本篇文章的目的是帮助Kafka初学者快速搭建一个Kafka集群,以及怎么在SpringBoot项目中使用Kafka。
kafka集群环境包地址:百度网盘 请输入提取码 提取码:x9yn

一、Kafka集群搭建
1、准备环境
(1)准备三台LINUX服务器:
xxx.xxx.xxx.1
xxx.xxx.xxx.2
xxx.xxx.xxx.3
(2)jdk版本大于1.8即可,我是1.8.0_181
(3)在三台服务器上创建用户admin,将环境放到admin用户下,嫌麻烦的同学也可以直接使用root用户安装(真实生产上不建议这么做)
tips:LINUX怎么给普通用户赋文件夹操作权限?
- 切换到root用户
- 使用chown -R admin:admin /home/admin命令
- 执行su - admin命令就可以切换用户并定位到/home/admin下
(4)一定要关闭三台服务器的防火墙,不然安装肯定会出问题,切记!这个真的很重要!
2、搭建Zookeeper集群
(1)解压zookeeper-3.4.12.tar.gz,进入zookeeper文件夹

(2)进入conf文件夹
1)复制zoo.cfg文件 cp zoo.cfg zoo_sample.cfg 2)修改zoo.cfg文件 vim zoo.cfg

这里的3个IP的作用如下:
2181:对cline端提供服务
3888:选举leader使用
2888:集群内机器通讯使用(Leader监听此端口)
(3)进入data文件夹,若没有自己创建一个
在data文件夹下创建myid文件,三台机器分别填入server对应的ID,这里我是1、2、3

(4)启动zookeeper集群
- 1. 启动ZK服务: sh bin/zkServer.sh start
- 2. 查看ZK服务状态: sh bin/zkServer.sh status
- 3. 停止ZK服务: sh bin/zkServer.sh stop
- 4. 重启ZK服务: sh bin/zkServer.sh restart
(5)三台机器都需要重复上述操作,注意myid中的ID要对应
3、搭建Kafka集群
(1)解压kafka_2.12-2.5.0.tgz,进入kafka文件夹

