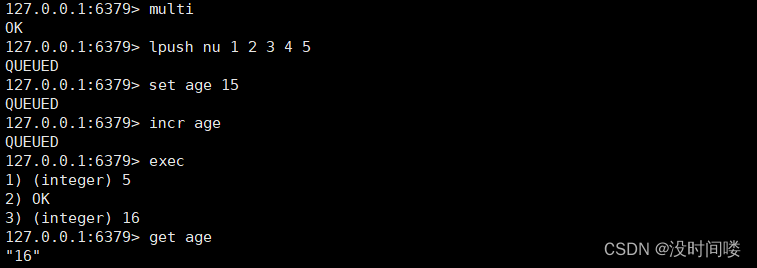
Redis事务
可以一次执行多个命令,本质是一组命令的集合。一个事务中的 所有命令都会序列化,按顺序地串行化执行而不会被其它命令插入,不许加塞。
单独的隔离的操作
官网说明
https://redis.io/docs/interact/transactions/
MULTI、EXEC、DISCARD、WATCH。这四个指令构成了 redis 事务处理的基础。
1.MULTI 用来组装一个事务;将命令存放到一个队列里面
2.EXEC 用来执行一个事务;相当于mysql的//commit
3.DISCARD 用来取消一个事务;相当于mysql的//rollback
4.WATCH 用来监视一些 key,一旦这些 key 在事务执行之前被改变,则取消事务的执行。
结束后统一执行
有关事务,经常会遇到的是两类错误:
调用 EXEC 之前的错误 如语法错误,事务不会被执行
调用 EXEC 之后的错误 如重复建,事务不会理睬错误(不会影响接下来的其他命令的执行)
WATCH
“WATCH”可以帮我们实现类似于“乐观锁”的效果,即 CAS(check and set)。
WATCH 本身的作用是“监视 key 是否被改动过”,而且支持同时监视多个 key,只要还没真正触发事务,WATCH 都会尽职尽责的监视,一旦发现某个 key 被修改了,在执行 EXEC 时就会返回 nil,表示事务无法触发。
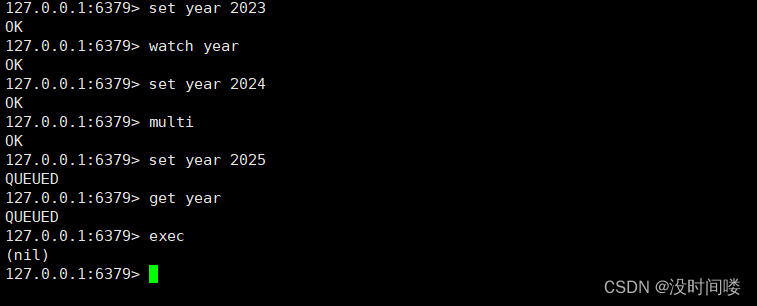
在 multi 之前 set year 修改了值所以 nil
事务回滚(discard)
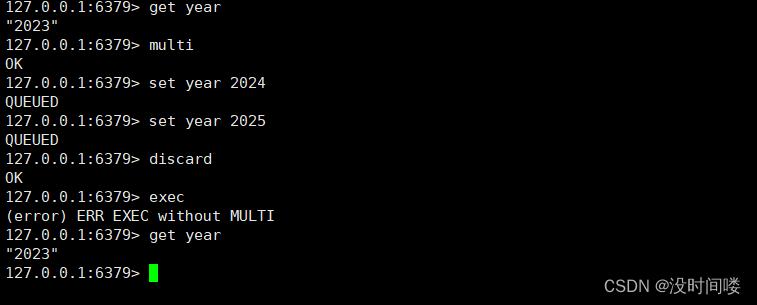
事务冲突
比如涉及金钱的操作,导致金额负数
解决方案
悲观锁(Pessimistic Lock)
顾名思义,就是很悲观
每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,
这样别人想拿这个数据就会block直到它拿到锁。
传统的关系型数据库里边就用到了很多这种锁机制,
比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
每次都会上锁影响效率
乐观锁(Optimistic Lock)
顾名思义,就是很乐观
每次去拿数据的时候都认为别人不会修改,所以不会上锁,
但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,
可以使用版本号等机制。乐观锁适用于多读的应用类型,
这样可以提高吞吐量。Redis就是利用这种check-and-set机制实现事务的。
redis与idea的连接
ssm
添加redis的依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>Jedis jds = new Jedis("IP")
jds.auth("密码")
jds.select(数据库) <!-- 0-15 -->
spring boot
加入redis的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>编写配置文件
#设置reis的索引
spring.redis.database=15
#设置连接redis的密码
spring.redis.password=yyl
#设置的redis的服务器
spring.redis.host=192.168.159.34
#端口号
spring.redis.port=6379
#连接超时时间(毫秒)
spring.redis.timeout=1800000
#连接池最大连接数(使用负值表示没有限制)
spring.redis.lettuce.pool.max-active=20
#最大阻塞等待时间(负数表示没限制)
spring.redis.lettuce.pool.max-wait=-1
#连接池中的最大空闲连接
spring.redis.lettuce.pool.max-idle=5
#连接池中的最小空闲连接
spring.redis.lettuce.pool.min-idle=0设置配置类
package com.example.demo;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import java.time.Duration;
@EnableCaching
@Configuration
public class RedisConfig extends CachingConfigurerSupport {
/**
* 连接池的设置
*
* @return
*/
@Bean
public JedisPoolConfig getJedisPoolConfig() {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
return jedisPoolConfig;
}
/**
* RedisTemplate
* @param factory
* @return
*/
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
// 指定要序列化的域,field,get和set,以及修饰符范围,ANY是都有包括private和public
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
// 指定序列化输入的类型,类必须是非final修饰的,final修饰的类,比如String,Integer等会跑出异常
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
template.setConnectionFactory(factory);
//key序列化方式
template.setKeySerializer(redisSerializer);
//value序列化
template.setValueSerializer(jackson2JsonRedisSerializer);
//value hashmap序列化
template.setHashValueSerializer(jackson2JsonRedisSerializer);
return template;
