相关概念
- 排序:使一串记录,按照其中某个或某些关键字的大小,递增或递减的排列起来。
- 稳定性:它描述了在排序过程中,相等元素的相对顺序是否保持不变。假设在待排序的序列中,有两个元素a和b,它们的值相等,并且在排序前a在b前面。如果在排序后,a仍然在b前面,那么就称该排序算法是稳定的;反之,如果排序后a跑到了b后面,那么这个排序算法就是不稳定的。
- 内部排序:当排序的数据量非常小时,待排序的数据全部存放在计算机的内存中,并且排序操作也在内存里完成。
- 外部排序:当待排序的数据量非常大,无法全部存入内存时,就需要借助外部存储设备(如硬盘、磁带等)来辅助完成排序。外部排序通常将数据分成多个较小的部分,先把这些部分依次读入内存进行内部排序,生成有序的子文件,再把这些有序子文件合并成一个最终的有序文件。
任何排序都可以分为单趟排序和多趟排序。将排序拆解开来,更方便理解。
插入排序
直接插入排序
直接插入排序的思想是:将插入的元素按大小逐一插入到已经排序好的有序序列中,直到所有的元素都插入完成,得到一个新的有序序列。
// 打印
void PrintArr(int* a, int n)
{
assert(a);
for (int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
printf("\n");
}单趟排序的思路:假设一个序列已经排序好了,现在要插入一个元素,怎么插入呢?看下面的过程。

// 单趟
// 要比较的最后一个元素的下标
int end;
// 要插入的新元素,先保存起来
int temp = a[end+1];
while(end >= 0)
{
// 如果比要比较的元素小,则将这个元素后移
if(tmp < a[end])
{
a[end+1] = a[end];
// 继续跟前一个元素比较
end--;
}
else
{
break;
}
}
// 走到这,1.tmp比要比较的元素大 2.比较完了,tmp比第一个元素还小,end为-1
a[end+1] = tmp;多趟排序的思路:那么,我们就可以将乱序序列的第一个元素看做是一个已经排序好的序列,将它的后一个元素插入到这个排序好的序列中,这两个元素就是新的排序好的序列,再将后一个元素插入到这个已经排序好的序列,依次类比。直到最后一个元素插入到已经排序好的序列中,这整个乱序序列就变成有序序列了。
void InsertSort(int* a, int n)
{
assert(a);
//多趟排序
for (int i = 0; i < n - 1; i++) // 注意:i结束条件为最后一个元素的前一个元素下标
{
// 单趟
// 要比较的最后一个元素的下标
int end = i;
// 要插入的新元素,先保存起来
int tmp = a[end + 1];
// 把end+1的元素插入到[0,end]
while (end >= 0)
{
// 如果比最后一个元素小,则将最后一个元素后移
if (tmp < a[end])
{
a[end + 1] = a[end];
end--;
}
else
{
break;
}
}
// 走到这,1.tmp比要比较的元素大 2.比较完了,比第一个元素还小,end为-1
a[end + 1] = tmp;
}
}我们来测试一下。
void TestInsertSort()
{
int a[] = {2, 1, 4, 3, 6, 7, 0, 5, 10, 8, 9};
PrintArr(a, sizeof(a) / sizeof(a[0]));
InsertSort(a, sizeof(a) / sizeof(a[0]));
PrintArr(a, sizeof(a) / sizeof(a[0]));
}
int main()
{
TestInsertSort();
return 0;
}
特性总结
- 元素集合越接近有序,直接插入排序算法的时间效率越高。
- 时间复杂度:O(N^2)。
- 空间复杂度:O(1)。
- 稳定性:稳定。
希尔排序
也叫缩小增量排序。对直接插入排序的优化。直接插入排序在序列有序或接近有序的情况下效率可以达到O(N),而在逆序或接近逆序的情况下效率就是O(N^2),所以效率时好时坏。
希尔排序是如何对直接插入排序进行优化的呢?
