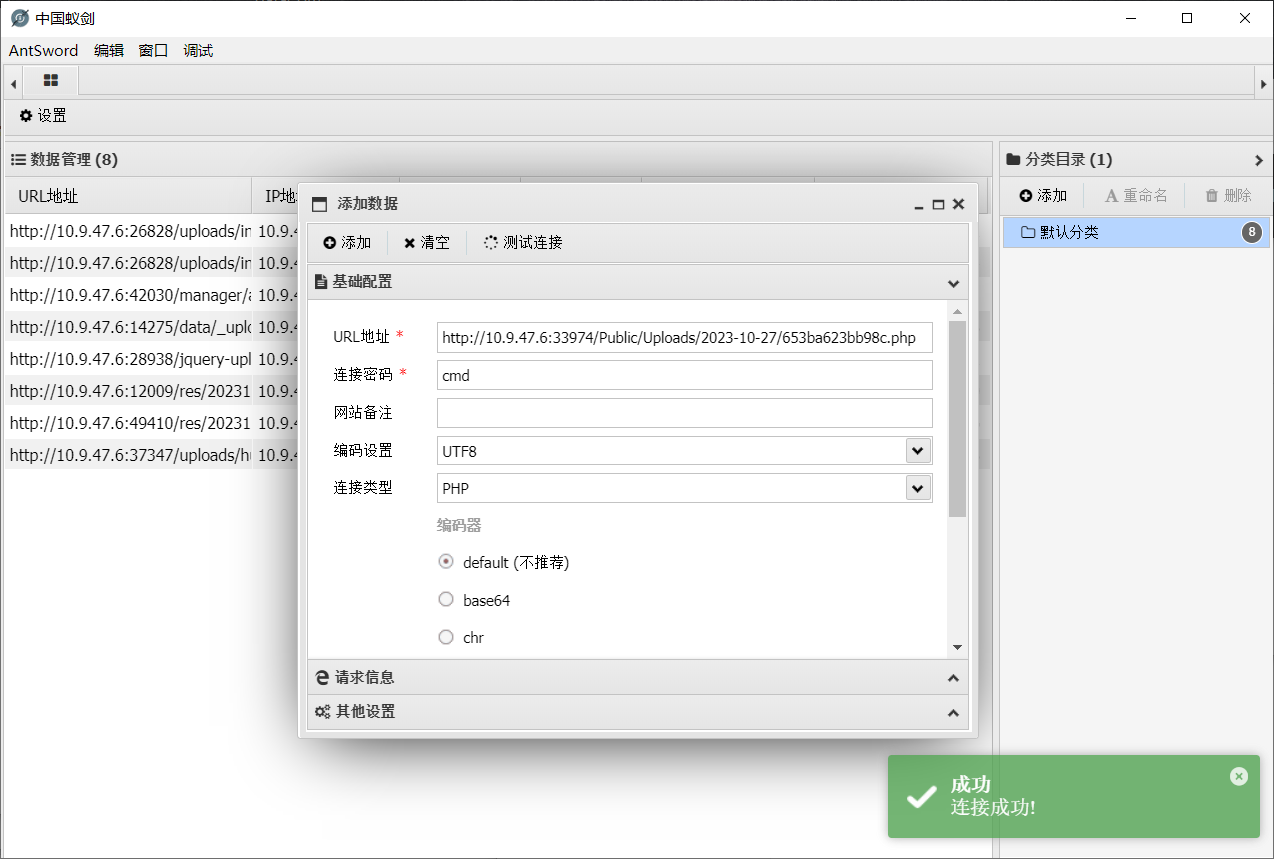
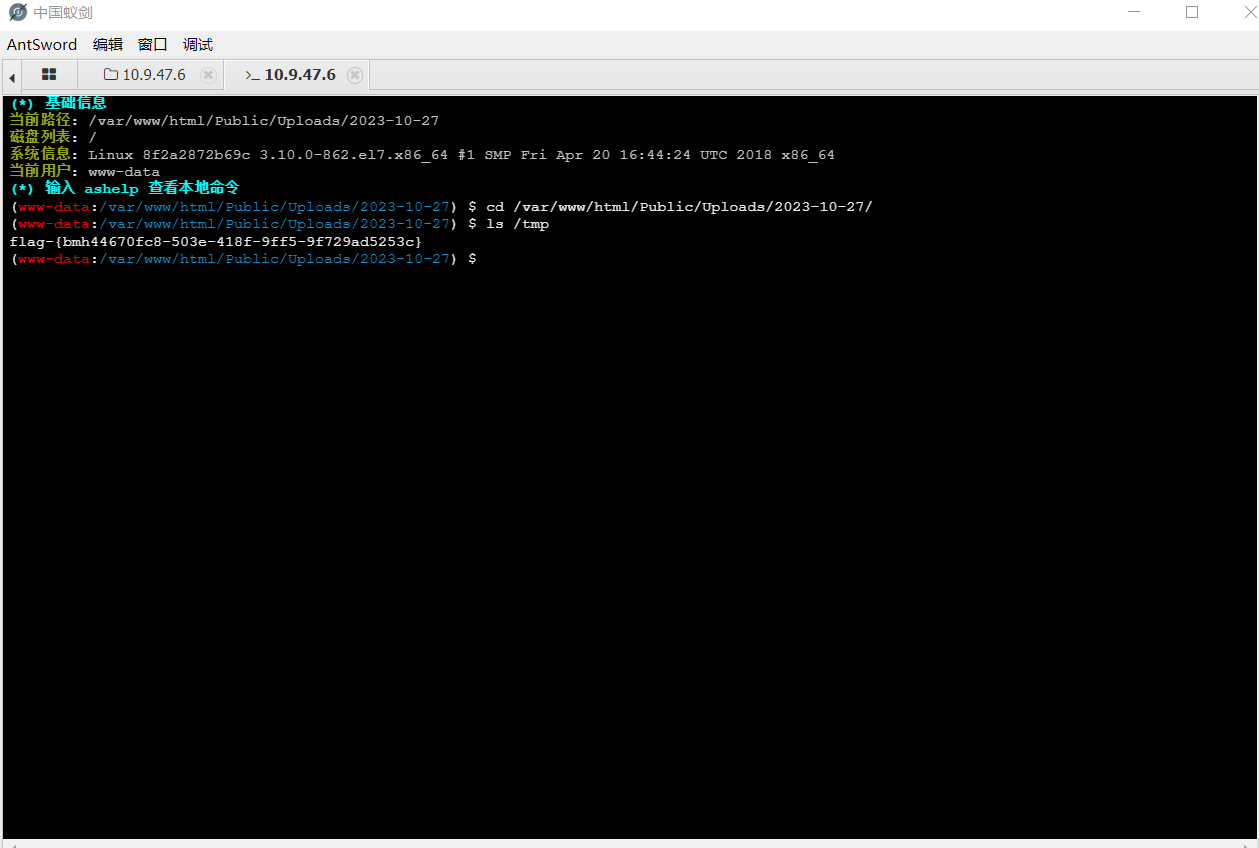
论文地址:SSCONV
代码地址:https://github.com/cheng-haha/ScConv
1.是什么?
