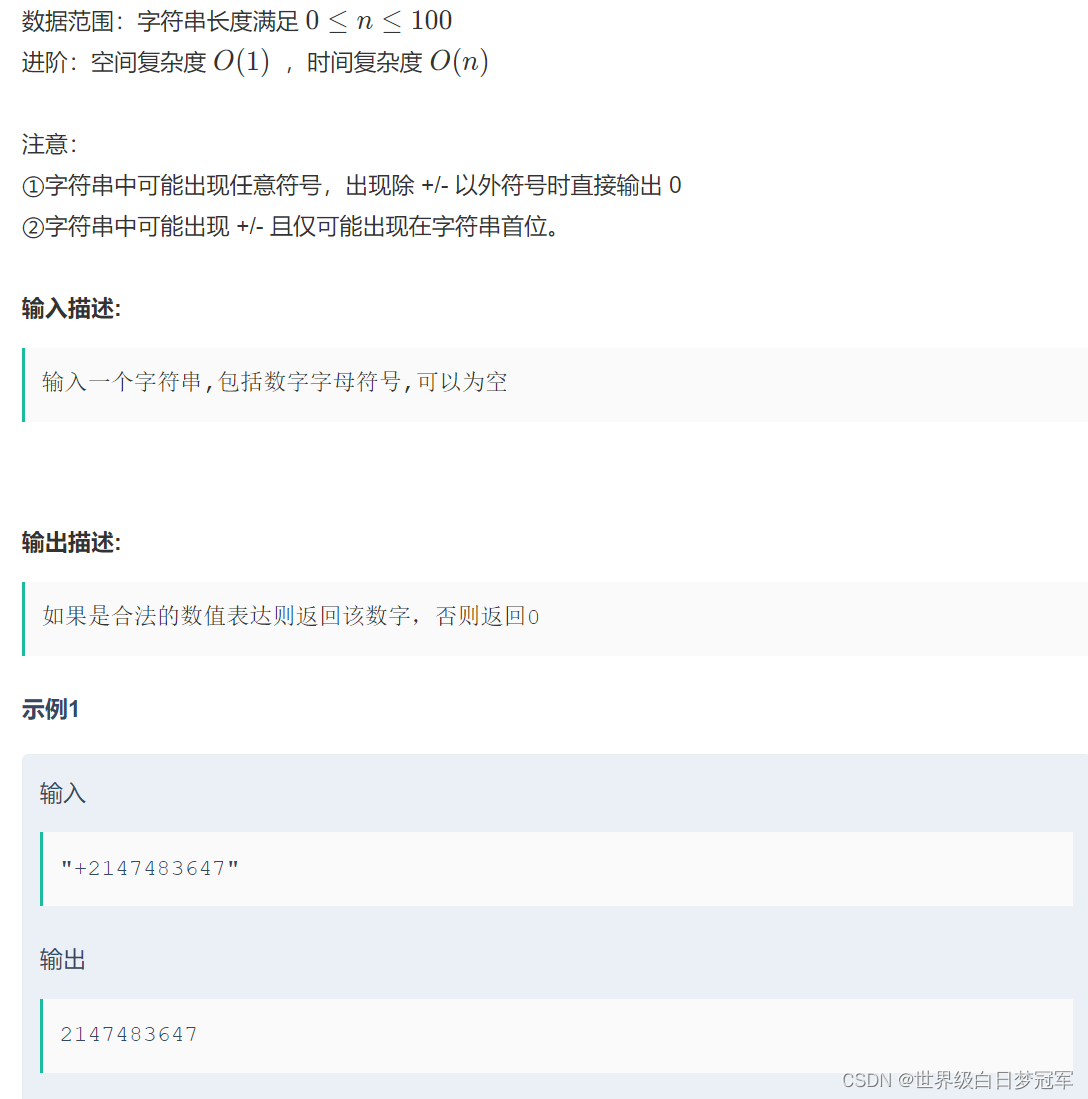
当需要根据已有的时间序列数据,预测未来多个时刻的状态时,被称之为时间序列多步预测。
时间序列多步预测有五种策略,分别为:
1、直接多步预测(Direct Multi-step Forecast)
2、递归多步预测(Recursive Multi-step Forecast)
3、直接递归混合预测(Direct-Recursive Hybrid Forecast)
4、多输出预测(Multiple Output Forecast)
5、seq2seq预测(seq2seq Forecast)
下面进行详细介绍。假设已知的时间序列数据为[1 2 3 4],需要预测紧跟其后的[x y]
1、直接多步预测(Direct Multi-step Forecast)
方法是训练两个模型,其中一个模型用于预测x,另一个模型用于预测y,即:
model1:[1 2 3 4]->[x]
model2:[1 2 3 4]->[y]
缺点主要有两个,第一个为需要为未来的每个状态建立相应的模型,计算负担较大,第二个为无法充分利用时间序列的相关性,即model1的预测结果无法被model2使用。
2、递归多步预测(Recursive Multi-step Forecast)
方法是训练一个固定的模型,按照递归的方法对x与y进行预测,其中的关键是,模型可以使用前一个时间步的预测结果来对下一个时间步进行预测,即:
[1 2 3 4]->[x]
[2 3 4 x]->[y]
优点是利用了时间序列的相关性。
缺点是将预测值作为观测值,会造成误差的累积,当需要预测的时间序列很长时,容易导致性能迅速下降。
3、直接递归混合预测(Direct-Recursive Hybrid Forecast)
该方法综合了直接多步预测和递归多步预测方法的特性。
训练两个模型,其中一个模型用于预测x,另一个模型用于预测y,需要注意的是,第二个模型可以利用第一模型的预测结果。
model1:[1 2 3 4]->[x]
model2:[2 3 4 x]->[y]
4、多输出预测(Multiple Output Forecast)
训练一个固定的模型,该模型的输出有两个值。更具体的来说,就相当于最后的dense层含有两个神经元,每个神经元就是一个值。
[1 2 3 4]->[x y]
优点是后一个时间步的预测和前一个时间步的预测是独立的,不会造成误差的累积。
缺点是,事实上,x和y应该是具有时序关系的,如果完全独立的预测他们的话,会造成信息的损失,引起误差。
5、seq2seq预测(seq2seq Forecast)
方法与多输出预测类似,都是训练一个固定的模型,该模型的输出有两个值。
[1 2 3 4]->[x y]
但是最大的不同是,该方法采用了如下图所示的seq2seq结构。
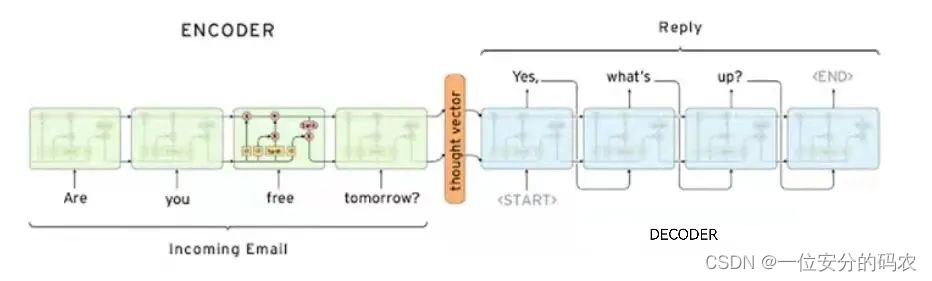
该结构采用了LSTM、attention+seq2seq、transformer、bert等网络结构,因此能够考虑输出的标签之间的序列依赖性,有效利用了预测值之间的时序关系,解决了多输出预测方法的缺陷,有利于提高预测精度。