根据博文:TensorFlow2.x模型转onnx、TensorRT给出的环境来配置。
以下是该博文中给出的版本信息
TensorFlow 2.4
CUDA 11.1
CUDNN 8
TensorRT 8.2.1.8
tf2onnx 1.13.0
onnx 1.12.0
下载地址
| 包 | 下载地址 |
|---|---|
| TensorRT 8.2.1.8 | https://developer.nvidia.com/nvidia-tensorrt-8x-download |
| CUDA | https://developer.nvidia.com/cuda-toolkit-archive |
| CUDA11.1 | https://developer.nvidia.com/cuda-11.1.1-download-archive |
| CUDNN 8.1.1 | https://developer.nvidia.com/rdp/cudnn-archive |
下载的文件名:
cuda_11.1.1_456.81_win10.exe
cudnn-11.2-windows-x64-v8.1.1.33.zip
TensorRT-8.2.1.8.Windows10.x86_64.cuda-11.4.cudnn8.2.zip:这个文件名应该是支持最大版本的cuda为11.4,cudnn为8.2,选择下面箭头这个(虽然箭头指的那个文件解释可以支持11.5版本的CUDA,我也不知道为啥文件名只写到了11.4)
不知道为什么上面这个截面下载的TensorRT安装包不能解压,出现以下问题
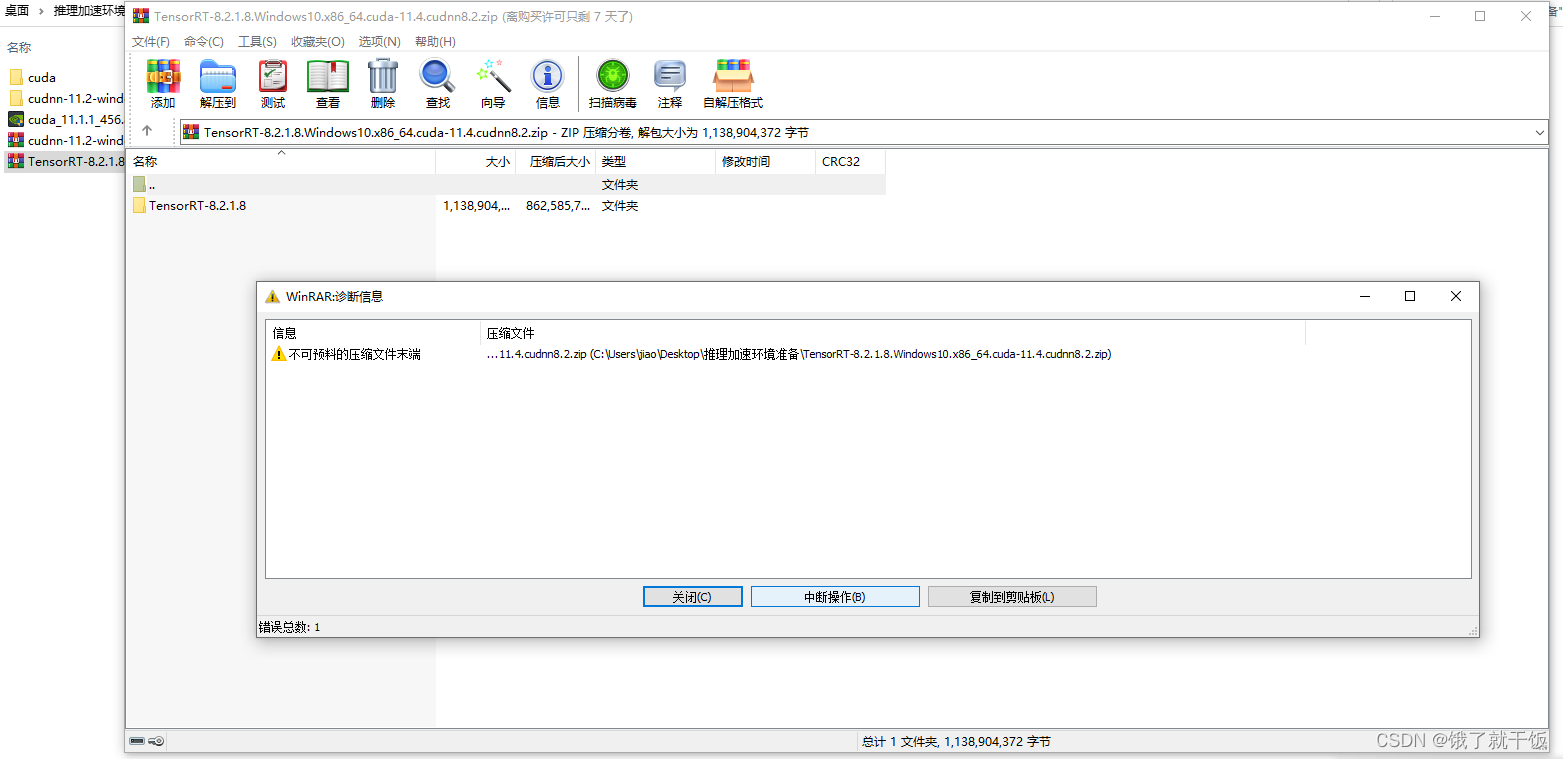
因此,更换一个版本的TensorRT,找了下面这个,8.4版本的,如下图:

不是版本的问题,是网络的问题,由于网络不稳定,下载的文件包会出错。这个结论出自:RAR/ZIP压缩文件解压提示文件损坏或无法解压原因及修复办法全解析,后来用手机的热点网络加上VPN下载好了可以直接解压的文件。
下载好安装一下试试
tensorrt各版本的介绍文档:https://docs.nvidia.com/deeplearning/tensorrt/release-notes/#rel_8-0-1
安装
1、安装cuda、cuDNN
安装这两个都可以参考:Windows10下多版本CUDA的安装与切换 超详细教程
2、安装TensorRT
两种方法:
1)将TensorRT的中的文件按照下面的方法直接复制粘贴到相应的文件下
2)将TensorRT的文件加入到环境变量中
两者作用是一样的,网上的配置方法不外乎这两种,我就选最麻烦的第一种