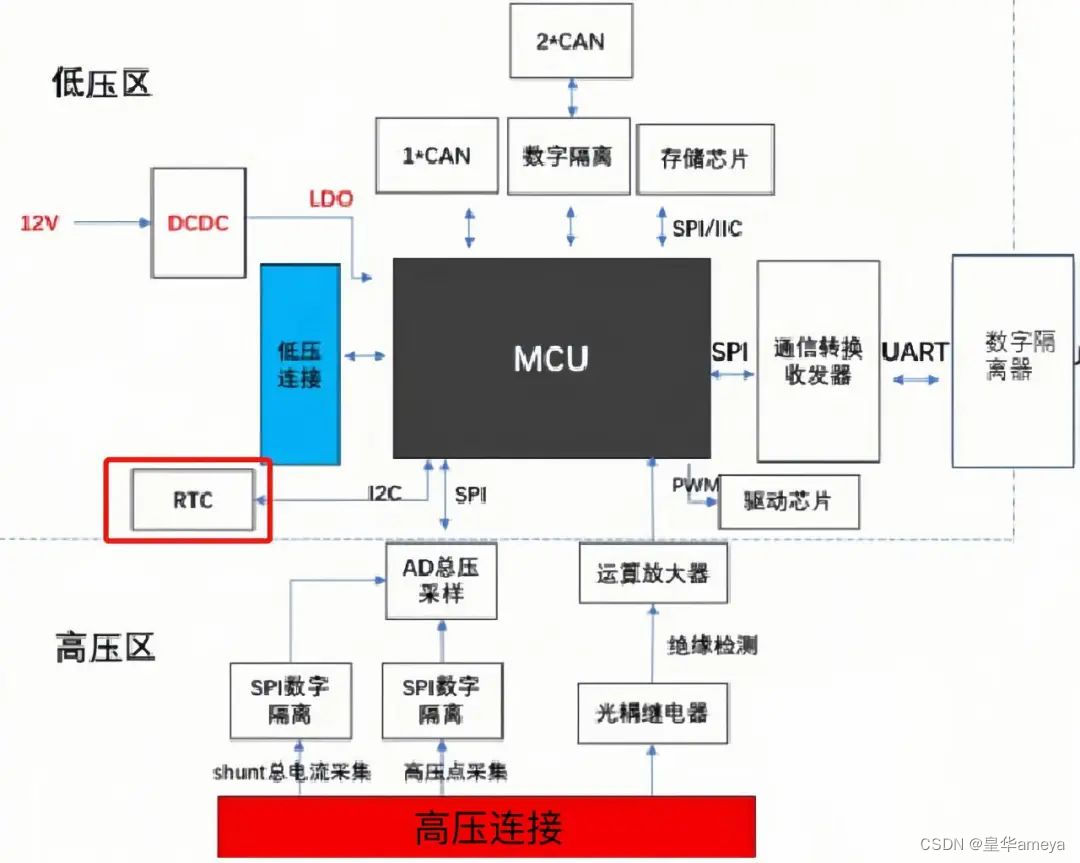
SCConv是一种高效的卷积模块,用于压缩卷积神经网络中的冗余特征,以减少计算负荷并提高模型性能。它由空间重构单元(SRU)和信道重构单元(CRU)两个单元组成,SRU用于抑制空间冗余,CRU用于减少信道冗余。SCConv可以直接用于替代各种卷积神经网络中的标准卷积,是一种即插即用的架构单元。实验结果表明,将SCConv嵌入模型可以通过减少冗余特征来获得更好的性能,并且显著降低了复杂度和计算成本。
2.为什么?
卷积神经网络(CNN)在各种计算机视觉任务中取得了显著的性能,但这是以巨大的计算资源为代价的,部分原因是卷积层提取冗余特征。最近的作品要么压缩训练有素的大型模型,要么探索设计良好的轻量级模型。在本文中,我们尝试利用特征之间的空间和通道冗余来进行CNN压缩,并提出了一种高效的卷积模块,称为SCConv (spatial and channel reconstruction convolution),以减少冗余计算并促进代表性特征的学习。提出的SCConv由空间重构单元(SRU)和信道重构单元(CRU)两个单元组成。SRU采用分离重构的方法来抑制空间冗余,CRU采用分离变换融合的策略来减少信道冗余。此外,SCConv是一种即插即用的架构单元,可直接用于替代各种卷积神经网络中的标准卷积。实验结果表明,scconvo嵌入模型能够通过减少冗余特征来获得更好的性能,并且显著降低了复杂度和计算成本。
3.怎么样?
