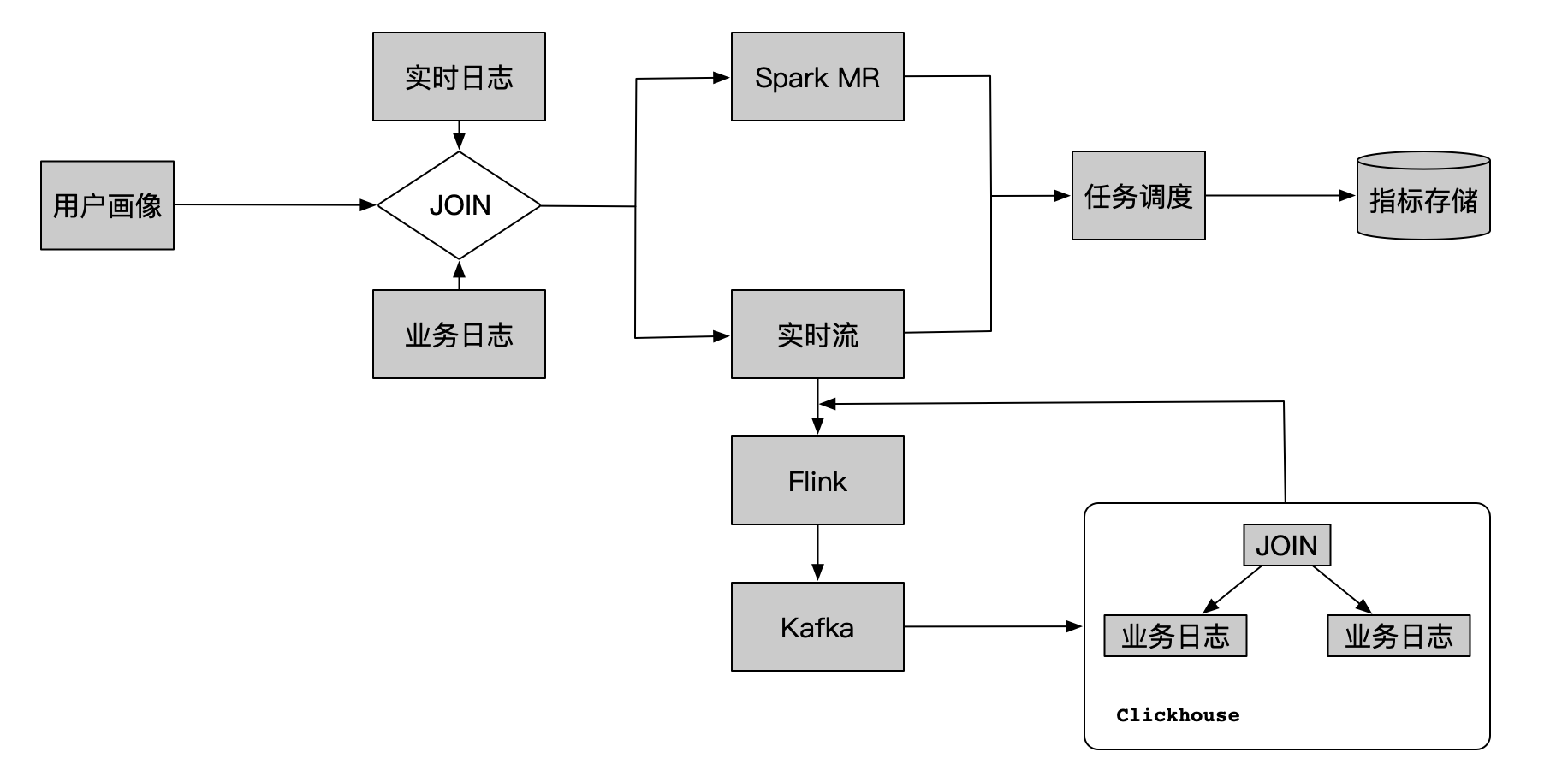
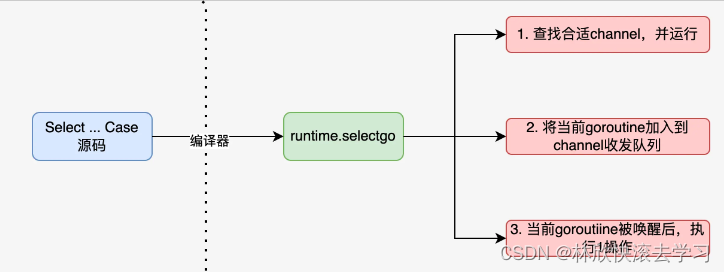
1: Bean在Spring容器中是如何存储和定义的
Bean在Spring中的定义是_org.springframework.beans.factory.config.BeanDefinition_接口,BeanDefinition里面存储的就是我们编写的Java类在Spring中的元数据,包括了以下主要的元数据信息:
1:Scope(Bean类型):包括了单例Bean(Singleton)和多实例Bean(Prototype)
2:BeanClass: Bean的Class类型
3:LazyInit:Bean是否需要延迟加载
4:AutowireMode:自动注入类型
5:DependsOn:Bean所依赖的其他Bean的名称,Spring会先初始化依赖的Bean
6:PropertyValues:Bean的成员变量属性值
7:InitMethodName:Bean的初始化方法名称
8:DestroyMethodName:Bean的销毁方法名称
同时BeanDefinition是存储到_org.springframework.beans.factory.support.DefaultListableBeanFactory类中维护的BeanDefinitionMap_中的,源码如下:
Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256);
了解了BeanDefinition的基础信息和存储位置后,接下来看看创建好的Bean实例是存储在什么地方的,创建好的Bean是存储在:_org.springframework.beans.factory.support.DefaultSingletonBeanRegistry_类中的
_singletonObjects_中的,Key是Bean的名称,Value就是创建好的Bean实例:
Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
了解了基本信息之后,就可以带着下面两个关键问题去分析Spring Bean的生命周期了:
1:Java类是如何被 Spring 扫描从而变成 BeanDefinition 的?
2:BeanDefinition是如何被 Spring 加工创建成我们可以直接使用的 Bean实例的?
2:Java类是如何被Spring扫描成为BeanDefinition的?
在Spring中定义Bean的方式有非常多,例如使用XML文件、注解,包括:@Component,@Service,@Configuration等,下面就以@Component注解为例来探究Spring是如何扫描我们的Bean的。我们知道使用@Component注解来标记Bean是需要配合@ComponentScan注解来使用的,而我们的主启动类上标注的@SpringBootApplication注解中就默认继承了@ComponentScan注解
@ComponentScan(excludeFilters = { @Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication
所以最初的问题就转化成了**@ComponentScan**注解是如何在Spring中运作的
2.1 @ComponentScan注解是如何运作的
在Spring框架中,这个注解对应的处理类是_ComponentScanAnnotationParser,这个类的parse_方法是主要的处理逻辑,这个方法简要处理逻辑如下:
1:获取@ComponentScan注解中的basePackage属性,若没有则默认为该注解所标注类所在的包路径
2:使用ClassPathBeanDefinitionScanner的scanCandidateComponents方法扫描classpath:+basePackage+/*.class**下的所有类资源文件
3:最后循环判断扫描的所有类资源文件,判断是否包含@Component注解,若有则将这些类注册到beandefinitionMap中
自此,我们代码里写的Java类,就被Spring扫描成BeanDefinition存储到了BeanDefinitionMap中了,扫描的细节大家可以去看看这个类的源码
3:Spring如何创建我们的Bean实例的
Spring把我们编写的Java类扫描成BeanDefinition之后,就会开始创建我们的Bean实例了,Spring将创建Bean的方法交给了_org.springframework.beans.factory.support.AbstractBeanFactory#getBean_方法,接下来就来看看getBean方法是如何创建Bean的
getBean方法的调用逻辑如下:getBean–> doGetBean --> createBean --> doCreateBean,最终Spring会使用org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#doCreateBean方法来创建Bean,创建Bean实例的主要逻辑分为了四个部分:创建Bean实例,填充Bean属性,初始化Bean,销毁Bean,接下来我们分别对这个四个部分进行探究
3.1 创建Bean实例
创建Bean实例的方法入口如下:
org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#__createBeanInstance
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
这个方法的主要逻辑是:推断出创建该Bean的构造器方法和参数,然后使用Java反射去创建Bean实例
3.2 填充Bean属性值populateBean方法
在这个方法中,主要是解析Bean需要注入的成员属性,然后将这些属性注入到该Bean中,如果该Bean有依赖的其他Bean则会优先去创建依赖的Bean,然后返回来继续创建该Bean,注意这里就会产生Bean创建的循环依赖问题,在本文的第6节中会详细说明
3.4:初始化Bean(initializeBean方法)
初始化Bean主要包括了四个部分:
3.4.1:invokeAwareMethods
在这个方法中主要调用实现的Aware接口中的方法,包括了BeanNameAware.setBeanName,BeanClassLoaderAware.setBeanClassLoader,BeanFactoryAware.setBeanFactory,这三个方法

Aware接口的功能:通过调用Aware接口中的set方法,将Spring容器中对应的Bean注入到正在创建的Bean中
3.4.2:调用前置处理方法:applyBeanPostProcessorsBeforeInitialization
在这个方法中主要是获取Spring容器中所有实现了_org.springframework.beans.factory.config.BeanPostProcessor接口的的实现类,然后循环调用postProcessBeforeInitialization_方法来加工正在创建的Bean