2.1 法1:文件复制粘贴
配置TensorRT(忽略下面三行字的中提到的版本号):
将 TensorRT-7.2.3.4\include 中头文件 copy 到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\include;
将 TensorRT-7.2.3.4\lib 中所有lib文件 copy 到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\lib\x64;
将 TensorRT-7.2.3.4\lib 中所有dll文件copy 到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\bin;
上面三行字参考链接:https://blog.csdn.net/m0_37605642/article/details/127583310
换句话说就是将TensorRT-8.2.0.6文件夹中的include文件所有文件移动到CUDA文件夹下的include里面,TensorRT-8.2.0.6文件夹中的lib中的dll与lib文件分别放到CUDA下的bin与lib\x64文件夹中(也是参考了多个博文的多个说法)
按照这个意思安装TensorRT8版本
2.2 法2:将 TensorRT的文件的路径放到环境变量中
C:\Users\admin\Downloads\Compressed\TensorRT-8.2.1.8\lib
2.2 pip安装包内的whl文件
参考:windows下安装tensorrt(python调用)
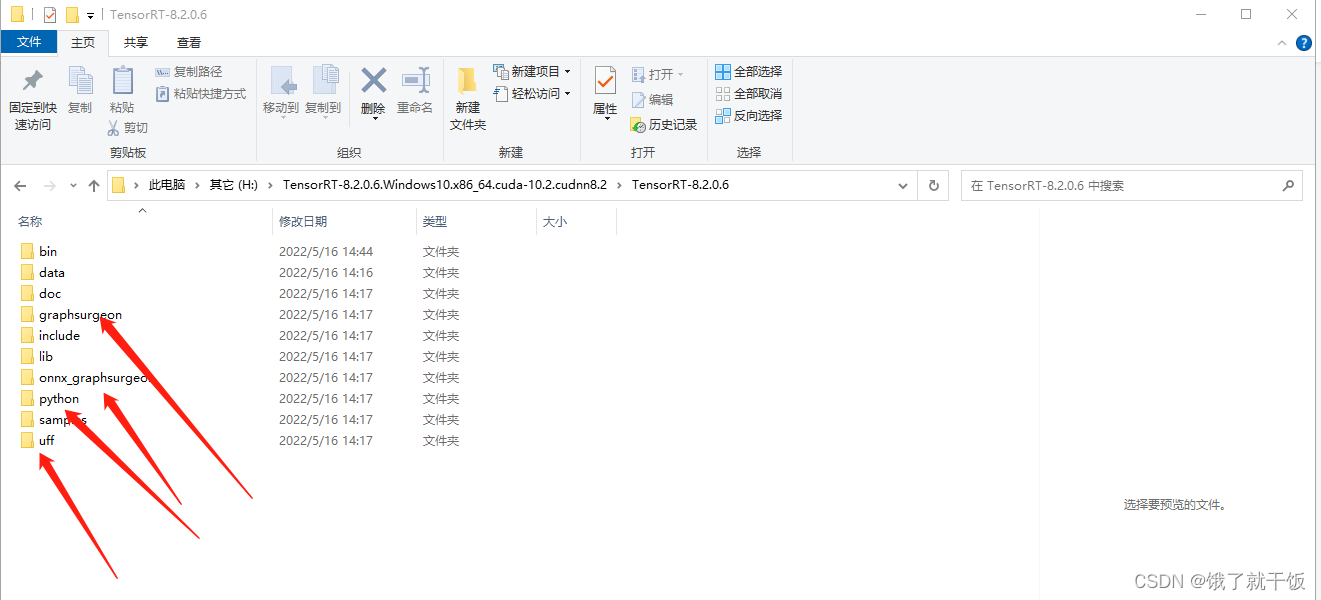
一共需要安装4个whl文件如下箭头的文件夹里面,安装方式如下,注意安装tensorrt的whl的时候,要根据你python环境来,我这里是3.7版本,所有就选的cp37

用哪个装哪个
想起来我还没有创建有python的虚拟环境,先建一个3.8的吧
conda create -n tensorrt python=3.8


切换cuda为11.1,根据windows下安装tensorrt(python调用)提供的代码,如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
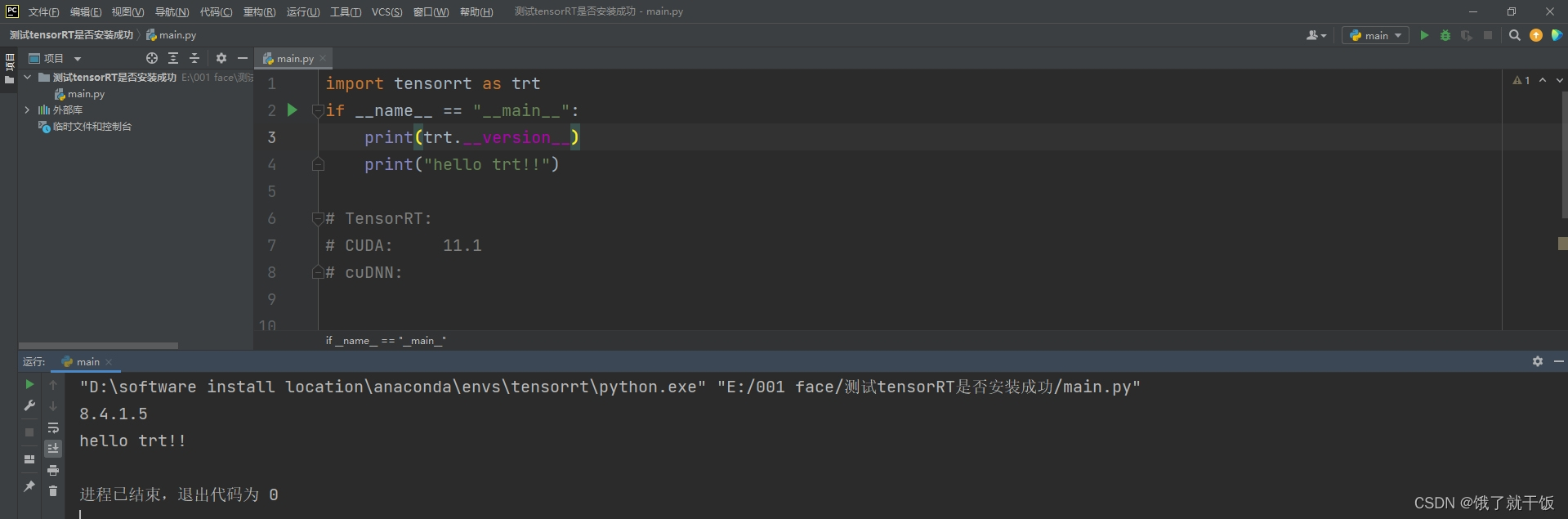
import tensorrt as trt
if __name__ == "__main__":
print(trt.__version__)
print("hello trt!!")
