ChatGPT的简答:
-
Redis的主从复制(Master-Slave Replication)是指将一个Redis服务器的数据复制到其他Redis服务器的过程,其中一个服务器作为主节点(Master),而其他服务器作为从节点(Slave)。主节点负责接收写操作并将数据同步到从节点,从节点负责接收主节点的同步数据并提供读服务。主从复制可以提升系统的性能和可靠性,实现数据的备份和故障恢复。
-
Redis的哨兵机制(Redis Sentinel)是一种用于监控和管理Redis实例的分布式系统。哨兵系统由多个独立的哨兵节点组成,它们能够监控主节点和从节点的健康状况,并在主节点宕机或出现其他故障时自动进行故障转移。哨兵机制提供了自动发现、故障检测、故障转移和选主等功能,保证了Redis系统的高可用性。
-
Redis的集群(Redis Cluster)是一种分布式解决方案,用于实现高可用和数据分片。集群将数据分散存储在多个Redis节点上,并使用一致性哈希算法进行数据分片。集群中的每个节点都是独立的,它们通过相互通信进行数据同步和故障转移,实现了数据的高可用性和负载均衡。
通过主从复制和哨兵机制,可以实现Redis的高可用性和故障恢复。而Redis集群则提供了分布式存储和负载均衡的能力,适用于大规模数据存储和高并发访问的场景。根据实际需求,在Redis中选择合适的架构和部署方案,可以满足不同的业务需求和系统要求。
为什么要用集群?
在了解Redis集群之前,我们先来了解Redis的主从复制和哨兵机制。
Redis的主从复制主要有两个作用:
- 读写分离,性能扩展,降低主服务器的压力
- 容灾,快速恢复,主机挂掉时,从机变为主机
哨兵机制:
- Redis 主从模式不具备自动容错和恢复功能,如果主节点宕机,Redis 集群将无法工作,此时需要人为干预,将从节点提升为主节点。
- 哨兵机制作用主要是监控主从节点,当主节点挂掉,通过内部投票机制,从 从节点当中选出一个主节点,这样可以避免人工成本。
虽然主从+哨兵采用了多节点,但是他们存在的目的主要是解决容灾问题,而并非性能问题。
那目前Redis性能存在什么问题?
- Redis 内存太大会导致 rdb文件过大,进一步导致主从同步时全量同步时间过长,在实例重启恢复时也会消耗很长的数据加载时间,特别是在云环境下,单个实例内存往往都是受限的。
- 单个 Redis 实例只能利用单个核心,这单个核心要完成海量数据的存取和管理工作压力会非常大。
- 单台redis内存容量限制,如何进行扩容?继续加内存、加硬件么?
互联网分布式架构设计,提高系统并发能力的方式,方法论上主要有两种:垂直扩展(Scale Up)与水平扩展(Scale Out)。
-
垂直扩展:提升单机处理能力。增强单机硬件性能,例如:增加CPU核数如32核,升级更好的网卡如万兆,升级更好的硬盘如SSD,扩充硬盘容量如2T,扩充系统内存如128G;
-
水平扩展:只要增加服务器数量,就能线性扩充系统性能。水平扩展对系统架构设计是有要求的,如何在架构各层进行可水平扩展的设计,以及互联网公司架构各层常见的水平扩展实践,是本文重点讨论的内容。
在互联网业务发展非常迅猛的早期,如果预算不是问题,强烈建议使用“增强单机硬件性能”的方式提升系统并发能力,因为这个阶段,公司的战略往往是发展业务抢时间,而“增强单机硬件性能”往往是最快的方法。
单机性能总是有极限的。所以互联网分布式架构设计高并发终极解决方案还是水平扩展。
Redis性能问题如何解决?
