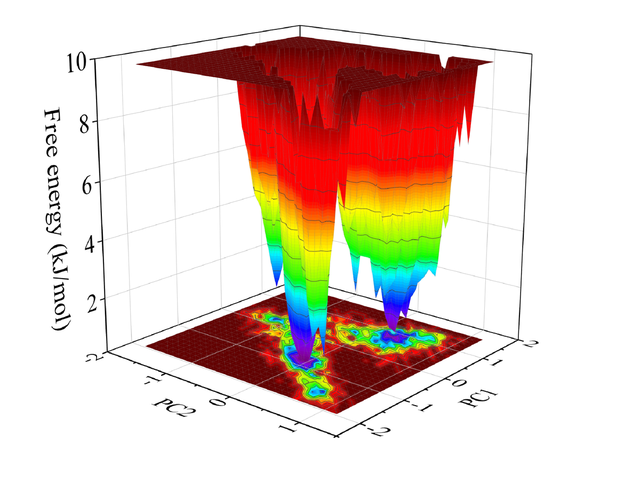
如何评估一个训练好模型的好坏,是目标检测中一个很重要的因素,如常见的TP、FP、AP、PR、map等
TP、FP、TN、FN
TP:被正确分类为正样本的数量;实际是正样本,也被模型分类为正样本
FP:被错误分类为正样本的数量;实际是负样本,但被模型分类为正样本
TN:被正确分类为负样本的数量;实际是负样本,也被模型分类为负样本
FN:被错误分类为负样本的数量;实际是正样本,但被模型分类为负样本
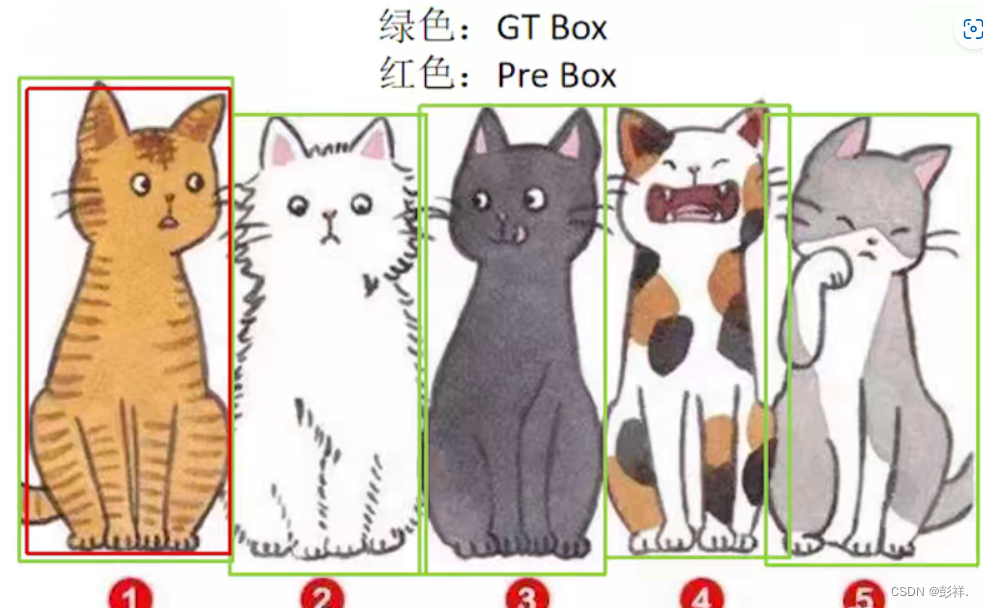
如下图举例:

红色是预测框,绿色是真实框。
假设阈值为0.5,意思就是预测框与真实框的IoU大于等于0.5时认为检测到目标了。
TP是IoU>0.5的检测框数量(在同一真实框下只计算一次),图中的框①。
FP是IoU<=0.5的检测框数量,图中的框②。
FN是没有被检测到的框数量,图中的框③。
Precision和Recall
Precision
计算公式:
P = TP / (TP + FP)
Precision是针对预测结果而言的,含义是在预测结果中,有多少预测框预测正确了。
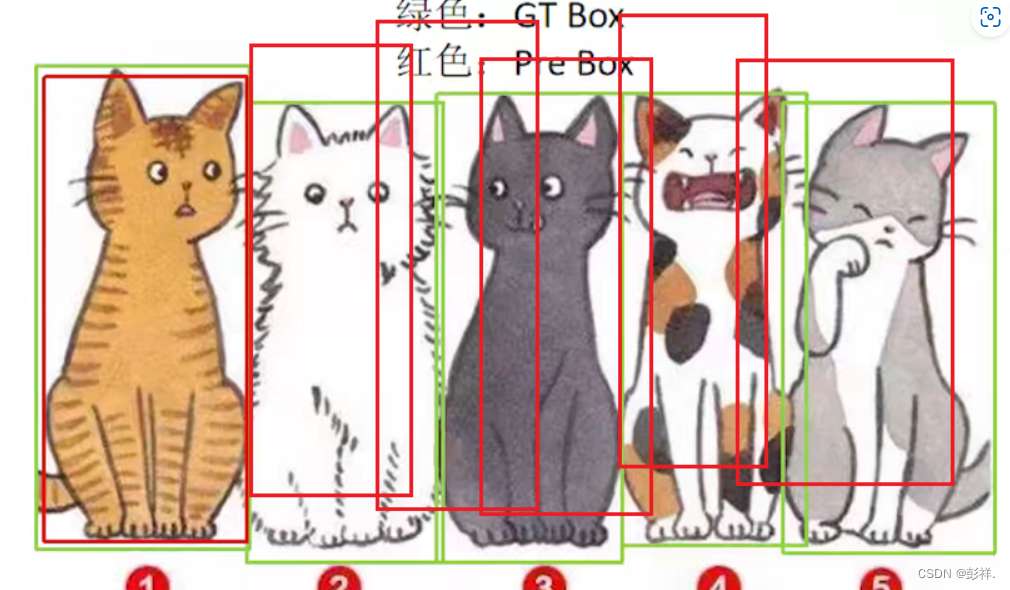
但是光靠一个Precision指标是有缺陷的,比如在下面这种情况中:
