下载驱动
NVIDIA显卡驱动官方下载地址
下载好对应驱动并放在某个目录下,
在Linux系统中安装NVIDIA显卡驱动前,建议先卸载Linux系统自带的显卡驱动nouveau。
禁用nouveau
首先,编辑黑名单配置。
vim /etc/modprobe.d/blacklist.conf
在文件的最后添加下面两行。
blacklist nouveau
options nouveau modeset=0
然后,输入下面的命令更新并重启。
update-initramfs -u
reboot
重启后输入下面的命令验证是否禁用成功,成功的话这行命令不会有输出。
lsmod | grep nouveau
驱动安装
首先,使用apt卸载已有的驱动,命令如下。
apt-get purge nvidia*
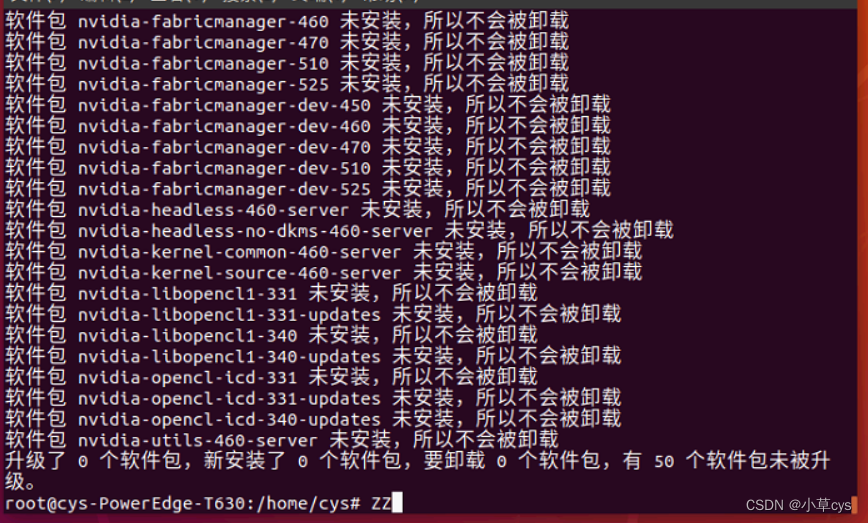
缺少gcc
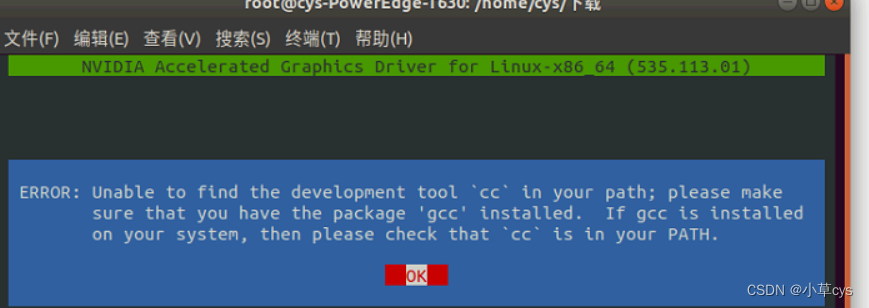
J解决办法:
sudo apt install build-essential
然后gcc -v看是否安装成功
我的系统是ubuntu18.04
要装cuda12.0,需要升级系统至至少Ubuntu20.04,升级后apt-get upgrade有问题,还是卸载后重新安装了系统。
Ubuntu操作系统的版本号。命令如下
lsb_release -a
可以看到Ubuntu的系统版本号码为18.04
在终端的命令窗口输入下面的命令,进行软件源列表的更新。
sudo apt-get update
完成上面的软件列表更新之后,使用下面的命令 进行更新包的安装。
sudo apt-get upgrade
重启
reboot
apt install update-manager-core
sudo apt dist-upgrade
sudo do-release-upgrade
cuda10.1及以上的卸载:
-
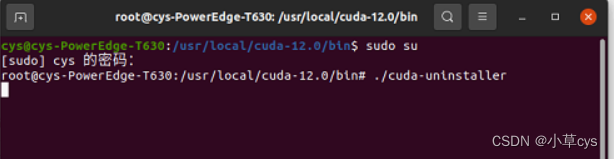
cd /usr/local/cuda-xx.x/bin/ -
sudo ./cuda-uninstaller -
sudo rm -rf /usr/local/cuda-xx.x
升级后apt-get upgrade有问题,还是卸载后重新安装了系统。
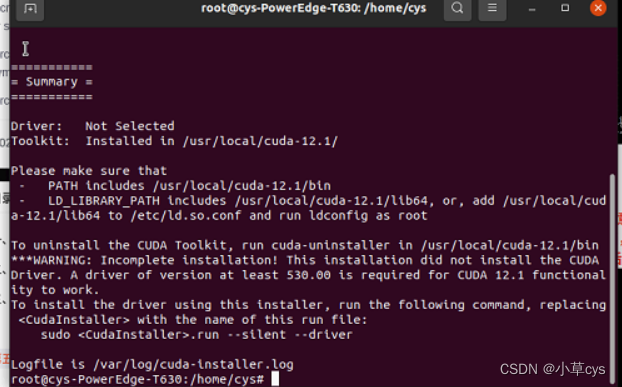
官网下载并安装对应版本CUDA
- 根据系统支持版本下载对应版本的CUDA Toolkit,为了后续的torch安装作者此处选择CUDA12.1。官网链接

- 没有用,还是从bin文件夹中卸载cuda-uninstaller
- 选择所需版本,通过对应命令进行下载安装(注意此处需要记住下载文件的目录,之后需要找到)
sh cuda_12.0**.run

配置环境变量
编辑 /etc/profile 结尾添加如下
export CUDA_HOME=/usr/local/cuda-12.0
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
PATH="$CUDA_HOME/bin:$PATH"