所以在这个方法中我们可以自定义_BeanPostProcessor_来扩展Bean的功能,实现自己的加工逻辑
3.4.3:调用Bean相关的初始化方法:
3.4.3.1 如果是InitializingBean则调用afterPropertiesSet方法

在这个流程中,Spring框架会判断正在创建的Bean是否实现了InitializingBean接口,如果实现了就会调用_afterPropertiesSet_方法来执行代码逻辑。
3.4.3.2 调用自定义初始化方法:initMethod
在这个流程中主要调用我们自定义的初始化方法,例如在xml文件中配置的_init-method和destory-method或者使用注解配置的@Bean(initMethod = “initMethod”, destroyMethod = “destroyMethod”)_ 方法

3.4.3.3:调用后置处理方法:applyBeanPostProcessorsAfterInitialization
在这个方法中主要是获取Spring容器中所有实现了_org.springframework.beans.factory.config.BeanPostProcessor接口的的实现类,然后循环调用postProcessAfterInitialization_来加工正在创建的Bean

在这个方法中我们可以自定义_BeanPostProcessor_来扩展Bean的功能,实现自己的加工逻辑
4:注册Bean销毁方法
在这里主要是注册Bean销毁时Spring回掉的方法例如:
1:xml文件中配置的destroy-method方法或者_@Bean注解中配置的destroyMethod_方法
2:_org.springframework.beans.factory.DisposableBean接口中的destory_方法
5:总结
到这里,从我们编写的Java类到Spring容器中可使用的Bean实例的创建过程就完整的梳理完成了,了解Bean的创建过程能够使我们更加熟悉Bean的使用方法,同时我们也可以在创建Bean的过程中新增自己的处理逻辑,从而实现将自己的组件接入Spring框架
6:Spring循环依赖的解决方法
Spring在创建Bean实例的时候,有时避免不了我们编写的Java类存在互相依赖的情况,如果Spring对这种互相依赖的情况不做处理,那么就会产生创建Bean实例的死循环问题,所以Spring对于这种情况必须特殊处理,下面就来探究Spring是如何巧妙处理Bean之间的循环依赖问题
6.1 暴露钩子方法getEarlyBeanReference
首先对于单实例类型的Bean来说,Spring在创建Bean的时候,会提前暴露一个钩子方法来获取这个正在创建中的Bean的地址引用,其代码如下:


如上面的代码所示,此时会在_singletonFactories这个Map中提前储存这个钩子方法singletonFactory_,从而能够提前对外暴露这个Bean的地址引用,那么为什么获取地址引用需要包装成复杂的方法呢?下面会解释
6.2 其他Bean获取提前暴露的Bean的地址引用
当其他Bean需要依赖正在创建中的Bean的时候,就会调用getSingleton方法来获取需要的Bean的地址引用
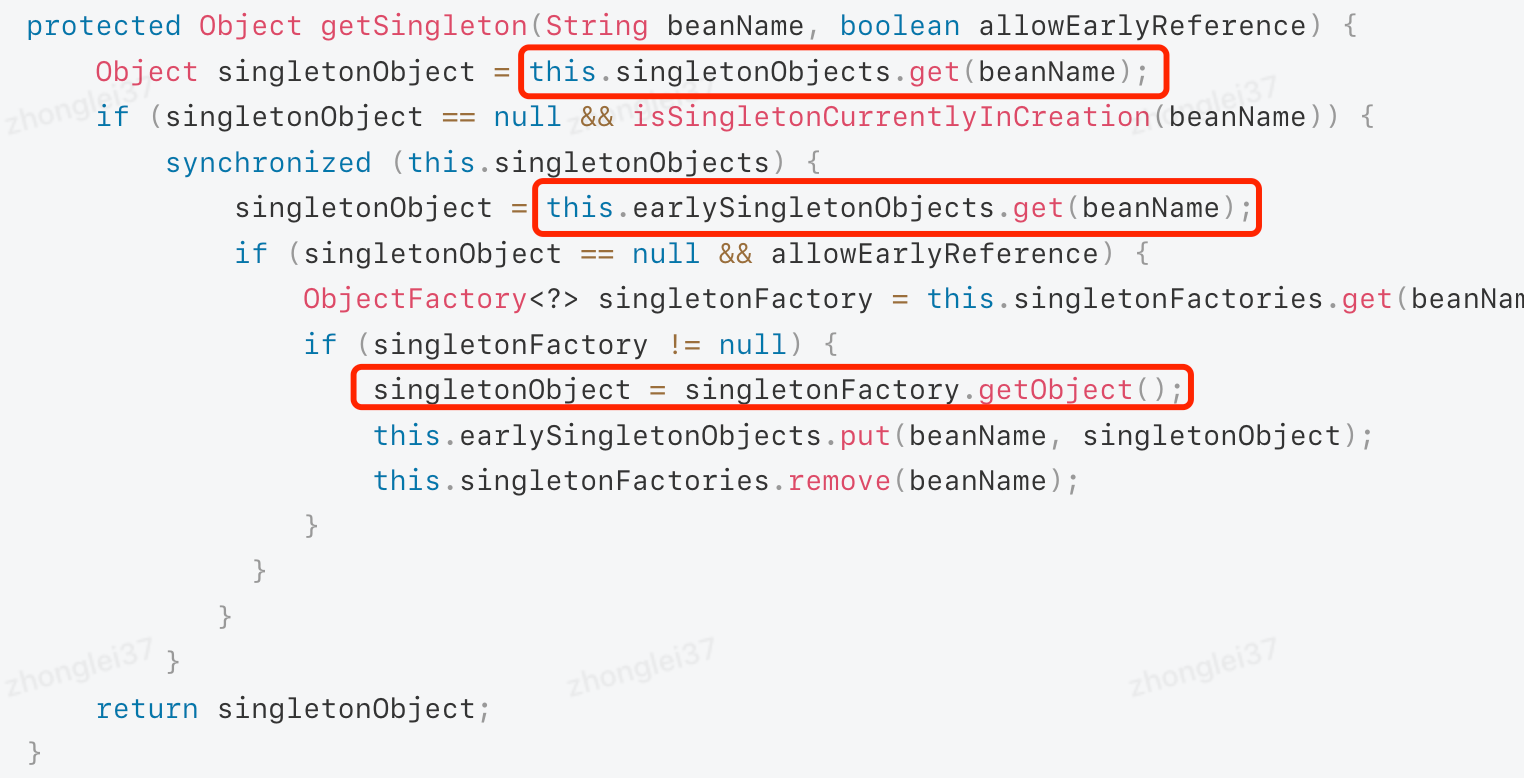
如上诉代码所示,在获取Bean的时候会从三个地方来获取
1:singletonObjects :这个是存放已经完全创建完成的Bean实例的Map
