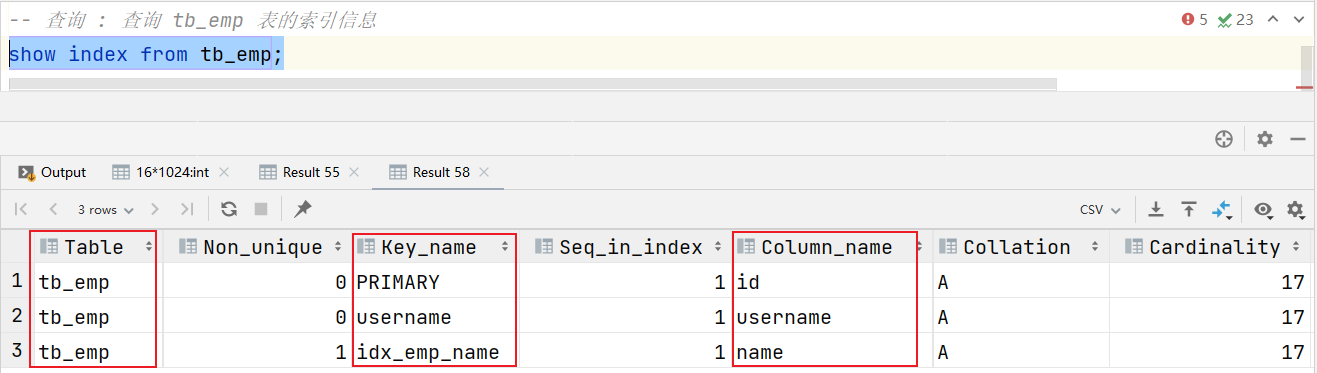
目录
set的key搜索树模拟
set内置的find与count函数
编辑
set的lower_bound与upper_bound内置函数、
map的key-value搜索树模拟
通过不同的方式向map中插入键值对。
map的遍历
编辑
map的operator的 [ ] 用法
关于map与set用法的几个例题
例题1: 随机链表的复制 leetcode 138leetcode138
编辑例题2: leetcode349两个数组的交集 set去重排序的应用场景
编辑
例题3: leetcode692 前k个高频单词 top-K问题
set的key搜索树模拟
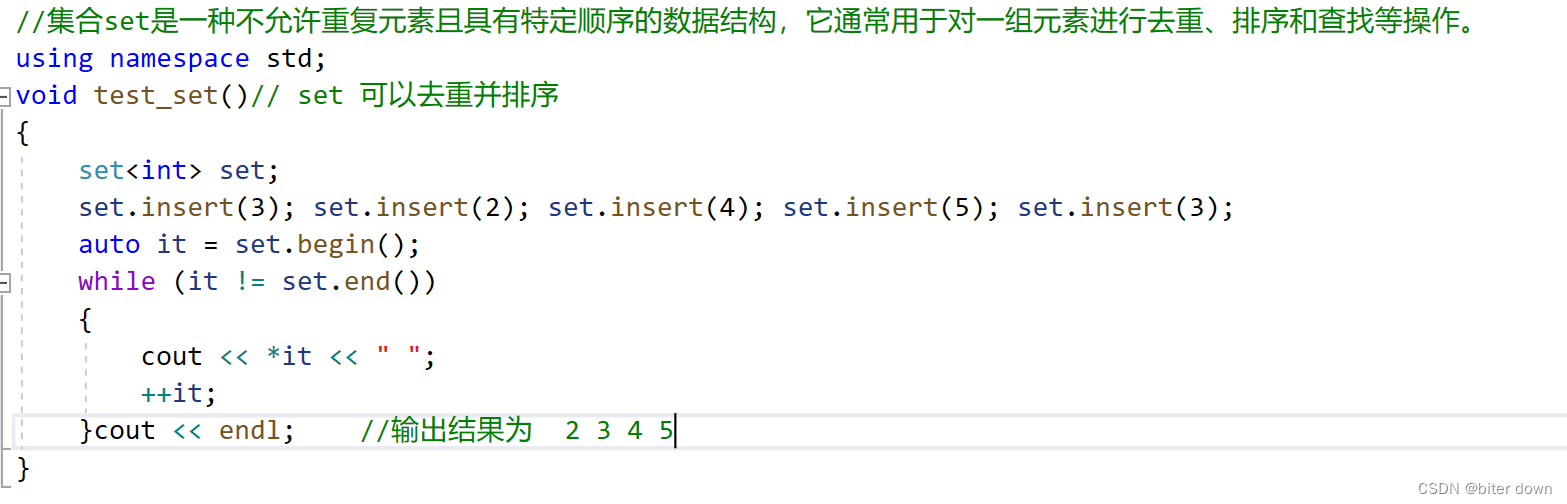
set的数据结构是一个集合类型,其内部元素保持有序。当在代码中多次插入同一个元素时,该元素会被重复出现,但在set中它是唯一的。此代码片段输出的是数字2, 3, 4和5的顺序排列。
set内置的find与count函数
以下代码是一个测试函数,用于演示set集合中的find函数和count函数的使用。
首先,创建了一个名为set的set集合对象。 接着,通过insert函数向set集合中插入一些整数元素:3、2、4、5。
然后,使用find函数来查找是否存在值为5的元素。如果查找成功(即返回的迭代器不等于end()),则打印“have finded”。 再使用count函数来统计值为5的元素在set集合出现的次数。如果出现次数大于0,则打印“have finded”。