}
/**
* 缓存处理
* @param factory
* @return
*/
@Bean
public CacheManager cacheManager(RedisConnectionFactory factory) {
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//解决查询缓存转换异常的问题
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// 配置序列化(解决乱码的问题),过期时间600秒
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(600))
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer))
.disableCachingNullValues();
RedisCacheManager cacheManager = RedisCacheManager.builder(factory)
.cacheDefaults(config)
.build();
return cacheManager;
}
}编写测试代码
spring-data-redis针对jedis提供了如下功能:
1. 连接池自动管理,提供了一个高度封装的“RedisTemplate”类
2. RedisTemplate 对五种数据结构分别定义了操作
操作字符串
redisTemplate.opsForValue();
操作hash
redisTemplate.opsForHash();
操作list
redisTemplate.opsForList();
操作set
redisTemplate.opsForSet();
操作有序set
redisTemplate.opsForZSet();
String类型与List类型
Set类型
添加元素
redisTemplate.opsForSet().add(key, values)
移除元素(单个值、多个值)
redisTemplate.opsForSet().remove(key, values)
删除并且返回一个随机的元素
redisTemplate.opsForSet().pop(key)
获取集合的大小
redisTemplate.opsForSet().size(key)
判断集合是否包含value
redisTemplate.opsForSet().isMember(key, value)
获取两个集合的交集(key对应的无序集合与otherKey对应的无序集合求交集)
redisTemplate.opsForSet().intersect(key, otherKey)
获取多个集合的交集(Collection var2)
redisTemplate.opsForSet().intersect(key, otherKeys)
key集合与otherKey集合的交集存储到destKey集合中(其中otherKey可以为单个值或者集合)
redisTemplate.opsForSet().intersectAndStore(key, otherKey, destKey)
key集合与多个集合的交集存储到destKey无序集合中
redisTemplate.opsForSet().intersectAndStore(key, otherKeys, destKey)
获取两个或者多个集合的并集(otherKeys可以为单个值或者是集合)
redisTemplate.opsForSet().union(key, otherKeys)
key集合与otherKey集合的并集存储到destKey中(otherKeys可以为单个值或者是集合)
redisTemplate.opsForSet().unionAndStore(key, otherKey, destKey)
获取两个或者多个集合的差集(otherKeys可以为单个值或者是集合)
redisTemplate.opsForSet().difference(key, otherKeys)
差集存储到destKey中(otherKeys可以为单个值或者集合)
redisTemplate.opsForSet().differenceAndStore(key, otherKey, destKey)
随机获取集合中的一个元素
redisTemplate.opsForSet().randomMember(key)
获取集合中的所有元素
redisTemplate.opsForSet().members(key)
随机获取集合中count个元素
redisTemplate.opsForSet().randomMembers(key, count)
获取多个key无序集合中的元素(去重),count表示个数
redisTemplate.opsForSet().distinctRandomMembers(key, count)
遍历set类似于Interator(ScanOptions.NONE为显示所有的)
redisTemplate.opsForSet().scan(key, options)Hash类型
Long delete(H key, Object... hashKeys);
删除给定的哈希hashKeys
System.out.println(template.opsForHash().delete("redisHash","name"));
System.out.println(template.opsForHash().entries("redisHash"));
1
{class=6, age=28.1}
Boolean hasKey(H key, Object hashKey);
确定哈希hashKey是否存在
System.out.println(template.opsForHash().hasKey("redisHash","666"));
System.out.println(template.opsForHash().hasKey("redisHash","777"));
true
false
HV get(H key, Object hashKey);
从键中的哈希获取给定hashKey的值
System.out.println(template.opsForHash().get("redisHash","age"));
