AI视野·今日CS.Sound 声学论文速览
Fri, 20 Oct 2023
Totally 7 papers
👉上期速览✈更多精彩请移步主页

Interesting:
📚Loop Copilot,基于对话模型的作曲助理 (from 伦敦大学玛丽女王学院)
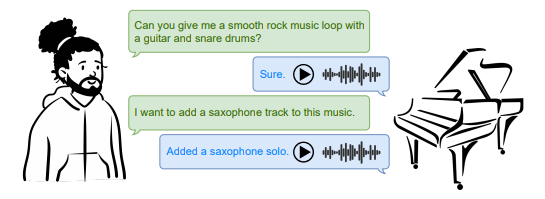
website:https://sites.google.com/view/loop-copilot
Daily Sound Papers
| Uncertainty Quantification of Bandgaps in Acoustic Metamaterials with Stochastic Geometric Defects and Material Properties Authors Han Zhang, Rayehe Karimi Mahabadi, Cynthia Rudin, Johann Guilleminot, L. Catherine Brinson 本文研究了不确定性量化技术(即谱投影和多项式混沌展开)的实用性,以减少在给定随机材料特性和几何缺陷的情况下表征声学超材料色散带响应的采样需求。在输入空间概率分布的形成中展示了一种以可解释的、与分辨率无关的方式编码几何缺陷的新方法。 |
| Audio Editing with Non-Rigid Text Prompts Authors Francesco Paissan, Zhepei Wang, Mirco Ravanelli, Paris Smaragdis, Cem Subakan 在本文中,我们探讨了非刚性文本编辑的音频编辑。我们表明,所提出的编辑管道能够创建忠实于输入音频的音频编辑。我们探索执行加法、风格转换和绘画的文本提示。我们定量和定性地表明,这些编辑能够获得优于 Audio LDM(最近发布的文本提示音频生成模型)的结果。 |
| EmoDiarize: Speaker Diarization and Emotion Identification from Speech Signals using Convolutional Neural Networks Authors Hanan Hamza, Fiza Gafoor, Fathima Sithara, Gayathri Anil, V. S. Anoop 在先进人工智能和人机交互的时代,识别口语中的情感至关重要。这项研究探索了深度学习技术在语音情感识别中的集成,为与说话人分类和情感识别相关的挑战提供了全面的解决方案。它引入了一个框架,该框架结合了现有的说话人二值化管道和基于卷积神经网络 CNN 构建的情绪识别模型,以实现更高的精度。所提出的模型使用来自五个语音情感数据集的数据进行训练,即 RAVDESS、CREMA D、SAVEE、TESS 和 Movie Clips,其中后者是专门为本研究创建的语音情感数据集。从每个样本中提取的特征包括梅尔频率倒谱系数 MFCC 、过零率 ZCR 、均方根 RMS 以及各种数据增强算法,例如音调、噪声、拉伸和移位。这种特征提取方法旨在提高预测精度,同时降低计算复杂度。 |
| Energy-Based Models For Speech Synthesis Authors Wanli Sun, Zehai Tu, Anton Ragni 最近,人们对用于语音合成的非自回归非 AR 模型产生了很大的兴趣,例如 FastSpeech 2 和扩散模型。与 AR 模型不同,这些模型的输出之间不存在自回归依赖性,这使得推理更加高效。本文通过另一个称为基于能量的模型 EBM 的成员扩展了可用的非 AR 模型的范围。该论文描述了如何使用噪声对比估计(依赖于正样本和负样本之间的比较)来训练 EBM。它提出了多种生成有效负样本的策略,包括使用高性能 AR 模型。它还描述了如何使用 Langevin Markov Chain Monte Carlo MCMC 执行 EBM 采样。 Langevin MCMC 的使用能够在 EBM 和当前流行的扩散模型之间建立联系。 |
| Loop Copilot: Conducting AI Ensembles for Music Generation and Iterative Editing Authors Yixiao Zhang, Akira Maezawa, Gus Xia, Kazuhiko Yamamoto, Simon Dixon 创作音乐是迭代的,每个阶段都需要不同的方法。然而,现有的人工智能音乐系统在协调多个子系统以满足不同需求方面存在不足。为了解决这一差距,我们推出了 Loop Copilot,这是一种新颖的系统,使用户能够通过交互式多轮对话界面生成并迭代地完善音乐。该系统使用大型语言模型来解释用户意图并选择合适的AI模型来执行任务。每个后端模型专门用于特定任务,并且它们的输出被聚合以满足用户的要求。为了确保音乐的连贯性,基本属性都保存在一个集中的表中。 |
| The CHiME-7 Challenge: System Description and Performance of NeMo Team's DASR System Authors Tae Jin Park, He Huang, Ante Jukic, Kunal Dhawan, Krishna C. Puvvada, Nithin Koluguri, Nikolay Karpov, Aleksandr Laptev, Jagadeesh Balam, Boris Ginsburg 我们在第七届 CHiME 挑战赛远程自动语音识别 DASR 任务中展示 NVIDIA NeMo 团队的多通道语音识别系统,重点开发多通道、多说话人语音识别系统,专门用于转录分布式麦克风和麦克风阵列的语音。该系统主要由以下几个集成模块组成:扬声器分类模块、多通道音频前端处理模块和ASR模块。这些组件共同建立了一个级联系统,精心处理多通道和多扬声器音频输入。此外,本文还重点介绍了显着提高我们系统性能的综合优化过程。 |
| Property-Aware Multi-Speaker Data Simulation: A Probabilistic Modelling Technique for Synthetic Data Generation Authors Tae Jin Park, He Huang, Coleman Hooper, Nithin Koluguri, Kunal Dhawan, Ante Jukic, Jagadeesh Balam, Boris Ginsburg 我们引入了一个复杂的多扬声器语音数据模拟器,专门用于生成多扬声器语音录音。该模拟器的一个显着特点是它能够通过调整统计参数来调节静音和重叠的分布。此功能提供了定制的训练环境,用于开发适合说话者分类和语音活动检测的神经模型。获取用于说话人分类的大量数据集通常会带来重大挑战,特别是在多说话人场景中。此外,语音数据的精确时间戳注释是训练说话人分类和语音活动检测的关键因素。我们提出的多扬声器模拟器通过生成大规模音频混合物来解决这些问题,该混合物保持与输入参数紧密一致的统计属性。我们证明了所提出的多扬声器模拟器生成的音频混合物具有与现实世界统计数据得出的输入参数密切相关的统计属性。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com