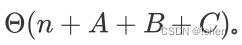有任何的书写错误、排版错误、概念错误等,希望大家包含指正。
由于这部分的参考资料比较少,网上大部分资料重复且不完整,对于一些关键计算没有推导,所以这里我主要讨论几篇论文和讲义。但是这些论文和讲义之间也有些许差别,讨论的过程中我会加入自己的理解,难免存在错误,欢迎大家讨论。
最大熵马尔可夫模型
最大熵马尔可夫模型(maximum-entropy Markov model,MEMM)又称为条件马尔可夫模型(conditional Markov model,CMM)。单纯顾名思义的话,可能会认为最大熵马尔可夫模型是最大熵模型与马尔可夫模型的融合,但其实,它结合了最大熵模型和隐马尔可夫模型(HMM)的共同特点,被广泛应用于序列标注问题。
模型介绍与对比
我们的讨论是以观测与状态是一对一关系为前提,而不考虑多个观测对应一个状态的情况,比如:Yellow River 被认为是一个专有名词,而不是一个形容词和一个名词。
先对比 MEMM 与 HMM。二者的概率图如下。
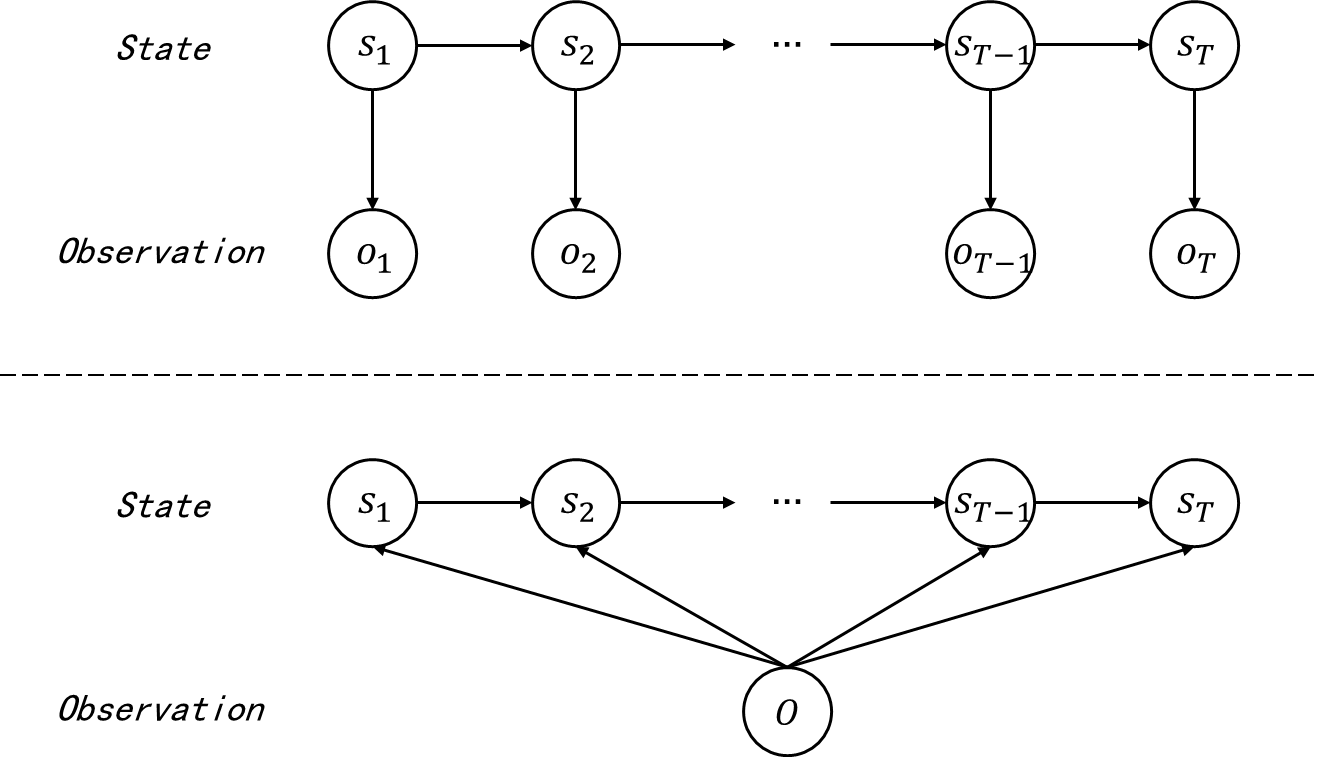
图 1 HMM (上)和满足一阶马尔可夫性质的 MEMM (下)
图 1 1 1 中的中的 MEMM 概率图为满足一阶马尔可夫性质的 MEMM,二阶 MEMM 的概率图只需要在此基础上加上从 s t − 2 s_{t-2} st−2 到 s t s_{t} st 的箭头。
对比 HMM 和 MEMM 的概率图,HMM 认为观测作为输出值与当前时刻的状态有关,而 MEMM 认为当前时刻的状态由之前时刻的状态和全部观测(或者多个时刻的观测值)共同确定,也就是说,在 MEMM 中观测不再独立,甚至作为输入值用于确定每个时刻的状态。这种性质决定了 HMM 是生成式模型,而 MEMM 是判别式模型。生成式模型对概率图表示的联合概率进行建模,再利用联合概率计算后验概率进行解码等操作;判别模型直接对概率图表示的条件概率建模,避免了对联合概率建模,使得解码等操作更加直接。
根据 HMM 的概率图,我们知道 HMM 直接对联合概率
P
(
S
,
O
)
P(S, O)
P(S,O) 建模,即
P
(
S
,
O
)
=
∏
t
=
1
T
P
(
s
t
∣
s
t
−
1
)
P
(
o
t
∣
s
t
)
P(S, O) = \prod_{t=1}^T P(s_t\mid s_{t-1}) P(o_t\mid s_t)
P(S,O)=t=1∏TP(st∣st−1)P(ot∣st)
为了公式简洁、形式统一,不再特殊考虑
t
=
1
t=1
t=1 时的初始概率分布。
根据 MEMM 的概率图,我们对条件概率建模,有
P
(
S
∣
O
)
=
∏
t
=
1
T
P
(
s
t
∣
s
t
−
1
,
O
)
(1)
P(S\mid O) = \prod_{t=1}^T P(s_t\mid s_{t-1}, O) \tag{1}
P(S∣O)=t=1∏TP(st∣st−1,O)(1)
也有部分参考资料会进一步简化模型,将 HMM 概率图中状态到观测的箭头反向后的概率图作为 MEMM 的概率图,这相当于他们认为每个时刻的状态 s t s_t st 不是与整个观测序列 O O O 有关,而是与当前时刻的观测值 o t o_t ot 有关。这会影响模型效果,但不会影响我们的推导和理解。
另外,对于每个时刻的状态,MEMM 考虑的是观测序列和之前时刻的状态,而 HMM 仅考虑之前时刻的状态。在序列标注问题中,将文本上下文包含的信息(特征)作为解码输出状态的判断依据显然更加合理,所以 MEMM 考虑整个观测序列是必然选择。如果将整个观测序列视为输入,那么输入值很可能无法完整枚举,因此需要大量的特征来刻画观测序列。如在文本中识别一个未见的公司名字时,除了传统的单词识别方法以外,还需要用到很多特征信息,如大写字母、结尾词、词性、格式、在文本中的位置等信息。也就是说,我们无法直接使用大量不同的观测序列,故需要提取其中的上下文信息(特征)来代表输入的观测序列。HMM 不适合处理用很多特征描述观测序列的情况,因为 HMM 在建模时不会将整个观测序列视为输入值,也就无法提取充足的特征。为此,MEMM 直接采用条件概率模型,从而使观测序列可以用特征表示,借助最大熵框架进行特征选取。
