欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/133992971
VQ-VAE 是基于变分自编码器(VAE)的生成模型,可以学习离散的潜在表示。VQ-VAE 的主要创新是引入了一个向量量化(VQ)层,将连续的编码器,输出映射到离散的潜在空间。VQ 层由一组可学习的向量组成,称为代码本 (Coding Book)。编码器输出的每个部分都被替换为最接近的代码本向量,从而实现了离散化。VQ-VAE 使用直接优化目标来训练编码器和解码器,而不是使用重参数化技巧或离散梯度估计。VQ-VAE 还使用了一个自回归模型,如 PixelCNN,来对离散的潜在变量进行建模,从而提高了生成质量和多样性。VQ-VAE 在图像和语音生成任务上表现出了优异的性能,证明了能够学习有意义和可控制的潜在表示。
VQ-VAE: Neural Discrete Representation Learning,神经离散表征学习
- Vector Quantised Variational AutoEncoder (VQ-VAE),矢量量化变分自编码器
大模型,预训练,自监督学习。高维信息(图像或音频)更加稀疏,信息压缩,隐空间,特征紧凑,VQ-VAE。
发表于 2018.5.30,作者 Google DeepMind - Aaron
OpenAI 在 DALLE 中,也使用了 VQ-VAE 技术。
GitHub 源码:
- DeepMind Tensorflow
- PyTorch
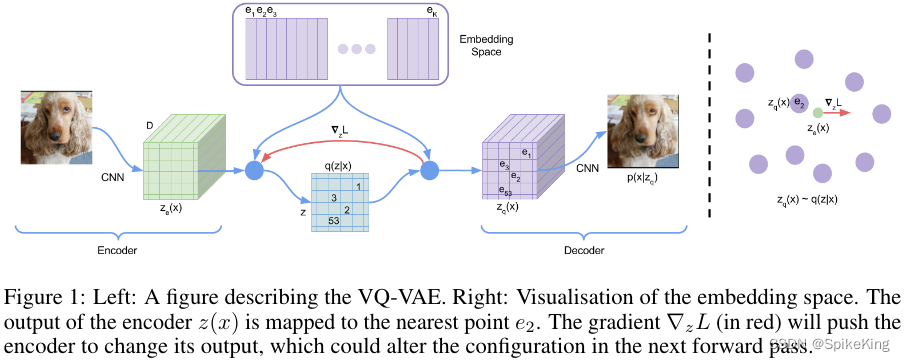
VQ-VAE 与 VAE 不同:
- 编码器网络产生的是离散 (Discrete) 的编码,而不是连续的编码。
- 先验 (Prior) 是可学习的而不是静态的。
避免后验坍塌 (Posterior Collapse),和方差过大 (Large Variance),同时,可生成高质量的不同模态的对象。
VAE:编码器网络 (Encoder Network) q ( z ∣ x ) q(z|x) q(z∣x)、先验分布 (Prior Distribution) p ( z ) p(z) p(z)、分布解码 (Distribution Decoder) p ( x ∣ z ) p(x|z) p(x∣z)。
- 后验和先验,都是标准的对角协方差 (Diagonal Covariance) 的高斯分布
VQ (Vector Quantisation): 隐变量不是从连续的高斯分布中生成,而是从离散的分布中生成。
- 后验和先验,都是类别 (Categorical) 分布,都是索引,从 Embedding Table 中选择 Embedding。
离散的隐变量 (Discrete Latent variables)
隐变量空间 e ∈ R K x D e \in R^{KxD} e∈RKxD ,K 个 Embedding Vectors,输入 x,经过 Encoder,输出 z e ( x ) z_{e}(x) ze(x),后验类别分布 q ( z ∣ x ) q(z|x) q(z∣x) 概率被定义成 one-hot 的形式:
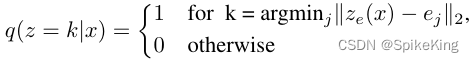
即 k 概率为 1,其他都是 0,最近邻查找,编码器输出的是离散的索引,one-hot vector 与 embedding table 做矩阵乘法。
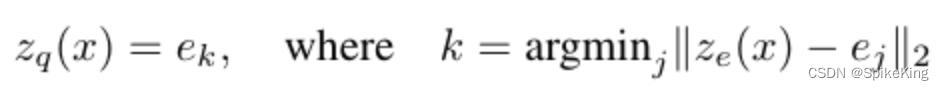
编码器的输出 k,解码器的输入是 e k e_{k} ek 。VAE loss 一般分为 2 个,一个是重构 loss,一个是 KL 散度 loss,量化后验分布与先验分布的距离。VQ-VAE 假设 先验分布是均匀分布,后验分布是类别分布,KL 散度是 log(k) 常数,可以忽略。
argmin 操作是不可导的,让解码器的重构 loss,传递至 编码器,直接将 解码器的梯度复制 (copy gradients) 到编码器。编码器的输出维度 z e ( x ) z_{e}(x) ze(x),与解码器的输入维度一致,这样梯度才能复制。直接复制,embedding space 无法训练,还需要其他 Loss。
Loss 由 3 个部分组成:
- 重构 Loss: l o g p ( x ∣ z q ( x ) ) log\ p(x|z_{q}(x)) log p(x∣zq(x)),可以优化到解码器和编码器,梯度直接 copy。
- 字典学习算法 (Dictionary Learning Algorithm): ∣ ∣ s g [ z e ( x ) − e ] ∣ ∣ 2 2 ||sg[z_{e}(x)-e]||^{2}_{2} ∣∣sg[ze(x)−e]∣∣22,sg 表示 stopgradient 梯度截断,embedding table 逼近编码器的输出。
- 与字典学习算法相反,让 e 逼近 z e ( x ) z_{e}(x) ze(x),其中 β \beta β 小于 1,建议参数是 0.25。
Overall Loss Function:
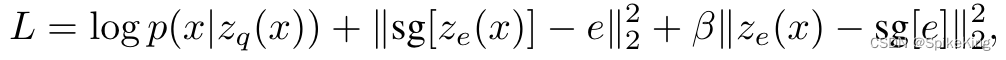
两个类别分布的 KL 散度是常数 log(k),即没有影响,不需要反传。重构 Loss,不同类型的数据不同,图像数据即 MSE Loss,即可。
评估 VQ-VAE 的模型训练效果,监督信号判断 VQ-VAE 的效果,自编码器包括编码和解码,经过编码器,输出编码,进行重构,判断输出图像的相似度。如果,训练不够充分或坍塌,无论输入什么图像,都会映射到相同的类别,可以通过编码器的信息熵,观测 VQ-VAE 的训练效果,即 − p l o g ( p ) -p\ log(p) −p log(p) ,均匀分布是最大,如果值很小,则可能出现坍塌。VQ-VAE 如何生成新的图像,即通过编码生成不同的图像。无监督的生成,大规模的图像预训练 VQ-VAE 之后,使用类别索引,与另外一个模型,对于文本进行自回归的建模,随机生成;条件生成对于离散的索引进行建模,文本作为条件输入,对于隐空间模型进行建模。即两个阶段,大规模预训练图像,再使用文本条件与离散序列对齐。