(2)进入config文件夹,修改 server.properties内容
# Kafka使用唯一的一个整数来标识每个broker,该参数默认是-1。如果不指定,kafka会自动生成一个唯一值 broker.id=1 # broker监听器的CSV列表,格式是[协议]://[主机名]:[端口]。 listeners=PLAINTEXT://xxx.xxx.xxx.1:9092 # 非常重要的参数!该参数指定了kafka持久化消息的目录。该参数可以设置多个目录,以逗号分隔,比如/home/kafka1,/home/kafka2,多目录的做法是推荐的 log.dirs=/tmp/kafka-logs # 同样是很重要的参数!这个参数完全没有默认值,是必须要自己设置的 zookeeper.connect=xxx.xxx.xxx.1:2181,xxx.xxx.xxx.2:2181,xxx.xxx.xxx.3:2181 # 是否开启unclean leader选举。由于开始可能不能保证数据一致性,所以设置为false unclean.leader.election.enable=false # topic 在当前 broker 上的分区个数 num.partitions=1 # 用来恢复和清理 data 下数据的线程数量 num.recovery.threads.per.data.dir=1 # segment文件保留的最长时间,超时将被删除 log.retention.hours=16 # 删除 topic 功能使能 ( 允许删除数据 ) ( 手动指定 ) delete.topic.enable=true # 处理网络请求的线程数量 num.network.threads=3 # 用来处理磁盘 IO 的线程数量 num.io.threads=8 # 发送套接字的缓冲区大小 socket.send.buffer.bytes=102400 # 接收套接字的缓冲区大小 socket.receive.buffer.bytes=102400 # 请求套接字的缓冲区大小 socket.request.max.bytes=10485760
(3)配置环境变量
vim ~/.bash_profile # KAFKA_HOME export KAFKA_HOME=/export/servers/kafka_2.11-0.11.0.0 export PATH=$PATH:$KAFKA_HOME/bin
(4)启动kafka集群
启动 :bin/kafka-server-start.sh config/server.properties &
关闭 :bin/kafka-server-stop.sh stop
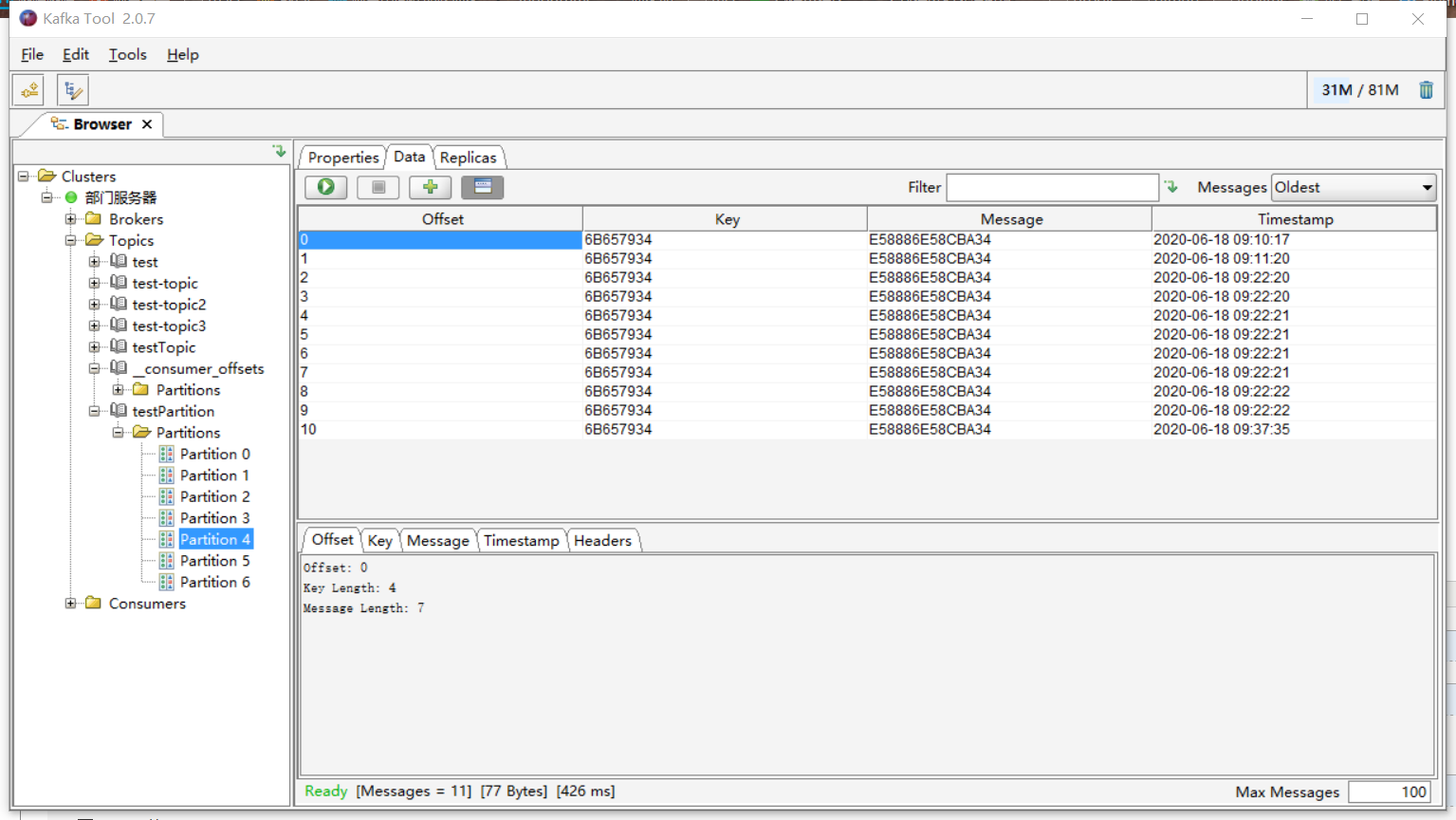
二、使用kafkatool工具操作Kafka
这里提供一篇详细操作:https://www.cnblogs.com/frankdeng/p/9452982.html
三、Kafka与SpringBoot集成
1、pom.xml导入
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.0.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.sunyard.bigdata</groupId>
<artifactId>springbootkafka</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>springbootkafka</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
2、application.properties配置
server.port=9001 spring.application.name=kafka #### kafka配置生产者 begin #### # 指定kafka server的地址,集群配多个,中间,逗号隔开 spring.kafka.bootstrap-servers=xxx.xxx.xxx.1:9092,xxx.xxx.xxx.2:9092,xxx.xxx.xxx.3:9092 # 写入失败时,重试次数。当leader失效,一个repli节点会替代成为leader节点,此时可能出现写入失败, # 当retris为0时,produce不会重复。retirs重发,此时repli节点完全成为leader节点,不会产生消息丢失。 spring.kafka.producer.retries=0 # 每次批量发送消息的数量,produce积累到一定数据,一次发送 spring.kafka.producer.batch-size=16384 # produce积累数据一次发送,缓存大小达到buffer.memory就发送数据 spring.kafka.producer.buffer-memory=33554432 #procedure要求leader在考虑完成请求之前收到的确认数,用于控制发送记录在服务端的持久化,其值可以为如下: #acks = 0 如果设置为零,则生产者将不会等待来自服务器的任何确认,该记录将立即添加到套接字缓冲区并视为已发送。