注意,对于某个时刻状态的解码一般不以整个观测序列作为输入,而是选取该时刻周围若干时刻的观测作为输入。之所以上文以“整个观测序列”进行叙述,其一是为了强调 MEMM 相比于 HMM 更加注重整体、上下文,其二是因为如此叙述会使得语言更加简洁。
对比 MEMM 与最大熵模型。最大熵模型没有考虑时序关系,以观测序列为条件,每个词是单独进行判别的,状态之间的关系无法得到充分利用,但是最大熵模型的优点在于可以使用任意的复杂特征。具有时序关系的 HMM 可以建立状态之间的马尔可夫性,这是最大熵模型所没有的。一个很自然的想法就是将两者的优势结合起来,这就得到了最大熵马尔可夫模型。
最大熵模型是一种特殊的逻辑回归模型(softmax),所以在有些文章中会看到。
学习问题
文献 [1 McCallum et al. ,2000] 与文献 [3 Michael Collins 讲义] 有些许不同,这里分开讨论。
基本假设,可能的状态数为 N N N,所有可能的状态的集合为 Q = { q 1 , q 2 , … , q N } Q = \{q_1,q_2,\dots, q_N\} Q={q1,q2,…,qN}。
先讨论文献 [3]。假设训练集中的样本个数为
D
D
D,样本的序列长度均为
T
T
T,第
d
d
d 个样本的状态序列
S
d
=
(
s
1
(
d
)
,
s
2
(
d
)
,
…
,
s
T
(
d
)
)
S_d=(s^{(d)}_1,s_2^{(d)},\dots, s^{(d)}_T)
Sd=(s1(d),s2(d),…,sT(d)),观测序列为
O
d
=
(
o
1
(
d
)
,
o
2
(
d
)
,
…
,
o
T
(
d
)
)
O_d = (o^{(d)}_1,o^{(d)}_2,\dots, o^{(d)}_T)
Od=(o1(d),o2(d),…,oT(d))。对于第
d
d
d 个样本的每个时刻
t
t
t,可以定义一个三元组
h
t
(
d
)
=
<
S
d
,
O
d
,
t
>
h_t^{(d)} =<\mathcal S_d,\mathcal O_d,t>
ht(d)=<Sd,Od,t>
其中
S
d
\mathcal S_d
Sd 为状态序列
S
d
S_d
Sd 的子集,在文献 [3] 中,由于讨论的是二阶马尔可夫性的 MEMM,所以
S
d
=
{
s
t
−
2
(
d
)
,
s
t
−
1
(
d
)
}
\mathcal S_d = \{s^{(d)}_{t-2},s^{(d)}_{t-1}\}
Sd={st−2(d),st−1(d)};
O
d
\mathcal O_d
Od 为观测序列
O
d
O_d
Od 的子集,在文献 [3] 中
O
d
=
O
d
\mathcal O_d = O_d
Od=Od;
t
t
t 表示序列的位置。可见,
h
t
h_t
ht 捕获
s
t
s_t
st 的条件信息,可以将
h
t
h_t
ht 与 HMM 中的
o
t
o_t
ot 类比理解,只不过在 MEMM 中不再简单地以某个时刻的观测值作为条件,而是以一组信息作为条件。另外,因为本文为了统一,仅讨论一阶 MEMM,故
S
d
=
{
s
t
−
1
(
d
)
}
\mathcal S_d = \{s_{t-1}^{(d)}\}
Sd={st−1(d)};至于
O
d
\mathcal O_d
Od ,在理论推导中是取
O
d
O_d
Od 的真子集还是与之相同都无所谓。
这样一来,特征函数
f
f
f 会将
h
h
h 和
s
s
s 一并考虑,即
f
(
h
,
s
)
=
{
1
,
if
(
h
,
s
)
and
meet
certain
conditions
0
,
otherwise
f (h,s) = \left\{ \begin{array}{ll} 1, & {\textbf {if}} \space\space (h,s) \space\space \textbf{and} \space\space \textbf{meet}\space\space \textbf{certain} \space\space \textbf{conditions}\\ 0, & \textbf{otherwise}\\ \end{array} \right.