set的lower_bound与upper_bound内置函数、
lower_bound函数返回的是第一个大于或等于给定值的元素迭代器,而upper_bound函数返回的是第一个大于给定值的元素迭代器。erase函数接受两个迭代器作为参数,表示要删除的范围,这两个迭代器通常用于表示一个范围的开始和结束。
map的key-value搜索树模拟
通过不同的方式向map中插入键值对。
- 使用
pair类型的构造函数创建了一个键值对kv1,其中键为"insert",值为"插入",然后将这个键值对插入到map中。 - 使用匿名的
pair对象直接插入了一个键值对,其中键为"sort",值为"排序"。 - 使用
make_pair函数创建了一个键值对,并将其插入到map中,键为"stirng",值为"string"。 - 使用花括号语法(C++11引入的初始化列表)创建了一个键值对,并将其插入到
map中。

通过这些方式,我们可以将不同的键值对插入到map中。
map的遍历

map的operator的 [ ] 用法
[ ]的operator,map会创建方括号“[ e ]”中key为e的二叉树结点,并返回存在key结点的value值

这段代码主要使用了C++的map数据结构,并且展示了如何使用operator[]进行查找和插入操作。下面是对这段代码的逐行解释:

关于map与set用法的几个例题
例题1: 随机链表的复制 leetcode 138leetcode138
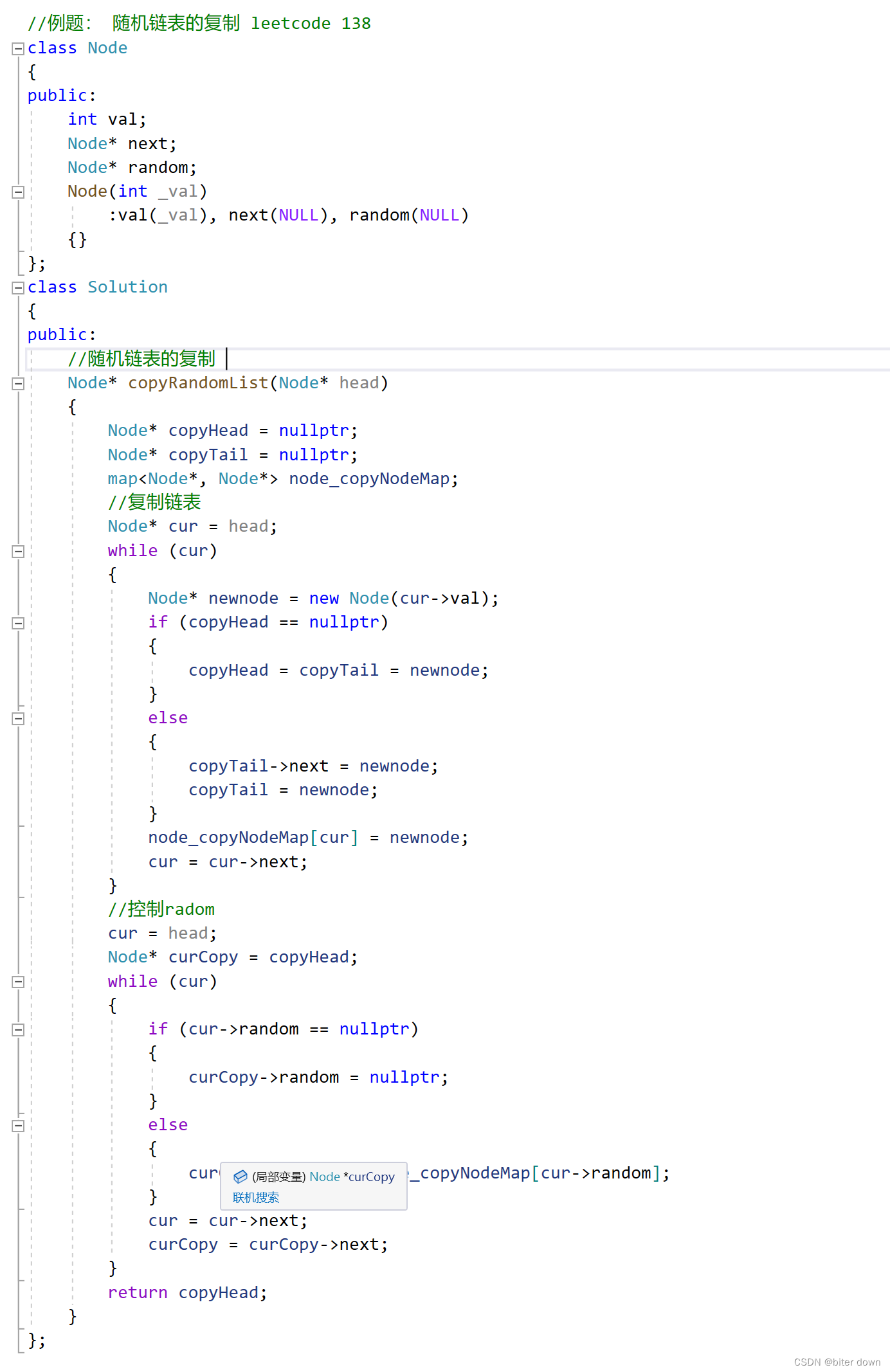
功能:复制一个带有随机指针的链表。这里使用了类和类的成员函数,包括一个节点类和一个解决方案类。
代码中的主要函数是copyRandomList,它接收一个链表的头节点作为输入,并返回复制后的链表的头节点。这个函数主要做了以下几件事:
- 创建一个新的节点,并将原链表的节点值复制到新节点中。同时,它也存储了原节点和新节点的映射关系,以便在后面的步骤中查找。
- 如果复制的头节点为空,那么就将复制的头节点和尾节点设置为新节点。否则,就将新节点添加到尾节点的后面。
- 遍历原链表,对于每个节点,如果它有随机指针,就查找对应的新节点,并将新节点的随机指针指向原节点的随机指针。
这个函数的主要目的是复制链表的结构,同时保留随机指针的功能。对于有随机指针的节点,它在复制链表中也会有一个对应的随机指针。这样就可以实现复制链表并保留原有节点的功能。
其中map来存储原节点和新节点的映射关系,以避免重复创建相同的节点。在代码中使用了node_copyNodeMap变量来存储这个映射关系。
 例题2: leetcode349两个数组的交集 set去重排序的应用场景
例题2: leetcode349两个数组的交集 set去重排序的应用场景
以下代码是一个解决leetcode 349题目的解法,题目要求找出两个数组的交集。