3.1网络结构
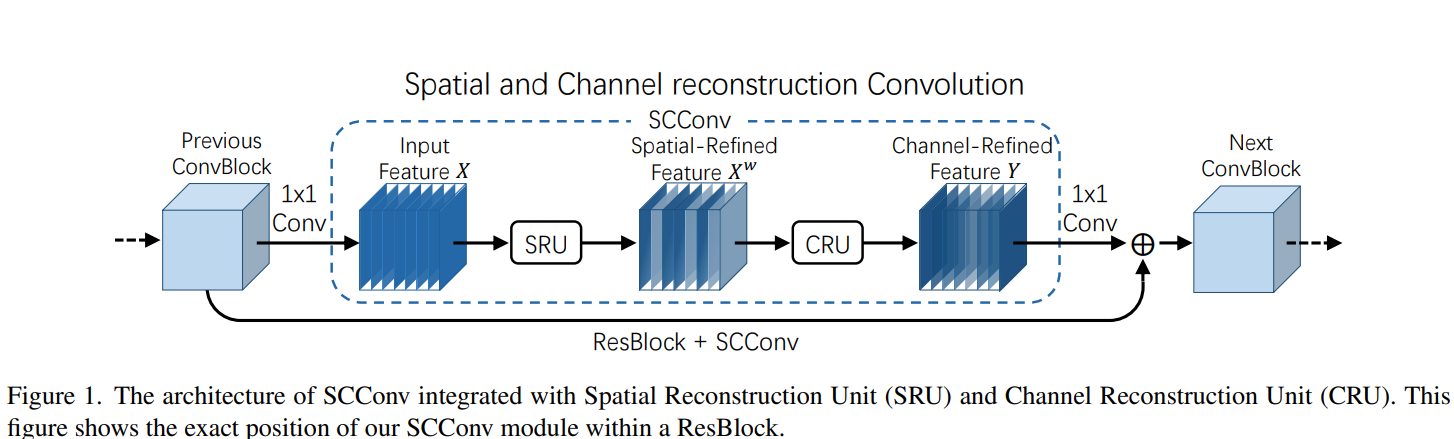
如图所示的SCConv,它由空间重构单元(SRU)和通道重构单元(CRU)两个按顺序放置的单元组成。具体而言,对于瓶颈残差块中的中间输入特征X,首先通过SRU操作得到空间细化特征Xw,然后利用CRU操作得到通道细化特征Y。在SCConv模块中利用特征之间的空间和通道冗余,可以无缝集成到任何CNN架构中,以减少中间特征图之间的冗余,并提高CNN的特征表示。
3.2 模块
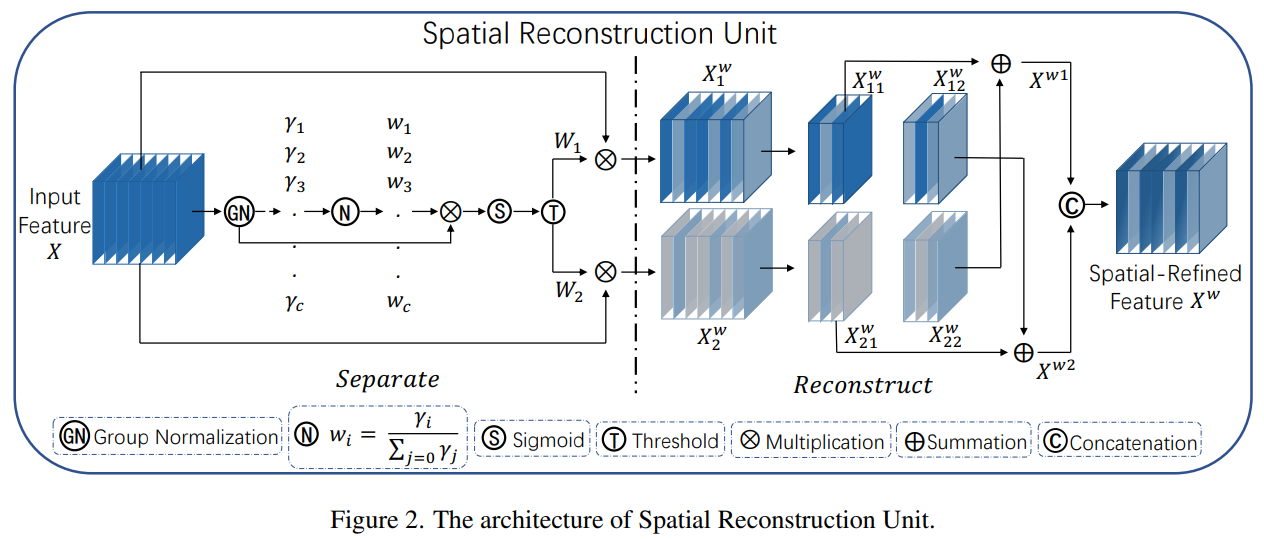
3.2.1SRU用于空间冗余
为了利用特征的空间冗余性,我们引入了空间重构单元(SRU),如图2所示,采用分离-重构操作。分离操作旨在将信息丰富的特征图与与空间内容对应的信息较少的特征图分离。利用组归一化(GN)层中的缩放因子来评估不同特征图的信息内容。具体来说,给定一个中间特征图X∈R N×C×H×W,其中N为批处理轴,C为通道轴,H和W为空间高度和宽度轴。我们首先通过减去均值µ除以标准差σ来标准化输入特征X,如下所示:
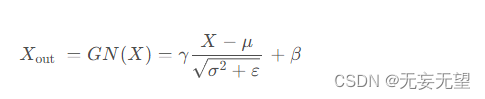
其中,μ和σ是X的均值和标准差,ε是一个为了稳定除法而添加的小的正数,γ和β是可训练的仿射变换。
注意到我们在GN层中利用可训练参数来衡量每个批次和通道的空间像素的方差。更丰富的空间信息反映了更多的空间像素的变化,从而贡献更大的γ 。归一化的相关权重
通过等式获得,这表明了不同特征图的重要性。
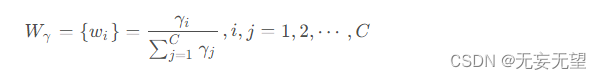
然后通过sigmoid函数将由重新加权的特征图的权重值映射到范围(0,1)并通过阈值进行门控。我们将高于阈值的权重设置为1以获得信息丰富的权重
,而将它们设置为0以获得非信息丰富的权重
(在实验中阈值设置为0.5)。获取W 的整个过程可以由等式表示:
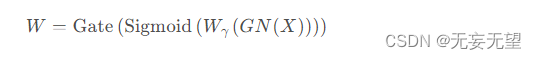
最后,我们将输入特征X分别乘以 和
,得到两个加权特征:信息丰富的特征
和信息较少的特征
。这样我们就成功地将输入特征分为两个部分:
具有信息丰富和表现力强的空间内容,而
几乎没有信息,被视为冗余。
为了进一步减少空间冗余,我们提出了一种Reconstruct操作,将富含信息的特征与信息较少的特征相加,以生成更丰富的信息特征并节省空间。我们没有直接将这两个部分相加,而是采用交叉重建操作来充分结合加权的两个不同的信息丰富的特征,并加强它们之间的信息流。之后我们将交叉重建后的特征和
连接起来以获得空间细化特征图
。Reconstruct操作的整体过程可以表示为:
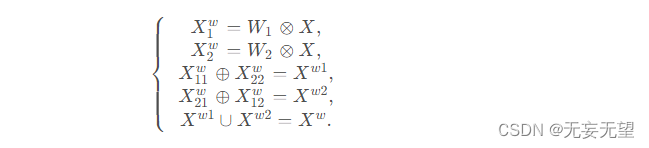
其中⊗ 表示逐元素相乘,⊕表示逐元素相加,∪ 表示拼接。将SRU应用于中间输入特征X XX后,我们不仅将信息丰富的特征与信息较少的特征分离,而且对它们进行了重构以增强代表性特征并抑制空间维度中的冗余特征。然而,空间细化特征图在通道维度上仍然存在冗余。
3.2.2. CRU用于通道冗余
为了利用特征的通道冗余,我们引入了通道重建单元(CRU),如图3所示,它利用了“分割-转换-融合”的策略。通常,我们使用重复的标准k \times k卷积来提取特征,导致一些相对冗余的特征图沿着通道维度。让我们表示一个k \times k卷积核,