26
Set<HK> keys(H key);
获取key所对应的散列表的key
System.out.println(template.opsForHash().keys("redisHash"));
//redisHash所对应的散列表为{class=1, name=666, age=27}
[name, class, age]
Long size(H key);
获取key所对应的散列表的大小个数
System.out.println(template.opsForHash().size("redisHash"));
//redisHash所对应的散列表为{class=1, name=666, age=27}
3
void putAll(H key, Map<? extends HK, ? extends HV> m);
使用m中提供的多个散列字段设置到key对应的散列表中
Map<String,Object> testMap = new HashMap();
testMap.put("name","666");
testMap.put("age",27);
testMap.put("class","1");
template.opsForHash().putAll("redisHash1",testMap);
System.out.println(template.opsForHash().entries("redisHash1"));
{class=1, name=jack, age=27}
void put(H key, HK hashKey, HV value);
设置散列hashKey的值
template.opsForHash().put("redisHash","name","666");
template.opsForHash().put("redisHash","age",26);
template.opsForHash().put("redisHash","class","6");
System.out.println(template.opsForHash().entries("redisHash"));
{age=26, class=6, name=666}
List<HV> values(H key);
获取整个哈希存储的值根据密钥
System.out.println(template.opsForHash().values("redisHash"));
[tom, 26, 6]
Map<HK, HV> entries(H key);
获取整个哈希存储根据密钥
System.out.println(template.opsForHash().entries("redisHash"));
{age=26, class=6, name=tom}
Cursor<Map.Entry<HK, HV>> scan(H key, ScanOptions options);
使用Cursor在key的hash中迭代,相当于迭代器。
Cursor<Map.Entry<Object, Object>> curosr = template.opsForHash().scan("redisHash",
ScanOptions.ScanOptions.NONE);
while(curosr.hasNext()){
Map.Entry<Object, Object> entry = curosr.next();
System.out.println(entry.getKey()+":"+entry.getValue());
}
age:27
class:6
name:666| 命令 | 操作 | 返回值 |
| hash.delete(H key, Object... hashKeys) | 删除,可以传入多个map的key【hdel】 | Long |
| hash.hasKey(key, hashKey) | 查看hash中的某个hashKey是否存在【hexists】 | Boolean |
| hash.get(key, hashKey) | 获取值【hget】 | Object(HV 泛型约束对象) |
| hash.multiGet(H key, Collection<HK> hashKeys) | 批量获取集合中的key对应的值【hmget】 | List<HV> |
| hash.increment(H key, HK hashKey, long delta) | 对值进行+(delta值)操作【】 | Long |
| hash.increment(H key, HK hashKey, double delta) | ~ | double |
| hash.keys(key) | 返回map内hashKey的集合【hkeys】 | Set<HK> |
| hash.lengthOfValue(H key, HK hashKey) | 返回查询键关联的值的长度,为null则返回0【hstrlen】 | Long |
| hash.size(H key) | 获取hashKey的个数【hlen】 | Long |
| hash.putAll(H key, Map<? extends HK, ? extends HV> m) | 相当于map的putAll【hmset】 | void |
| hash.put(H key, HK hashKey, HV value) | 设置值,添加hashKey-value,hashKay相当于map的key 【hset】 | void |
| hash.putIfAbsent(H key, HK hashKey, HV value) | 仅当hashKey不存在时设置值 | Boolean |
| hash.values(key) | 返回value的集合【hvals】 | List<HV> |
| hase.entries(H key) | 获取map【hgetall】 | Map<HK, HV> |
| hash.scan(H key, ScanOptions options) | 基于游标的迭代查询【hscan】 | Cursor<Map.Entry<HK, HV>>(返回的Cursor要手动关闭,见下面示例2) |
| hash.getOperations() | 返回RedisOperation,它就是redis操作的接口 | RedisOperations<H, ?> |