f(h,s)={1,0,if (h,s) and meet certain conditionsotherwise
式
(
1
)
(1)
(1) 可以被写为
P
(
S
∣
O
)
=
∏
t
=
1
T
P
(
s
t
∣
h
t
)
(2)
P(S\mid O) = \prod_{t=1}^T P(s_t\mid h_t) \tag{2}
P(S∣O)=t=1∏TP(st∣ht)(2)
根据最大熵模型,其中
P
(
s
t
∣
h
t
)
P(s_t\mid h_t)
P(st∣ht) 可以表示为
P
(
s
t
∣
h
t
;
w
)
=
exp
(
w
⋅
f
(
h
t
,
s
t
)
)
∑
i
=
1
N
exp
(
w
⋅
f
(
h
t
,
s
=
q
i
)
)
(3)
P(s_t\mid h_t;w) = \frac{\exp\left(w·f(h_t,s_t)\right)}{\sum\limits_{i=1}^N\exp\left( w·f(h_t, s=q_i) \right)} \tag{3}
P(st∣ht;w)=i=1∑Nexp(w⋅f(ht,s=qi))exp(w⋅f(ht,st))(3)
其中
w
w
w 和
f
f
f 均为向量,
w
⋅
f
w·f
w⋅f 表示内积运算。
文献 [3] 中直接给出了采用正则化的对数似然函数来学习模型参数
w
w
w,
L
(
w
)
=
log
∏
d
=
1
D
∏
t
=
1
T
P
(
s
t
(
d
)
∣
h
t
(
d
)
;
w
)
−
λ
2
∥
w
∥
2
2
=
∑
d
=
1
D
∑
t
=
1
T
log
P
(
s
t
(
d
)
∣
h
t
(
d
)
;
w
)
−
λ
2
∑
i
=
1
n
w
i
2
\begin{align} L(w) &= \log \prod_{d = 1}^D\prod_{t=1}^T P(s_t^{(d)}\mid h_t^{(d)};w) - \frac{\lambda}{2} \Vert w \Vert_2^2 \notag\\ &= \sum_{d=1}^D\sum_{t=1}^T \log P(s_t^{(d)}\mid h_t^{(d)};w) - \frac{\lambda}{2} \sum_{i=1}^n w_i^2 \tag{4} \end{align}
L(w)=logd=1∏Dt=1∏TP(st(d)∣ht(d);w)−2λ∥w∥22=d=1∑Dt=1∑TlogP(st(d)∣ht(d);w)−2λi=1∑nwi2(4)
将全部样本每个时刻的条件概率之积作为似然函数,同时引入正则化项。加入正则化项主要是考虑到最大似然估计可能会遇到特征函数数量特别大的情况,从而导致个别特征函数只有一个样本符合的极端情形。可以想象到,这些特征函数对应的权重会趋于无穷,所以样本对应的条件概率为
1
1
1,这使得模型对于这些样本不具有很好的泛化能力。举个简单的例子,训练集中满足特征函数
f
1
f_1
f1 的只有样本 Yellow River,训练后的特征函数
f
1
f_1
f1 对应的权重
w
1
w_1
w1 趋于无穷,
P
(
s
t
=
R
i
v
e
r
∣
s
t
−
1
=
Y
e
l
l
o
w
)
=
1
P(s_t = {\rm River} \mid s_{t-1} = {\rm Yellow})=1
P(st=River∣st−1=Yellow)=1,也就是说,训练后的模型只要遇到 Yellow 就一定会将下一个时刻的状态解码为 River,这显然是不合理的,加上正则化项以缓解这类问题。
我认为文献 [3] 中的学习算法,即式 ( 4 ) (4) (4) 有些许不合理,因为无法类似于最大熵模型一样证明对偶函数与对数似然函数等价。
再来讨论我认为比较合理的文献 [1] 提出的学习方案。
该文献提出的方案为,在一阶 MEMM 的前提下,将 < s t − 1 ( d ) , s t ( d ) , O d > <s_{t-1}^{(d)},s_t^{(d)},O_d> <st−1(d),st(d),Od> 视为一个单元,那么对于大小为 D D D,各序列长度均为 T T T 的训练集而言,可以拆分出大约 D × T D\times T D×T 个单元。这些单元相当于特征为 h t ( d ) = < s t − 1 ( d ) , O d , t > h_t^{(d)}=<s_{t-1}^{(d)},O_d,t> ht(d)=<st−1(d),Od,t>,标签为 s t ( d ) s_t^{(d)} st(d) 的新样本,但是为了区别于“样本”,仍然采用“单元”来叙述。为了表示更加简洁,我们为这些单元统一下标,即第 i i i 个单元为 < h i , s i > <h_i, s_i> <hi,si>。