表示输入和卷积后的输出特征。一个标准卷积可以定义为
。具体来说,我们将标准卷积替换为CRU,它通过三个运算符-Split、Transform和Fuse来实现。
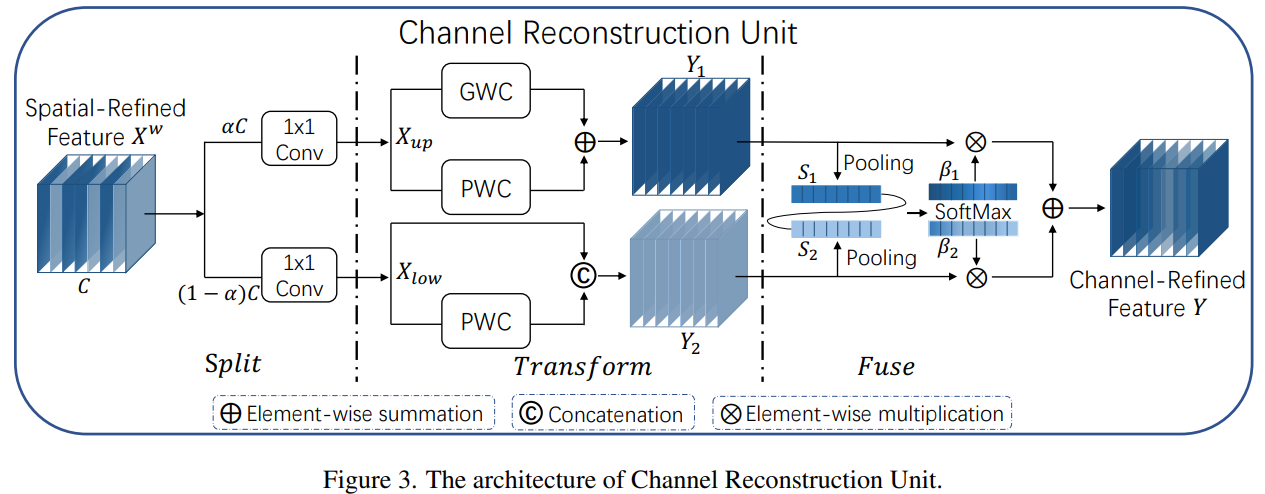
Split:对于给定的空间细化特征,我们首先将
的通道分成两部分,其中一部分具有αC个通道,另一部分具有( 1 − α ) C 个通道,如图3中的分割部分所示,其中0 ≤ α ≤ 1 是一个分割比例。随后,我们进一步利用1 \times 1卷积来压缩特征图的通道以提高计算效率。这里我们引入一个压缩比例r来控制CRU的特征通道以平衡计算成本(实验中典型的r设置为2)。在分割和压缩操作之后,我们将空间细化特征
分为上部分
和下部分
Transform: 被输入到上转换阶段,作为“丰富的特征提取器”。我们采用高效的卷积操作(即GWC和PWC)来代替昂贵的标准k \times k卷积来提取高级代表性信息,同时降低计算成本。由于稀疏卷积连接,GWC减少了参数和计算量,但切断了通道组之间的信息流。而PWC弥补了信息的损失并帮助信息在特征通道之间流动。因此,我们在相同的
上执行k × k GWC(在实验中我们将组大小g = 2 g=2g=2)和1 × 1 PWC操作。之后,我们将输出相加形成合并代表特征图
,如图3中的Transform部分所示。上转换阶段可以表示为:
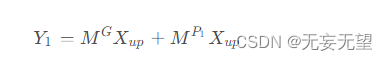
其中,
是GWC和PWC的可学习权重矩阵,
和 分别是上输入和输出特征图。简而言之,上转换阶段利用GWC和PWC在相同的特征图
上的组合来以较少的计算成本提取丰富的代表性特征
。
被输入到底部转换阶段,其中我们应用廉价的1 × 1 PWC操作生成具有浅层隐藏细节的特征图,作为丰富特征提取器的补充。此外,我们重用特征
以获取更多的特征图而不增加额外成本。最后,我们将生成的和重用的特征连接起来形成底部阶段的输出
,如下所示:
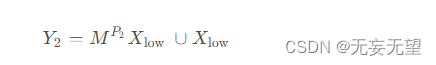
其中是PWC的可学习权重矩阵,∪是连接操作,
和
分别是底部输入和输出特征图。总之,底部转换阶段重用前面的特征
并利用廉价的1 × 1 PWC来获取具有补充详细信息的特征
。
merge:在进行转换之后,我们不是直接连接或添加两种类型的特征,而是利用简化的SKNet方法自适应地合并上转换阶段和下转换阶段的输出特征 和
,如图3的Fuse部分所示。我们首先应用全局平均池化(Pooling)来收集全局空间信息,通道统计信息
计算如下:
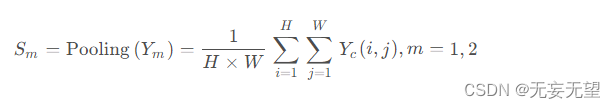
接下来,我们将上部分和下部分的全局通道描述子,
堆叠在一起,并使用通道注意力操作来生成特征重要性向量
,如下所示:
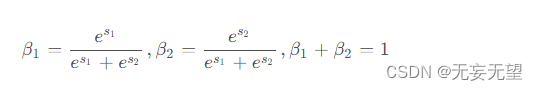
最后,在特征重要性向量的指导下,通过以通道的方式合并上特征
和下特征
来获得通道精细化特征Y ,如下所示:
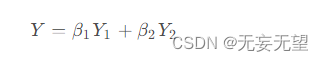
简而言之,我们采用CRU,使用Split-Transform-and-Fuse策略,以进一步减少空间细化特征图在通道维度上的冗余。此外,CRU通过轻量级卷积操作提取丰富的代表性特征,同时使用廉价操作和特征重用方案进行冗余特征的处理。总体而言,CRU可以单独使用或与SRU操作结合使用。通过以顺序方式排列SRU和CRU,建立了提出的SCConv,它具有高效率且能够替代标准卷积操作。
