时间序列预测领域在最近的几年有着快速的发展,比如N-BEATS、N-HiTS、PatchTST和TimesNet。
大型语言模型(llm)最近在ChatGPT等应用程序中变得非常流行,因为它们可以适应各种各样的任务,而无需进一步的训练。
这就引出了一个问题:时间序列的基础模型能像自然语言处理那样存在吗?一个预先训练了大量时间序列数据的大型模型,是否有可能在未见过的数据上产生准确的预测?
通过Azul Garza和Max Mergenthaler-Canseco提出的TimeGPT-1,作者将llm背后的技术和架构应用于预测领域,成功构建了第一个能够进行零样本推理的时间序列基础模型。
在本文中,我们将探索TimeGPT背后的体系结构以及如何训练模型。然后,我们将其应用于预测项目中,以评估其与其他最先进的方法(如N-BEATS, N-HiTS和PatchTST)的性能。
TimeGPT
TimeGPT是为时间序列预测创建基础模型的第一次尝试。
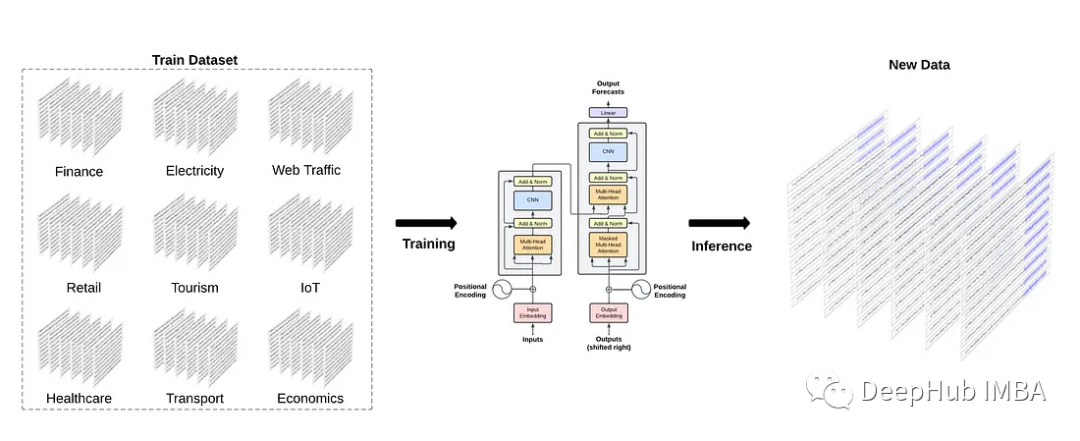
从上图中,我们可以看到TimeGPT背后的一般思想是在来自不同领域的大量数据上训练模型,然后对未见过的数据产生零样本的推断。
这种方法依赖于迁移学习,迁移学习是指模型利用在训练过程中获得的知识解决新任务的能力。这种方式只有当模型足够大,并且在大量数据上进行训练时才有效。
为此,作者对TimeGPT进行了超过1000亿个数据点的训练,这些数据点都来自开源的时间序列数据。该数据集涵盖了广泛的领域,从金融、经济和天气,到网络流量、能源和销售。
但是这里作者没有披露用于管理1000亿个数据点的公共数据的来源。
这种多样性对于基础模型的成功至关重要,因为它可以学习不同的时间模式,因此可以更好地进行泛化。
例如,我们可以预期天气数据具有日季节性(白天比晚上热)和年季节性,而汽车交通数据可以具有日季节性(白天路上的汽车比晚上多)和周季节性(一周内路上的汽车比周末多)。
为了保证模型的鲁棒性和泛化能力,预处理被保持在最低限度。事实上只有缺失的值被填充,其余的保持原始形式。虽然作者没有具体说明数据输入的方法,但我怀疑使用了某种插值技术,如线性、样条或移动平均插值。
然后作者对模型进行多天的训练,在此期间对超参数和学习率进行优化。虽然作者没有透露训练需要多少天和gpu资源,但我们确实知道该模型是在PyTorch中实现的,并且它使用Adam优化器和学习率衰减策略。
TimeGPT利用Transformer架构。

从上图中,我们可以看到TimeGPT使用了完整的编码器-解码器Transformer架构。
输入可以包括历史数据窗口,也可以包括外生数据窗口,如准时事件或其他系列。
输入被馈送到模型的编码器部分。然后编码器内部的注意力机制从输入中学习不同的属性。然后将其输入解码器,解码器使用学习到的信息进行预测。预测序列在达到用户设置的预测范围长度时结束。