我们总共要训练出 N N N 个最大熵模型, N N N 为上面介绍的可能的状态数。每个单元的三元组 h i h_i hi 中的前一个时刻状态总共有 N N N 种取值,将相同取值的单元划分为同组,总共可以将单元分为 N N N 组,每组单元训练一个最大熵模型,即每组单元对应一个权重向量。这些最大熵模型的训练方法类似,所以这里只讨论其中一组的训练方法。
假设这组单元对应的前一个时刻状态取值均为
s
′
s'
s′,单元个数为
K
s
′
K_{s'}
Ks′,对这组单元重新顺序编号为
1
∼
K
s
′
1\sim K_{s'}
1∼Ks′,那么这些单元对应的
<
h
,
s
>
<h,s>
<h,s> 的下标也对应重新编号为
1
∼
K
s
′
1\sim K_{s'}
1∼Ks′。定义特征函数的经验期望:
E
P
~
(
f
)
=
1
K
s
′
∑
k
=
1
K
s
′
f
(
h
k
,
s
k
)
(5)
E_{\tilde P} (f) = \frac{1}{K_{s'}} \sum_{k=1}^{K_{s'}} f (h_k, s_k) \tag{5}
EP~(f)=Ks′1k=1∑Ks′f(hk,sk)(5)
使用估计的条件概率计算的特征函数的真实期望:
E
P
(
f
)
=
1
K
s
′
∑
k
=
1
K
s
′
∑
i
=
1
N
P
(
s
=
q
i
∣
s
′
,
h
k
)
f
(
h
k
,
s
=
q
i
)
=
1
K
s
′
∑
k
=
1
K
s
′
∑
i
=
1
N
P
s
′
(
s
=
q
i
∣
h
k
)
f
(
h
k
,
s
=
q
i
)
(6)
\begin{align} E_P(f) &= \frac{1}{K_{s'}} \sum_{k=1}^{K_{s'}} \sum_{i = 1}^N P(s = q_i\mid s', h_k) f(h_k, s=q_i) \\ &= \frac{1}{K_{s'}} \sum_{k=1}^{K_{s'}} \sum_{i = 1}^N P_{s'}(s = q_i\mid h_k) f(h_k, s=q_i) \\ \end{align} \tag{6}
EP(f)=Ks′1k=1∑Ks′i=1∑NP(s=qi∣s′,hk)f(hk,s=qi)=Ks′1k=1∑Ks′i=1∑NPs′(s=qi∣hk)f(hk,s=qi)(6)
最大熵模型对应优化问题的约束条件(之一)为
E
P
~
(
f
i
)
=
E
P
(
f
)
,
i
=
1
,
2
,
…
,
n
E_{\tilde P}(f_i) = E_P(f),\space\space\space\space i = 1,2,\dots, n
EP~(fi)=EP(f), i=1,2,…,n
其中
n
n
n 为特征函数个数。最大熵模型的学习转化为约束最优化问题,优化问题对应的目标函数为
max
P
s
′
H
(
P
s
′
)
=
−
∑
k
=
1
K
s
′
∑
i
=
1
N
P
s
′
(
h
k
)
P
s
′
(
s
=
q
i
∣
h
k
)
log
P
s
′
(
s
=
q
i
∣
h
k
)
\max_{P_{s'}} \space \space\space\space H(P_{s'}) = -\sum_{k=1}^{K_{s'}} \sum_{i=1}^N P_{s'}(h_k)P_{s'}(s=q_i\mid h_k) \log P_{s'}(s=q_i\mid h_k)
Ps′max H(Ps′)=−k=1∑Ks′i=1∑NPs′(hk)Ps′(s=qi∣hk)logPs′(s=qi∣hk)
由于枚举的单元都是被观察到的单元,所以
P
s
′
(
h
k
)
=
1
P_{s'}(h_k)=1
Ps′(hk)=1。故,完整的约束优化问题为
max
P
s
′
H
(
P
s
′
)
=
−
∑
k
=
1
K
s
′
∑
i
=
1
N
P
s
′
(
s
=
q
i
∣
h
k
)
log
P
s
′
(
s
=
q
i
∣
h
k
)
s
.
t
.