在预测结果中,预测正确的目标有一个,预测错误的目标有0个,所以TP=1,FP=0,则P=1,但是图中除了①,②③④⑤都没有检测出来,所以单靠一个Precision指标肯定是不行的。
Recall
计算公式:
R = TP / (TP + FN)
Recall是针对原样本而言的,含义是在所有真实目标中,模型预测正确目标的比例。
但是单靠Recall来判断模型预测结果好坏也不行,比如下面这种情况:
AP(P-R曲线下的面积)
对于以下三张猫的图片,分别对每张图片进行统计,并存入一个表格中,这个表格是按照置信度降序排序的:
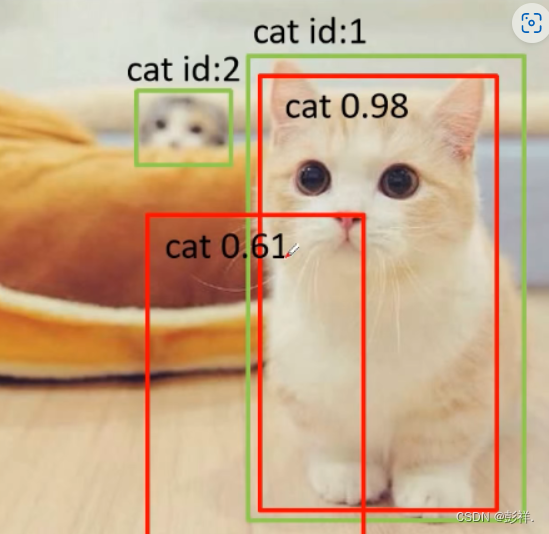
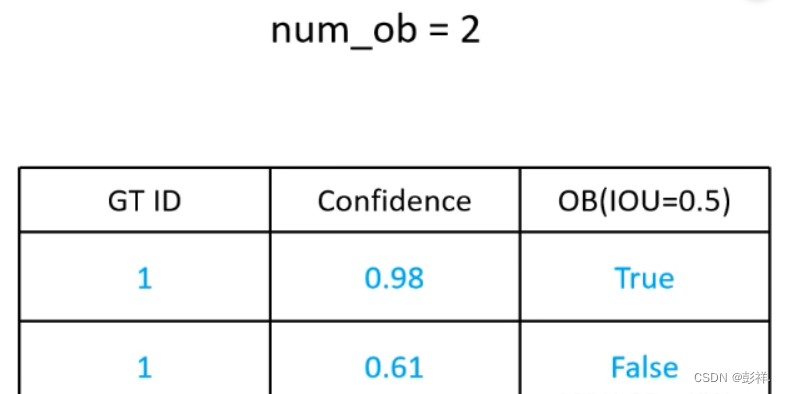
此时真实框有两个,所有num_ob=2(num_ob是累加起来的),当IoU大于等于0.5时,认为检测到了目标。

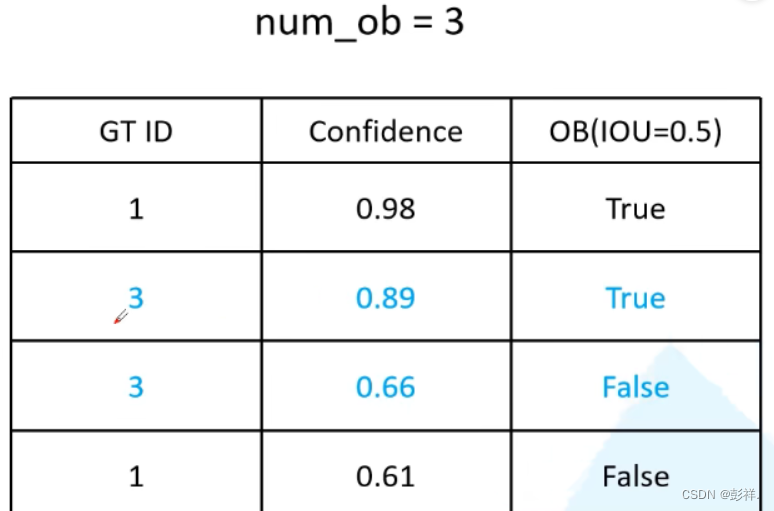
此时num_ob=3,这张图片只有一个真实框,所以num_ob+=1
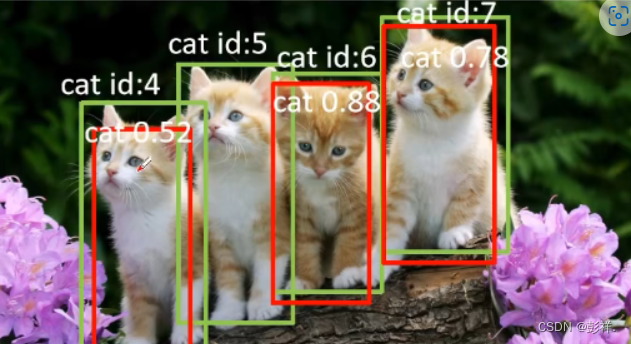
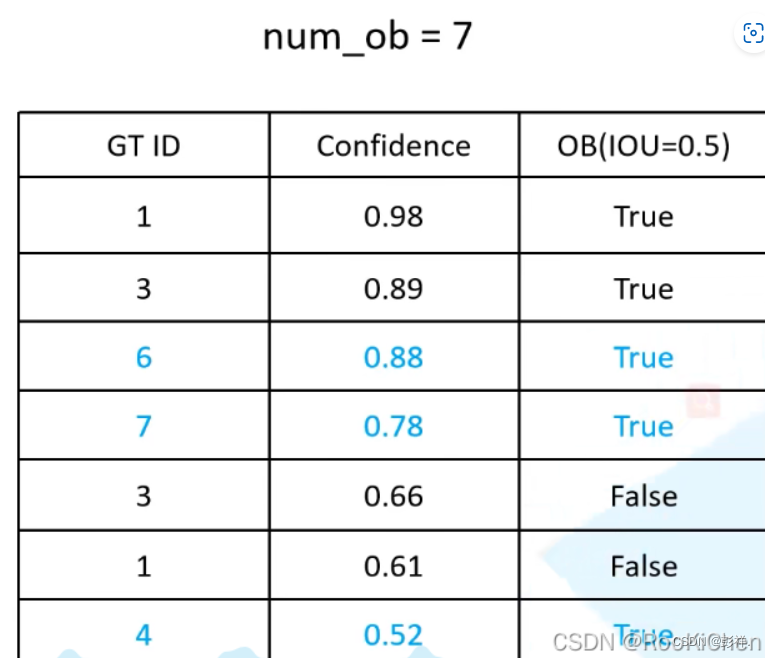
最后得到左边的一张表格,先从第一个元素开始计算Precision和Recall,一次累加一个元素,直到表格中所以元素计算完成为止
