题目
406. 根据身高重建队列
中等
相关标签
贪心 树状数组 线段树 数组 排序
假设有打乱顺序的一群人站成一个队列,数组 people 表示队列中一些人的属性(不一定按顺序)。每个 people[i] = [hi, ki] 表示第 i 个人的身高为 hi ,前面 正好 有 ki 个身高大于或等于 hi 的人。
请你重新构造并返回输入数组 people 所表示的队列。返回的队列应该格式化为数组 queue ,其中 queue[j] = [hj, kj] 是队列中第 j 个人的属性(queue[0] 是排在队列前面的人)。
示例 1:
输入:people = [[7,0],[4,4],[7,1],[5,0],[6,1],[5,2]] 输出:[[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]] 解释: 编号为 0 的人身高为 5 ,没有身高更高或者相同的人排在他前面。 编号为 1 的人身高为 7 ,没有身高更高或者相同的人排在他前面。 编号为 2 的人身高为 5 ,有 2 个身高更高或者相同的人排在他前面,即编号为 0 和 1 的人。 编号为 3 的人身高为 6 ,有 1 个身高更高或者相同的人排在他前面,即编号为 1 的人。 编号为 4 的人身高为 4 ,有 4 个身高更高或者相同的人排在他前面,即编号为 0、1、2、3 的人。 编号为 5 的人身高为 7 ,有 1 个身高更高或者相同的人排在他前面,即编号为 1 的人。 因此 [[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]] 是重新构造后的队列。
示例 2:
输入:people = [[6,0],[5,0],[4,0],[3,2],[2,2],[1,4]] 输出:[[4,0],[5,0],[2,2],[3,2],[1,4],[6,0]]
提示:
1 <= people.length <= 20000 <= hi <= 1060 <= ki < people.length- 题目数据确保队列可以被重建
思路和解题方法
- 首先,定义了一个静态成员函数
cmp作为排序函数。在该函数中,根据题目要求,我们首先比较两个人的身高(a[0]和b[0]),如果身高相同,则按照第二个元素(a[1]和b[1])即前面身高大于等于自己的人数进行升序排序。如果身高不同,则按照身高降序排序。- 接下来,在
reconstructQueue函数中,对输入的people数组进行排序,排序的依据是调用了上述定义的cmp函数。这样,排序后的数组就满足了题目要求:身高高的人排在前面,身高相同的人按照前面身高大于等于自己的人数进行排序。- 然后,创建一个空的二维向量
que,用于存储重建后的队列。- 接下来,遍历排序后的
people数组。对于每个人,根据其应该插入的位置(即前面身高大于等于自己的人数),使用insert函数将其插入到que中的对应位置。由于在插入之前已经按照身高和前面身高大于等于自己的人数进行了排序,所以每次插入操作都不会破坏已经插入的人的相对顺序。- 最后,返回重建后的队列
que。- 这种贪心的思路是基于以下观察:对于每个人,他的前面身高大于等于自己的人数已经确定了,而在重建队列时,只需要根据这个人数将其插入到合适的位置即可。由于已经按照身高和前面身高大于等于自己的人数进行了排序,所以每次插入操作都不会破坏已经插入的人的相对顺序。因此,通过贪心地从身高最高的人开始,依次将每个人插入到合适的位置,就可以得到满足题目要求的重建队列。
复杂度
时间复杂度:
O(n^2)
在代码中,首先进行了一次排序操作,时间复杂度为O(nlogn),其中n是people数组的长度。然后,通过遍历排序后的数组,对于每个人都进行了一次插入操作。插入操作的平均时间复杂度为O(n),因为每个人可能需要插入到队列的任意位置。所以总体的时间复杂度为O(n^2)。
空间复杂度
O(n)
对于空间复杂度,除了输入的people数组外,额外使用了一个二维向量que来存储重建后的队列。队列的长度与people数组的长度相同,所以空间复杂度为O(n)。
c++ 代码
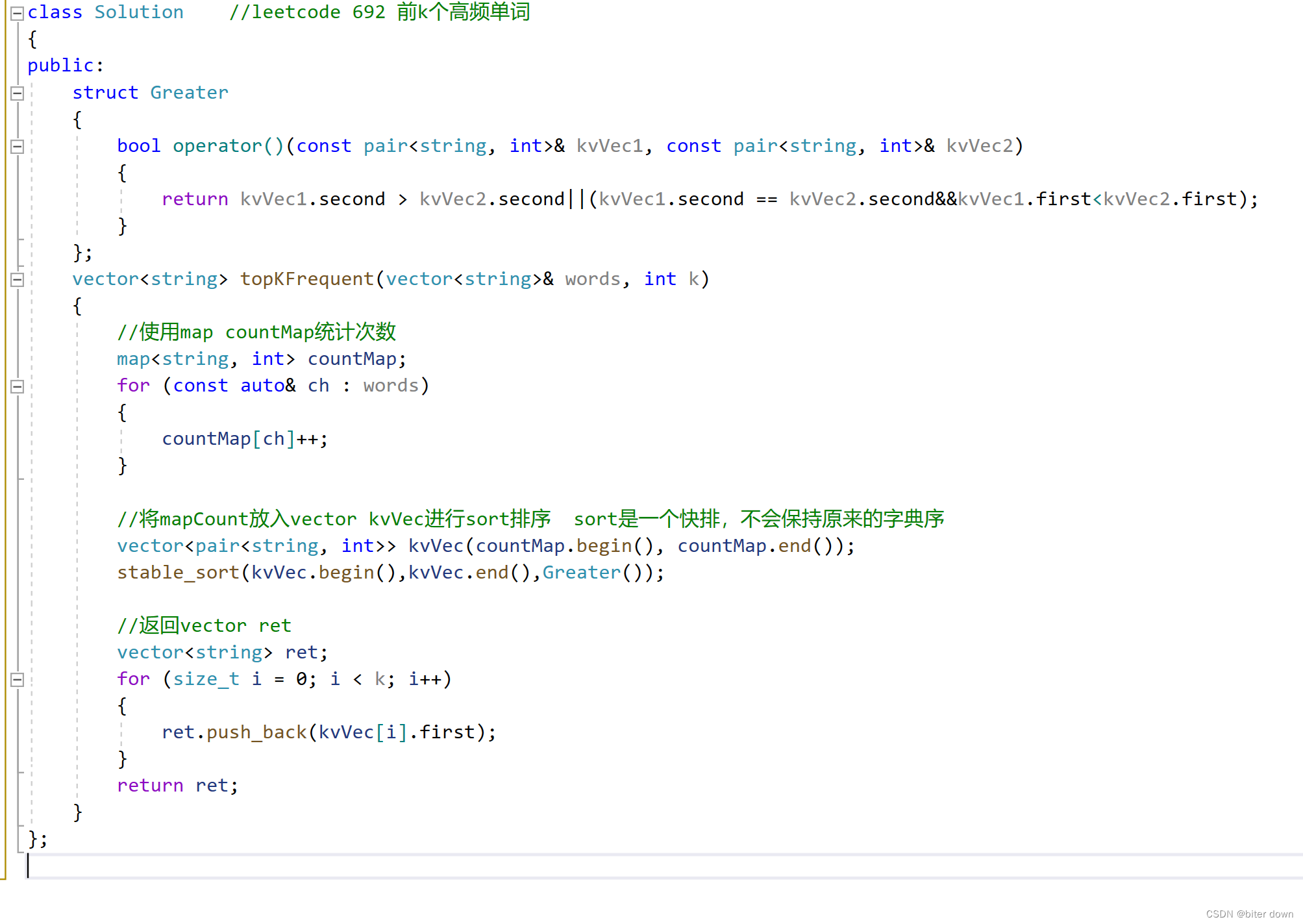
class Solution {