K
s
′
E
P
(
f
i
)
=
K
s
′
E
P
~
(
f
i
)
,
i
=
1
,
2
,
…
,
n
∑
k
=
1
K
s
′
∑
i
=
1
N
P
s
′
(
s
=
q
i
∣
h
k
)
=
K
s
′
\begin{array}{l} \max\limits_{P_{s'}} & H(P_{s'}) = -\sum\limits_{k=1}^{K_{s'}} \sum\limits_{i=1}^NP_{s'}(s=q_i\mid h_k) \log P_{s'}(s=q_i\mid h_k) \\ s.t. & K_{s'}E_P(f_i) = K_{s'}E_{\tilde P} (f_i),\space\space\space\space i=1,2,\dots, n \\ & \sum\limits_{k=1}^{K_{s'}} \sum\limits_{i=1}^N P_{s'}(s=q_i\mid h_k) = K_{s'} \end{array}
Ps′maxs.t.H(Ps′)=−k=1∑Ks′i=1∑NPs′(s=qi∣hk)logPs′(s=qi∣hk)Ks′EP(fi)=Ks′EP~(fi), i=1,2,…,nk=1∑Ks′i=1∑NPs′(s=qi∣hk)=Ks′
转换为最小化问题后对应的拉格朗日函数为
L
(
P
s
′
,
w
)
=
−
H
(
P
s
′
)
+
w
0
(
K
s
′
−
∑
k
=
1
K
s
′
∑
i
=
1
N
P
s
′
(
s
=
q
i
∣
h
k
)
)
+
K
s
′
∑
i
=
1
n
w
i
(
E
P
~
(
f
i
)
−
E
P
(
f
i
)
)
=
∑
k
=
1
K
s
′
∑
i
=
1
N
P
s
′
(
s
=
q
i
∣
h
k
)
log
P
s
′
(
s
=
q
i
∣
h
k
)
+
w
0
(
K
s
′
−
∑
k
=
1
K
s
′
∑
i
=
1
N
P
s
′
(
s
=
q
i
∣
h
k
)
)
+
∑
i
=
1
n
w
i
∑
k
=
1
K
s
′
(
f
i
(
h
k
,
s
k
)
−
∑
i
=
1
N
P
s
′
(
s
=
q
i
∣
h
k
)
f
i
(
h
k
,
s
=
q
i
)
)
\begin{align} L(P_{s'},w) &= -H(P_{s'})+ w_0 \Big(K_{s'} - \sum_{k=1}^{K_{s'}}\sum_{i=1}^N P_{s'} (s=q_i\mid h_k)\Big) + K_{s'}\sum_{i=1}^n w_i\big( E_{\tilde P}(f_i) - E_{P}(f_i) \big) \notag\\ &= \sum\limits_{k=1}^{K_{s'}} \sum\limits_{i=1}^N P_{s'}(s=q_i\mid h_k) \log P_{s'}(s=q_i\mid h_k) + w_0 \Big(K_{s'} - \sum_{k=1}^{K_{s'}}\sum_{i=1}^N P_{s'} (s=q_i\mid h_k)\Big) + \sum_{i=1}^n w_i\sum_{k=1}^{K_{s'}}\Big( f_i(h_k, s_k) - \sum_{i=1}^N P_{s'}(s=q_i\mid h_k)f_i(h_k, s=q_i) \Big) \notag \\ \end{align}
L(Ps′,w)=−H(Ps′)+w0(Ks′−k=1∑Ks′i=1∑NPs′(s=qi∣hk))+Ks′i=1∑nwi(EP~(fi)−EP(fi))=k=1∑Ks′i=1∑NPs′(s=qi∣hk)logPs′(s=qi∣hk)+w0(Ks′−k=1∑Ks′i=1∑NPs′(s=qi∣hk))+i=1∑nwik=1∑Ks′(fi(hk,sk)−i=1∑NPs′(s=qi∣hk)fi(hk,s=qi))
拉格朗日函数对
P
s
′
(
s
∣
h
)
P_{s'}(s\mid h)
Ps′(s∣h) 求偏导,其中
s
s
s 和
h
h
h 均为确切取值,假设这
K
s
′
K_{s'}
Ks′ 个单元中为
<
h
,
s
>
<h,s>
<h,s> 的单元个数为
K
K
K,则
∂
L
∂
P
s
′
(
s
∣
h
)
=
K
(
log
P
s
′
(
s
∣
h
)
+
1
)
−
K
w
0
−
K
∑
i
=
1
N
w
i
f
i
(
h
,
s
)
\frac{\partial L}{\partial P_{s'}(s\mid h)} = K\big(\log P_{s'}(s\mid h)+1\big) - Kw_0 - K\sum_{i=1}^N w_if_i(h, s)
∂Ps′(s∣h)∂L=K(logPs′(s∣h)+1)−Kw0−Ki=1∑Nwifi(h,s)
令偏导为零,利用
∑
i
=
1
N
P
s
′
(
s
=
q
i
∣
h
)
\sum\limits_{i=1}^N P_{s'}(s=q_i\mid h)
i=1∑NPs′(s=qi∣h) 可得最大熵模型
P
s
′
(
s
∣
h
)
=
exp
(
w
⋅
f
(
h
,
s
)
)
Z
(
h
,
s
′
)
(7)
P_{s'}(s\mid h) = \frac{\exp\big( w·f(h, s) \big)}{Z(h,s')} \tag{7}
Ps′(s∣h)=Z(h,s′)exp(w⋅f(h,s))(7)
其中
Z
(
h
,
s
′
)
=
∑
i
=
1
N
exp
(
w
⋅
f
(
h
,
s
=
q
i
)
)
Z(h, s') = \sum\limits_{i=1}^N\exp\big( w·f(h, s=q_i) \big)
Z(h,s′)=i=1∑Nexp(w⋅f(h,s=qi))
其中
w
⋅
f
w·f
w⋅f 为向量内积。