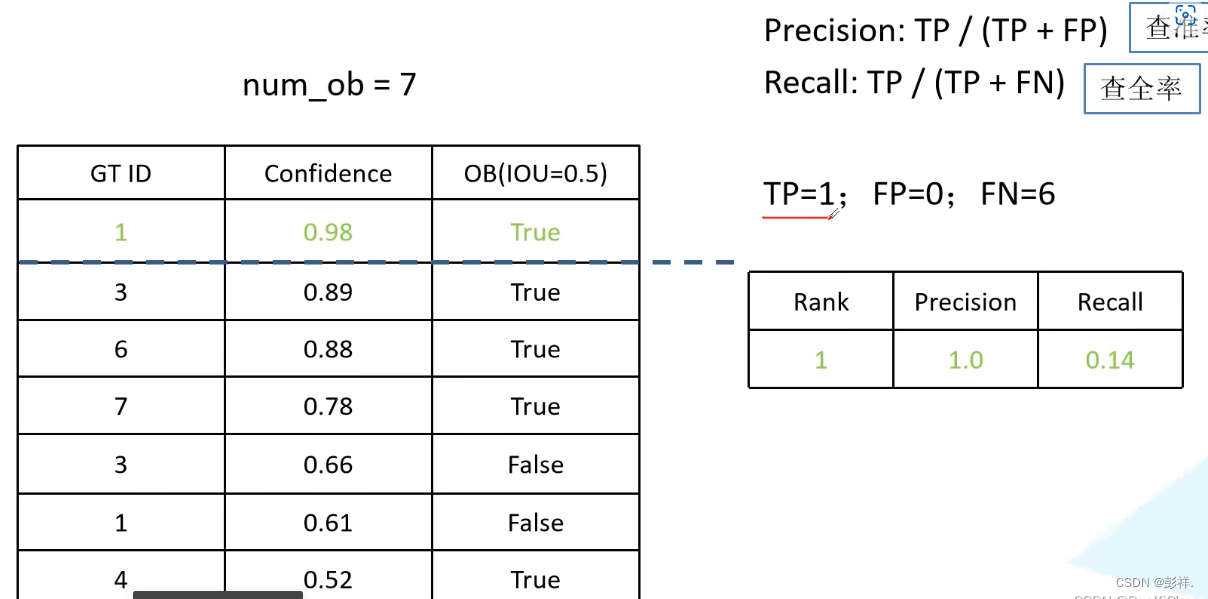
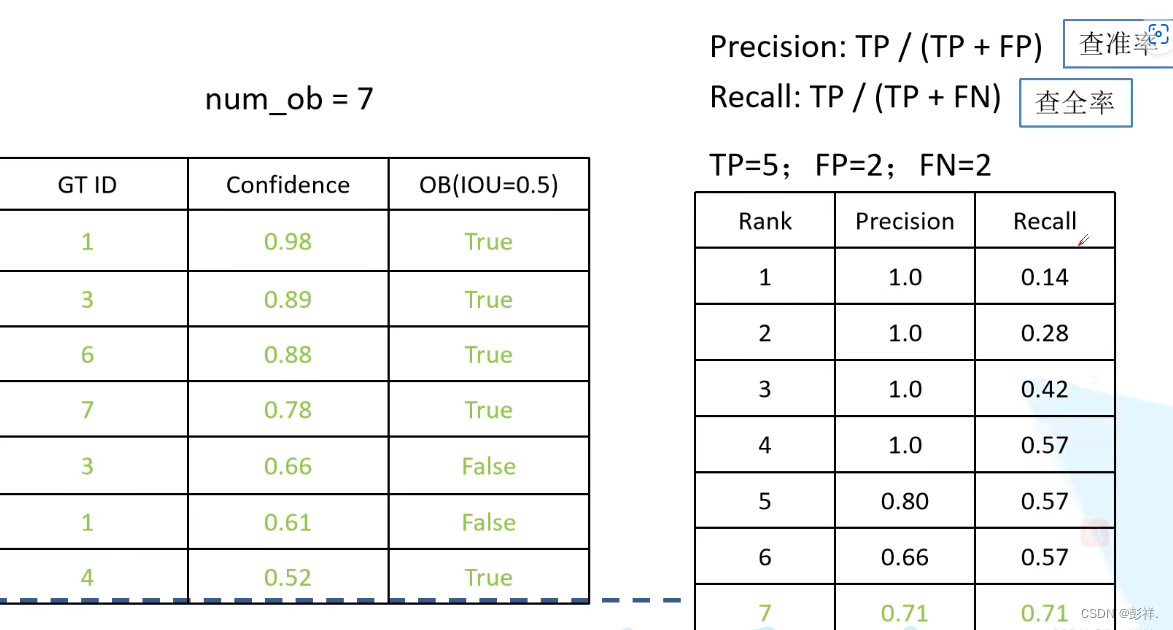
此时我们会得到右边的一张表格,按照这个表格,我们就可以绘制P-R曲线了,在绘制前需要删除一些Recall重复的数据,如图中的第五和第六个数据。
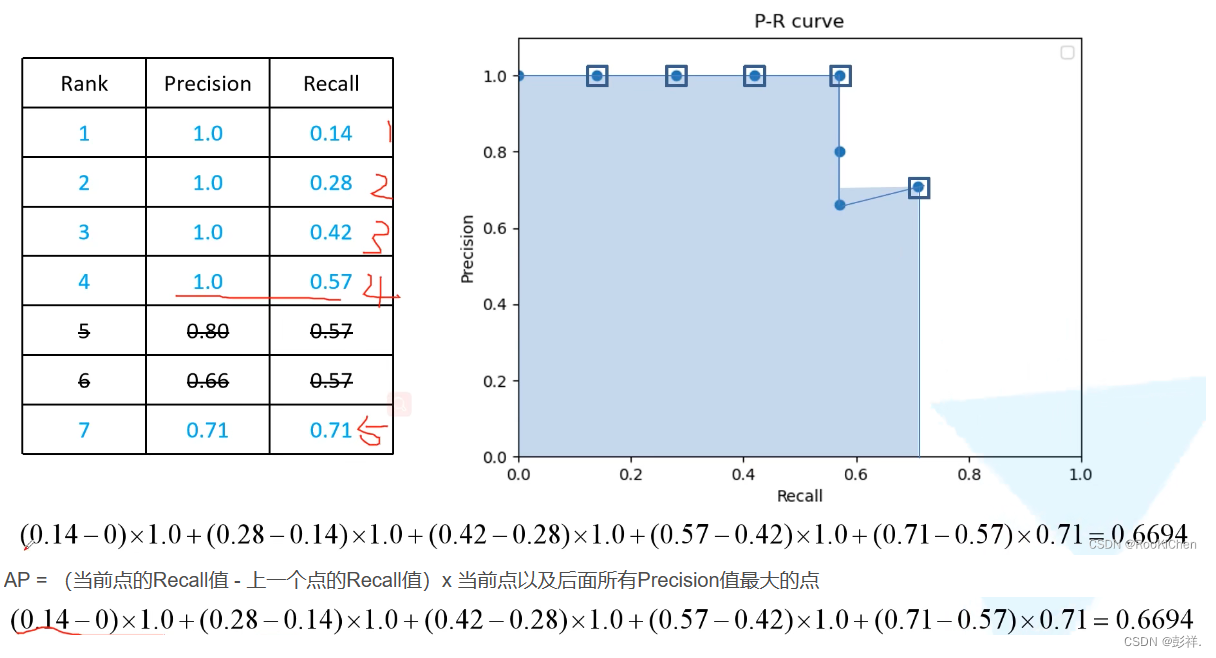
mAP(mean Average Precision)
上面的0.6694就是猫所对应的AP值,采用这个方法,我们可以计算出所有类别所对应的AP值,再除以类别的个数,就得到了map。
def get_map_txt(self, image_id, image, class_names, map_out_path):
f = open(os.path.join(map_out_path, "detection-results/"+image_id+".txt"), "w", encoding='utf-8')
image_shape = np.array(np.shape(image)[0:2])
#---------------------------------------------------------#
