在数据库章节中可能会考察以下内容:
文章目录
- 数据库完整性约束🌟
- 数据库模式🌟🌟
- ER模式🌟
- 关系代数🌟🌟
- 并发控制🌟
- 数据仓库与数据挖掘🌟🌟
- 反规范化技术🌟
数据库完整性约束🌟
不能用作数据完整性约束实现技术的是()
A、实体完整性约束
B、触发器
C、参照完整性约束
D、视图
答案选择D
数据完整性包括:
- 实体完整性:即主键约束,主键不能为空,也不能重复。
- 参照完整性:即外键约束,外键必须是其他表中已经存在的主键的值或者为空。
- 用户自定义完整性:自定义表达式约束
- 触发器比较灵活,可以写脚本语言来检查和约束,可以看作是自定义,所以排除法选择是D
数据库模式🌟🌟
数据库管理系统提供授权功能以便控制不同用户访问数据库的权限,其主要的目的是为了实现数据库的()
A、一致性
B、完整性
C、安全性
D、可靠性
答案选择C
看到授权 一般是从安全角度考虑
在分布式数据库中有分片透明、复制透明、位置透明和逻辑透明等基本概念。其中,()是指用户无需知道数据存放的物理位置。
A.分片透明
B.逻辑透明
C.位置透明
D.复制透明
答案选择C,
这一题是历年真题,物理位置肯定是和位置相关的,所以选择位置透明;
分片透明:是用户或应用程序不需要知道逻辑上访问的表具体是如何分块存储的;
逻辑透明:是用户或应用程序无需知道局部使用的是哪种数据模型;
复制透明:是用户或应用程序不关心复制的数据从何而来。
在数据库设计的需求分析、概念结构设计、逻辑结构设计和物理结构设计的四个阶段中,基本E-R图是();数据库逻辑结构设计阶段的主要工作步骤依次为()。
A.需求分析阶段形成的文档,并作为概念结构设计阶段的设计依据
B.逻辑结构设计阶段形成的文档,并作为概念结构设计阶段的设计依据
C.概念结构设计阶段形成的文档,并作为逻辑结构设计阶段的设计依据
D.概念结构设计阶段形成的文档,井作为物理设计阶段的设计依据