将式
(
7
)
(7)
(7) 代入拉格朗提函数得到对偶函数
ψ
(
w
)
=
∑
k
=
1
K
s
′
∑
i
=
1
N
P
s
′
(
s
=
q
i
∣
h
k
)
log
P
s
′
(
s
=
q
i
∣
h
k
)
+
∑
i
=
1
n
w
i
∑
k
=
1
K
s
′
(
f
i
(
h
k
,
s
k
)
−
∑
i
=
1
N
P
s
′
(
s
=
q
i
∣
h
k
)
f
i
(
h
k
,
s
=
q
i
)
)
=
∑
k
=
1
K
s
′
∑
i
=
1
N
P
s
′
(
s
=
q
i
∣
h
k
)
log
P
s
′
(
s
=
q
i
∣
h
k
)
+
∑
k
=
1
K
s
′
∑
i
=
1
n
w
i
f
i
(
h
k
,
s
k
)
−
∑
k
=
1
K
s
′
∑
i
=
1
N
P
s
′
(
s
=
q
i
∣
h
k
)
∑
i
=
1
n
w
i
f
i
(
h
k
,
s
=
q
i
)
=
∑
k
=
1
K
s
′
∑
i
=
1
n
w
i
f
i
(
h
k
,
s
k
)
+
∑
k
=
1
K
s
′
∑
i
=
1
N
P
s
′
(
s
=
q
i
∣
h
k
)
log
P
s
′
(
s
=
q
i
∣
h
k
)
−
∑
k
=
1
K
s
′
∑
i
=
1
N
P
s
′
(
s
=
q
i
∣
h
k
)
∑
i
=
1
n
w
i
f
i
(
h
k
,
s
=
q
i
)
=
∑
k
=
1
K
s
′
∑
i
=
1
n
w
i
f
i
(
h
k
,
s
k
)
+
∑
k
=
1
K
s
′
∑
i
=
1
N
P
s
′
(
s
=
q
i
∣
h
k
)
(
log
P
s
′
(
s
=
q
i
∣
h
k
)
−
∑
i
=
1
n
w
i
f
i
(
h
k
,
s
=
q
i
)
)
=
∑
k
=
1
K
s
′
∑
i
=
1
n
w
i
f
i
(
h
k
,
s
k
)
−
∑
k
=
1
K
s
′
∑
i
=
1
N
P
s
′
(
s
=
q
i
∣
h
k
)
log
Z
(
h
k
,
s
′
)
=
∑
k
=
1
K
s
′
∑
i
=
1
n
w
i
f
i
(
h
k
,
s
k
)
−
∑
k
=
1
K
s
′
log
Z
(
h
k
,
s
′
)
∑
i
=
1
N
P
s
′
(
s
=
q
i
∣
h
k
)
=
∑
k
=
1
K
s
′
∑
i
=
1
n
w
i
f
i
(
h
k
,
s
k
)
−
∑
k
=
1
K
s
′
log
Z
(
h
k
,
s
′
)
\begin{align} \psi(w) &= \sum\limits_{k=1}^{K_{s'}} \sum\limits_{i=1}^N P_{s'}(s=q_i\mid h_k) \log P_{s'}(s=q_i\mid h_k) + \sum_{i=1}^n w_i\sum_{k=1}^{K_{s'}}\Big( f_i(h_k, s_k) - \sum_{i=1}^N P_{s'}(s=q_i\mid h_k)f_i(h_k, s=q_i) \Big) \notag \\ &= \sum_{k=1}^{K_{s'}} \sum_{i=1}^N P_{s'} (s=q_i \mid h_k) \log P_{s'} (s = q_i\mid h_k) + \sum_{k=1}^{K_{s'}}\sum_{i=1}^n w_i f_i(h_k,s_k) - \sum_{k=1}^{K_{s'}}\sum_{i=1}^NP_{s'}(s = q_i\mid h_k) \sum_{i=1}^n w_i f_i(h_k, s=q_i) \notag \\ &= \sum_{k=1}^{K_{s'}}\sum_{i=1}^n w_i f_i(h_k,s_k) + \sum_{k=1}^{K_{s'}} \sum_{i=1}^N P_{s'} (s=q_i \mid h_k) \log P_{s'} (s = q_i\mid h_k) - \sum_{k=1}^{K_{s'}}\sum_{i=1}^NP_{s'}(s = q_i\mid h_k) \sum_{i=1}^n w_i f_i(h_k, s=q_i) \notag\\ &= \sum_{k=1}^{K_{s'}}\sum_{i=1}^n w_i f_i(h_k,s_k) + \sum_{k=1}^{K_{s'}} \sum_{i=1}^N P_{s'} (s=q_i \mid h_k) \Big(\log P_{s'} (s = q_i\mid h_k) - \sum_{i=1}^n w_i f_i(h_k, s=q_i) \Big) \notag\\ &= \sum_{k=1}^{K_{s'}}\sum_{i=1}^n w_i f_i(h_k,s_k) - \sum_{k=1}^{K_{s'}} \sum_{i=1}^N P_{s'} (s=q_i \mid h_k) \log Z(h_k, s')\notag\\ &= \sum_{k=1}^{K_{s'}}\sum_{i=1}^n w_i f_i(h_k,s_k) - \sum_{k=1}^{K_{s'}} \log Z(h_k, s')\sum_{i=1}^N P_{s'}(s=q_i\mid h_k) \notag\\ &= \sum_{k=1}^{K_{s'}}\sum_{i=1}^n w_i f_i(h_k,s_k) - \sum_{k=1}^{K_{s'}} \log Z(h_k, s') \notag\\ \end{align}