使生效
source /etc/profile
4.测试CUDA安装是否成功
nvcc -V

重装cuda12.1的时候,注意不要选driver,因为之前安装过了
安装依赖
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
安装Git LFS
1. curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
2. sudo apt-get install git-lfs
3. 验证安装成功:
输入: git lfs install
如果出现: Git LFS initialized. 则说明成功
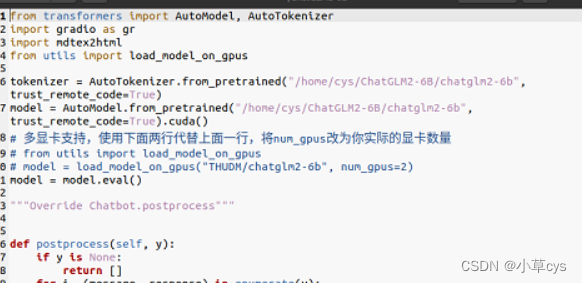
从Hugging Face Hub 下载模型
git clone https://huggingface.co/THUDM/chatglm2-6b
模型量化
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
# 按需在web_demo.py中修改,目前只支持 4/8 bit 量化
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).quantize(4).cuda()
其中"THUDM/chatglm2-6b"需修改为你本地部署的路径
注:如果内存只有8G,模型量化选择int4
安装transformers和gradio和mdtex2html,pip install gradio -i https://pypi.tuna.tsinghua.edu.cn/simple
如果没有报错,输入信息后没有输出,有可能是gradio的版本问题。
需要降低版本 gradio==3.39.0
启动web_demo.py
python web_demo.pyAPI部署
首先需要安装额外的依赖
pip install fastapi uvicorn
将api.py中的"THUDM/chatglm2-6b"修改为本地模型路径
tokenizer = AutoTokenizer.from_pretrained("D:\ChatGLM2-6B", trust_remote_code=True)
model = AutoModel.from_pretrained("D:\ChatGLM2-6B", trust_remote_code=True).quantize(4).cuda()
运行仓库中的 api.py
python api.py
基于 P-Tuning v2 的微调
软件依赖
运行微调除 ChatGLM2-6B 的依赖之外,还需要安装以下依赖
pip install rouge_chinese nltk jieba datasets -i https://pypi.tuna.tsinghua.edu.cn/simple
cd ptuning
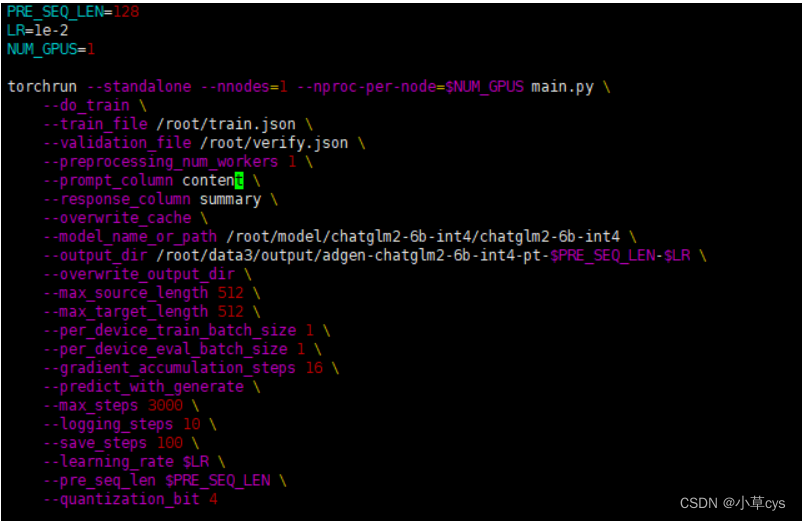
vi train_chat.sh,修改模型地址,数据集地址,输出模型地址
参数解释:
PRE_SEQ_LEN=128: 定义了一个名为PRE_SEQ_LEN的变量,并将其设置为128。这个变量的作用在后续的代码中会用到。
LR=2e-2: 定义了一个名为LR的变量,并将其设置为2e-2,即0.02。这个变量表示学习率,在后续的代码中会用到。
–train_file /root/train.json : 指定训练数据文件的路径和文件名为"/root/train.json"。
–validation_file /root/verify.json : 指定验证数据文件的路径和文件名为"/root/verify.json"。
–prompt_column content : 指定输入数据中作为提示的列名为"content"。
–response_column summary : 指定输入数据中作为响应的列名为"summary"。
–overwrite_cache : 一个命令行参数,指示在缓存存在的情况下覆盖缓存。
–model_name_or_path THUDM/chatglm-6b : 指定使用的模型的名称或路径为"THUDM/chatglm-6b"。
–output_dir output/adgen-chatglm-6b-pt : 指定输出目录的路径和名称为"output/adgen-chatglm-6b-pt
–overwrite_output_dir : 一个命令行参数,指示在输出目录存在的情况下覆盖输出目录。
–max_source_length 512 : 指定输入序列的最大长度为512。
–max_target_length 512 : 指定输出序列的最大长度为512。
–per_device_train_batch_size 1 : 指定每个训练设备的训练批次大小为1。
–per_device_eval_batch_size 1 : 指定每个评估设备的评估批次大小为1。
–gradient_accumulation_steps 16 : 指定梯度累积的步数为16。在每个更新步骤之前,将计算并累积一定数量的梯度。
–predict_with_generate : 一个命令行参数,指示在生成模型的预测时使用生成模式。
–max_steps 3000 : 指定训练的最大步数为3000。
–logging_steps 10 : 指定每隔10个步骤记录一次日志。
–save_steps 1000 : 指定每隔1000个步骤保存一次模型。
–learning_rate $LR : 指定学习率为之前定义的LR变量的值。
–pre_seq_len $PRE_SEQ_LEN : 指定预设序列长度为之前定义的PRE_SEQ_LEN变量的值。
–quantization_bit 4 : 指定量化位数为4。这个参数可能是与模型相关的特定设置。
执行训练命令
sh train_chat.sh
在p-tuning文件夹下执行 sh web_demo.py可以运行微调后的模型。
web_demo.py中注意模型地址和微调模型地址

![2023年中国高尔夫服饰市场规模、主要品牌及行业发展方向分析[图]](https://img-blog.csdnimg.cn/img_convert/6865b53e52ee9aeb183dc6fc2a91c291.png)