ZSet类型
Boolean add(K key, V value, double score);
新增一个有序集合,存在的话为false,不存在的话为true
System.out.println(template.opsForZSet().add("zset1","zset-1",1.0));
true
Long add(K key, Set<TypedTuple<V>> tuples);
新增一个有序集合
ZSetOperations.TypedTuple<Object> objectTypedTuple1 = new DefaultTypedTuple<>("zset-5",9.6);
ZSetOperations.TypedTuple<Object> objectTypedTuple2 = new DefaultTypedTuple<>("zset-6",9.9);
Set<ZSetOperations.TypedTuple<Object>> tuples = new HashSet<ZSetOperations.TypedTuple<Object>>();
tuples.add(objectTypedTuple1);
tuples.add(objectTypedTuple2);
System.out.println(template.opsForZSet().add("zset1",tuples));
System.out.println(template.opsForZSet().range("zset1",0,-1));
[zset-1, zset-2, zset-3, zset-4, zset-5, zset-6]
Long remove(K key, Object... values);
从有序集合中移除一个或者多个元素
System.out.println(template.opsForZSet().range("zset1",0,-1));
System.out.println(template.opsForZSet().remove("zset1","zset-6"));
System.out.println(template.opsForZSet().range("zset1",0,-1));
[zset-1, zset-2, zset-3, zset-4, zset-5, zset-6]
1
[zset-1, zset-2, zset-3, zset-4, zset-5]
Long rank(K key, Object o);
返回有序集中指定成员的排名,其中有序集成员按分数值递增(从小到大)顺序排列
System.out.println(template.opsForZSet().range("zset1",0,-1));
System.out.println(template.opsForZSet().rank("zset1","zset-2"));
[zset-2, zset-1, zset-3, zset-4, zset-5]
0 //表明排名第一
Set<V> range(K key, long start, long end);
通过索引区间返回有序集合成指定区间内的成员,其中有序集成员按分数值递增(从小到大)顺序排列
System.out.println(template.opsForZSet().range("zset1",0,-1));
[zset-2, zset-1, zset-3, zset-4, zset-5]
Long count(K key, double min, double max);
通过分数返回有序集合指定区间内的成员个数
System.out.println(template.opsForZSet().rangeByScore("zset1",0,5));
System.out.println(template.opsForZSet().count("zset1",0,5));
[zset-2, zset-1, zset-3]
3
Long size(K key);
获取有序集合的成员数,内部调用的就是zCard方法
System.out.println(template.opsForZSet().size("zset1"));
6
Double score(K key, Object o);
获取指定成员的score值
System.out.println(template.opsForZSet().score("zset1","zset-1"));
2.2
Long removeRange(K key, long start, long end);
移除指定索引位置的成员,其中有序集成员按分数值递增(从小到大)顺序排列
System.out.println(template.opsForZSet().range("zset2",0,-1));
System.out.println(template.opsForZSet().removeRange("zset2",1,2));
System.out.println(template.opsForZSet().range("zset2",0,-1));
[zset-1, zset-2, zset-3, zset-4]
2
[zset-1, zset-4]
Cursor<TypedTuple<V>> scan(K key, ScanOptions options);
遍历zset
Cursor<ZSetOperations.TypedTuple<Object>> cursor = template.opsForZSet().scan("zzset1", ScanOptions.NONE);
while (cursor.hasNext()){
ZSetOperations.TypedTuple<Object> item = cursor.next();
System.out.println(item.getValue() + ":" + item.getScore());
}
zset-1:1.0
zset-2:2.0
zset-3:3.0
zset-4:6.0





![2023年中国高尔夫服饰市场规模、主要品牌及行业发展方向分析[图]](https://img-blog.csdnimg.cn/img_convert/6865b53e52ee9aeb183dc6fc2a91c291.png)