println("列表项为: "+list.get(i));
}
// 程序结束时需要关闭JedisCluster对象
cluster.close();
System.out.println("集群测试成功!");
}
}
注意:使用非本机连接前,先要修改集群中的每个服务器的redis.conf文件,至于修改什么,我在这篇博客中已经讲过,所以不再赘述。
最后
本篇博客对redis集群理论和搭建就到这里了,如果本篇博客对你有帮助的话请点赞收藏支持一下,谢谢!答应我!不要白嫖好吗?哈哈哈!咱们下篇博客见。