首先,将数组nums1和nums2转换为set容器,以便去除重复元素并进行排序。然后定义一个空的vector容器用于存储交集结果。
通过循环遍历setNums1容器中的每个元素,判断其是否存在于setNums2容器中。如果存在,则将该值添加到vector容器中。
最后返回vector容器作为结果。
该解法利用了set容器的特性,即自动去重并有序。可以提供相对高效的解决方案。

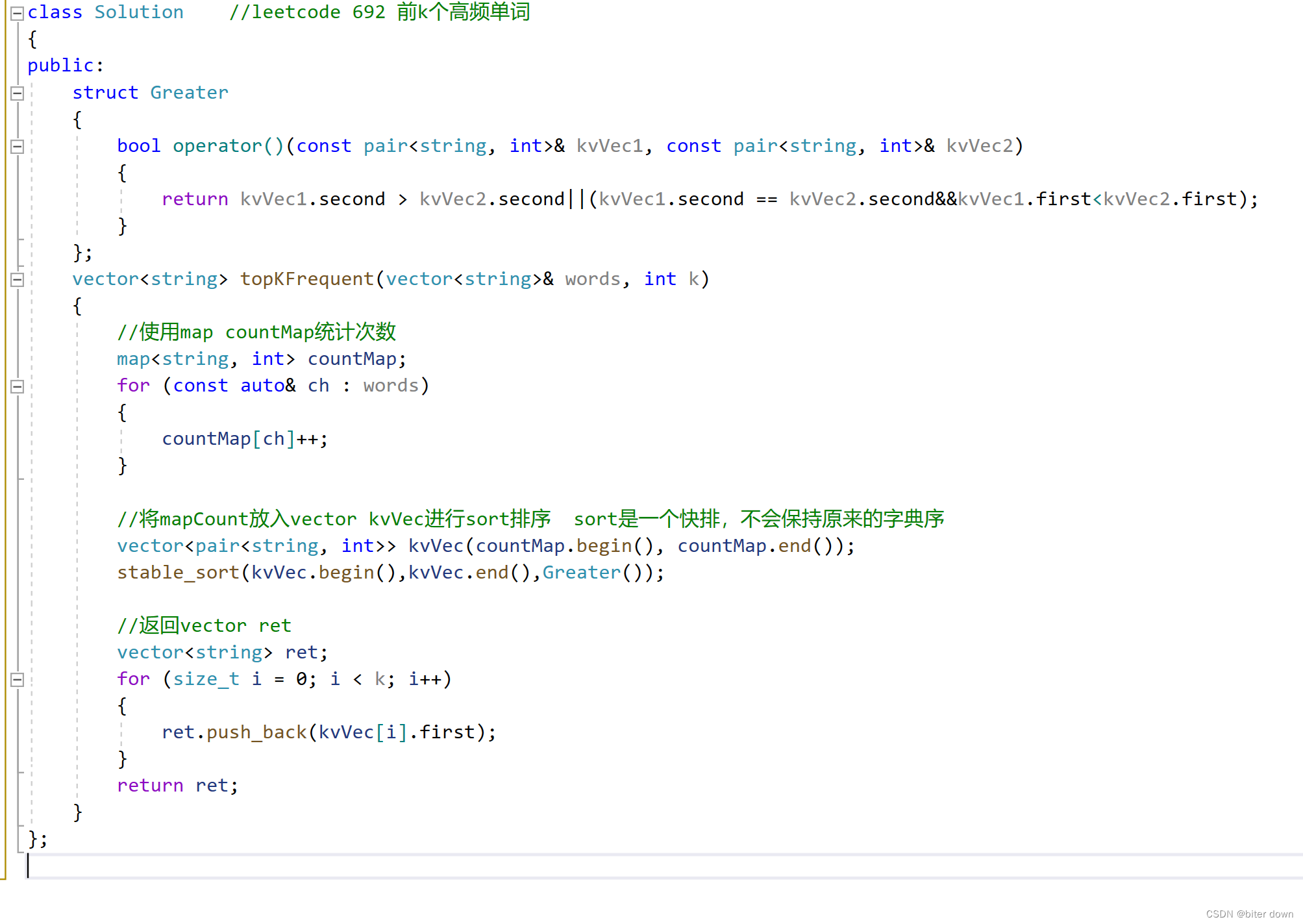
例题3: leetcode692 前k个高频单词 top-K问题
该代码是解决LeetCode上问题692的解题代码,目标是找出给定字符串列表现频率最高的前k个单词。
首先,定义了一个结构体Greater,用于比较两个键值对(pair)。比较规则为按照键值对的值降序排列,如果值相同则按照键的字典序升序排列。
然后,创建一个map类型的countMap,用于统计每个单词在列表¥¥现的次数。遍历接收到的words列表,使用map的特性将每个单词作为键,累加次数作为值保存起来。
接下来,将countMap中的键值对复制到一个vector类型的kvVec中。这里使用stable_sort函数对kvVec进行排序,排序规则为使用Greater结构体中定义的比较方式。
最后,将排序后的kvVec的前k个单词提取出来,放入vector ret中作为结果返回。
整体思路是通过map来统计单词出现的次数,然后通过对map中的键值对进行排序得到频率最高的前k个单词,并返回这些单词的列表。