在这种情况下,无法保证服务器已收到记录,并且重试配置将不会生效(因为客户端通常不会知道任何故障),为每条记录返回的偏移量始终设置为-1。 #acks = 1 这意味着leader会将记录写入其本地日志,但无需等待所有副本服务器的完全确认即可做出回应,在这种情况下,如果leader在确认记录后立即失败,但在将数据复制到所有的副本服务器之前,则记录将会丢失。 #acks = all 这意味着leader将等待完整的同步副本集以确认记录,这保证了只要至少一个同步副本服务器仍然存活,记录就不会丢失,这是最强有力的保证,这相当于acks = -1的设置。 #可以设置的值为:all, -1, 0, 1 spring.kafka.producer.acks=1 # 指定消息key和消息体的编解码方式 spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer #### kafka配置生产者 end #### #### kafka配置消费者 start #### # 指定默认消费者group id --> 由于在kafka中,同一组中的consumer不会读取到同一个消息,依靠groud.id设置组名 spring.kafka.consumer.group-id=test1 # smallest和largest才有效,如果smallest重新0开始读取,如果是largest从logfile的offset读取。一般情况下我们都是设置smallest spring.kafka.consumer.auto-offset-reset=earliest # enable.auto.commit:true --> 设置自动提交offset spring.kafka.consumer.enable-auto-commit=true #如果'enable.auto.commit'为true,则消费者偏移自动提交给Kafka的频率(以毫秒为单位),默认值为5000。 spring.kafka.consumer.auto-commit-interval=1000 # 指定消息key和消息体的编解码方式 spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer #### kafka配置消费者 end ####
3、启动类代码
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.kafka.annotation.EnableKafka;
@SpringBootApplication
@EnableKafka
public class SpringbootkafkaApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootkafkaApplication.class, args);
}
}
4、生产者代码
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api/kafka/")
public class KafkaController {
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
@GetMapping("send")
@ResponseBody
public boolean send(@RequestParam String message) {
try {
kafkaTemplate.send("test-topic", message);
kafkaTemplate.send("test-topic2", message);
System.out.println("消息发送成功...");
} catch (Exception e) {
e.printStackTrace();
}
return true;
}
@GetMapping("test")
@ResponseBody
public String test() {
System.out.println("hello world!");
return "ok";
}
}
5、消费者代码
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class ConsumerListener {
@KafkaListener(topics = "test-topic")
public void onMessage1(String message) {
System.out.println("我是第一个消费者:" + message);
}
@KafkaListener(topics = "test-topic2")
public void onMessage2(String message) {
System.out.println("我是第二个消费者:" + message);
}
}