Selenium是一个自动化测试框架,主要用于Web应用程序的自动化测试。它可以模拟用户在浏览器中的操作,如打开网页、点击链接、填写表单等,并且可以在代码中实现条件判断、异常处理等功能。Selenium最初是用于测试Web应用程序的,但也可以用于其他用途,如爬取网站数据、自动化提交表单等。Selenium支持多种编程语言,如Java、Python、C#等,同时也支持多种浏览器,如Chrome、Firefox、Safari等。
该工具在使用时需要安装两个模块,首先读者需要自行安装selenium包,并且需下载与对应浏览器匹配的驱动程序。
- 安装PIP包:pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple
- 安装驱动程序:https://chromedriver.storage.googleapis.com/index.html
我们以Google浏览器为例,此处本人的版本为112.0.5615.121(32 位)根据该版本下载对应的驱动程序,并将驱动程序放入到Google浏览器根目录下,如下图所示,此时的驱动就已经安装成功了;
21.9.1 模拟打开页面
当需要使用浏览器模拟时,首先我们要调用webdriver.Chrome(executable_path=WebPath)函数并传入驱动程序路径,此时即可打开驱动程序与谷歌浏览器链接,接着就可以通过各类函数操控浏览器行为。
from selenium import webdriver
from selenium.webdriver.common.by import By
WebPath = "C:/Users/admin/AppData/Local/Google/Chrome/Application/chromedriver.exe"
if __name__ == "__main__":
driver = webdriver.Chrome(executable_path=WebPath)
# 设置窗口大小为1275*765
driver.set_window_size(1275, 765)
# 设置窗体为全屏
driver.maximize_window()
# 获得窗口大小
get_size = driver.get_window_size()
print("获取窗口大小: {}".format(get_size))
# 获取当前窗体句柄
handle = driver.current_window_handle
print("当前句柄: {}".format(handle))
# 打开链接并得到页面源代码
url = "https://www.baidu.com"
driver.get(url)
url_source = str(driver.page_source)
# print("页面源代码: {}".format(url_source))
# 定位a标签并点击,跳转到贴吧
click_url = driver.find_element(By.XPATH, '//*[@id="s-top-left"]/a[4]')
click_url.click()
# 打开页面后输出所有窗体句柄
all_handles = driver.window_handles
print("当前所有窗体句柄: {}".format(all_handles))
input("输入回车结束")
driver.quit()
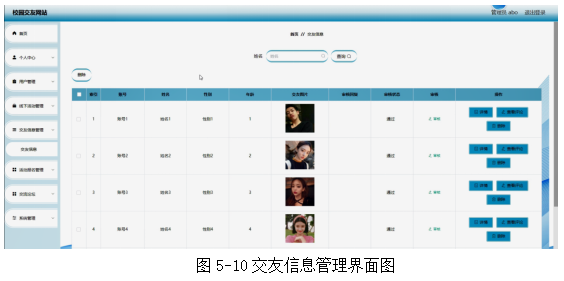
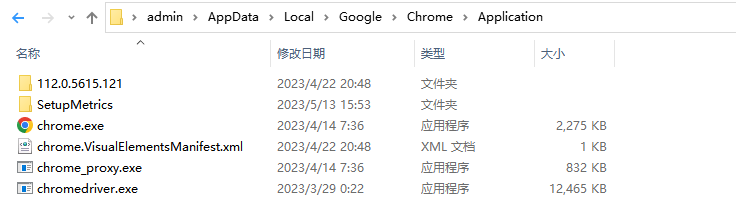
上述代码片段中,首先通过set_window_size()函数将浏览器页面设置为1275*765接着再调用maximize_window()设置为全屏,通过得到当前窗体句柄,并通过get()函数让浏览器打开一个页面,最后通过xpath语法定位到//*[@id="s-top-left"]/a[4]标签(贴吧)上,并点击鼠标左键,打开页面后并输出所有窗体,如下图所示;
21.9.2 切换窗体句柄
如上代码执行后虽然打开了百度百科,但是窗体的句柄其实还是停留在了百度首页上,定位的元素还是在百度上,此时我们就需要切换窗体句柄,也就是将当前句柄切换到百度贴吧页面上,此时才可读取该页面的完整源代码信息。
我们通过使用all_handles[-1]的方式切换到最后一个窗体上,也就是对应的百度贴吧页面,接着再执行switch_to.window(new_handle_tieba)函数实现窗口句柄的切换功能,代码如下所示;
from selenium import webdriver
from selenium.webdriver.common.by import By
WebPath = "C:/Users/admin/AppData/Local/Google/Chrome/Application/chromedriver.exe"
if __name__ == "__main__":
driver = webdriver.Chrome(executable_path=WebPath)
# 设置窗口大小为1275*765
driver.set_window_size(1275, 765)
# 打开链接并得到页面源代码
url = "https://www.baidu.com"
driver.get(url)
# 定位a标签并点击,跳转到贴吧
click_url = driver.find_element(By.XPATH, '//*[@id="s-top-left"]/a[4]')
click_url.click()
# 打开页面后输出所有窗体句柄
all_handles = driver.window_handles
print("当前所有窗体句柄: {}".format(all_handles))
# 从所有句柄的集合中,获取最后那个,也就是最新的
new_handle_tieba = all_handles[-1]
# 执行切换操作
driver.switch_to.window(new_handle_tieba)
# 切换后查看现在的句柄
now_handles = driver.current_window_handle
