说明:
- 面试题来源于网络书籍,公司题目以及博主原创或修改(题目大部分来源于各种公司);
- 文中很多题目,或许大家直接编译器写完,1分钟就出结果了。但在这里博主希望每一个题目,大家都要经过认真思考,答案不重要,重要的是通过题目理解所考知识点,好应对题目更多的变化;
- 博主与大家一起学习,一起刷题,共同进步;
- 写文不易,麻烦给个三连!!!
1.递归函数mystrlen(char *buf, int N)是用来实现统计字符串中第一个空字符前面字符长度
例如:字符串buf,当输入N=10或者20,期待输出结果是6;当输入N=3或5,期待输出结果是3
或5。
char buf[] = {'a', 'b', 'c', 'd', 'e', 'f', '\0', 'x', 'y', 'z'};
答案:
#include <iostream>
using namespace std;
int mystrlen(char *buf, int N)
{
if(buf[0] == 0 || N == 0) // 如果空字符出现,返回0
return 0;
else if(N == 1) // 如果字符长度为1,返回1
return 1;
int t = mystrlen(buf, N/2); // 折半递归取长度
if(t < N/2) // 如果长度小于输入N值的一半,取当前长度
return t;
else // 反之取下面一个祖父并继续递归
return (t + mystrlen(buf + N/2, (N+1)/2));
}
int main()
{
char buf[] = {'a', 'b', 'c', 'd', 'e', 'f', '\0', 'x', 'y', 'z'};
int k;
k = mystrlen(buf, 20);
cout << k << endl;
return 0;
}
2.算法从一个等边三角形开始,在随后的每次迭代中,在外部添加新的三角形。n的前三个值的结果如下图所示。在经过100次迭代之后,会有多少个小三角形?
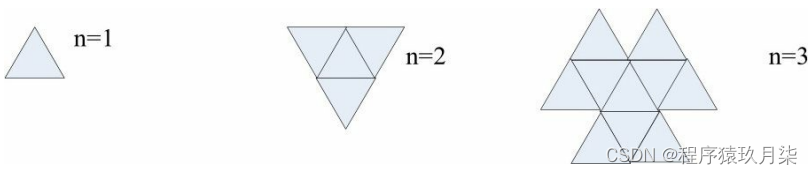
A.19800
B.14501
C.14851
D.14702
解析:
本题规律如下,新增加的小三角形数目为3*(n-1)
f(1)=1;
f(2)=f(1)+3 * (2-1);
f(3)=f(2)+3 * (3-1);
…
f(n)=f (n-1)+3 * (n-1)
答案:C
3.这段代码的输出结果为?
#include <iostream>
#include <string>
using namespace std;
int main()
{
int x = 10, y = 10, i;
for(i=0; x > 8; y=i++)
{
printf("%d %d ", x--, y);
}
return 0;
}
A.10,0,9,1
B.10,10,9,0
C.10,1,9,2
D.9,10,8,0
解析:
for循环括号内被两个分号分为3部分:i=0是初始化变量;x>8是循环条件,也就是只要x>8就执行循环;那y=i++是什么?在第一次循环时执行了么?
答案是不执行,y=i++实际上是个递增条件,仅在第二次循环开始时才执行。
所以结果是10,10,9,0。
答案:B
题目变形:
int main()
{
int x = 10, y = 10, i;
for(i=0; x > 8; )
{
y=i++;
printf("%d %d ", x--, y); // 10 0 9 1
}
return 0;
}
4.有两等长数组A、B,所含元素相同,但顺序不同,只能取得A数组某值和B数组某值进行比较,比较结果为大于、小于或等于,但是不能取得同一数组A或B中的两个数组进行比较,也不能取得某数组中的某个值。写一个算法实现正确匹配
答案:
#include <iostream>
using namespace std;
void matching(int a[], int b[], int k)
{
int i = 0;
while(i <= k-1)
{
int j = 0;
while(j <= k-1)
{
if(a[i] == b[j])
{
cout << "a[" << i << "]" << "match" << "b[" << j << "] " << endl;
break;
}
j++;
}
i++;
}
cout << endl;
}
int main()
{
int a[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int b[10] = {10, 6, 4, 5, 1, 8, 7, 9, 3, 2};
int k = sizeof(a) / sizeof(int);
matching(a, b, k);
return 0;
}
5.介绍一下STL和包容器,如何实现?举例实现vector
答案:
C++的一个新特性就是采用了标准模板库(STL)。所有主要编译器销售商现在都把标准模板库作为编译器的一部分进行提供。标准模板库是一个基于模板的容器类库,包括链表、列表、队列和堆栈。标准模板库还包含许多常用的算法,包括排序和查找。
