文章目录
- 前言
- 数据格式
- 部分代码
- 训练参数
- 接下来的尝试
- 总结
前言
随着大模型的爆火,很多垂域行业都开始使用大模型来优化自己的业务,最典型的方法就是RAG(检索增强生成)了。简单来说就是利用检索技术,找出与用户问题相关性最高的段落,再让LLM基于以上段落,去回答用户的提问。这样的事情,在CSDN的时候其实也做过一次,参考:CSDN问答机器人。只不过当时是在SBERT模型上微调,也取得了不错的效果。这里我们使用的基座模型是BAAI/bge-large-zh-v1.5。
数据格式
{"query": str, "pos": List[str], "neg":List[str]}
{"query": "小孩做胃镜有哪几种方法", "pos": ["儿童做胃镜常用的方法有如下两种:1、有痛胃镜,不在麻醉状态下做胃镜;2、无痛胃镜,在麻醉状态下做胃镜。国内通用的方法,不建议麻醉。因为小孩子麻醉,有很多副反应,包括麻醉药本身的副作用和麻醉后的复苏,都有副反应。不麻醉,即不使用麻醉药,目前通用的方法是抓麻,即把小孩抓住,做胃镜。这种情况虽然恢复快,但也有不好的地方。因为小孩害怕做该检查。在不麻醉非常清楚的情况下,做检查时比较痛苦,虽然过程比较短暂,但是对以后的心理上会造成一定阴影和压力。综合利弊就是这两种各有各的好处和不好的地方。对于患儿配合度较好的,建议不使用麻醉。对于不配合甚至极不配合的患儿,建议麻醉做胃镜做相关检查。"], "neg": ["胃镜检查在临床上是非常常用的,而且是非常有效的一个检查方式。其实在国外,尤其是在日本、欧美一些国家,它是被列为体检检查的,不是有症状了才来查,而是到了一定年龄就应该做这项检查。有些胃的早期病变,比如胃早癌、萎缩性胃炎,它临床上是没有症状的或者症状很轻微,很难被早期发现,所以胃镜检查非常重要。做胃镜检查一般分成两种方式:一、普通的胃镜。给病人口服一支利多卡因胶浆,它主要是起到麻醉咽部的作用,减少胃镜的痛苦,在常规的清醒状态下就可以做胃镜。二、无痛胃镜。无痛胃镜其实就是一种麻醉胃镜,就是用一种静脉麻醉的方式让他睡着,就没有痛苦的这种反应了,再做胃镜检查。这两种检查的效果相同,但是如果病人比较敏感,咽部的反射比较强烈,建议还是做无痛胃镜,这样检查的效果更好。关于费用,一个普通的胃镜加上胃镜之前要做一些抽血的检查,主要是筛查传染病,费用大概在500-800块钱左右。如果是麻醉胃镜或者无痛胃镜,费用相对来说,因为它有麻醉的费用,包括一次性耗材的使用,可能费用在2000块钱左右。", "做胃镜并非就诊当天就能做胃镜,也不是任意时间均可做胃镜。胃镜检查之前要先预约,中国人看病,很多情况下来了就要看病,或进医院就要检查,这种习惯逐渐在改变,必须提前预约。因为做胃镜需要达到一定要求:第一,身体要达到一定要求。不能有严重心肺疾病,不能有严重的精神疾病,口腔、咽部及存在一些其他的症状,这些情况不能做胃镜。如颈椎有严重脱位也不能做胃镜,做胃镜是有禁忌症的。做胃镜前医生需要给患者讲解清楚,同时让患者签一张知情同意书。如选择做无痛胃镜更需要提前预约,医生需讲清楚某些状况下不能做无痛胃镜,因为使用无痛药物后会诱发某些疾病发作。做胃镜前一定要先预约,医生会告之其注意事项。基本注意事项是,如第二天上午做胃镜,需要禁食,前一日晚上晚饭后应禁食,第二日早晨也不需禁食,最好达到8小时。