(一)串的基本概念
串(string或字符串)是由零个或多个字符组成的有限序列,一般记为:s=′a1a2…a′n(n≥0)
其中,s是串的名称,用单括号括起来的字符序列是串的值; ai(1≤i≤n)ai(1≤i≤n)可以是字母、数字或其他字符;串中字符的数目n称为串的长度。零个字符的串称为空串,它的长度为0。
串中任意个连续的字符组成的子序列称为该串的子串。包含子串的串相应的称为主串。通常称字符在序列中的序号为该字符在串中的位置子串在主串中的位置则以子串的第一个字符在主串的位置来表示。
两个串是相等时当且仅当这两个串的值相等。即只有当两个串的长度相等且各个对应位置的字符都相等时才相等。
由一个或多个空格组成的串‘ ’叫做空格串,它的长度为串中空格字符的个数。为了清楚起见,以后我们用符号“ ”来表示空串。
串的表示
1.定长顺序存储表示
#define MAXSIZE 255
typedef struct
{
char ch[MAXSIZE];
int length;
}SString;这种存储方式类似于线性表的顺序存储,用地址连续的存储单元存储字符序列。串的长度可以在预定长度范围内随意取,超过预定长度的值被舍去。
2.堆分配存储表示
typedef struct
{
char *ch;
int length;
}HString;这种存储方式以一组地址连续的存储单元存放串值,但存储空间的分配是动态进行的。例如在C语言中用malloc()和free()来动态管理存储空间。
3.块链存储表示
#define CHUNKSIZE 80
typedef struct Chunk
{
char ch[CHUNKSIZE];
struct Chunk *next;
}Chunk;
typedef struct
{
Chunk *head,*tail; /* 串的头和尾指针 */
int curlen; /* 串的当前长度 */
}LString;和线性表的链式存储结构类似,串值也可以用链表存储。在这里要注意的是定义的结点可存放字符的长度可不同。
(三)串的基本操作
一般来说,就是增删查改+子串处理,子串比较,增加子串,取子串等
#include <stdio.h>
#include <stdlib.h>
#define MAXSIZE 1024
typedef struct
{
char memory[MAXSIZE];
int curSize; //万金油参数
}string, * LPSTR;
//创建一个串
LPSTR createStr(const char* str)
{
LPSTR pStr = (LPSTR)malloc(sizeof(string));
if (pStr == NULL)
{
return NULL;
}
for (int i = 0; i < MAXSIZE; i++)
{
pStr->memory[i] = '\0';
}
int count = 0;
while (str[count] != '\0')
{
pStr->memory[count] = str[count];
count++;
}
pStr->curSize = count;
return pStr;
}
//串的插入 在当前串中插入多个元素
//123456
//xxx
//xxx123456
//1xxx23456
//123456xxx
void insertStr(LPSTR pStr, const char* str, int len, int pos)
{
//pos = pos - 1;
if (pos < 0 || pos >= MAXSIZE)
{
printf("下标有误,无法插入!\n");
return;
}
if (pStr->curSize + len >= MAXSIZE)
{
printf("太长,无法插入!\n");
return;
}
if (pos > pStr->curSize) //直接放在原来串的后面
{
for (int i = 0; i < len; i++)
{
pStr->memory[pStr->curSize++] = str[i];
}
}
else
{
//1.腾位置
for (int i = pStr->curSize; i >= pos; i--)
{
pStr->memory[len + i] = pStr->memory[i];
}
//2.插入新串
for (int i = 0; i < len; i++)
{
pStr->memory[pos + i] = str[i];
}
pStr->curSize += len;
}
}
//串删除
//不做匹配删除,只做区间删除
void deleteStr(LPSTR pStr, int start, int end)