2:earlySingletonObjects :这个是存放用提前暴露的钩子方法创建好的Bean实例的Map
3:singletonFactories :这个是用来存放钩子方法的Map
当获取依赖的Bean的时候,就会调用钩子方法getEarlyBeanReference来获取提前暴露的Bean的引用,这个方法的源码如下:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
如上面的源码所示,这个方法主要是需要调用SmartInstantiationAwareBeanPostProcessor的getEarlyBeanReference方法来提前处理一下尚未创建完成的Bean,而getEarlyBeanReference方法有逻辑的实现类只有一个**org.springframework.aop.framework.autoproxy.AbstractAutoProxyCreator,**这个类就是创建Aop代理的类,其代码如下:
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = this.getCacheKey(bean.getClass(), beanName);
//提前标记这个bean已经创建过代理对象了
this.earlyProxyReferences.put(cacheKey, bean);
//按条件创建代理对象
return this.wrapIfNecessary(bean, beanName, cacheKey);
}
如上面的代码所示,这段代码的主要目标就是判断提前暴露的Bean是否需要做动态代理,需要的话就会返回提前暴露的Bean的动态代理对象
那么这里为什么要去判断是否需要动态代理呢?考虑下面这种情况
1:如果这里不返回这个Bean的动态代理对象,但是这个Bean在后续的初始化流程中会存在动态代理:
举例:这里假设A依赖B,B又依赖A,此时B正在获取A提前暴露的引用,如果这时将A本身的地址引用返回给B,那么B里面就会保存A原始的地址引用,当B创建完成后,程序返回去创建A时,结果A在初始化的流程(initializingBean)中发生了动态代理,那么这时Spring容器中实际使用的是A的动态代理对象,而B却持有了原始A的引用,那么这时容器中就会存在A原始的引用以及A的动态代理的引用,从而产生歧义,这就是为什么需要提前去判断是否需要创建动态代理的原因,__这个原因的问题在于填充属性populateBean流程在初始化流程(initializingBean)之前,而创建动态代理的过程在初始化流程中
6.3 判断Bean的地址是否发生变化
Spring在Bean初始化之后,又判断了一下Bean初始化之后的地址是否发生了变化,其代码逻辑如下所示:
if (earlySingletonExposure) {
Object earlySingletonReference = getSingleton(beanName, false);
//判断是否触发了提前创建bean的逻辑(getEarlyBeanReference)
//如果有其他bean触发了提前创建bean的逻辑,那么这里就不为null
if (earlySingletonReference != null) {
//判断引用地址是否发生了变化
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
}
}
那么这里为什么需要在初始化之后继续判断Bean的地址是否发生了变化呢?