即使在这种情况下,部分人胃动力不好,置入胃镜后会出现胃潴留,发生胃潴留做胃镜是没有效果的。首先胃潴留后因为胃内有很多食物导致看不到病变部位,其次胃阻流时做无痛胃镜,会发生反流,造成窒息,这是很危险的情况。因此做胃镜前需要禁食、禁水一定的时间。某些特殊疾病做胃镜时,医生会告知注意事项。如为糖尿病及高血压患者需做胃镜,糖尿病患者早上需注射胰岛素或口服降糖药,做胃镜要求术晨禁食,所以对于糖尿病及高血压病人医生会进行术晨用药指导,告之何时服药。总之,做胃镜前有很多要求,一定要在做胃镜前,去内镜室与医生联系,确定注意事项。", "胃镜是检查胃癌的金标准,分为普通胃镜、镇静胃镜、胶囊胃镜和全麻胃镜,通过检查可发现胃黏膜病变情况,亦可由病理活检确诊胃癌。除此之外,CT检查可发现胃肿瘤的局部侵犯情况,包括肝、肺或其它脏器是否发生转移,以确定肿瘤分期及淋巴结分期,进而确定患者是否适合进行手术治疗,若不适于手术则建议采取化疗或放疗手段,以为患者选择最佳的治疗方案。其中,患者进行胃镜检查当天清晨需禁食,并口服局麻药物,以减轻检查过程中的咽喉部反应;或给予镇静药物或剂量稍重的麻醉药物,以行镇静胃镜或全麻胃镜检查,减轻患者不适感。", "这个问题可能做过的患者就很清楚,没做过的患者都会有疑虑,特别是很多患者会害怕胃镜检查。经常碰到患者跟我说,犹豫了几个月都没敢来做,最后下定决心终于来做了,结果发现原来胃镜也不是那么难受,当然他是做的无痛的胃镜检查。其实胃镜检查从外行来看是个很简单的过程,患者躺在病床上左侧卧位,然后医生通过一条软管从口腔咽喉进入食道,然后再进入胃进入十二指肠。在进和退的过程中进行各个部位的仔细观察,医生会在这个过程中得出结论、诊断,所以还是比较简单快捷的检查。有经验的医生一般在5min之内,当然如果有特殊情况,比如胃里面有一些病变需要活检或者治疗,可能会需要的时间更长一点。", "胃镜检查前需空腹6-8小时,前1天晚餐进食少渣、易消化食物,检查当天避免进食辛辣热烫食物,检查前取出活动性假牙。高血压、糖尿病患者需根据实际情况,在医生指导下选择性服药。胃镜检查过程中可出现恶心、呕吐、腹胀、腹痛等情况,积极配合工作人员指导,多数患者均能够顺利完成检查。检查前使用局部麻药者,术后2小时再饮水进食,以免引起呛咳。根据个体情况术后暂停1-2天阿司匹林、华法林、波立维、泰嘉等药物;若患者检查后出现剧烈腹痛、呕吐、出血等情况,需及时就医诊治。", "做胃镜前的注意事项如下:1、根据医生判断,患者病情应符合检查指征;2、检查当天早晨保持空腹,检查前进行血象化验;3、检查前需停服部分药物,如服用阿司匹林、三七等活血化瘀、抗凝药物者,检查前应在医生指导下尽量停药一周,以保证检查的安全性;由于检查过程中,可能发现可疑病变,需取活检,若服用抗凝药,可能出现出血量较多的情况。", "做无痛胃镜时,患者要保证胃内的食物已经彻底排空,有些患者有胃潴留或胃蠕动的障碍,不建议做胃镜。医生会给患者注射些短效的麻醉药物,使患者处于睡眠状况,医护人员会使用特殊的监测设备监测患者的生命体征,如心率、呼吸、血氧等,最后医生会将胃镜管缓慢插入胃内进行观察。过程中患者的感觉较轻,多数情况下不会出现特殊的不适。检查以后医生会叫醒患者,患者早期会有些头晕不适症状,一般会缓慢自行消失。医生在做完胃镜以后,要嘱咐患者在3天之内尽量不要吃不易消化的食物以及刺激性的辛辣食物。", "无痛胃镜是借助麻醉医生给患者从静脉输入一种短效的麻醉药物,输完麻醉药物以后病人很快进入睡眠状态,然后在病人睡眠状态下,内镜医生进行常规的内镜操作,操作完以后病人就会立刻清醒。