实际业务场景中,除了各类条件计算、同环比计算以外,排名也是比较常见的问题,我们经常需要使用Rankx函数来进行某些TopN计算等。
微软新推出的开窗函数Rank,可以说是对排名问题的一次优化,也解决了一些之前Rankx函数的坑点。
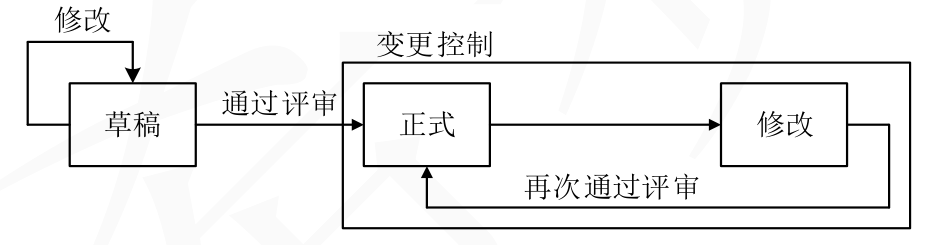
Rank函数基本语法
RANK ( [<ties>][, <relation>][, <orderBy>][, <blanks>][, <partitionBy>][, <matchBy>] )
参数介绍:
ties:可选项,DENSE或SKIP,相同值的排名处理。
relation:可选项,排名依据的表或表表达式。
orderBy:可选项,排序依据,如果省略,第2参数需绑定。
blanks:可选项,处理空值排名位置使用。
partitionBy:可选项,分区定义,参照SQL的开窗分区即可。
matchby:可选项,定义匹配数据和标识当前行的列的语句。
PS:
看起来参数很多,实际上我们日常中用到第2参数和第3参数的频率较高,其他参数一般是为了处理某些特殊场景时使用。

先来看看本期的案例数据:



案例数据共计3张表,产品表、分店表以及事实表,将其导入到PowerBI中,模型关系如下:

添加基础度量值:
销售金额:
001.SalesAmount =
SUMX ( 'Fact_Sales', 'Fact_Sales'[Quantity] * RELATED ( Dim_Product[Price] ) )
销售成本:
002.SalesCost =
SUMX ( 'Fact_Sales', 'Fact_Sales'[Quantity] * RELATED ( Dim_Product[Cost] ) )
销售利润:
003.SalesProfit =
[001.SalesAmount] - [002.SalesCost]
销售单价:
001.Price =
SUM ( 'Dim_Product'[Price] )
销售单位成本:
002.Cost =
SUM ( 'Dim_Product'[Cost] )
到这里,我们的准备工作完成,接下来我们来看看在不同的场景中,Rank函数的表现。
①.浮点运算
浮点运算指的是因为数值小数位过长,而导致排名发生错乱的情况,比如,我们添加如下代码:
004.ProfitRankx =
IF (
HASONEFILTER ( Dim_Store[City] ),
RANKX ( ALLSELECTED ( 'Dim_Store' ), [003.SalesProfit] )
)
其结果如下图:

可以看到有很多依据值不同的维度,排名却是相同的,之前我们的处理方式如下:
005.ProfitRankxAmend =
IF (
HASONEFILTER ( Dim_Store[City] ),
RANKX ( ALLSELECTED ( 'Dim_Store' ), ROUND ( [003.SalesProfit], 2 ) )
)

解决的思路是利用ROUND函数将依据值处理成固定位数,来避免浮点计算差。
而有了Rank函数之后,我们无需考虑这种情况。
006.ProfitRank =
RANK ( ALLSELECTED ( 'Dim_Store' ), ORDERBY ( [003.SalesProfit], DESC ) )
结果如下:

②.并列排名
实际场景中,经常会出现并列排名的情况,一般情况的处理办法是发现并列排名,则进行加权处理。
例如,我们现在根据销售价格,对产品进行排序。
003.RankxPrice =
RANKX ( ALLSELECTED ( 'Dim_Product' ), [001.Price],, ASC )
结果如下:

为了解决并列排名,我们选择将产品单位成本进行加权。
004.RankxPriceCost =
RANKX (
ALLSELECTED ( 'Dim_Product' ),
[001.Price]
+ RANKX ( ALLSELECTED ( 'Dim_Product' ), [002.Cost],, ASC ) / 10000,
,
ASC
)
结果如下:

写法上对性能是有损耗的,有了Rank函数后,我们可以换一种写法。
005.RankPriceCost =
RANK (
ALLSELECTED ( 'Dim_Product' ),
ORDERBY ( [001.Price], ASC, [002.Cost], ASC )
)
结果如下:

写法上对比Rankx的处理方式,无疑是简洁了很多。
PS:
擅长SQL的小伙伴不难发现,微软就是将SQL中的Rank函数移植到了DAX中,写法上有差异,其内核基本相同。
③.性能方面
我们来分别比较一下两个场景中,Rankx函数和Rank函数的执行性能。

肉眼上可见,在处理浮点运算问题上,二者的差异并不大。

在处理并列排名的问题上,Rank函数的性能是高于Rankx函数的。
除了上述的3个问题之外,还有相关的绝对排名、相对排名以及组内排名等,白茶这里就不赘述了,感兴趣的小伙伴可以自己动手测试。











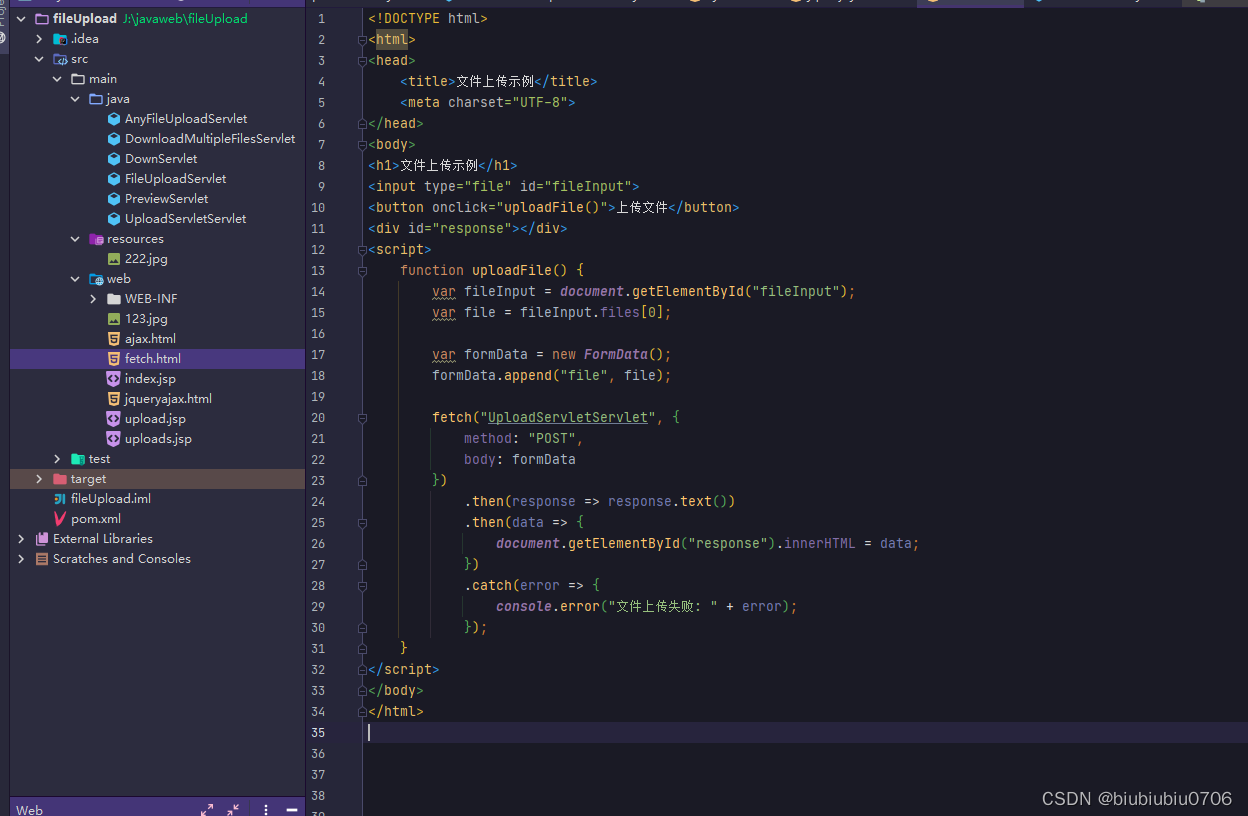
![[17]JAVAEE-HTTP协议](https://img-blog.csdnimg.cn/b248a8002cb847b2a877cb765e0a1b89.png)