标准模板库的目的是提供对常用需求重新开发的一种替代方法。标准模板库已经经过测试和调试,具有很高的性能并且是免费的。最重要的是,标准模板库是可重用的。当你知道如何使用一个标准模板库的容器以后,就可以在所有的程序中使用它而不需要重新开发了。
容器是包容其他对象的对象。标准C++库提供了一系列的容器类,它们都是强有力的工具,可以帮助C++开发人员处理一些常见的编程任务。标准模板库容器类有两种类型,分别为顺序和关联。顺序容器可以提供对其成员的顺序访问和随机访问。关联容器则经过优化关键值访问它们的元素。标准模板库在不同操作系统间是可移植的。所有标准模板库容器类都在namespace std中定义。
举例实现vector如下:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
// 创建一个空的 vector
vector<int> vec;
// 检查 vector 是否为空
if (vec.empty()) {
cout << "Vector is empty" << endl;
}
// 添加元素到 vector
vec.push_back(10);
vec.push_back(20);
vec.push_back(30);
// 获取 vector 的大小
cout << "Vector size: " << vec.size() << endl;
// 访问 vector 中的元素
cout << "Elements in vector: ";
for (const auto& element : vec) {
cout << element << " ";
}
cout << endl;
// 修改 vector 中的元素
vec[1] = 50;
// 删除 vector 中的最后一个元素
vec.pop_back();
// 插入元素到指定位置
vec.insert(vec.begin() + 1, 100);
// 删除指定位置的元素
vec.erase(vec.begin() + 2);
// 判断指定元素是否存在于 vector 中
int searchElement = 50;
auto iter = find(vec.begin(), vec.end(), searchElement);
if (iter != vec.end()) {
cout << searchElement << " found in vector" << endl;
} else {
cout << searchElement << " not found in vector" << endl;
}
// 清空 vector
vec.clear();
// 检查 vector 是否为空
if (vec.empty()) {
cout << "Vector is empty" << endl;
}
return 0;
}
6.解释一下什么是泛型编程,泛型编程和C++及STL的关系是什么?并且,你是怎么在C++环境里进行泛型编程的?
答案:
泛型编程是一种编程方式,它允许我们编写可以适用于多种数据类型的代码。通过使用模板技术,泛型编程可以实现高度重用性和通用性,从而提高代码的可维护性和扩展性。
在 C++ 中,泛型编程被广泛应用于标准模板库(STL)中。STL 是 C++ 标准库的一部分,包含了许多常用的容器、算法和迭代器等组件。这些组件都是使用泛型编程技术实现的,因此可以适用于不同的数据类型,从而提高了代码的重用性和可扩展性。
在 C++ 环境中,进行泛型编程需要使用模板技术。C++ 的模板是一种通用的编程机制,它允许我们编写可以适用于多种数据类型的代码。通过使用模板,我们可以将函数或类定义为通用的,从而可以在不同的数据类型上进行操作。
例如,下面是一个简单的模板函数示例,用于比较两个值的大小:
template <typename T>
T max(T a, T b) {
return (a > b) ? a : b;
}
在上述示例中,max 函数使用了模板技术,其中 表示这是一个通用的模板函数,可以适用于不同的数据类型。在函数体中,我们比较了两个值的大小,并返回其中较大的值。
当我们需要使用该函数时,可以将不同类型的参数传递给它,例如:
int a = 10, b = 20;
std::cout << "max(a, b) = " << max(a, b) << std::endl;
double c = 3.14, d = 2.71;
std::cout << "max(c, d) = " << max(c, d) << std::endl;
在上述示例中,我们分别使用了 int 和 double 类型的参数调用了 max 函数,从而实现了泛型编程。
总之,泛型编程是一种强大的编程技术,可以提高代码的重用性和可扩展性。在 C++ 中,STL 是一个优秀的泛型编程库,可以帮助我们更加高效地开发各种应用程序。在进行泛型编程时,需要使用模板技术来实现通用性,从而可以适用于不同的数据类型。
7.下面哪个些关键字与封装相关?
A.virtual
B.void
C.interface
D.private
E.all of the above
解析:
什么是封装?