所以在这个过程中做无痛胃镜是有一定危害的。具体危害有以下几点:1、有些患者会对麻醉药品出现过敏反应,或者中毒反应,出现呼吸或心跳加快,会出现麻醉意外,甚至病人会昏迷;2、麻醉药品都有一定的呼吸抑制,当出现有呼吸道梗阻或者呼吸抑制时,病人会出现呼吸困难,这时也是比较危险的;3、有些病人会出现胃内容物反流入气管而出现麻醉意外。有些患者有呼吸道情况,比如咳嗽、哮喘、心功能不全,这些患者的无痛胃镜属于禁忌症,其完全不能做无痛胃镜。", "胃镜检查是一种有创检查,可对患者造成一定的生理痛苦。年龄较大或既往有心脏病史的患者,应先通过心电图排查,患明确胃部疼痛等症状是否因心脏病引起,因心梗病人做胃镜后可直接损害心脏,应尽量避免。另外肝炎、HIV等传染病患者也不适宜进行胃镜检查,因胃镜反复利用,有造成医源性交叉污染的可能。", "无痛胃镜需要进行全身麻醉,其危害如下:1、静脉麻药可引起呼吸抑制、呛咳、恶心、呕吐,尤其在饱胃状态下,患者出现恶心、呕吐的可能性会大大提高,所以全身麻醉前需禁食6-8小时;2、患者被麻醉后,意识会丧失,咽喉反射也会消失,可能出现误吸,严重者可导致当场窒息死亡。所以全麻手术若非急诊,一定要保证足够的禁食时间。"]}
具体的样例参考官方的吧:https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune
其实官方的readme已经说的很明白了,官方说过的我就不赘述了,我这里主要讲一下数据集的构造过程。
我做了两种尝试:
第一种
1、使用bge基础模型将所有数据向量化
2、对每个query召回top10
3、计算top10的重排得分
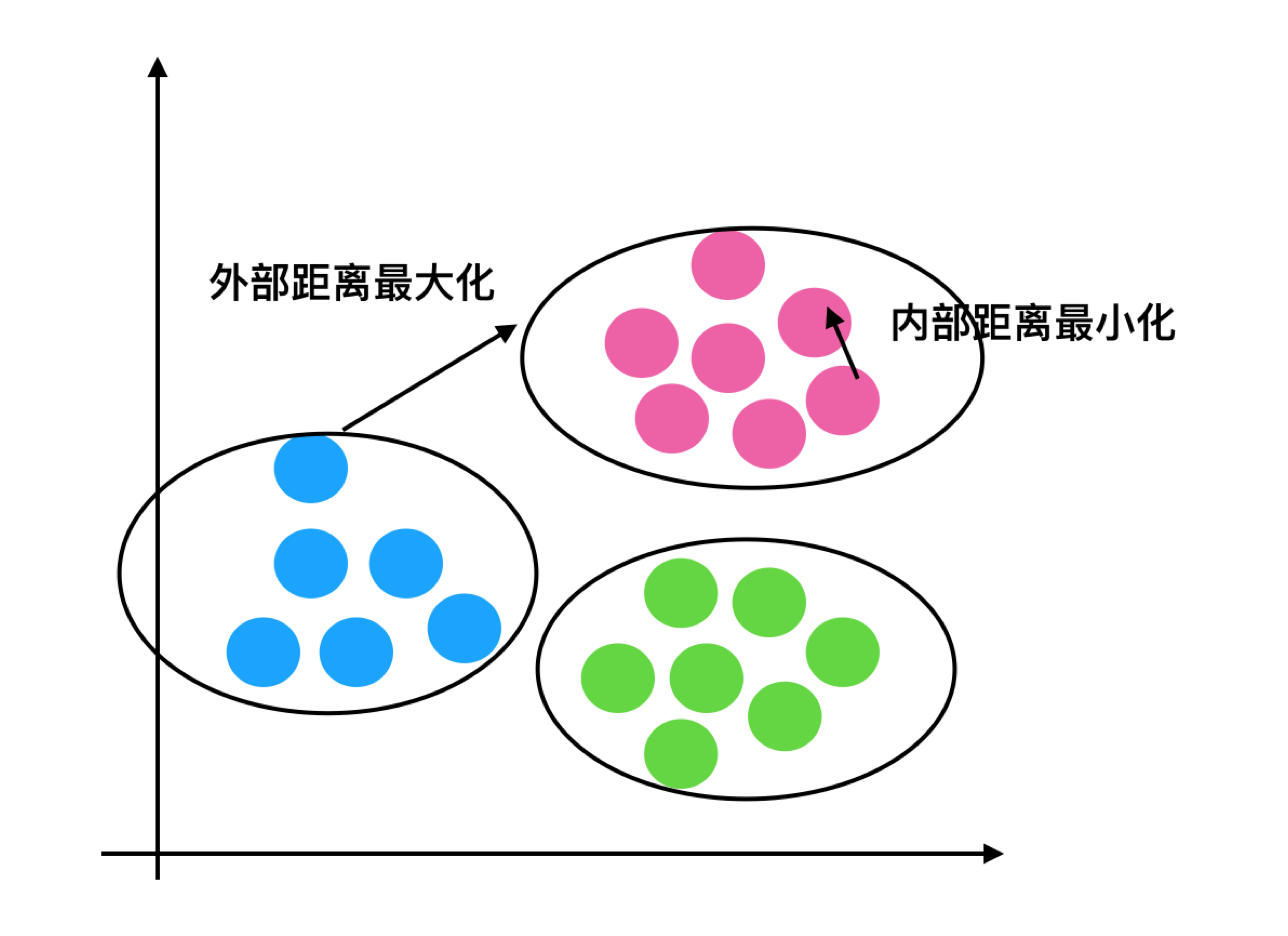
4、两两计算query、answer、target_query、target_answer的bge cos相似度、jaccard系数、lcs、编辑距离等
5、使用重排得分、bge相似度、jaccard等相似度组合策略,筛选出训练数据
大概有这么些字段:
writer.writerow(["query", "answer", "target_query", "target_answer", "rerank_score",
"query_tgt_query_bge_cos", "query_tgt_query_lcs_score", "query_tgt_query_edit_dist", "query_tgt_query_jaccard",
"answer_tgt_query_bge_cos", "answer_tgt_query_lcs_score", "answer_tgt_query_edit_dist", "answer_tgt_query_jaccard",
"query_tgt_answer_bge_cos", "query_tgt_answer_lcs_score", "query_tgt_answer_edit_dist", "query_tgt_answer_jaccard",
"answer_tgt_answer_bge_cos", "answer_tgt_answer_lcs_score", "answer_tgt_answer_edit_dist", "answer_tgt_answer_jaccard"