这是因为,如果存在循环依赖,同时Bean在初始化的流程(initializingBean)中又发生了额外的动态代理,例如,除了在**getEarlyBeanReference中发生的动态代理之外,还有额外的动态代理发生了,也就是发生了两次动态代理,那么这时Bean的地址与getEarlyBeanReference流程中产生的Bean的地址就不一样了,**这时如果不处理这种情况,又会出现Spring容器中同时存在两种不同的引用对象,又会造成歧义,所以Spring需要避免这种情况的存在
6.4 如果Bean地址发生变化则判断是否存在强依赖的Bean
Spring在Bean的创建过程中如果出现了上诉6.3节的情况时,Spring采取了下面的方法进行处理:
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
//获取该Bean依赖的Bean
String[] dependentBeans = getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet<>(dependentBeans.length);
//去除因为类型检查而创建的Bean(doGetBean方法typeCheckOnly参数来控制)
for (String dependentBean : dependentBeans) {
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
//如果去除因为类型检查而创建的bean之外还存在依赖的bean
//(这些剩下的bean就是spring实际需要使用的)那么就会抛出异常,阻止问题出现
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName,
"Bean with name '" + beanName + "' has been injected into other beans [" +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
"] in its raw version as part of a circular reference, but has eventually been " +
"wrapped. This means that said other beans do not use the final version of the " +
"bean. This is often the result of over-eager type matching - consider using " +
"'getBeanNamesForType' with the 'allowEagerInit' flag turned off, for example.");
}
}
上面这段代码就是Spring处理上诉情况的逻辑,首先明确的是Spring不允许上诉情况发生,Spring对于Bean的引用地址发生变化的情况,Spring首先会判断依赖的Bean是否已经完全创建完毕,如果存在完全创建完成的Bean就会直接抛出异常,因为这些完全创建完成的依赖Bean中持有的引用已经是旧地址引用了
具体的处理逻辑是:先拿到该Bean所有依赖的Bean,然后从这些Bean中排除仅仅是因为类型检查而创建的Bean,如果排除这些Bean之后,还有依赖的Bean,那么这些Bean就是可能存在循环依赖并且是强依赖的Bean(这些Bean中持有的引用地址是老地址,所以会存在问题),Spring就会及时抛出异常,避免发生问题
作者:京东物流 钟磊
来源:京东云开发者社区 自猿其说Tech 转载请注明来源