运行代码,报如下的错误:
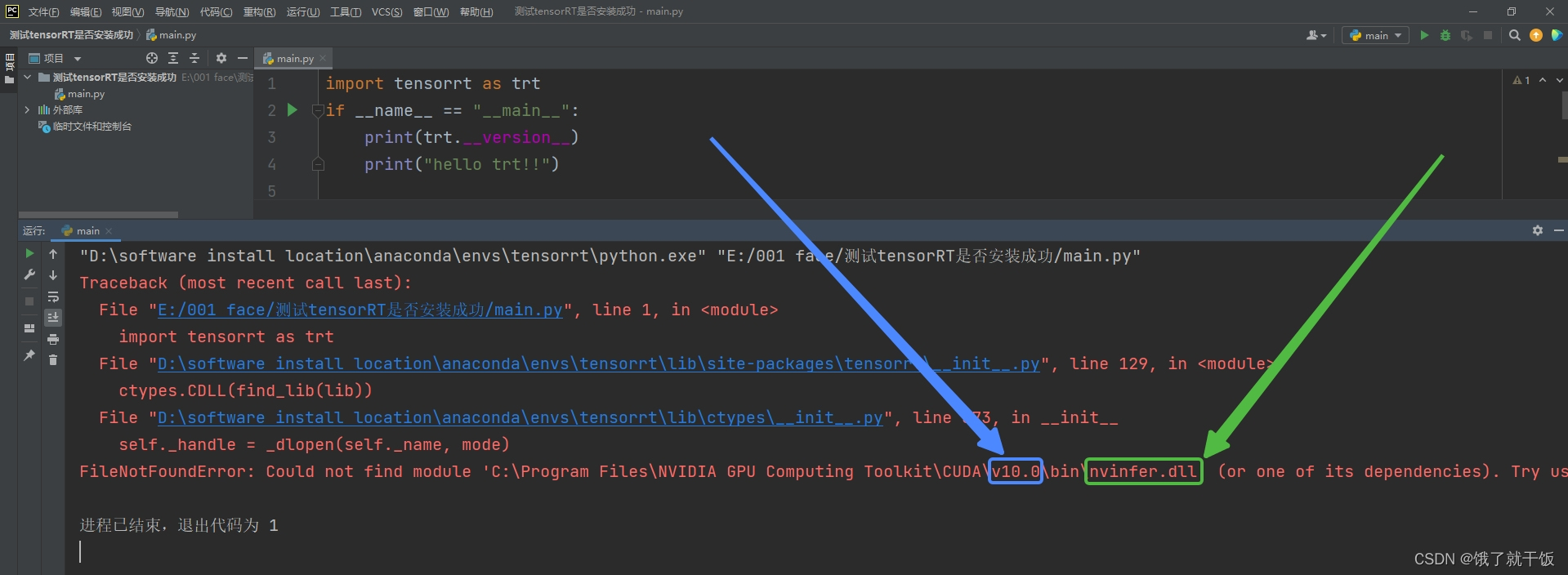
我对这个错误有两个疑惑:
1)如蓝色箭头所示,其中说的是CUDA\v10.0缺少一个文件,我分明已经将cuda11.1添加到环境变量中了(参考的是Windows10下多版本CUDA的安装与切换 超详细教程),且在终端中nvcc -V显示v11.1已经切换过来了
2)缺少的这些个dll文件我找不到从哪里搞。
根据一个博主的文章(windows下安装tensorrt(python调用))的图片中,如下:
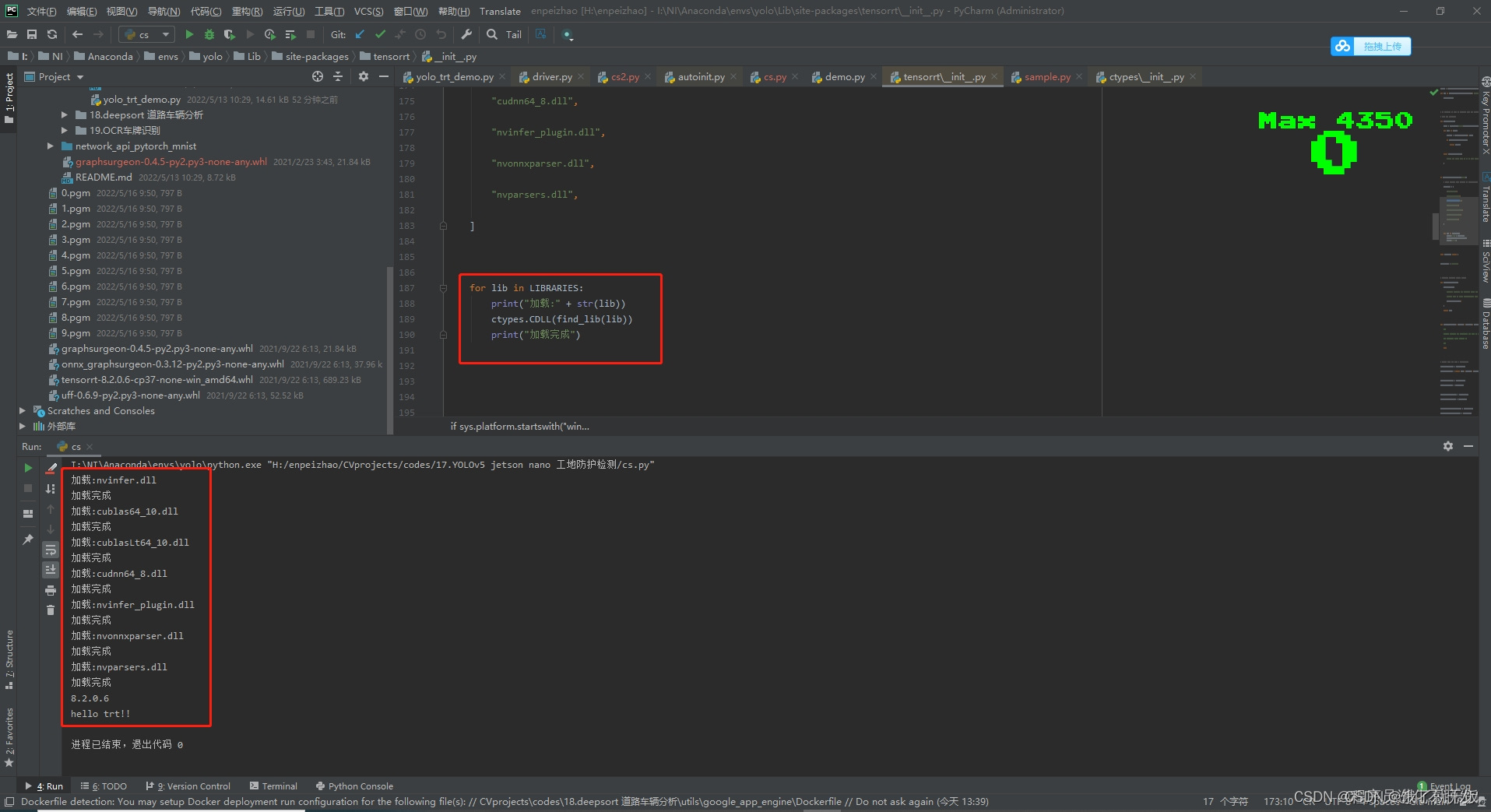
下面的红色方框中的第一个输出的文件名和我缺少的是一样的,都是nvinfer.dll,因此怀疑是不是在安装TensorRT的时候,是不是有的文件没放对地方。
针对我的两个疑惑,我的解决方案:忽略第一个出现的CUDA\v10.0这个文件的事情,直接从TensorRT文件中找到nvinfer.dll复制到v11.1\bin,运行一下试试。发现缺少其他文件。这个过程一共缺少以下3个文件:
和上面的例子类似,进行文件的复制粘贴,运行成功!
如下:
不知道为什么报错v10.0下没有这个文件,将文件放进v11.1中就解决了该问题。不管了,接下来写代码,看看TensorRT怎么用!
按这个流程:TensorRT部署流程
1、把你的模型导出成 ONNX 格式。
2、把 ONNX 格式模型输入给 TensorRT,并指定优化参数。
3、使用 TensorRT 优化得到 TensorRT Engine。
4、使用 TensorRT Engine 进行 inference。
我的模型已经转换为onnx格式了
接下来看怎么将ONNX 格式模型输入给 TensorRT,并指定优化参数。
"D:\software install location\anaconda\envs\tensorrt\python.exe" "E:/001 face/测试tensorRT是否安装成功/onnx2trt.py"
E:/001 face/测试tensorRT是否安装成功/onnx2trt.py:23: DeprecationWarning: Use set_memory_pool_limit instead.
config.max_workspace_size = 1 << 20
[10/20/2023-17:24:53] [TRT] [W] onnx2trt_utils.cpp:369: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
E:/001 face/测试tensorRT是否安装成功/onnx2trt.py:27: DeprecationWarning: Use build_serialized_network instead.
engine = builder.build_engine(network, config)
Traceback (most recent call last):
File "E:/001 face/测试tensorRT是否安装成功/onnx2trt.py", line 38, in <module>
onnx2trt(input_path, output_path)
File "E:/001 face/测试tensorRT是否安装成功/onnx2trt.py", line 28, in onnx2trt
printShape(engine)
File "E:/001 face/测试tensorRT是否安装成功/onnx2trt.py", line 10, in printShape
for i in range(engine.num_bindings):
AttributeError: 'NoneType' object has no attribute 'num_bindings'
[10/20/2023-17:24:53] [TRT] [E] 4: [network.cpp::nvinfer1::Network::validate::2965] Error Code 4: Internal Error (Network has dynamic or shape inputs, but no optimization profile has been defined.)