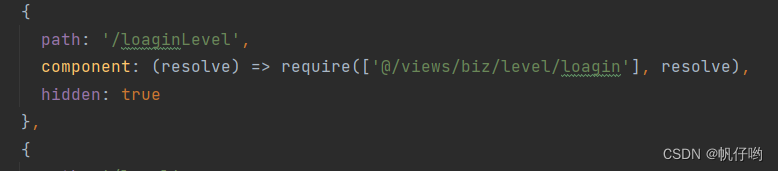
3.3代码实现
import torch # 导入 PyTorch 库
import torch.nn.functional as F # 导入 PyTorch 的函数库
import torch.nn as nn # 导入 PyTorch 的神经网络模块
# 自定义 GroupBatchnorm2d 类,实现分组批量归一化
class GroupBatchnorm2d(nn.Module):
def __init__(self, c_num:int, group_num:int = 16, eps:float = 1e-10):
super(GroupBatchnorm2d,self).__init__() # 调用父类构造函数
assert c_num >= group_num # 断言 c_num 大于等于 group_num
self.group_num = group_num # 设置分组数量
self.gamma = nn.Parameter(torch.randn(c_num, 1, 1)) # 创建可训练参数 gamma
self.beta = nn.Parameter(torch.zeros(c_num, 1, 1)) # 创建可训练参数 beta
self.eps = eps # 设置小的常数 eps 用于稳定计算
def forward(self, x):
N, C, H, W = x.size() # 获取输入张量的尺寸
x = x.view(N, self.group_num, -1) # 将输入张量重新排列为指定的形状
mean = x.mean(dim=2, keepdim=True) # 计算每个组的均值
std = x.std(dim=2, keepdim=True) # 计算每个组的标准差
x = (x - mean) / (std + self.eps) # 应用批量归一化
x = x.view(N, C, H, W) # 恢复原始形状
return x * self.gamma + self.beta # 返回归一化后的张量
# 自定义 SRU(Spatial and Reconstruct Unit)类
class SRU(nn.Module):
def __init__(self,
oup_channels:int, # 输出通道数
group_num:int = 16, # 分组数,默认为16
gate_treshold:float = 0.5, # 门控阈值,默认为0.5
torch_gn:bool = False # 是否使用PyTorch内置的GroupNorm,默认为False
):
super().__init__() # 调用父类构造函数
# 初始化 GroupNorm 层或自定义 GroupBatchnorm2d 层
self.gn = nn.GroupNorm(num_channels=oup_channels, num_groups=group_num) if torch_gn else GroupBatchnorm2d(c_num=oup_channels, group_num=group_num)