- 预排序。先将数组接近有序。
- 直接插入排序。数组接近有序,再直接插入排序。
预排序:将间距为gap的值分为一组,分别对每个组进行插入排序。

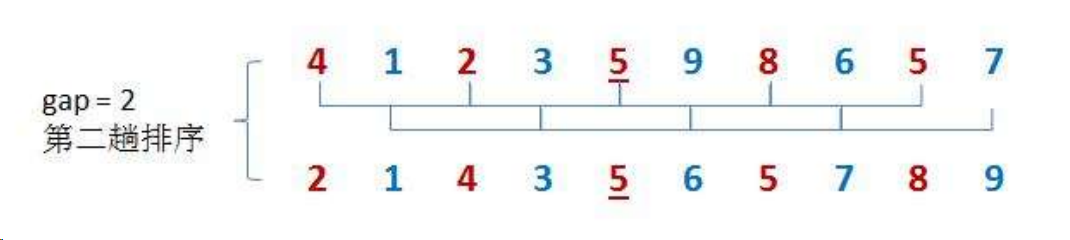

我们先实现一组的直接插入排序。
int gap;
int end;
int tmp = a[end+gap];
while(end >= 0)
{
if(tmp < a[end])
{
a[end+gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end+gap] = tmp;其实,就相当于是插入排序,只不过插入排序gap为1。
多组是怎么排序的呢?一组一组排吗?不是的,多组并排,非常巧妙。
int gap;
for (int i = 0; i < n - gap; i++) // i < n-gap很巧妙
{
int end = i;
int tmp = end + gap;
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}gap越大,前面大的数据可以越快到后面,后面小的数,可以越快到前面,但是gap越大,越不接近有序。gap=1时,就是直接插入排序。
那gap设置为几呢?希尔是这样设计的:gap=n;gap = n / gap + 1;只要gap大于1就是预排序,gap等于1为直接插入排序。
void ShellSort(int* a, int n)
{
assert(a);
int gap = n;
// gap大于1预排序 ==1直接插入排序
while (gap > 1)
{
//预排序:把间距为gap的值分为一组 进行插入排序。+1保证最后是直接插入排序
gap = gap / 3 + 1;
//多组并排
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tmp = end + gap;
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
// 测试用的打印
PrintArr(a, n);
}
}我们来测试一下。
void TestInsertSort()
{
int a[] = {2, 1, 4, 3, 6, 7, 0, 5, 10, 8, 9};
PrintArr(a, sizeof(a) / sizeof(a[0]));
InsertSort(a, sizeof(a) / sizeof(a[0]));
PrintArr(a, sizeof(a) / sizeof(a[0]));
}
void TestShellSort()
{
int a[] = { 19,30,11,20,1,2,5,7,4,8,6,26,3,29 };
PrintArr(a, sizeof(a) / sizeof(a[0]));
ShellSort(a, sizeof(a) / sizeof(a[0]));
PrintArr(a, sizeof(a) / sizeof(a[0]));
}
下面我们来测试一下直接插入排序和希尔排序的效率。
void TestOp()
{
const int N = 100000;
srand(time(0));
int* a1 = (int*)malloc(sizeof(int) * N);
int* a2 = (int*)malloc(sizeof(int) * N);
for (int i = 0; i < N; i++)
{
a1[i] = rand();
a2[i] = a1[i];
}
int begin1 = clock();
InsertSort(a1, N);
int end1 = clock();
int begin2 = clock();
ShellSort(a2, N);
int end2 = clock();
printf("InsertSort time: %d milliseconds\n", end1 - begin1);
printf("ShellSort time: %d milliseconds\n", end2 - begin2);
free(a1);
free(a2);
}
int main()
{
TestOp();
return 0;
}
特性总结
- 希尔排序是对直接插入排序的优化。
- 当gap>1时都是预排序,目的是让序列接近有序。当gap==1时,数组已经接近有序了,直接插入排序,可以达到优化效果。
- 希尔排序的时间复杂度不好计算,因为gap的取值方法有很多。大概为O(N^1.25)~O(1.6 * N^1.25)。
- 稳定性:不稳定。
选择排序
直接选择排序
每一次都从待排序序列中找出最小元素与最大元素,放在序列的起始位置和末尾位置,直到最后所有元素排完。
void SelectSort(int* a, int n)
{
assert(a);
int begin = 0;
int end = n-1;
while (begin < end)
{
int mini = begin; // 最小元素的下标