值得注意的是,作者已经在TimeGPT中实现了适形预测,允许模型根据历史误差估计预测间隔。
考虑到TimeGPT是为时间序列构建基础模型的第一次尝试,它具有一系列广泛的功能。
TimeGPT的功能总结:
首先,TimeGPT是一个预先训练的模型,这意味着可以生成预测,而不需要对数据进行特定的训练。尽管如此,还是可以根据我们的数据对模型进行微调。
其次,该模型支持外生变量来预测我们的目标,也就是说可以处理多变量预测任务。
最后,使用保形预测,TimeGPT可以估计预测区间。这反过来又允许模型执行异常检测。如果一个数据点落在99%的置信区间之外,那么模型将其标记为异常。
所有这些任务都可以通过零样本推理或一些微调来实现,这是时间序列预测领域范式的根本转变。
现在我们对TimeGPT有了更扎实的了解,了解了它是如何工作的,以及它是如何训练的,让我们来看看实际的模型。
TimeGPT进行预测
现在让我们将TimeGPT应用于预测任务,并将其性能与其他模型进行比较。
在撰写本文时,TimeGPT只能通过API访问,并且还处于封闭测试阶段。我提交申请,并获得了免费使用该模型两周的授权。
如前所述,该模型是在来自公开可用数据的1000亿个数据点上进行训练的。由于作者没有指定使用的实际数据集,我认为在已知的基准数据集(如ETT或weather)上测试模型是不合理的,因为模型可能在训练期间看到了这些数据。
因此,我使用了自己的数据集,数据集现在在GitHub上公开可用,最重要的是TimeGPT没有在这些数据上进行训练。
导入库并读取数据
import pandas as pd
import numpy as np
import datetime
import matplotlib.pyplot as plt
from neuralforecast.core import NeuralForecast
from neuralforecast.models import NHITS, NBEATS, PatchTST
from neuralforecast.losses.numpy import mae, mse
from nixtlats import TimeGPT
%matplotlib inline
然后,为了访问TimeGPT模型从文件中读取API密钥。
with open("data/timegpt_api_key.txt", 'r') as file:
API_KEY = file.read()
然后读取数据。
df = pd.read_csv('data/medium_views_published_holidays.csv')
df['ds'] = pd.to_datetime(df['ds'])
df.head()
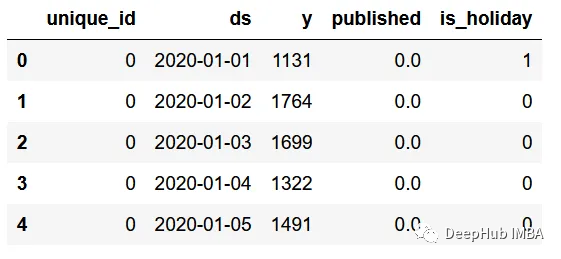
从上图中,我们可以看到数据集的格式与我们使用Nixtla的其他开源库时的格式相同。