public:
// 定义一个静态函数 cmp,用于比较两个 vector<int> 对象
static bool cmp(const vector<int>& a, const vector<int>& b) {
// 如果 a 和 b 的第一个元素相同,则按照第二个元素进行比较,如果 a 的第二个元素小于 b 的第二个元素,则返回 true,否则返回 false
if (a[0] == b[0]) return a[1] < b[1];
// 如果 a 和 b 的第一个元素不同,则按照第一个元素进行比较,如果 a 的第一个元素大于 b 的第一个元素,则返回 true,否则返回 false
return a[0] > b[0];
}
// 定义一个函数 reconstructQueue,接收一个 vector<vector<int>> 类型的参数 people
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
// 对 people 数组进行排序,排序规则为 cmp 函数定义的方式
sort (people.begin(), people.end(), cmp);
// 定义一个空的 vector<vector<int>> 对象 que
vector<vector<int>> que;
// 遍历 people 数组
for (int i = 0; i < people.size(); i++) {
// 获取 people 数组中每个元素的第二个元素,即他们在队列中的位置,并赋值给 position 变量
int position = people[i][1];
// 在 que 数组的指定位置插入 people 数组中的元素,实现重新构造队列
que.insert(que.begin() + position, people[i]);
}
// 返回重新构造后的队列
return que;
}
}; 对比
用list优化后的代码
其优化是底层的相关知识
具体来说,当需要在vector<int> que中插入或删除元素时,需要将该元素后面的所有元素向后移动或向前移动,以确保vector中的元素始终连续存储。这个过程的时间复杂度为O(n),其中n是vector中元素的数量。
而在使用list<vector<int>> que时,插入或删除元素只需要修改相邻节点的指针,不需要移动元素本身,因此时间复杂度为O(1)。
class Solution {
public:
// 身高从大到小排(身高相同k小的站前面)
static bool cmp(const vector<int> a, const vector<int> b) {
if (a[0] == b[0]) return a[1] < b[1]; // 如果身高相同,则按照k值从小到大排序
return a[0] > b[0]; // 否则按照身高从大到小排序
}
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
sort (people.begin(), people.end(), cmp); // 对people进行排序,使其满足题目要求的顺序
list<vector<int>> que; // 创建一个链表,存储排序后的people
for (int i = 0; i < people.size(); i++) {
int position = people[i][1]; // 获取当前人员的插入位置
std::list<vector<int>>::iterator it = que.begin(); // 创建一个迭代器,指向链表头部
while (position--) { // 寻找当前人员的插入位置
it++; // 迭代器向后移动
}
que.insert(it, people[i]); // 在迭代器指向的位置前插入当前人员
}
return vector<vector<int>>(que.begin(), que.end()); // 将链表转换为二维向量并返回
}
};
觉得有用的话可以点点赞,支持一下。
如果愿意的话关注一下。会对你有更多的帮助。
每天都会不定时更新哦 >人< 。