int maxi = begin; // 最小元素的下标
for (int i = begin + 1; i <= end; i++)
{
//在[begin,end]找最小值和最大值的下标
if (a[i] < a[mini])
{
mini = i;
}
if (a[i] > a[maxi])
{
maxi = i;
}
}
Swap(&a[begin], &a[mini]);
// 如果begin和maxi的位置重叠,最大值已经被换走了,所以maxi的值需要修正
if (begin == maxi)
{
maxi = mini;
}
Swap(&a[end], &a[maxi]);
begin++;
end--;
}
}来测试一下。
void TestSelectSort()
{
int a[] = { 9,1,2,5,7,4,8,6,3,5 };
PrintArr(a, sizeof(a) / sizeof(a[0]));
SelectSort(a, sizeof(a) / sizeof(a[0]));
PrintArr(a, sizeof(a) / sizeof(a[0]));
}
int main()
{
TestSelectSort();
return 0;
}

特性总结
- 效率不高。
- 时间复杂度:O(N^2)。
- 空间复杂度:O(1)。
- 稳定性:不稳定。
堆排序
利用堆来进行选择排序,排升序,建大堆;排降序,建小堆。关于堆排序可以看下面这篇文章。
《二叉树:二叉树的顺序结构->堆》
// 大堆向下调整算法
// 注意:调整的树的左右子树必须为大堆
void AdjustDown(int* a, int n, int root)
{
// 父亲
int parent = root;
// 1.选出左右孩子较大的孩子跟父亲比较
// 默认较大的孩子为左孩子
int child = parent * 2 + 1;
// 终止条件孩子到叶子结点最后跟父亲比一次
while (child < n)
{
// 2.如果右孩子大于左孩子,则较大的孩子为右孩子
if (child + 1 < n && a[child + 1] > a[child])
{
child++;
}
// 3.如果孩子大于父亲,则跟父亲交换
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* a, int n)
{
assert(a);
//建堆 排升序 建大堆
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
int end = n - 1;
while (end >= 1)
{
// 交换堆顶与最后一个元素
Swap(&a[0], &a[end]);
// 向下调整
AdjustDown(a, end, 0);
end--;
}
}来测试一下。
void TestHeapSort()
{
int a[] = { 9,1,2,5,7,4,8,6,3,5 };
PrintArr(a, sizeof(a) / sizeof(a[0]));
HeapSort(a, sizeof(a) / sizeof(a[0]));
PrintArr(a, sizeof(a) / sizeof(a[0]));
}
int main()
{
TestHeapSort();
return 0;
}
特性总结
- 使用堆来选数,效率高。
- 时间复杂度:O(NlogN)。
- 空间复杂度:O(1)。
- 稳定性:不稳定。
交换排序
根据序列中两个键值的比较结果来对换这两个记录在序列中的位置。特点是:键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
冒泡排序
void BubbleSort(int* a, int n)
{
assert(a);
int i = 0;
// 整体
for (int j = 0; j < n; j++)
{
// 单趟
// 判断是否有序,如果有序,不用比较了,直接退出
int flag = 0;
for (i = 0; i < n-1-j; i++)
{
if (a[i] > a[i + 1])
{
// 交换
Swap(&a[i], &a[i + 1]);
flag = 1;
}
}
if (flag == 0)
{
break;
}
}
}来测试一下。
void TestBubbleSort()
{
//int a[] = { 0,5,7,6,8,9,3,2,4,1 };
//int a[] = { 0,9,1,2,3,4,5,6,7,8 };
int a[] = { 9,8,7,6,5,4,3,2,1,0 };
PrintArr(a, sizeof(a) / sizeof(a[0]));
BubbleSort(a, sizeof(a) / sizeof(a[0]));
PrintArr(a, sizeof(a) / sizeof(a[0]));
}
int main()
{
TestSelectSort();
return 0;
}