我们有一个unique_id列来标记不同的时间序列,但在本例中,我们只有一个序列。
y列表示我的博客每天的浏览量,published是一个简单的标志,用来标记某一天有新文章发布(1)或没有文章发布(0)。一般来说当新内容发布时,浏览量通常会增加一段时间。
最后,列is_holiday表示美国是否有假日。在假期很少有人会访问。
现在让我们把我们的数据可视化。
published_dates = df[df['published'] == 1]
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(df['ds'], df['y'])
ax.scatter(published_dates['ds'], published_dates['y'], marker='o', color='red', label='New article')
ax.set_xlabel('Day')
ax.set_ylabel('Total views')
ax.legend(loc='best')
fig.autofmt_xdate()
plt.tight_layout()

从上图中,我们可以看到一些有趣的行为。首先,红点表示新发表的文章,并且几乎紧随其后的是访问高峰。
我们还注意到2021年的活动减少,这反映在日浏览量减少上。最后在2023年,我们注意到一篇文章发表后,访问量出现了一些异常高峰。
放大数据,我们还发现了明显的每周季节性。

从上图中,可以看到周末访问的访客比平时少。
考虑到所有这些,让我们看看如何使用TimeGPT进行预测。
首先,将数据集分成训练集和测试集。在这里为测试集保留168个时间步长,这对应于24周的每日数据。
train = df[:-168]
test = df[-168:]
然后使用7天的预测范围,因为我对预测整个星期的每日视图感兴趣。
该API没有附带验证的实现。因此我们创建自己的循环,一次生成七个预测,直到我们对整个测试集进行预测。
future_exog = test[['unique_id', 'ds', 'published', 'is_holiday']]
timegpt = TimeGPT(token=API_KEY)
timegpt_preds = []
for i in range(0, 162, 7):
timegpt_preds_df = timegpt.forecast(
df=df.iloc[:1213+i],
X_df = future_exog[i:i+7],
h=7,
finetune_steps=10,
id_col='unique_id',
time_col='ds',
target_col='y'
)
preds = timegpt_preds_df['TimeGPT']
timegpt_preds.extend(preds)