{
if (start > end || end > pStr->curSize || start <= 0)
{
printf("区间有误\n");
return;
}
int count = end - start + 1;
for (int i = end, j = start - 1; i < pStr->curSize; i++, j++)
{
pStr->memory[j] = pStr->memory[i];
}
//把后面的东西置空
for (int i = pStr->curSize; i >= pStr->curSize - count; i--)
{
pStr->memory[i] = '\0';
}
pStr->curSize -= count;
}
//串连接
LPSTR concatStr(LPSTR pStr, const char* str,int len)
{
LPSTR pstr = (LPSTR)malloc(sizeof(string));//新的串接收
int cout = 0;//新的串长度
for (int i = 0; i < pStr->curSize; i++)
{
pstr->memory[i] = pStr->memory[i];
cout++;
}
for (int i =0; i < len-1; i++)
{
pstr->memory[cout] = str[i];
cout++;
}
pstr->curSize = cout;
return pstr;
}
//串的打印的
void printStr(LPSTR pStr)
{
for (int i = 0; i < pStr->curSize; i++)
{
printf("%c", pStr->memory[i]);
}
printf("\n");
/*
%s
puts
*/
}
int main()
{
char name[20] = "bbbm";
LPSTR pStr = createStr("ILoveyou"); //8 0-7
printStr(concatStr(pStr, name, 5));
printf("pStr->curSize:%d\n", pStr->curSize);
printStr(pStr);
insertStr(pStr, "xxx", 3, 0);
printStr(pStr);
printf("pStr->curSize:%d\n", pStr->curSize);
deleteStr(pStr, 1, 3);
printStr(pStr);
printf("pStr->curSize:%d\n", pStr->curSize);
return 0;
}(三)串的各种匹配模式BF算法和KMP算法
BF算法
相关知识点:
BF算法,即暴力(Brute Force)算法,是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符;若不相等,则比较S的第二个字符和T的第一个字符,依次比较下去,直到得出最后的匹配结果。一力破百巧
实例如下:

具体代码:
#include <stdio.h>
#include <stdlib.h>
#define MAXSIZE 1024
typedef struct
{
char memory[MAXSIZE];
int curSize; //万金油参数
}string, * LPSTR;
//创建一个串
LPSTR createStr(const char* str)
{
LPSTR pStr = (LPSTR)malloc(sizeof(string));
if (pStr == NULL)
{
return NULL;
}
for (int i = 0; i < MAXSIZE; i++)
{
pStr->memory[i] = '\0';
}
int count = 0;
while (str[count] != '\0')
{
pStr->memory[count] = str[count];
count++;
}
pStr->curSize = count;
return pStr;
}
bool Index(LPSTR Str, LPSTR str )
{
int i = 0, j = 0;//用来保存Str和str长度的
while (i<Str->curSize&& j<str->curSize)
{
if (Str->memory[i] == str->memory[j])
{
i++;
j++;//比较第二个元素
}
else
{
i = i - j + 1;//主串从头开始匹配
j = 0;//子串从头开始