从字面意思来看,封装就是把一些相关的东西打包成一“坨”。封装最广为人知的例子,就是在面向对象编程里面,把数据和针对该数据的操作,统一到一个class里。
很多人把封装的概念局限于类,认为只有OO中的class才算是封装。这实际上是片面的。在很多不使用“类”的场合,一样能采用封装的手法:
(1)通过文件。
比如C和C++支持对头文件的包含(#include)。因此,可以把一些相关的常量定义、类型定义、函数声明,统统封装到某个头文件中。
(2)通过namespace/package/module。
C++的namespace、Java的package、Python的module,这些语法虽然称呼各不相同,但具有相同的本质。因此,也可以利用这些语法来进行封装。那么封装有一个主要的好处,就是增加软件代码的内聚性。通过增加内聚性,进而提高可复用性和可维护性。此外还可以“信息隐藏”:把不该暴露的信息藏起来。如private、protected之类的关键字。这些关键字可以通过访问控制,来达到信息隐藏的目的。
本题中,interface属于继承,virtual属于多态,private才是与封装相关。
答案:D
8.C++中的空类默认产生哪些类成员函数?
答案:
对于一个空类,编译器默认产生4个成员函数:默认构造函数、析构函数、拷贝构造函数和赋值函数。
9.哪一种成员变量可以在同一个类的实例之间共享?
答案:
在同一个类的实例之间,静态成员变量是可以共享的。静态成员变量属于类本身而不是类的实例,因此它们在类的所有实例之间共享相同的值。
当我们声明一个静态成员变量时,无论创建多少个类的实例,都只有一个静态成员变量的副本存在。这意味着对静态成员变量的修改会影响到所有实例。
以下是一个示例代码,演示了静态成员变量的共享特性:
#include <iostream>
class MyClass {
public:
static int sharedVariable;
};
int MyClass::sharedVariable = 0; // 静态成员变量的定义和初始化
int main() {
MyClass obj1;
MyClass obj2;
obj1.sharedVariable = 10;
std::cout << "obj1.sharedVariable: " << obj1.sharedVariable << std::endl;
std::cout << "obj2.sharedVariable: " << obj2.sharedVariable << std::endl;
obj2.sharedVariable = 20;
std::cout << "obj1.sharedVariable: " << obj1.sharedVariable << std::endl;
std::cout << "obj2.sharedVariable: " << obj2.sharedVariable << std::endl;
return 0;
}
10.这个类声明正确吗?为什么?
class A {
const int Size = 0;
};
答案:
这道程序题存在着成员变量问题。常量必须在构造函数的初始化列表里面初始化或者将其设置成static。
// 方式1
class A {
A() {
const int Size = 0;
}
};
// 方式2
class A {
static const int Size = 0;
};
11.析构函数可以为virtual型,构造函数则不能。那么为什么构造函数不能为虚呢?
答案:
构造函数不能为虚函数的主要原因是在对象创建时,虚函数表还没有被创建。虚函数表是在对象创建后才被创建的,它存储了类的虚函数的地址。因此,在对象创建期间,调用虚函数是不可能的。
在 C++ 中,当我们创建一个对象时,会先分配内存空间,然后调用构造函数来初始化该对象。在构造函数执行期间,对象的虚函数表还没有被创建,因此无法调用虚函数。如果将构造函数声明为虚函数,那么编译器也无法确定应该调用哪个虚函数,因为虚函数表还没有被创建。另外,虚函数的调用需要使用虚函数表,这会带来一定的额外开销。但是,由于构造函数在对象创建时只会被调用一次,因此将构造函数声明为虚函数并不能带来性能上的优势,反而会增加额外的开销。
因此,C++ 标准规定,构造函数不能为虚函数。而析构函数可以为虚函数,因为在对象销毁时,虚函数表仍然存在,可以通过虚函数表来调用析构函数,从而保证正确的析构顺序。
12.析构函数可以是内联函数吗?
答案:
析构函数可以是内联函数。在 C++ 中,我们可以使用 inline 关键字将函数声明为内联函数。
内联函数是一种编译器优化的手段,它的作用是将函数的定义插入到调用它的地方,而不是通过函数调用的方式执行。这样可以减少函数调用的开销,提高程序的执行效率。
对于简单且频繁调用的函数,通常会将其声明为内联函数。析构函数通常是在对象销毁时自动调用的,因此对于小型、简单的类,将析构函数声明为内联函数是合理的
要将析构函数声明为内联函数,只需在类定义中的析构函数声明前加上 inline 关键字即可,例如:
class MyClass {
public:
inline ~MyClass(); // 内联析构函数的声明
};
inline MyClass::~MyClass() {
// 析构函数的定义
// ...
}
需要注意的是,虽然将析构函数声明为内联函数可以提高程序的执行效率,但并不是所有情况下都适合将析构函数声明为内联函数。如果析构函数的实现较为复杂或包含大量代码,那么将其声明为内联函数可能会导致代码膨胀,反而降低了性能。因此,在决定是否将析构函数声明为内联函数时,需要综合考虑函数的复杂性和调用频率。