print("贴吧窗体句柄: {}".format(now_handles))
# 得到贴吧源代码
url_source = str(driver.page_source)
print(url_source)
input("输入回车结束")
driver.quit()
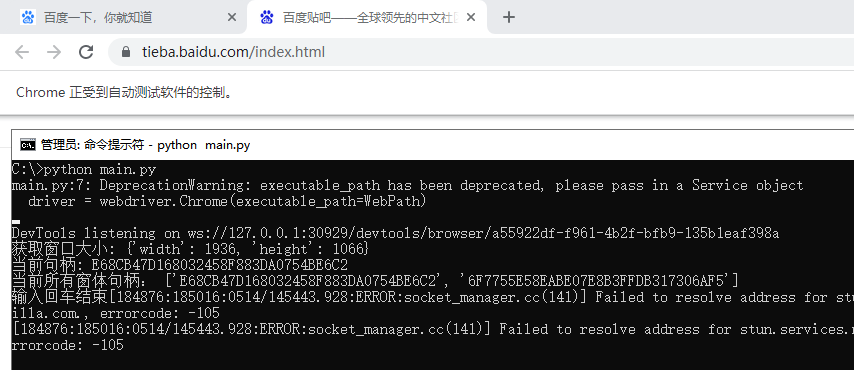
运行后读者可自行查询当前句柄所在位置,如下图所示;
21.9.3 前进后退刷新
在控制页面是我们可能需要使用页面前进后退与刷新功能,前进时可以调用driver.forward()函数实现,后退调用driver.back()函数,而刷新则可调用driver.refresh()函数,功能如下案例所示;
from selenium import webdriver
from selenium.webdriver.common.by import By
WebPath = "C:/Users/admin/AppData/Local/Google/Chrome/Application/chromedriver.exe"
if __name__ == "__main__":
driver = webdriver.Chrome(executable_path=WebPath)
# 设置窗口大小为1275*765
driver.set_window_size(1275, 765)
# 打开链接
driver.get(url="https://www.baidu.com")
driver.get(url="https://www.lyshark.com")
# 后退上一页,等待3秒
driver.implicitly_wait(3)
driver.back()
# 前进下一页,等待3秒
driver.implicitly_wait(3)
driver.forward()
# 刷新页面,等待3秒
driver.implicitly_wait(3)
driver.refresh()
# 获取当前页面句柄,并切换过去
handle = driver.current_window_handle
driver.switch_to.window(handle)
# 得到源代码
url_source = str(driver.page_source)
print(url_source)
# 关闭当前窗口
driver.close()
input("输入回车结束")
driver.quit()
运行后读者可自行观察输出效果,如下图所示;
21.9.4 自动页面采集
如下是一个综合案例,在案例中我们通过使用三种解析库实现了对百度页面中特定关键字的采集,当运行后读者可自行判断是否存在安全验证,如果存在可自行手动绕过检测,并输入y此时即可实现关键字的采集,当采集完成后自动柏村委html格式文件。
import re,argparse,requests
from selenium import webdriver
from bs4 import BeautifulSoup
from queue import Queue
WebPath = "C:/Users/admin/AppData/Local/Google/Chrome/Application/chromedriver.exe"
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--search",dest="search",help="输入要搜索的语法,inurl:lyshark")
args = parser.parse_args()
if args.search:
driver = webdriver.Chrome(executable_path=WebPath)
driver.set_window_size(1024,768)
queue = Queue()
# 生成链接
for item in range(0,1000,10):
queue.put('https://www.baidu.com/s?wd={}&pn={}'.format(str(args.search),str(item)))
# 每次吐出一个
for item in queue.queue:
driver.get(item)
ret = str(driver.page_source)
# 是否有验证
if driver.title == "百度安全验证":
print("请用户完成验证,并输入y: ")
is_true = input()
if is_true != "y":
driver.close()
soup = BeautifulSoup(ret,'html.parser')
urls = soup.find_all(name='a',attrs={'data-click':re.compile(('.')),'class':None})
for item in urls:
try:
get_url = requests.get(url=item['href'],headers=head,timeout=5)
print(get_url)
if get_url.status_code == 200:
title = re.findall('<title>(.+)</title>', get_url.text)
print("[+] 抓取URL: {} 抓取标题: {}".format(get_url.url,title))
with open("save.html","a+") as fp:
fp.write("<a href={}>{}</a><br>".format(get_url.url,title))
except Exception:
pass
else:
parser.print_help()
运行上述代码,读者可观察输出效果,此时会自动抓取特定页面中的链接,并存储到本地;
本文作者: 王瑞
本文链接: https://www.lyshark.com/post/6fa05047.html
版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!