])
说实话有点多,要结合这么多字段筛选数据,也不是件容易的事情
第二种
1、使用bge基础模型将所有数据向量化
2、对每个query召回top100
3、过滤出 0.4 < distance <= 0.7 的数据作为负样本
可见,第二种方法简单很多,利用查询出来的top100设定阈值筛选出训练数据(不同数据集阈值不同,可根据自己的实际情况设置)。
说明一下:
我的场景是query-passage,即匹配出与query最相关的段落。
理论上,第一种方法构造出来的数据会更好,但实际操作起来会发现,这种方法会非常耗时,即使使用多GPU并行、多进程等优化处理,二十万数据,还是需要将近一天的时间(因机器性能而异),我使用这种方法构造了一批数据,训练出来的模型效果比基座模型还要差几十个点,主要原因是困难负例样本没有构造好,困难样本量也不够,时间充裕的同学可以尝试下召回Top100试试,理论上应该会效果更好才对!
最后实际使用的是第二种方法,相比基座模型top100召回率提升了5.7%,还有优化的空间。
部分代码
class BuildTrainData:
def __init__(self, config, options):
model_path = "bge-large-zh-v1.5"
data_path = "src_data.csv"
logger.info("加载原始数据...")
self.data = pd.read_csv(data_path)
logger.info(f"从 {model_path} 加载向量化模型...")
self.model = SentenceTransformer(model_path)
self.model.eval()
self.batch_size = 32
self.faiss_measure = faiss.METRIC_L2
self.index_type = "HNSW64"
file_name = data_path.split('/')[-1].split('.')[0]
save_dir = "./data/models/bge_ft"
if not os.path.exists(save_dir):
os.makedirs(save_dir, exist_ok=True)
self.embedding_path = f"{save_dir}/embedding_{file_name }.pkl"
self.faiss_index_path = f"{save_dir}/faiss_{file_name }.index"
self.bge_train_data_path = f"./data/datasets/bge/train/{embedding_name}_train.jsonl"
def embedding(self, text_list):
logger.info("向量化...")
embeddings = self.model.encode(text_list, self.batch_size, show_progress_bar=True)
return embeddings
def embedding_mul_gpu(self, text_list):
logger.info("多GPU并行向量化...")