}
}
if (j >= str->curSize) return true;
else
{
return false;
}
}
//普通的串要传长度
bool Index1(LPSTR* Str, const char* str,int len)
{
return false;
}
int main()
{
LPSTR pStr = createStr("ababcababa");
LPSTR pstr = createStr("abacc");
LPSTR pstr1 = createStr("ababa");
printf("匹配%s\n", Index(pStr, pstr) ? "成功" : "不成功");
printf("匹配%s\n", Index(pStr, pstr1) ? "成功" : "不成功");
return 0;
}
KMP算法
相关知识点:
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个next()函数实现,函数本身包含了模式串的局部匹配信息。KMP算法的时间复杂度为O(m+n)。
详解KMP:第一次应用到BF算法,一个一个第比较。
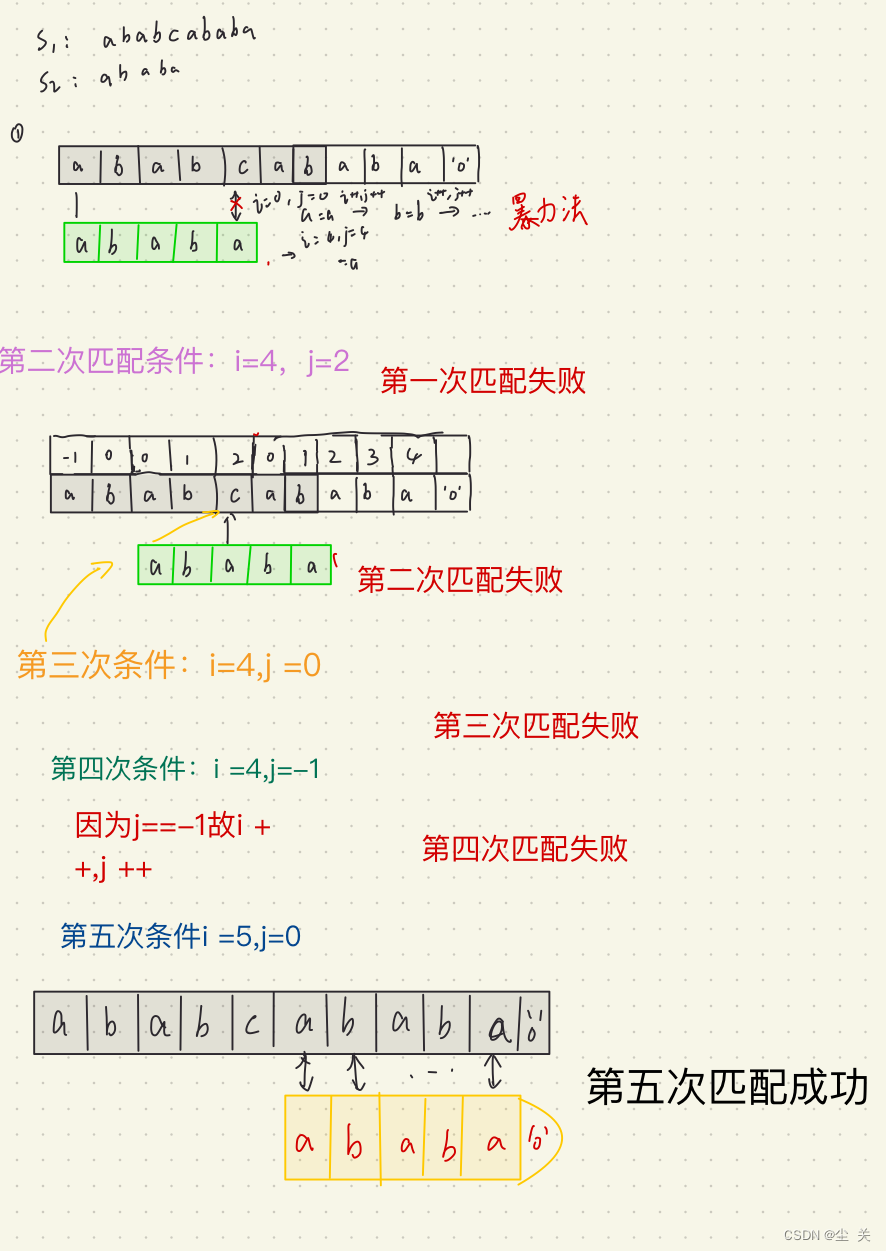
具体代码:
#include <stdio.h>
#include <stdlib.h>
#define MAXSIZE 1024
typedef struct
{
char memory[MAXSIZE];
int curSize; //万金油参数
}string, * LPSTR;
//创建一个串
LPSTR createStr(const char* str)
{
LPSTR pStr = (LPSTR)malloc(sizeof(string));
for (int i = 0; i < MAXSIZE; i++)
{
pStr->memory[i] = '\0';
}
int count = 0;
while (str[count] != '\0')
{
pStr->memory[count] = str[count];
count++;
}
pStr->curSize = count;
return pStr;
}
//求相应的部分匹配值 就是找某串的共同前缀和后缀 如 ABCA 的前缀为A,AB,ABC ;后缀为A,AC,ACB,共同元素为A,故相应的部分匹配值为1
void getNext(LPSTR pstr, int next[])
{
int len = pstr->curSize;
int i = 0;
int j = -1;
next[0] = -1; //第一个位置为0,或者-1都行
while (i < len)
{
if (j == -1 || pstr->memory[i] == pstr->memory[j])
{
i++;
j++;
next[i] = j; //部分匹配元素的长度
}
else
{
j = next[j]; //重置j为-1
}
}
}
int KMP(LPSTR pStr1, LPSTR pStr2, int next[])
{
//KMP 第一个得到表
getNext(pStr2, next);
int i = 0;
int j = 0;
while (i < pStr1->curSize && j < pStr2->curSize)
{
if (j == -1 || pStr1->memory[i] == pStr2->memory[j])
{
i++;
j++;
}
else
{
j = next[j]; //重置
}
}
if (j == pStr2->curSize)
{
return i - j;
}
return 0;
}
int main()
{
int next[11];//字符串长度
LPSTR pStr = createStr("ababcababa");
getNext(pStr, next);
for (int i = 0; i < 10; i++)//‘\0’不算
{
printf(" %d ", next[i]);//打印字符串前缀和后缀相同元素的长度
}
printf("\n");
LPSTR pstr = createStr("abacc");
LPSTR pstr1 = createStr("ababa");
int next1[6];//
printf("匹配%s\n", KMP(pStr, pstr,next) ? "成功" : "不成功");
printf("匹配%s\n", KMP(pStr, pstr1,next1) ? "成功" : "不成功");
return 0;
}