正是在这样的大数据高并发的需求之下,Redis 集群方案应运而生。redis集群是对redis的水平扩容,即启动N个redis节点,将整个数据分布存储在这个N个节点中,每个节点存储总数据的1/N。
如下图:由3台master和3台slave组成的redis集群,每台master承接客户端三分之一请求和写入的数据,当master挂掉后,slave会自动替代master,做到高可用。
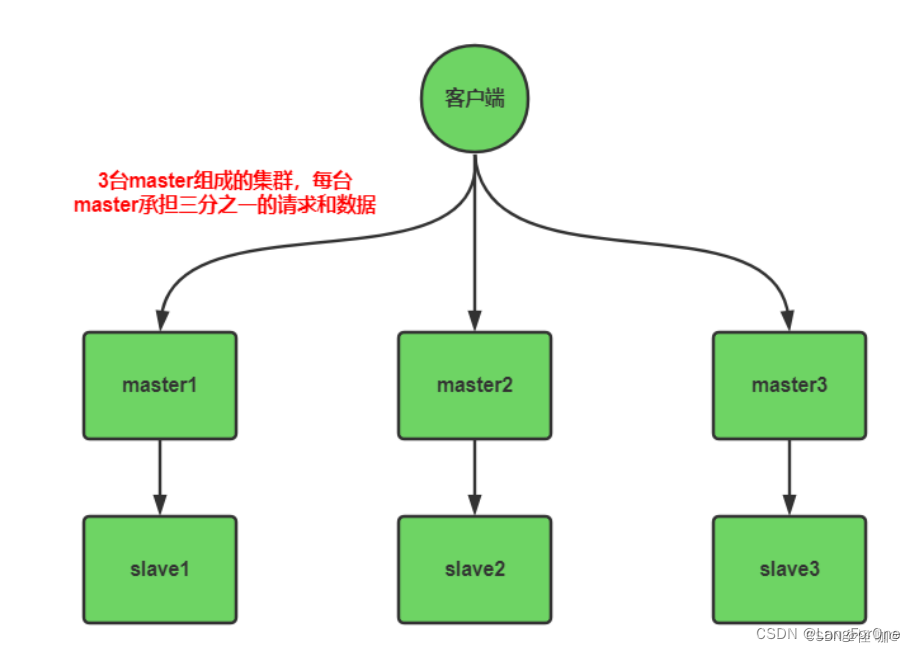
集群的介绍
为什么需要集群呢?
在之前的哨兵当中,一旦Main挂掉了,就势必会导致一段时间内的数据写不进去了,当并发量很大的时候这势必是一个比较大的问题
集群就说为了解决这个问题而诞生的。
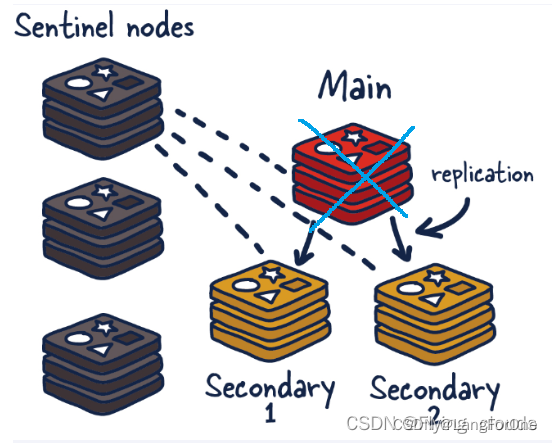
什么是集群?