# 通过target_devices指定GPU,如target_devices=['cuda:0', 'cuda:1']
pool = self.model.start_multi_process_pool()
embeddings = self.model.encode_multi_process(text_list, pool, batch_size=self.batch_size)
self.model.stop_multi_process_pool(pool)
return embeddings
def build_faiss_index(self):
if os.path.exists(self.faiss_index_path):
logger.info(f"{self.faiss_index_path}已存在...")
faiss_index = faiss.read_index(self.faiss_index_path)
embeddings = joblib.load(self.embedding_path)
return faiss_index, embeddings
logger.info("从本地加载向量化的数据...")
embeddings = joblib.load(self.embedding_path)
dim = embeddings.shape[1]
faiss_index = faiss.index_factory(dim, self.index_type, self.faiss_measure)
logger.info("构建索引...")
faiss_index.add(embeddings)
faiss.write_index(faiss_index, self.faiss_index_path)
return faiss_index, embeddings
def compute_retrival(self, mul_gpus=None, retrival_topk=100):
logger.info("挖掘困难样本...")
query_list = self.data["query"]
# query = "为这个句子生成表示以用于检索相关文章:" + row["query"]
if not os.path.exists(self.embedding_path):
logger.info("embedding 文件不存在, 重新embedding...")
if not mul_gpus:
logger.info("只使用一个GPU...")
query_embedding = self.embedding(self.data["text"])
else:
logger.info("多GPU加速...")
query_embedding = self.embedding_mul_gpu(self.data["text"])
joblib.dump(query_embedding, self.embedding_path)
faiss_index, query_embedding = self.build_faiss_index()
logger.info("开始处理数据...")
distances, indexs = faiss_index.search(query_embedding, retrival_topk)
for idx, query in enumerate(tqdm(query_list, desc="挖掘困难样本")):
answer = self.data["text"][idx]
if query in set(self.has_processed_list):
# logger.info(f"{query} 已处理过...")
continue
target_answers = []
# dist越小越相似
neg_samples_tune = []
for dist, df_idx in zip(*[distances[idx], indexs[idx]]):
if df_idx == -1:
# logger.info(f"bade index {df_idx}")
continue
target_query = self.data["query"][df_idx]
if target_query == query:
continue
target_answer = self.data["text"][df_idx]
if target_answer == answer:
continue
if dist > 0.4 and dist <= 0.7:
target_answers.append(target_answer)
elif dist > 0.7:
neg_samples_tune.append(target_answer)
if len(target_answers) == 0:
# logger.info(f"query: {query} 无负样本")
target_answers = neg_samples_tune
if len(target_answers) == 0:
# logger.info(f"query: {query} 无负样本")
continue
elif len(target_answers) > 10:
target_answers = random.sample(target_answers, 10)
meta = {
"query": query,
"pos": [answer],
"neg": target_answers
}
with jsonlines.open(self.bge_train_data_path, 'a') as f:
f.write(meta)
src_data.csv包含了两个字段,分别是query、text,query是问题,text是包含该问题答案的段落
整体过程挺简单的,最重要的就是合理地构造困难负例,这个过程需要尝试不同地阈值,分析构造出来的数据是否准确。
认真看了官方文档的同学,肯定发现了官方其实也做了困难样本挖掘,如下:

阅读了源码后发现,官方的困难样本挖掘,只是个简单的例子,同样也是取出TopN的数据,但官方是直接从range_for_sampling 范围内随机抽样,肯定没有我们从0.3-0.7的范围内抽样更好,实际上,应该按照distance排序,然后从大于0.3的distance的样本中从小到大取N条。
注: distance越小表示越相似
训练参数
torchrun --nproc_per_node 8 \
-m FlagEmbedding.baai_general_embedding.finetune.run \
--output_dir bge-large-zh-medical-v2.1 \
--model_name_or_path ./BAAI/bge-large-zh-v1.5 \
--train_data train_src_v2_train.jsonl \
--learning_rate 1e-5 \
--fp16 \
--num_train_epochs 5 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 32 \
--dataloader_drop_last True \
--normlized True \
--temperature 0.02 \
--query_max_len 256 \
--passage_max_len 512 \
--train_group_size 6 \
--logging_steps 10 \
--logging_strategy steps \
--query_instruction_for_retrieval "" \
--report_to tensorboard \
--save_steps 100 \
--save_strategy steps \
--save_total_limit 10
我这里没有加query_instruction_for_retrieval ,官方建议是说检索任务最好加query_instruction_for_retrieval,效果会更好些,但是在我这个场景中,加了query_instruction_for_retrieval反而效果更差,差了2%左右。
参数解释看官方说明吧,说实话个人觉得官方的教程写的非常详细了:

重点: batch_size一定要大,显存不够就结合gradient_accumulation_steps 一起使用,小batch_size训练过程中loss非常抖,而且效果很差:
比如:
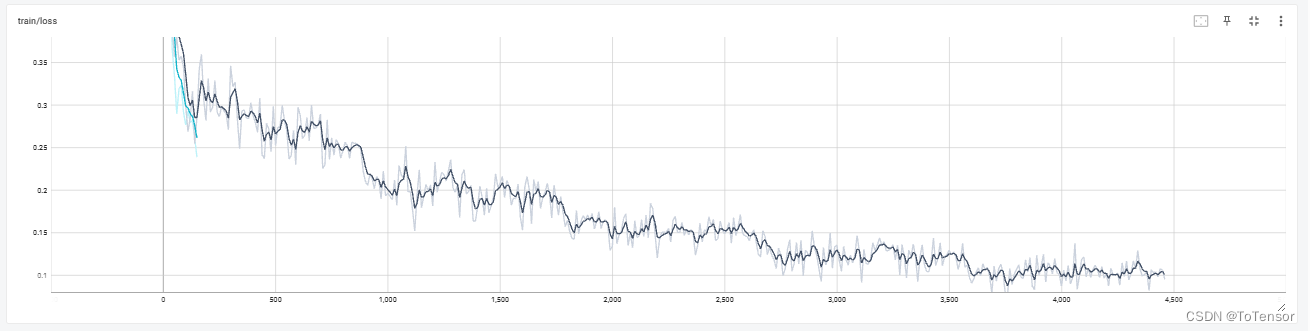
同一个epoch内loss非常抖,效果比基座模型效果还差。
再来看个大batch_size的
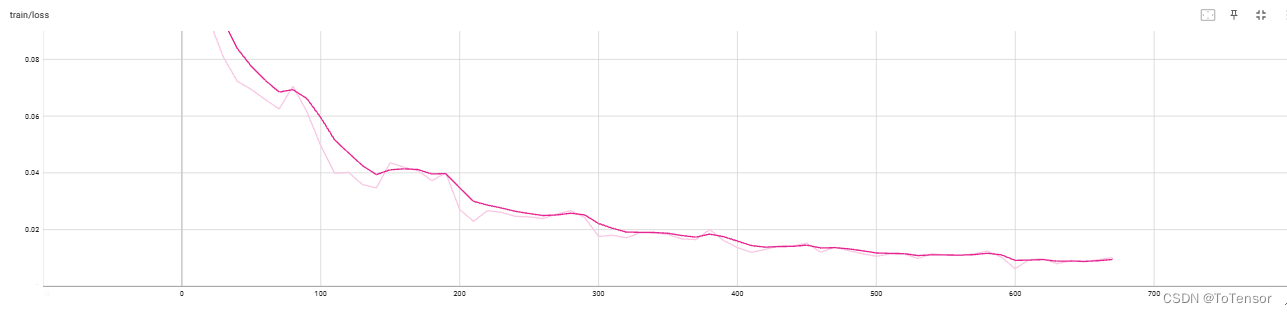
稳定得很。
接下来的尝试
1、使用训练好的向量模型去构造困难样例,再重新训练基座模型,效果会不会更好?(套娃?)
2、将负样本从阈值区间采样改为取相对来说更相近的前TopK个
总结
1、领导要求提高10%以上,没有标注数据的情况下,感觉还是很难的
2、各位大佬要是有想法,欢迎在评论区留言一起讨论
![一、PHP环境搭建[phpstorm]](https://img-blog.csdnimg.cn/2e76ed6278314a99890a21337e7fa99a.png)