进程已结束,退出代码为 1
先来一段摘抄自网上的TensorRT介绍:
TensorRT是英伟达针对自家平台做的加速包,TensorRT主要做了这么两件事情,来提升模型的运行速度。
TensorRT支持INT8和FP16的计算。深度学习网络在训练时,通常使用 32 位或 16 位数据。TensorRT则在网络的推理时选用不这么高的精度,达到加速推断的目的。
TensorRT对于网络结构进行了重构,把一些能够合并的运算合并在了一起,针对GPU的特性做了优化。现在大多数深度学习框架是没有针对GPU做过性能优化的,而英伟达,GPU的生产者和搬运工,自然就推出了针对自己GPU的加速工具TensorRT。一个深度学习模型,在没有优化的情况下,比如一个卷积层、一个偏置层和一个reload层,这三层是需要调用三次cuDNN对应的API,但实际上这三层的实现完全是可以合并到一起的,TensorRT会对一些可以合并网络进行合并。我们通过一个典型的inception block来看一看这样的合并运算。
————————————————
版权声明:本文为CSDN博主「CaiDou_」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_36276587/article/details/113175314
根据文章【python】tensorrt8版本下的onnx转tensorrt engine代码:
# from :https://blog.csdn.net/weixin_42492254/article/details/125319112
import tensorrt as trt
import os
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
TRT_LOGGER = trt.Logger()
def get_engine(onnx_file_path, engine_file_path=""):
"""Attempts to load a serialized engine if available, otherwise builds a new TensorRT engine and saves it."""
def build_engine():
"""Takes an ONNX file and creates a TensorRT engine to run inference with"""
with trt.Builder(TRT_LOGGER) as builder, \
builder.create_network(EXPLICIT_BATCH) as network, \
builder.create_builder_config() as config, \
trt.OnnxParser(network, TRT_LOGGER) as parser, \
trt.Runtime(TRT_LOGGER) as runtime:
config.max_workspace_size = 1 << 32 # 4GB
builder.max_batch_size = 1
# Parse model file
if not os.path.exists(onnx_file_path):
print(
"ONNX file {} not found, please run yolov3_to_onnx.py first to generate it.".format(onnx_file_path)
)
exit(0)
print("Loading ONNX file from path {}...".format(onnx_file_path))
with open(onnx_file_path, "rb") as model:
print("Beginning ONNX file parsing")
print("-----")
if not parser.parse(model.read()):
print("ERROR: Failed to parse the ONNX file.")
for error in range(parser.num_errors):
# print("-----")
print(parser.get_error(error))
return None
# # The actual yolov3.onnx is generated with batch size 64. Reshape input to batch size 1
# network.get_input(0).shape = [1, 3, 608, 608]
print("Completed parsing of ONNX file")
print("Building an engine from file {}; this may take a while...".format(onnx_file_path))
plan = builder.build_serialized_network(network, config)
engine = runtime.deserialize_cuda_engine(plan)
print("Completed creating Engine")
with open(engine_file_path, "wb") as f:
f.write(plan)
return engine
if os.path.exists(engine_file_path):
# If a serialized engine exists, use it instead of building an engine.
print("Reading engine from file {}".format(engine_file_path))
with open(engine_file_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
else:
return build_engine()
def main():
"""Create a TensorRT engine for ONNX-based YOLOv3-608 and run inference."""
# Try to load a previously generated YOLOv3-608 network graph in ONNX format:
# onnx_file_path = "model.onnx"
onnx_file_path = "model.onnx"
engine_file_path = "model.trt"
get_engine(onnx_file_path, engine_file_path)
if __name__ == "__main__":
main()
报错:
"D:\software install location\anaconda\envs\tensorrt\python.exe" "E:/001 face/测试tensorRT是否安装成功/onnx转trt(第三种方法).py"
E:/001 face/测试tensorRT是否安装成功/onnx转trt(第三种方法).py:20: DeprecationWarning: Use set_memory_pool_limit instead.
config.max_workspace_size = 1 << 32 # 4GB
E:/001 face/测试tensorRT是否安装成功/onnx转trt(第三种方法).py:21: DeprecationWarning: Use network created with NetworkDefinitionCreationFlag::EXPLICIT_BATCH flag instead.
builder.max_batch_size = 1
Loading ONNX file from path model.onnx...
Beginning ONNX file parsing
-----
[10/22/2023-03:15:01] [TRT] [W] onnx2trt_utils.cpp:369: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
Completed parsing of ONNX file
Building an engine from file model.onnx; this may take a while...
[10/22/2023-03:15:01] [TRT] [E] 4: [network.cpp::nvinfer1::Network::validate::2965] Error Code 4: Internal Error (Network has dynamic or shape inputs, but no optimization profile has been defined.)