在上面的代码块中必须传递外生变量的未来值,因为它们是静态变量,我们知道未来假期的日期,
这里我们还使用finetune_steps参数对TimeGPT进行了微调。
一旦循环完成就可以将预测结果添加到测试集中。TimeGPT一次生成7个预测,直到获得168个预测,因此我们可以评估它预测下周每日浏览量的能力。
test['TimeGPT'] = timegpt_preds
test.head()

与N-BEATS, N-HiTS和PatchTST对比
现在我们用其他方法来进行对比,这里使用了N-BEATS, N-HiTS和PatchTST。
horizon = 7
models = [NHITS(h=horizon,
input_size=5*horizon,
max_steps=50),
NBEATS(h=horizon,
input_size=5*horizon,
max_steps=50),
PatchTST(h=horizon,
input_size=5*horizon,
max_steps=50)]
然后,我们初始化NeuralForecast对象并指定数据的频率,在本例中是每天。
nf = NeuralForecast(models=models, freq='D')
在7个时间步骤的24个窗口上运行执行验证,以获得与用于TimeGPT的测试集一致的预测。
preds_df = nf.cross_validation(
df=df,
static_df=future_exog ,
step_size=7,
n_windows=24
)
然后合并结果,这样就得到了一个包含所有模型预测的单一DataFrame。
preds_df['TimeGPT'] = test['TimeGPT']

下面开始评估每个模型的性能。在度量性能指标之前,可视化一下测试集中每个模型的预测。
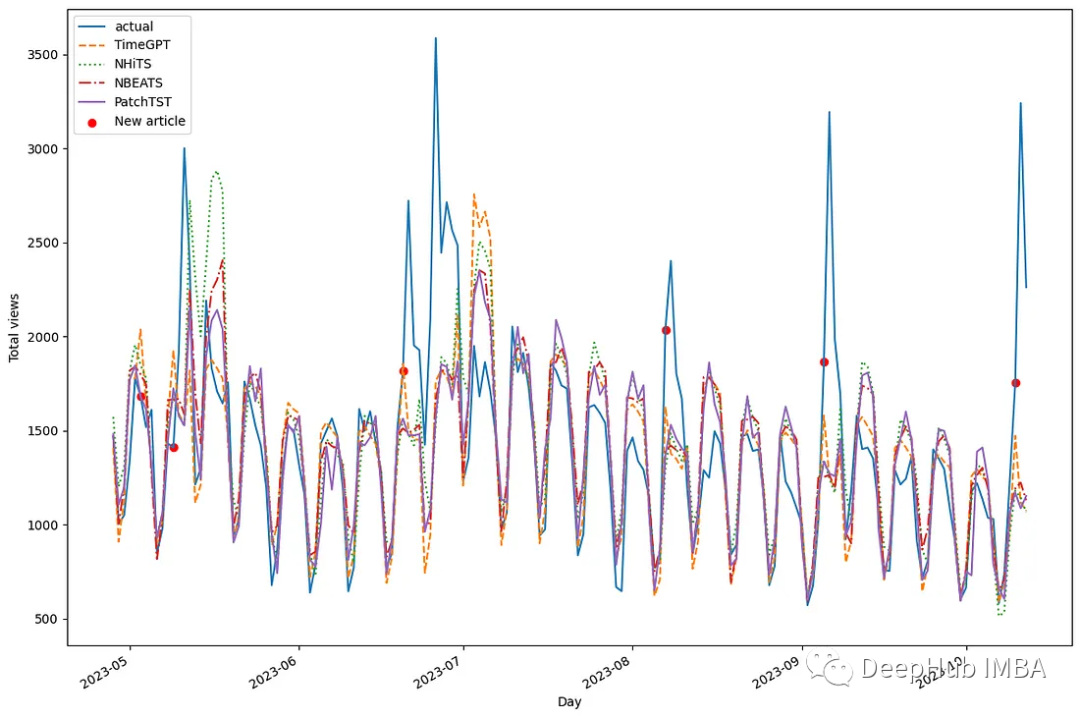
每个模型之间有很多重叠。我们确实注意到N-HiTS预测的两个峰值在现实中没有实现。此外PatchTST似乎经常预测不足。但是TimeGPT似乎通常与实际数据重叠得很好。
但是评估每个模型性能的唯一方法是度量性能指标。在这里使用平均绝对误差(MAE)和均方误差(MSE)。另外我们做的一个动作是将预测四舍五入为整数,因为小数在每日访问量上下文中是没有意义的。
preds_df = preds_df.round({
'NHITS': 0,
'NBEATS': 0,
'PatchTST': 0,
'TimeGPT': 0
})
data = {'N-HiTS': [mae(preds_df['NHITS'], preds_df['y']), mse(preds_df['NHITS'], preds_df['y'])],