A.关系规范化一转换为数据模型一模式优化一设计用户模式
B.转换为数据模型一关系规范化一模式优化一设计用户模式
C.模式优化一设计用户模式一>关系规范化一转换为数据模型
D.设计用户模式一>模式优化一>关系规范化一转换为数据模型
答案选择C、B
在软件工程中 在需求阶段的产物是ER图数据建模;而在数据库设计中,概念结构设计的产物是ER图,
- 需求分析的产物是DFD分层
数据流图、数据字典、需求说明书,获得用户对系统的三个要求:信息要求、处理要求、系统要求。 - 概念结构设计是设计ER图也就是实体联系图,在这一块可能存在冲突:属性冲突、命名冲突、结构冲突。
- 逻辑结构设计的主要工作:将ER图转为关系模式,一般包括:确定数据模型、将er图转换成为指定的数据模型、确定完整性约束和确定用户视图,一般用户模式比较滞后.(
在数据库逻辑结构设计阶段,需要需求分析阶段形成的需求说明文档、数据字典、数据流图作为设计依据) - 物理设计:确定数据分布、存储结构和访问方式。
- 数据库实施阶段:根据逻辑设计和物理设计阶段的结果建立数据库,编制与调试应用程序,组织数据入库,并进行试运行。
- 数据库运行和维护阶段:数据库应用系统经过运行即可投入运行,但该阶段需要不断对系统进行评价、调整与修改。
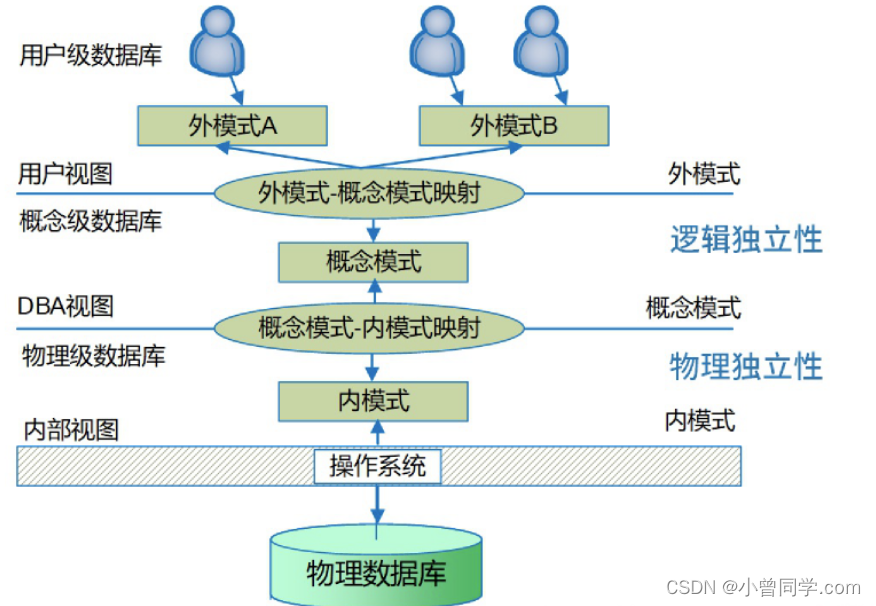
在数据库系统中,数据库的视图、基本表和存储文件的结构分别与(
外模式、模式、内模式)对应;数据的物理独立性和数据的逻辑独立性是分别通过修改(模式与内模式之间的映像、外模式与模式之间的映像 )来完成的。
在数据库中有三级模式和两级映射,两级映射就是外模式-模式映射(逻辑独立性),模式-内模式映射(物理独立性)。
物理独立性是当存储结构发生变化时,应用程序不会变,是存储到数据表之间的映射。
逻辑独立性是是基本表发生了变化,但应用程序不变,即基本表到视图的映射。