# 在这里将图像转换成RGB图像,防止灰度图在预测时报错。
# 代码仅仅支持RGB图像的预测,所有其它类型的图像都会转化成RGB
#---------------------------------------------------------#
image = cvtColor(image)
#---------------------------------------------------------#
# 给图像增加灰条,实现不失真的resize
# 也可以直接resize进行识别
#---------------------------------------------------------#
image_data = resize_image(image, (self.input_shape[1], self.input_shape[0]), self.letterbox_image)
#---------------------------------------------------------#
# 添加上batch_size维度
#---------------------------------------------------------#
image_data = np.expand_dims(np.transpose(preprocess_input(np.array(image_data, dtype='float32')), (2, 0, 1)), 0)
with torch.no_grad():
images = torch.from_numpy(image_data)
if self.cuda:
images = images.cuda()
#---------------------------------------------------------#
# 将图像输入网络当中进行预测!
#---------------------------------------------------------#
outputs = self.net(images)
outputs = self.bbox_util.decode_box(outputs)
#---------------------------------------------------------#
# 将预测框进行堆叠,然后进行非极大抑制
#---------------------------------------------------------#
results = self.bbox_util.non_max_suppression(torch.cat(outputs, 1), self.num_classes, self.input_shape,
image_shape, self.letterbox_image, conf_thres = self.confidence, nms_thres = self.nms_iou)
if results[0] is None:
return
top_label = np.array(results[0][:, 6], dtype = 'int32')
top_conf = results[0][:, 4] * results[0][:, 5]
top_boxes = results[0][:, :4]
for i, c in list(enumerate(top_label)):
predicted_class = self.class_names[int(c)]
box = top_boxes[i]
score = str(top_conf[i])
top, left, bottom, right = box
if predicted_class not in class_names:
continue
f.write("%s %s %s %s %s %s\n" % (predicted_class, score[:6], str(int(left)), str(int(top)), str(int(right)),str(int(bottom))))
f.close()
return