特性总结
- 非常容易理解。
- 时间复杂度:O(N^2)。
- 空间复杂度:O(1)。
- 稳定性:稳定。
快速排序
是一种二叉树结构的交换排序方法。取待排序元素序列中的某元素key作为基准值,按照该key,将排序集合分为两个子序列,左子序列中所有元素都小于key,右子序列所有元素都大于key。然后左子序列和右子序列分别重复该过程,直到所有的元素都到相应的位置上。
通常取key为最右边的值,或最左边的值。
左右指针法


这样,比key小的值,都换到前面了,比key大的值都换到后面了,而key在正确位置。
来看单趟排序是怎么排的。
// 单趟
int PartSort(int* a, int begin, int end)
{
// key下标
// 选最后一个值作为key
int keyIndex = end;
while (begin < end)
{
// 让左边先走
// 左边找比key大的
while (begin < end && a[begin] <= a[keyIndex]) // 注意:为>=,不然会造成死循环,例如 3 5 4 7 1 2 8 5 7 5
{
begin++;
}
// 右边再走
// 右边找比key小的
while (begin < end && a[end] >= a[keyIndex]) // 注意:为>=,不然会造成死循环,例如 3 5 4 7 1 2 8 5 7 5
{
end--;
}
// 交换
// 左边的大值就交换到后边了,右边的小值就交换到前面了
Swap(&a[begin], &a[end]);
}
// 走到这,代表相遇了,相遇的位置的值和key交换
// 交换完之后,不管左边和右边是否是有序的,总之,key的位置到了正确的位置
// 如果选最后一个值作为key,让左边先走可以保证相遇的位置的值是比key大的
Swap(&a[begin], &a[keyIndex]);
// 返回相遇位置
return begin;
}多趟排序,将左子序列和右子序列递归重复该过程即可完成整个排序。
// 多趟
void QuickSort(int* a, int left, int right)
{
// 递归结束条件
if (left >= right)
return;
// 此时相遇位置的值已经是正确的位置
int div = PartSort(a, left, right);
PrintArr(a + left, right - left + 1);
// 用于打印测试的
printf("[%d, %d]%d[%d, %d]\n", left, div - 1, div, div + 1, right);
// 递归的思想,让该位置的左边和右边按照同样的思想进行排序
QuickSort(a, left, div - 1);
QuickSort(a, div + 1, right);
}来测试一下。
void TestQuickSort()
{
int a[] = { 6,1,2,7,9,3,4,8,10,5 };
// 如果序列本来就有序
// int a[] = { 1,2,3,4,5,6,7,8,9};
PrintArr(a, sizeof(a) / sizeof(a[0]));
QuickSort(a, 0,sizeof(a) / sizeof(a[0])-1);
PrintArr(a, sizeof(a) / sizeof(a[0]));
}
int main()
{
TestQuickSort();
return 0;
}
可以看到递归的整个过程。
再来测试一下。
void TestQuickSort()
{
// int a[] = { 6,1,2,7,9,3,4,8,10,5 };
// 如果序列本来就有序
int a[] = { 1,2,3,4,5,6,7,8,9};
PrintArr(a, sizeof(a) / sizeof(a[0]));
QuickSort(a, 0,sizeof(a) / sizeof(a[0])-1);
PrintArr(a, sizeof(a) / sizeof(a[0]));
}
int main()
{
TestQuickSort();
return 0;
}
快速排序的最好情况:如果每次递归取key值都能取到中位数,排序的效率是最高的,因为每次都能平均将左子序列和右子序列划分开。时间复杂度为O(NlogN)。

快速排序的最坏情况:每次递归取key值都是最大值或最小值,排序的效率是最差的,也就是序列在有序或接近有序的情况下,每次划分都会产生一个空的子序列和一个长度仅比原序列少 1 的子序列。时间复杂度为O(N^2)。

那么,实际中,我们无法保证取到的key是中位数,但是,是不是可以考虑不要取到最大的或最小的。
三位数取中
三位数取中,能避免取到最大值和最小值。如果在最坏的情况有序的情况下,取序列中间的元素作为key值,与最后的元素交换,还是最右边的值作为key值,此时就变成了最好的情况。如果是在其他,也能避免取到最大值和最小值。也就是说三位数取中,让最坏的情况不再出现,时间复杂度综合为O(NlogN)。
// 三位数选中