ψ(w)=k=1∑Ks′i=1∑NPs′(s=qi∣hk)logPs′(s=qi∣hk)+i=1∑nwik=1∑Ks′(fi(hk,sk)−i=1∑NPs′(s=qi∣hk)fi(hk,s=qi))=k=1∑Ks′i=1∑NPs′(s=qi∣hk)logPs′(s=qi∣hk)+k=1∑Ks′i=1∑nwifi(hk,sk)−k=1∑Ks′i=1∑NPs′(s=qi∣hk)i=1∑nwifi(hk,s=qi)=k=1∑Ks′i=1∑nwifi(hk,sk)+k=1∑Ks′i=1∑NPs′(s=qi∣hk)logPs′(s=qi∣hk)−k=1∑Ks′i=1∑NPs′(s=qi∣hk)i=1∑nwifi(hk,s=qi)=k=1∑Ks′i=1∑nwifi(hk,sk)+k=1∑Ks′i=1∑NPs′(s=qi∣hk)(logPs′(s=qi∣hk)−i=1∑nwifi(hk,s=qi))=k=1∑Ks′i=1∑nwifi(hk,sk)−k=1∑Ks′i=1∑NPs′(s=qi∣hk)logZ(hk,s′)=k=1∑Ks′i=1∑nwifi(hk,sk)−k=1∑Ks′logZ(hk,s′)i=1∑NPs′(s=qi∣hk)=k=1∑Ks′i=1∑nwifi(hk,sk)−k=1∑Ks′logZ(hk,s′)
这里的最大熵模型同样满足对偶函数与对数似然函数等价。对数似然函数为
L
(
w
)
=
log
∏
k
=
1
K
s
′
P
s
′
(
s
k
∣
h
k
)
=
∑
k
=
1
K
s
′
log
P
s
′
(
s
k
∣
h
k
)
=
∑
k
=
1
K
s
′
(
∑
i
=
1
n
w
i
f
i
(
h
k
,
s
k
)
−
log
Z
(
h
k
,
s
′
)
)
=
∑
k
=
1
K
s
′
∑
i
=
1
n
w
i
f
i
(
h
k
,
s
k
)
−
∑
k
=
1
K
s
′
log
Z
(
h
k
,
s
′
)
\begin{align} L(w) &= \log \prod_{k=1}^{K_{s'}} P_{s'} (s_k \mid h_k)\notag \\ &= \sum_{k=1}^{K_{s'}} \log P_{s'} (s_k\mid h_k) \notag\\ &= \sum_{k=1}^{K_{s'}} \left( \sum_{i=1}^n w_if_i(h_k,s_k) - \log Z(h_k, s') \right) \notag\\ &= \sum_{k=1}^{K_{s'}}\sum_{i=1}^n w_i f_i(h_k,s_k) - \sum_{k=1}^{K_{s'}} \log Z(h_k, s')\notag \\ \end{align}
L(w)=logk=1∏Ks′Ps′(sk∣hk)=k=1∑Ks′logPs′(sk∣hk)=k=1∑Ks′(i=1∑nwifi(hk,sk)−logZ(hk,s′))=k=1∑Ks′i=1∑nwifi(hk,sk)−k=1∑Ks′logZ(hk,s′)
可见,对数似然函数与对偶函数相同。
极大化 ψ ( w ) \psi(w) ψ(w) 可以采用最大熵模型中提到的最优化算法,比如通用迭代尺度法(GIS)、改进的迭代尺度法(IIS)等。文献 [3] 中介绍到,对每组单元对应的 ψ ( w ) \psi(w) ψ(w) 分别采用 GIS 进行迭代,最终得到 N N N 组权重向量,对应 N N N 个最大熵模型,这 N N N 个最大熵模型完整地描述了概率分布 P ( s ∣ s ′ , h ) P(s\mid s', h) P(s∣s′,h)。
可以想象,如果满足二阶马尔可夫性,那么就需要训练 N × N N\times N N×N 个最大熵模型来描述概率分布 P ( s ∣ s ′ , s ′ ′ , h ) P(s\mid s', s'', h) P(s∣s′,s′′,h),具体过程与上面类似。
对比两个文献提出的学习方法,文献 [1] 的观点更能让我信服,而且可以通过比较合理的推导进行证明。
这部分推导属于我自己研究的,正确性无法保证,仅供参考。
解码问题
Daniel Jurafsky 在《Speech and Language Processing》中提到,MEMM 的解码也可以采用类似于 HMM 中近似算法的贪心思想。使用这种方式解码,需要对输入观测序列从头到尾运行分类器,每次分类都作出当前最好的决定。算法流程大致描述为,从头到尾扫描整个观测序列,对于每个时刻,根据前一个时刻我们的解码得到的状态选择当前时刻对应的最大熵模型学习到的条件概率分布来确定当前时刻的解码状态,依次类推。特别地,第一个时刻的解码状态可以仅依赖于观测。
至于 Viterbi 算法也是与 HMM 一致。定义
δ
t
(
i
)
=
max
s
1
,
s
2
,
…
,
s
t
−
1
P
(
O
,
s
t
=
q
i
,
s
t
−
1
,
…
,
s
1
∣
w
)
,
1
≤
i
≤
N
\delta_t(i) = \max _{s_1,s_2,\dots, s_{t-1}} P(O,s_{t}=q_i,s_{t-1},\dots, s_1\mid w),\space\space\space\space 1\le i\le N
δt(i)=s1,s2,…,st−1maxP(O,st=qi,st−1,…,s1∣w), 1≤i≤N
其中
P
P
P 是
P
s
′
P_{s'}
Ps′ 的简写。对式
(
1
)
(1)
(1) 变形可得
δ
t
(
i
)
=
max
s
1
,
s
2
,
…
,
s
t
−
1
P
(
s
t
=
q
i
∣
s
t
−
1
,
…
,
s
1
,
O
,
w
)
P
(
s
t
−
1
,
…
,
s
1
,
O
∣
w
)
=
max
1
≤
j
≤
N
P
(
s
t
=
q
i
∣
h
t
,
w
)
δ
t
−
1
(
j
)
=
max
1
≤
j
≤
N
[
δ
t
−
1
(
j
)
]
P
(
s
t
=
q
i
∣
h
t
,
w
)