[10/22/2023-03:15:01] [TRT] [E] 2: [builder.cpp::nvinfer1::builder::Builder::buildSerializedNetwork::636] Error Code 2: Internal Error (Assertion engine != nullptr failed. )
Traceback (most recent call last):
File "E:/001 face/测试tensorRT是否安装成功/onnx转trt(第三种方法).py", line 72, in <module>
main()
File "E:/001 face/测试tensorRT是否安装成功/onnx转trt(第三种方法).py", line 68, in main
get_engine(onnx_file_path, engine_file_path)
File "E:/001 face/测试tensorRT是否安装成功/onnx转trt(第三种方法).py", line 57, in get_engine
return build_engine()
File "E:/001 face/测试tensorRT是否安装成功/onnx转trt(第三种方法).py", line 45, in build_engine
engine = runtime.deserialize_cuda_engine(plan)
TypeError: deserialize_cuda_engine(): incompatible function arguments. The following argument types are supported:
1. (self: tensorrt.tensorrt.Runtime, serialized_engine: buffer) -> tensorrt.tensorrt.ICudaEngine
Invoked with: <tensorrt.tensorrt.Runtime object at 0x000001AFCFC8ECB0>, None
进程已结束,退出代码为 1
根据文章:
把onnx模型转TensorRT模型的trt模型报错:Your ONNX model has been generated with INT64 weights. while TensorRT的方法,安装:
pip install onnx-simplifier
Successfully installed markdown-it-py-3.0.0 mdurl-0.1.2 onnx-simplifier-0.4.35 pygments-2.16.1 rich-13.6.0
运行
python -m onnxsim model.onnx model2.onnx
结果
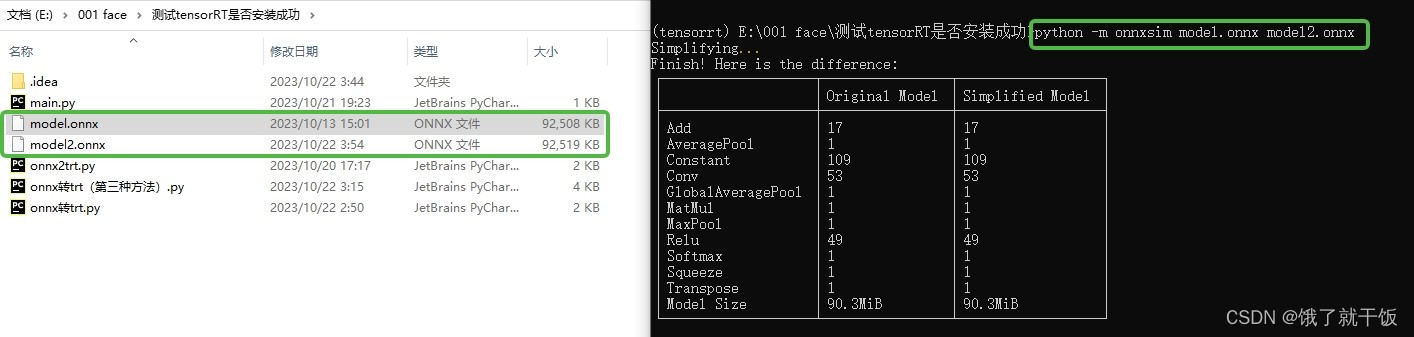
提示我cuDNN版本不符合,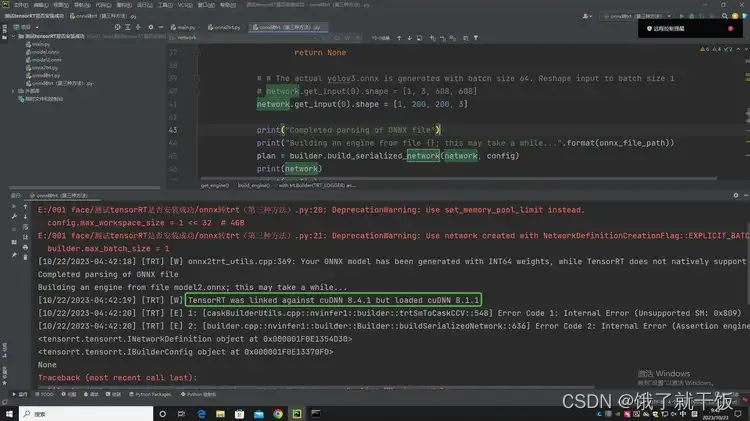
虽然在网上有的博客里说没有影响,但是我还是想更换版本,因此在https://developer.nvidia.com/rdp/cudnn-archive下载了Download cuDNN v8.4.1 (May 27th, 2022), for CUDA 11.xwindows版本,文件名:cudnn-windows-x86_64-8.4.1.50_cuda11.6-archive.zip,根据Windows10下多版本CUDA的安装与切换 超详细教程安装cuDNN,装完以后就不报错了
但是仍存在以下错误:
E:/001 face/测试tensorRT是否安装成功/onnx转trt(第三种方法).py:20: DeprecationWarning: Use set_memory_pool_limit instead.
config.max_workspace_size = 1 << 32 # 4GB
E:/001 face/测试tensorRT是否安装成功/onnx转trt(第三种方法).py:21: DeprecationWarning: Use network created with NetworkDefinitionCreationFlag::EXPLICIT_BATCH flag instead.
builder.max_batch_size = 1
[10/23/2023-09:53:06] [TRT] [W] onnx2trt_utils.cpp:369: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
Completed parsing of ONNX file
Building an engine from file model2.onnx; this may take a while...
进程已结束,退出代码为 -1073740791 (0xC0000409)
更换策略:使用trtexec.exe在命令行中进行转换,参考:onnx转trt方法
cd C:\Users\jiao\Desktop\推理加速环境准备\TensorRT-8.4.1.5.Windows10.x86_64.cuda-11.6.cudnn8.4\TensorRT-8.4.1.5\bin
trtexec.exe --onnx=model1023.onnx --saveEngine=moedls.egine --fp16
--onnx的参数不太懂,因此我把model1023.onnx放在了和trtexec.exe同一位置下
报错:
[10/23/2023-15:26:58] [W] [TRT] onnx2trt_utils.cpp:369: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
[10/23/2023-15:26:58] [I] Finish parsing network model
[10/23/2023-15:26:58] [W] Dynamic dimensions required for input: Input:0, but no shapes were provided. Automatically overriding shape to: 1x200x200x3
[10/23/2023-15:26:59] [I] [TRT] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +730, GPU +266, now: CPU 22634, GPU 3398 (MiB)
[10/23/2023-15:26:59] [I] [TRT] [MemUsageChange] Init cuDNN: CPU +138, GPU +58, now: CPU 22772, GPU 3456 (MiB)
[10/23/2023-15:26:59] [I] [TRT] Local timing cache in use. Profiling results in this builder pass will not be stored.
Could not locate zlibwapi.dll. Please make sure it is in your library path!
搜索:Could not locate zlibwapi.dll. Please make sure it is in your library path!