'N-BEATS': [mae(preds_df['NBEATS'], preds_df['y']), mse(preds_df['NBEATS'], preds_df['y'])],
'PatchTST': [mae(preds_df['PatchTST'], preds_df['y']), mse(preds_df['PatchTST'], preds_df['y'])],
'TimeGPT': [mae(preds_df['TimeGPT'], preds_df['y']), mse(preds_df['TimeGPT'], preds_df['y'])]}
metrics_df = pd.DataFrame(data=data)
metrics_df.index = ['mae', 'mse']
metrics_df.style.highlight_min(color='lightgreen', axis=1)
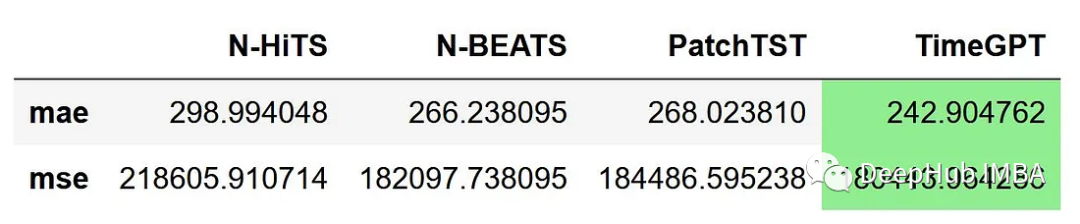
从上图中可以看到TimeGPT是表现最好,它实现了最低的MAE和MSE,其次是N-BEATS, PatchTST和N-HiTS。
这是一个令人兴奋的结果,因为TimeGPT从未见过这个数据集,并且只进行了几个步骤的微调。虽然这不是一个详尽的实验,但我相信它确实展示了潜在的基础模型在预测领域的潜力。
对TimeGPT的看法
TimeGPT是时间序列预测的第一个基础模型。它利用了Transformer架构,并在1000亿个数据点上进行了预训练,以便对新的未见过的数据进行零样本推断。该模型结合保形预测技术,无需特定数据集的训练即可生成预测区间并进行异常检测。
虽然TimeGPT的简短实验证明是令人兴奋的,但原始论文在许多重要概念仍然含糊不清。
比如我们不知道使用了哪些数据集来训练和测试模型,因此我们无法真正验证TimeGPT的性能结果,如下所示。
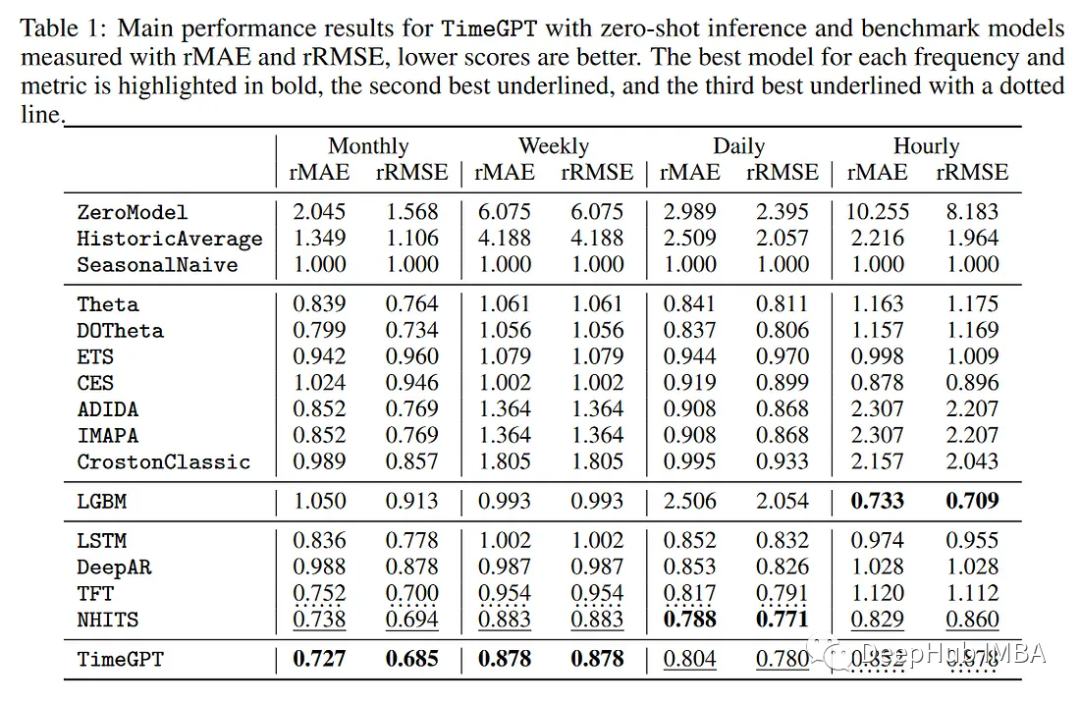
从上表中可以看到TimeGPT在每月和每周频率上表现最好,N-HiTS和TFT通常排名第二或第三。因为我们不知道使用了什么数据,所以我们无法验证这些指标。
虽然TimeGPT看起来很好,但是它还是有2个问题要面对:
1、当涉及到如何训练模型以及如何调整模型来处理时间序列数据时缺乏透明度,可以认为是没有任何的可解释性。
2、这个模型是用于商业用途的,这也就是为什么论文缺少细节,无法让人通过论文来复制TimeGPT。当然这并没有错,因为毕竟是要赚钱的。但这就导致论文缺乏可重复性,没人或再去研究和改进他。
虽然是这样,但是我还是觉得这能激发时间序列基础模型的新工作和研究,并且我们最终能看到这些模型的开源版本,就像我们在LLM中看到的那样。
https://avoid.overfit.cn/post/ef2f733060294bc98bbc185f1f41047a
作者:Marco Peixeiro