-
由于数据量过大,单个Master复制集难以承担,因此需要对多个复制集进行集群,形成水平扩展每个复制集只负责存储整个数据集的一部分,这就是Redis的集群,其作用是提供在多个Redis节点间共享数据的程序集。
-
Redis集群是一个提供在多个Redis节点间共享数据的程序集
-
Redis集群可以支持多个Master
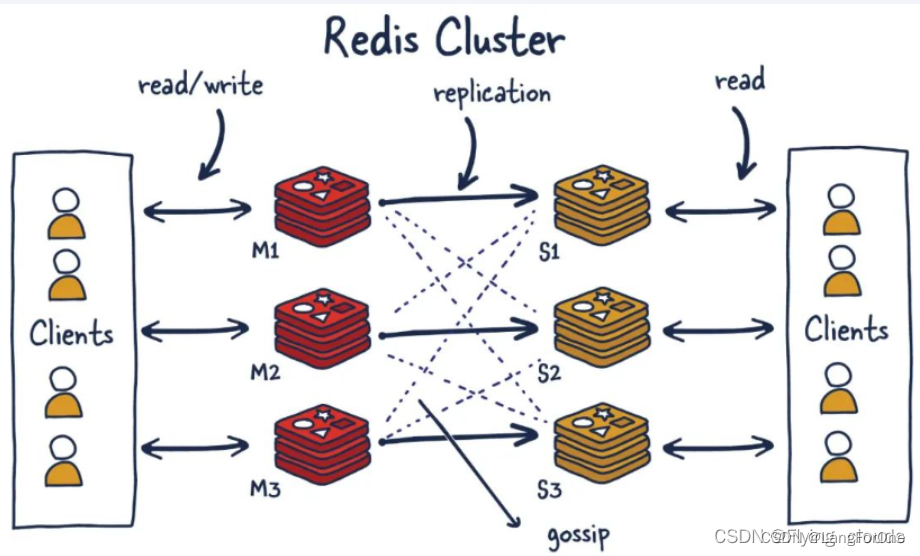
集群能干什么呢?
- Redis集群支持多个Master,每个Master又可以挂载多个Slave
- 读写分离
- 支持海量数据的高可用
- 支持海量数据的读写存储操作
- 由于Cluster自带Sentinel的故障转移机制,内置了高可用的支持,无需再去使用哨兵功能
- 客户端和Redis的节点连接,不再需要连接集群中所有节点,只需连接集群中的任意一个可用节点即可(一个有所有都有了)
- 槽位slot负责分配到各个物理服务节点,由对应的集群来负责维护节点、插槽和数据之间的关系
集群的实现
slot 槽位映射的三种算法
1、哈希取余分区(小厂)
2、一致性哈希(中厂)
3、哈希槽分区
关于集群的算法之分片&槽位slot详解参考:
集群的算法之分片&slot槽位、slot 槽位映射的三种算法
实现数据分片的三种方案
- 客户端分片:客户端通过固定的Hash算法,针对不同的key计算对应的Hash值,然后对不同的Redis节点进行读写。说白了就是自己实现分片算法。这样对于程序代码侵入性太强,一般也很少有人会这么搞。
- 代理分片:理解为业务只连一个代理应用,代理应用后面会控制连接哪些实例。对于代理现在已经有两个现成可使用的,分别是Twemproxy、Codis。
- Redis Cluster:Redis3.*自带的应用。Redis Cluster将所有Key映射到16384个Slot中,集群中每个Redis实例负责一部分,业务程序通过集成的Redis Cluster客户端进行操作。客户端可以向任一实例发出请求,如果所需数据不在该实例中,则该实例引导客户端自动去对应实例读写数据。

在早期搭建集群很多都是采用代理分片,因为当时redis cluster发布得比较晚(2015年才发布正式版 ),各大厂等不及了,陆陆续续开发了自己的redis数据分片集群模式,比如:Twemproxy、Codis等。都属于当时的产物,现在codis已经彻底不更新了,而Twemproxy更新速度非常缓慢。所以基本上现在搭建集群都是使用官方的Redis Cluster!
关于集群之数据分片的三种方案实现详解参考:
Redis 集群方案应该怎么做?都有哪些方案?



![[AutoSAR系列] 1.3 AutoSar 架构](https://img-blog.csdnimg.cn/img_convert/2bd7acf4ec67ae190cb4dc7b0a202941.jpeg)







![一、PHP环境搭建[phpstorm]](https://img-blog.csdnimg.cn/2e76ed6278314a99890a21337e7fa99a.png)