int GetMidIndex(int* a,int begin,int end)
{
int midIndex = (begin + end) / 2;
if (a[begin] > a[midIndex])
{
// begin > mid mid > end
if (a[midIndex] > a[end])
{
return midIndex;
}
// begin > mid mid<end
else
{
if (a[begin] < a[end])
{
return begin;
}
else
{
return midIndex;
}
}
}// begin <mid
else
{
if (a[midIndex] < a[end])
{
return midIndex;
}// begin<mid mid>end
else
{
if (a[begin] < a[end])
{
return end;
}
else
{
return begin;
}
}
}
}
// 单趟
int PartSort1(int* a, int begin, int end)
{
// 三位数选中 避免最坏情况
int midIndex = GetMidIndex(a, begin, end);
Swap(&a[midIndex], &a[end]);
// key下标
// 选最后一个值作为key
int keyIndex = end;
while (begin < end)
{
// 让左边先走
// 左边找比key大的
while (begin < end && a[begin] <= a[keyIndex]) // 注意:为>=,不然会造成死循环,例如 3 5 4 7 1 2 8 5 7 5
{
begin++;
}
// 右边再走
// 右边找比key小的
while (begin < end && a[end] >= a[keyIndex]) // 注意:为>=,不然会造成死循环,例如 3 5 4 7 1 2 8 5 7 5
{
end--;
}
// 交换
// 左边的大值就交换到后边了,右边的小值就交换到前面了
Swap(&a[begin], &a[end]);
}
// 走到这,代表相遇了,相遇的位置的值和key交换
// 交换完之后,不管左边和右边是否是有序的,总之,key的位置到了正确的位置
// 如果选最后一个值作为key,让左边先走可以保证相遇的位置的值是比key大的
Swap(&a[begin], &a[keyIndex]);
// 返回相遇位置
return begin;
}
// 多趟
void QuickSort(int* a, int left, int right)
{
// 递归结束条件
if (left >= right)
return;
// 此时相遇位置的值已经是正确的位置
int div = PartSort1(a, left, right);
// PrintArr(a + left, right - left + 1);
// 用于打印测试的
// printf("[%d, %d]%d[%d, %d]\n", left, div - 1, div, div + 1, right);
// 递归的思想,让该位置的左边和右边按照同样的思想进行排序
QuickSort(a, left, div - 1);
QuickSort(a, div + 1, right);
}挖坑法
取最右边(也可以左边的)的值作为key。该位置为坑,左边找比key大的元素,填入到坑里,该元素的位置成为新的坑;右边找比坑小的元素,填入到新坑里,该元素位置成为新的坑,直到相遇,将key填入到新坑。此时key的左边就是比key小的,右边就是比key大的。再将该key左边的序列和右边的序列迭代重复此操作即可。


// 单趟
int PartSort2(int* a, int begin, int end)
{
assert(a);
// 三位数选中 避免最坏情况
int midIndex = GetMidIndex(a, begin, end);
Swap(&a[midIndex], &a[end]);
// 最后一个元素为坑
// 坑的意思就是这的值被拿走了,可以覆盖新的值
int key = a[end];
while (begin < end)
{
// begin找大的放进坑 begin成为新坑
while (begin < end && a[begin] <= key)
{
begin++;
}
a[end] = a[begin];
// end找小的放进新坑 end成为新坑
while (begin < end && a[end] >= key)
{
end--;
}
a[begin] = a[end];
}
//把最后一个元素放到相遇位置
a[begin] = key;
return begin;
}
// 多趟
void QuickSort(int* a, int left, int right)
{
// 递归结束条件
if (left >= right)
return;