self.gate_treshold = gate_treshold # 设置门控阈值
self.sigomid = nn.Sigmoid() # 创建 sigmoid 激活函数
def forward(self, x):
gn_x = self.gn(x) # 应用分组批量归一化
w_gamma = self.gn.gamma / sum(self.gn.gamma) # 计算 gamma 权重
reweights = self.sigomid(gn_x * w_gamma) # 计算重要性权重
# 门控机制
info_mask = reweights >= self.gate_treshold # 计算信息门控掩码
noninfo_mask = reweights < self.gate_treshold # 计算非信息门控掩码
x_1 = info_mask * x # 使用信息门控掩码
x_2 = noninfo_mask * x # 使用非信息门控掩码
x = self.reconstruct(x_1, x_2) # 重构特征
return x
def reconstruct(self, x_1, x_2):
x_11, x_12 = torch.split(x_1, x_1.size(1) // 2, dim=1) # 拆分特征为两部分
x_21, x_22 = torch.split(x_2, x_2.size(1) // 2, dim=1) # 拆分特征为两部分
return torch.cat([x_11 + x_22, x_12 + x_21], dim=1) # 重构特征并连接
# 自定义 CRU(Channel Reduction Unit)类
class CRU(nn.Module):
def __init__(self, op_channel:int, alpha:float = 1/2, squeeze_radio:int = 2, group_size:int = 2, group_kernel_size:int = 3):
super().__init__() # 调用父类构造函数
self.up_channel = up_channel = int(alpha * op_channel) # 计算上层通道数
self.low_channel = low_channel = op_channel - up_channel # 计算下层通道数
self.squeeze1 = nn.Conv2d(up_channel, up_channel // squeeze_radio, kernel_size=1, bias=False) # 创建卷积层
self.squeeze2 = nn.Conv2d(low_channel, low_channel // squeeze_radio, kernel_size=1, bias=False) # 创建卷积层
# 上层特征转换
self.GWC = nn.Conv2d(up_channel // squeeze_radio, op_channel, kernel_size=group_kernel_size, stride=1, padding=group_kernel_size // 2, groups=group_size) # 创建卷积层