\begin{align} \delta_t(i) &= \max_{s_1, s_2,\dots, s_{t-1}} P(s_t=q_i\mid s_{t-1},\dots, s_1, O, w) P(s_{t-1},\dots, s_1, O \mid w) \notag\\ &= \max_{1\le j \le N} P(s_t=q_i \mid h_t, w) \delta_{t-1}(j) \notag\\ &= \max_{1\le j \le N} [\delta_{t-1}(j)]P(s_t=q_i \mid h_t, w) \notag\\ \end{align}
δt(i)=s1,s2,…,st−1maxP(st=qi∣st−1,…,s1,O,w)P(st−1,…,s1,O∣w)=1≤j≤NmaxP(st=qi∣ht,w)δt−1(j)=1≤j≤Nmax[δt−1(j)]P(st=qi∣ht,w)
如果考虑一阶马尔可夫性,那么其中
h
t
=
<
s
t
−
1
,
O
,
t
>
h_t=< s_{t-1},O, t>
ht=<st−1,O,t>。初始化
δ
1
(
i
)
=
P
(
s
1
=
q
i
∣
h
1
,
w
)
\delta_1(i) = P(s_1 = q_i\mid h_1, w)
δ1(i)=P(s1=qi∣h1,w)
其中
h
1
=
<
O
,
1
>
h_1 = <O, 1>
h1=<O,1>。
定义在时刻
t
t
t 状态为
q
i
q_i
qi 的所有单个路径
(
s
1
,
s
2
,
…
,
s
t
−
1
,
s
t
=
q
i
)
(s_1,s_2,\dots ,s_{t-1},s_t=q_i)
(s1,s2,…,st−1,st=qi) 中概率最大的路径的第
t
−
1
t - 1
t−1 个结点为
ψ
t
(
i
)
=
a
r
g
max
1
≤
j
≤
N
[
δ
t
−
1
(
j
)
]
,
,
1
≤
i
≤
N
\psi_t(i) = {\rm arg} \max_{1\le j \le N} [\delta_{t-1}(j)],\space\space\space\space,1\le i \le N
ψt(i)=arg1≤j≤Nmax[δt−1(j)], ,1≤i≤N
ψ
t
(
i
)
\psi_t(i)
ψt(i) 保存的是时刻
t
t
t 状态
s
t
=
q
i
s_t=q_i
st=qi 由时刻
t
−
1
t-1
t−1 的哪种状态转移而来。初始化
ψ
1
(
i
)
=
0
\psi_1(i) = 0
ψ1(i)=0
终止
P
∗
=
max
1
≤
i
≤
N
δ
T
(
i
)
s
T
∗
=
a
r
g
max
1
≤
i
≤
N
[
δ
T
(
i
)
]
P^* = \max_{1\le i \le N}\delta_T(i) \\ s_T^* = {\rm arg}\max \limits_{1\le i\le N} [\delta_T(i)]
P∗=1≤i≤NmaxδT(i)sT∗=arg1≤i≤Nmax[δT(i)]
路径回溯,只需要根据
s
t
∗
=
ψ
t
+
1
(
s
t
+
1
∗
)
s_t^* = \psi_{t+1}(s_{t+1}^*)
st∗=ψt+1(st+1∗) 逆序递推即可得到最优路径
S
∗
=
(
s
1
∗
,
s
2
∗
,
…
,
s
T
∗
)
S^*=(s_1^*,s_2^*,\dots, s_T^*)
S∗=(s1∗,s2∗,…,sT∗)。
关于“双向 MEMM”、“MEMM 的缺点”等扩展问题在这里不展开,可以见其他文章。
REF
[1] McCallum A, Freitag D, Pereira F C N. Maximum entropy Markov models for information extraction and segmentation[C]//Icml. 2000, 17(2000): 591-598.
[2] Ratnaparkhi A. A maximum entropy model for part-of-speech tagging[C]//Conference on empirical methods in natural language processing. 1996.
[3] fall2014-loglineartaggers.pdf (columbia.edu)
[4] Collins M. Log-linear models[J]. Self-published Tutorial, 2005.
[5] Collins M. Log-linear models, memms, and crfs[J]. Columbia University lecture, 2015.
[6] Lafferty J, McCallum A, Pereira F C N. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[J]. 2001.
[7] Wang H, Fei H, Yu Q, et al. A motifs-based Maximum Entropy Markov Model for realtime reliability prediction in System of Systems[J]. Journal of Systems and Software, 2019, 151: 180-193.
[8]《Speech and Language Processing》Daniel Jurafsky 等著
[9]《百面机器学习》诸葛越等著
[10] 【机器学习】最大熵模型【上】最大熵模型概述与约束最优化问题 - CSDN
[11] 【机器学习】最大熵模型【下】最大熵模型学习的最优化算法 - CSDN
[12] 【自然语言处理】隐马尔可夫模型【Ⅴ】解码问题 - CSDN
[13] (【自然语言处理】隐马尔可夫模型【Ⅱ】隐马尔科夫模型概述 - CSDN