ER模式🌟
在数据模型中需要掌握以下内容:
- 概念模型是从用户的角度进行建模,是现实世界到信息世界到第一抽象,是真正的实体-联系模型。
- 数据模型三要素:数据结构、数据操作、数据的约束条件。
- E-R图中
- 实体是:客观存在并可相互区别的事物。
- 联系类型:一对一、一对多、多对多
- E-R模型转换为关系模型,每个实体都对应一个关系模式。
- 关系模型中的数据逻辑结构是一张二维表:
- 优点:建立在严格的数据概念基础上;概念单一、结构简单、清晰,用户易懂易用;存取路径对用户透明,从而数据独立性,安全性,简化 数据库开发工作。
- 缺点:由于存取路径透明,查询效率不如非关系数据模型。
关系代数🌟🌟
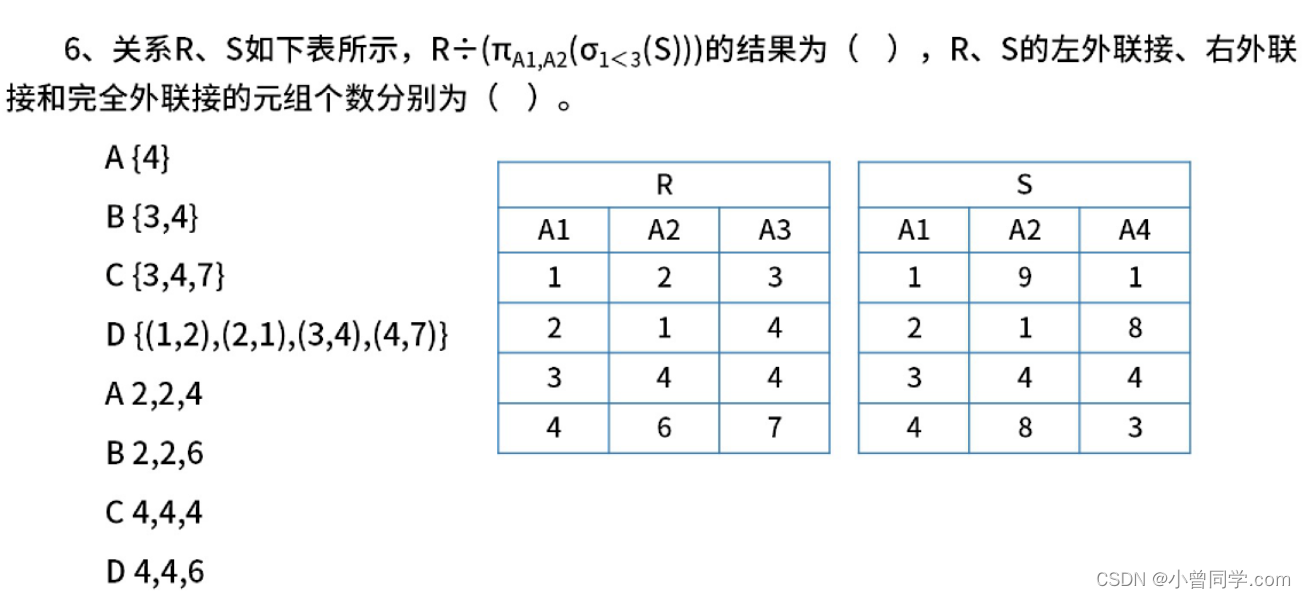
答案是A、D
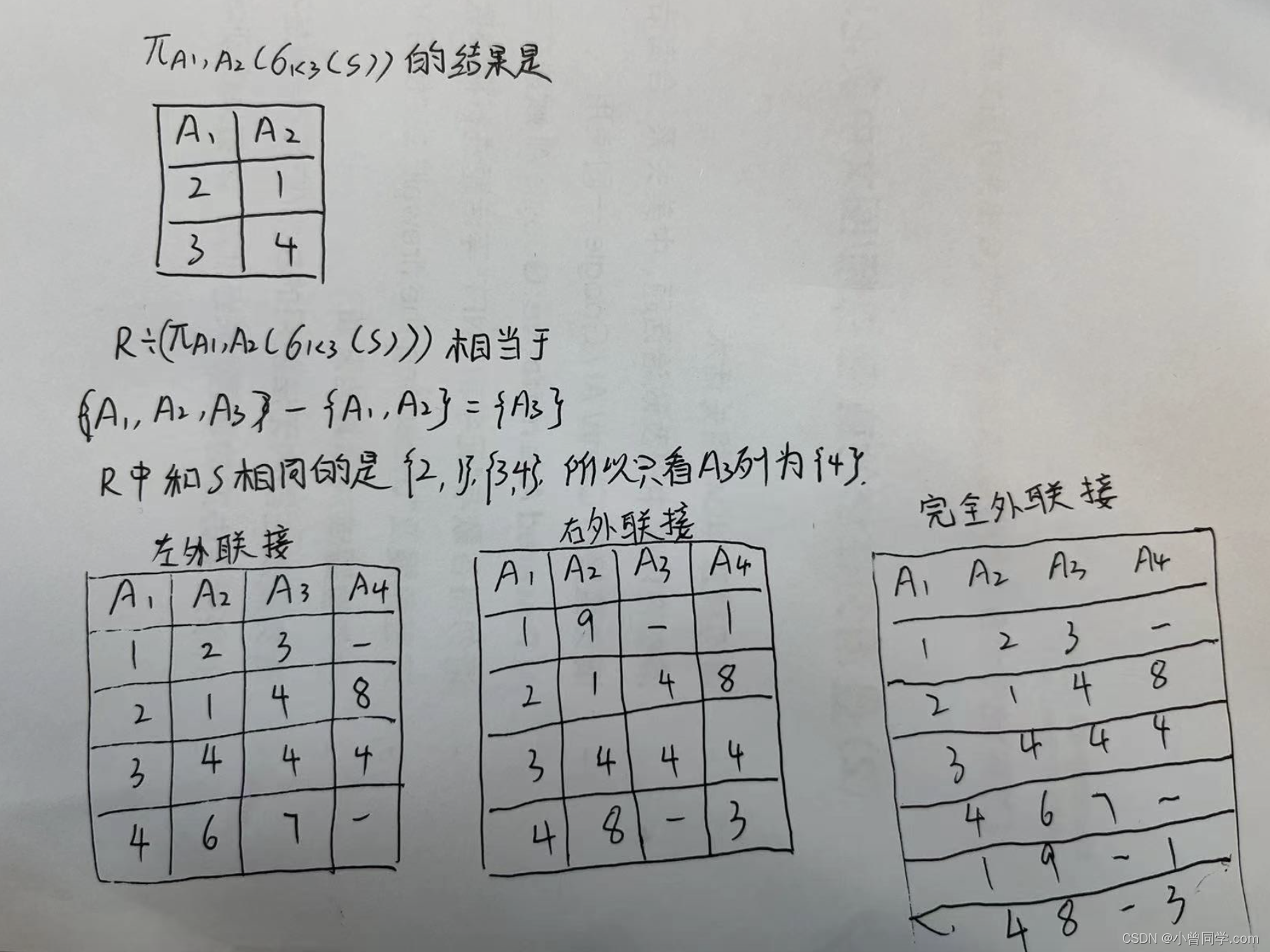
在关系代数中需要掌握:
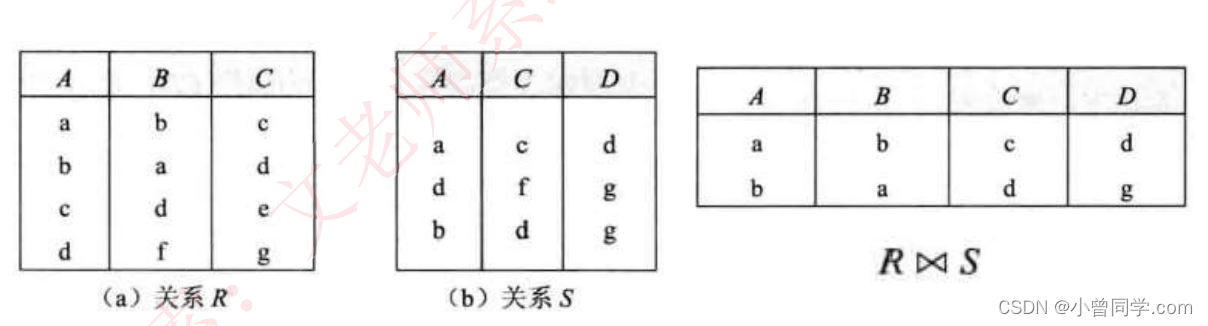
自然连接:显示全部的属性列,但是相同属性列只显示一次,显示两个关系模式中属性相同且值相同的记录。
在数据库模块还需要掌握函数依赖
给定一个X、能唯一确定一个Y,就称X确定Y,或者Y依赖于X,

范式:
第一范式:关系中的每一个分量必须是一个不可分的数据项,就是表中不允许有小表存在。
第二范式:在第一范式的基础上,表中的每一个非主属性不会依赖复合主键中的某一个
列。
第三范式:在满足第一范式的基础上,表中不存在非主属性对码的传递依赖。
BC范式:是在第三范式的基础上进一步消除主属性对于码的部分函数依赖和传递依赖。

在模式分解中,无损分解是分解后的关系模式能够还原出关系模式,不能还原就是有损。

并发控制🌟
数据库中的事物概念:由一系列操作组成,这些操作要么全做,要么全不做,有四大特征:
- 原子性(操作):要么全做,要么全不做