self.PWC1 = nn.Conv2d(up_channel // squeeze_radio, op_channel, kernel_size=1, bias=False) # 创建卷积层
# 下层特征转换
self.PWC2 = nn.Conv2d(low_channel // squeeze_radio, op_channel - low_channel // squeeze_radio, kernel_size=1, bias=False) # 创建卷积层
self.advavg = nn.AdaptiveAvgPool2d(1) # 创建自适应平均池化层
def forward(self, x):
# 分割输入特征
up, low = torch.split(x, [self.up_channel, self.low_channel], dim=1)
up, low = self.squeeze1(up), self.squeeze2(low)
# 上层特征转换
Y1 = self.GWC(up) + self.PWC1(up)
# 下层特征转换
Y2 = torch.cat([self.PWC2(low), low], dim=1)
# 特征融合
out = torch.cat([Y1, Y2], dim=1)
out = F.softmax(self.advavg(out), dim=1) * out
out1, out2 = torch.split(out, out.size(1) // 2, dim=1)
return out1 + out2
# 自定义 ScConv(Squeeze and Channel Reduction Convolution)模型
class ScConv(nn.Module):
def __init__(self, op_channel:int, group_num:int = 16, gate_treshold:float = 0.5, alpha:float = 1/2, squeeze_radio:int = 2, group_size:int = 2, group_kernel_size:int = 3):
super().__init__() # 调用父类构造函数
self.SRU = SRU(op_channel, group_num=group_num, gate_treshold=gate_treshold) # 创建 SRU 层
self.CRU = CRU(op_channel, alpha=alpha, squeeze_radio=squeeze_radio, group_size=group_size, group_kernel_size=group_kernel_size) # 创建 CRU 层
def forward(self, x):
x = self.SRU(x) # 应用 SRU 层
x = self.CRU(x) # 应用 CRU 层
return x
if __name__ == '__main__':
x = torch.randn(1, 32, 16, 16) # 创建随机输入张量
model = ScConv(32) # 创建 ScConv 模型
print(model(x).shape) # 打印模型输出的形状
参考:
CVPR 2023 | SCConv: 即插即用的空间和通道重建卷积(附源码)
SCConv:用于特征冗余的空间和通道重构卷积