// 此时相遇位置的值已经是正确的位置
// 左右指针法
// int div = PartSort1(a, left, right);
// 挖坑法
int div = PartSort2(a, left, right);
// PrintArr(a + left, right - left + 1);
// 用于打印测试的
// printf("[%d, %d]%d[%d, %d]\n", left, div - 1, div, div + 1, right);
// 递归的思想,让该位置的左边和右边按照同样的思想进行排序
QuickSort(a, left, div - 1);
QuickSort(a, div + 1, right);
}前后指针法

// 单趟
int PartSort3(int* a, int begin, int end)
{
assert(a);
//三位数选中 避免最坏情况
int midIndex = GetMidIndex(a, begin, end);
Swap(&a[midIndex], &a[end]);
int keyIndex = end;
int prev = begin - 1;
int cur = begin;
while (cur < end)
{
if (a[cur] < a[keyIndex] && ++prev != a[cur]) // ++prev如果和cur相等 自己跟自己交换不用交换
{
//交换
Swap(&a[prev], &a[cur]);
}
cur++;
}
Swap(&a[++prev], &a[keyIndex]);
return prev;
}
// 多趟
void QuickSort(int* a, int left, int right)
{
// 递归结束条件
if (left >= right)
return;
// 此时相遇位置的值已经是正确的位置
// 左右指针法
// int div = PartSort1(a, left, right);
// 挖坑法
// int div = PartSort2(a, left, right);
// 前后指针法
int div = PartSort3(a, left, right);
// PrintArr(a + left, right - left + 1);
// 用于打印测试的
// printf("[%d, %d]%d[%d, %d]\n", left, div - 1, div, div + 1, right);
// 递归的思想,让该位置的左边和右边按照同样的思想进行排序
QuickSort(a, left, div - 1);
QuickSort(a, div + 1, right);
}快速排序就像一颗二叉树一样,选出一个key分出左区间和右区间,左区间的值都比key小,右区间的值都比key大,再再左区间中找出一个key分出左区间和右区间,在右区间中找出一个key分出左区间和右区间......
快速排序还有可以优化的地方,当不断的递归划分区间,区间已经数据很少时,不用再递归方式划分区间排序了,使用插入排序去排序,减少整体的递归次数。
// 多趟
void QuickSort(int* a, int left, int right)
{
// 递归结束条件
if (left >= right)
return;
// 此时相遇位置的值已经是正确的位置
// 左右指针法
// int div = PartSort1(a, left, right);
// 挖坑法
// int div = PartSort2(a, left, right);
// 前后指针法
int div = PartSort3(a, left, right);
// PrintArr(a + left, right - left + 1);
// 用于打印测试的
// printf("[%d, %d]%d[%d, %d]\n", left, div - 1, div, div + 1, right);
// 区间大于十个元素用快速排序
if ((right - left + 1) > 10)
{
int div = PartSort3(a, left, right);
// 递归的思想,让该位置的左边和右边按照同样的思想进行排序
QuickSort(a, left, div - 1);
QuickSort(a, div + 1, right);
}
// 小于十个元素用插入排序
else
{
InsertSort(a + left, right - left + 1);
}
}特性总结
- 快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序。
- 时间复杂度:O(NlogN)。
- 空间复杂度:O(1),使用栈模拟则为O(logN)。
- 稳定性:不稳定。







![[蓝桥杯 2023 省 A] 网络稳定性](https://i-blog.csdnimg.cn/direct/57b39206c1854f50b9f637d4a3239a53.png)