- 一致性(数据):事务发生后数据是一致的,例如A向B转账,不会存在B账户没收到的情况。
- 隔离性(执行):任一事务的更新操作直到其成功提交的整个过程对其他事务都是不可见的,不同事务之间是隔离的,互不干涉。
- 持续性(改变):事务操作的结果是持续性的。
事务是并发控制的前提条件,并发控制就是控制不同的事务并发执行,提高系统效率,但是并发控制中存在三个问题:
- 丢失更新:事务2 对数据的更新会覆盖事务1对数据的更新,所以会丢失事务1对数据的更新,即对数据的更新会被覆盖。
- 不可重复读:事务2读A,而后事务1对数据A进行了修改并写回,此时若事务2再读A,发现数据不对。即一个事务重复读A两次,会发现数据A有误。
- 读脏数据:事务1对数据A进行了修改后,事务2 读数据A,而后事务1回滚,数据A回复了原来的值,那么事务2对数据A做的事是无效的,读到了脏数据。
数据仓库与数据挖掘🌟🌟
数据仓库技术有四个阶段
- 数据预处理:包括数据抽取、转换、加载
- 建立数据仓库:是处理海量数据的基础
- 数据分析:一般采用
联机分析处理(OLAP)和数据挖掘- 联机分析处理:联机分析处理不仅进行数据汇总/聚集,同时还提供切片、切块、下钻、上卷和旋转等数据分析功能,用户可以方便地对海量数据进行多维分析。
- 数据挖掘的目标则是挖掘数据背后隐藏的知识,通过关联分析、聚类和分类等方法建立分析模型,预测企业末来发展趋势和将要面临的问题;
- 数据展现:在海量数据和分析手段增多的情况下,数据展现则主要保障系统分析结果的可视化。
反规范化技术🌟
反规范化技术:规范化设计后,数据库设计者希望牺牲部分规范化来提高性能。
- 优点:
降低连接操作的需求、降低外码和索引的数目,还可能减少表的数目,能够提高查询效率。 - 缺点:数据的重复存储,浪费了磁盘空问;可能出现数据的完整性问题,为了保障数据的一致性,增加了数据维护的复杂性,会降低修改速度。