根据:【Bug】Could not locate zlibwapi.dll. Please make sure it is in your library path!,下载zlib123dllx64.zip,将zlibwapi.dll放在C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\bin下面,继续运行
trtexec.exe --onnx=model1023.onnx --saveEngine=moedls.egine --fp16
报错:
[10/23/2023-15:32:46] [W] [TRT] onnx2trt_utils.cpp:369: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
[10/23/2023-15:32:46] [I] Finish parsing network model
[10/23/2023-15:32:46] [W] Dynamic dimensions required for input: Input:0, but no shapes were provided. Automatically overriding shape to: 1x200x200x3
[10/23/2023-15:32:47] [I] [TRT] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +717, GPU +266, now: CPU 22965, GPU 3398 (MiB)
[10/23/2023-15:32:47] [I] [TRT] [MemUsageChange] Init cuDNN: CPU +145, GPU +58, now: CPU 23110, GPU 3456 (MiB)
[10/23/2023-15:32:47] [I] [TRT] Local timing cache in use. Profiling results in this builder pass will not be stored.
[10/23/2023-15:32:53] [E] Error[1]: [caskBuilderUtils.cpp::nvinfer1::builder::trtSmToCaskCCV::548] Error Code 1: Internal Error (Unsupported SM: 0x809)
[10/23/2023-15:32:53] [E] Error[2]: [builder.cpp::nvinfer1::builder::Builder::buildSerializedNetwork::636] Error Code 2: Internal Error (Assertion engine != nullptr failed. )
[10/23/2023-15:32:53] [E] Engine could not be created from network
[10/23/2023-15:32:53] [E] Building engine failed
[10/23/2023-15:32:53] [E] Failed to create engine from model or file.
[10/23/2023-15:32:53] [E] Engine set up failed
&&&& FAILED TensorRT.trtexec [TensorRT v8401] # trtexec.exe --onnx=model1023.onnx --saveEngine=moedls.egine --fp16
虽然解决了,但是据【Bug】Could not locate zlibwapi.dll. Please make sure it is in your library path!所说有些东西还需要放置。
将 zlibwapi.lib 文件放到 path/to/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.1/lib 下
为保险起见:
将 zlibwapi.lib 文件放到了 path/to/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.6/lib/x64 下
参考:【Error】Could not locate zlibwapi.dll. Please make sure it is in your library path!
继续运行测试一下,报错:
[10/23/2023-15:54:16] [W] [TRT] onnx2trt_utils.cpp:369: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
[10/23/2023-15:54:16] [I] Finish parsing network model
[10/23/2023-15:54:16] [W] Dynamic dimensions required for input: Input:0, but no shapes were provided. Automatically overriding shape to: 1x200x200x3
[10/23/2023-15:54:16] [I] [TRT] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +733, GPU +266, now: CPU 21473, GPU 3398 (MiB)
[10/23/2023-15:54:16] [I] [TRT] [MemUsageChange] Init cuDNN: CPU +124, GPU +58, now: CPU 21597, GPU 3456 (MiB)
[10/23/2023-15:54:16] [I] [TRT] Local timing cache in use. Profiling results in this builder pass will not be stored.
[10/23/2023-15:54:22] [E] Error[1]: [caskBuilderUtils.cpp::nvinfer1::builder::trtSmToCaskCCV::548] Error Code 1: Internal Error (Unsupported SM: 0x809)
[10/23/2023-15:54:22] [E] Error[2]: [builder.cpp::nvinfer1::builder::Builder::buildSerializedNetwork::636] Error Code 2: Internal Error (Assertion engine != nullptr failed. )
[10/23/2023-15:54:22] [E] Engine could not be created from network
[10/23/2023-15:54:22] [E] Building engine failed
[10/23/2023-15:54:22] [E] Failed to create engine from model or file.
[10/23/2023-15:54:22] [E] Engine set up failed
&&&& FAILED TensorRT.trtexec [TensorRT v8401] # trtexec.exe --onnx=model1023.onnx --saveEngine=moedls.egine --fp16
报错依然如此,说明上面两个文件的移动没用!
搜索: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
根据:onnx模型转TensorRT模型时出错说的使用onnx-simplifier来简化模型
命令:
python -m onnxsim model1023.onnx model1023s.onnx
转换结果:
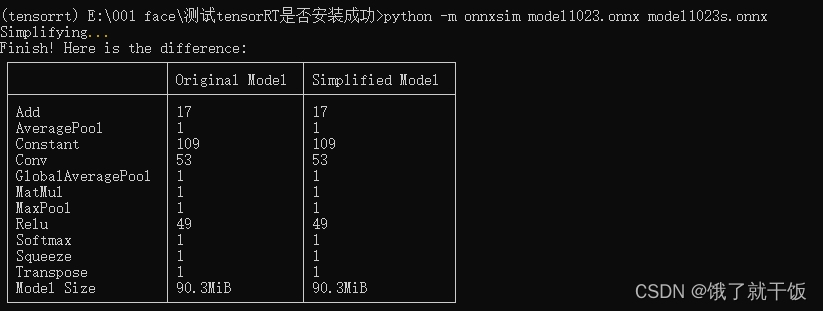
解决因为模型输入名称不对问题
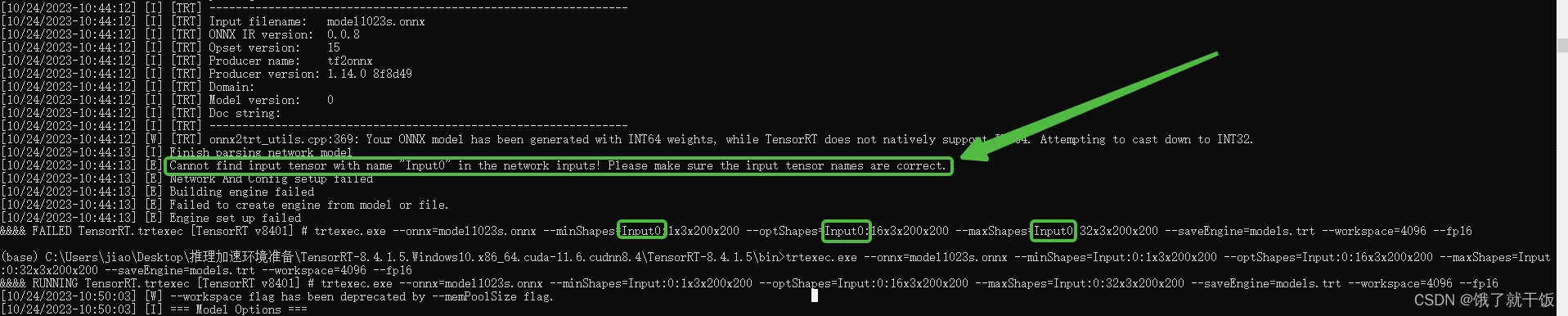
原先写的输入名称为Input0,报错:Cannot find input tensor with name "Input0" in the network inputs! Please make sure the input tensor names are correct.,根据:获取 onnx 模型的输入输出信息 Python 脚本,运行代码:
from pprint import pprint
import onnxruntime
onnx_path = "model1023s.onnx"
# onnx_path = "custompool/output.onnx"
provider = "CPUExecutionProvider"
onnx_session = onnxruntime.InferenceSession(onnx_path, providers=[provider])
print("----------------- 输入部分 -----------------")
input_tensors = onnx_session.get_inputs() # 该 API 会返回列表
for input_tensor in input_tensors: # 因为可能有多个输入,所以为列表
input_info = {
"name" : input_tensor.name,
"type" : input_tensor.type,
"shape": input_tensor.shape,
}
pprint(input_info)
print("----------------- 输出部分 -----------------")
output_tensors = onnx_session.get_outputs() # 该 API 会返回列表
for output_tensor in output_tensors: # 因为可能有多个输出,所以为列表
output_info = {
"name" : output_tensor.name,
"type" : output_tensor.type,
"shape": output_tensor.shape,
}
pprint(output_info)
输出:
"D:\software install location\anaconda\envs\tensorrt\python.exe" "E:/001 face/测试tensorRT是否安装成功/2 查看onnx模型文件的输入名称.py"
----------------- 输入部分 -----------------
{'name': 'Input:0', 'shape': ['unk__616', 200, 200, 3], 'type': 'tensor(float)'}
----------------- 输出部分 -----------------
{'name': 'Identity:0', 'shape': ['unk__617', 93], 'type': 'tensor(float)'}
进程已结束,退出代码为 0
因此确定输入名称为Input:0
trtexec.exe --onnx=model1023s.onnx --minShapes=Input:0:1x3x200x200 --optShapes=Input:0:16x3x200x200 --maxShapes=Input:0:32x3x200x200 --saveEngine=models.trt --workspace=4096 --fp16
运行后,报错Cannot find input tensor with name "Input0" in the network inputs! Please make sure the input tensor names are correct.就消失了
之前出的错误仍然没有解决掉:
--workspace flag has been deprecated by --memPoolSize flag.
[10/24/2023-10:50:04] [E] Error[4]: [network.cpp::nvinfer1::Network::validate::3008] Error Code 4: Internal Error (Input:0: for dimension number 1 in profile 0 does not match network definition (got min=3, opt=3, max=3), expected min=opt=max=200).)
[10/24/2023-10:50:04] [E] Error[2]: [builder.cpp::nvinfer1::builder::Builder::buildSerializedNetwork::636] Error Code 2: Internal Error (Assertion engine != nullptr failed. )
[10/24/2023-10:50:04] [E] Engine could not be created from network
[10/24/2023-10:50:04] [E] Building engine failed
[10/24/2023-10:50:04] [E] Failed to create engine from model or file.
[10/24/2023-10:50:04] [E] Engine set up failed
&&&& FAILED TensorRT.trtexec [TensorRT v8401] # trtexec.exe --onnx=model1023s.onnx --minShapes=Input:0:1x3x200x200 --optShapes=Input:0:16x3x200x200 --maxShapes=Input:0:32x3x200x200 --saveEngine=models.trt --workspace=4096 --fp16
针对这个错误:--workspace flag has been deprecated by --memPoolSize flag.我把--workspace=4096取消,之后就不报这个错误了,继续运行下面这句话
trtexec.exe --onnx=model1023s.onnx --minShapes=Input:0:1x3x200x200 --optShapes=Input:0:1x3x200x200 --maxShapes=Input:0:32x3x200x200 --saveEngine=models.trt --fp16
报错:
[10/24/2023-14:13:23] [E] Error[4]: [network.cpp::nvinfer1::Network::validate::3008] Error Code 4: Internal Error (Input:0: for dimension number 1 in profile 0 does not match network definition (got min=3, opt=3, max=3), expected min=opt=max=200).)
[10/24/2023-14:13:23] [E] Error[2]: [builder.cpp::nvinfer1::builder::Builder::buildSerializedNetwork::636] Error Code 2: Internal Error (Assertion engine != nullptr failed. )
[10/24/2023-14:13:23] [E] Engine could not be created from network
[10/24/2023-14:13:23] [E] Building engine failed
[10/24/2023-14:13:23] [E] Failed to create engine from model or file.
[10/24/2023-14:13:23] [E] Engine set up failed
&&&& FAILED TensorRT.trtexec [TensorRT v8401] # trtexec.exe --onnx=model1023s.onnx --minShapes=Input:0:1x3x200x200 --optShapes=Input:0:1x3x200x200 --maxShapes=Input:0:32x3x200x200 --saveEngine=models.trt --fp16
修改
trtexec.exe --onnx=model1023s.onnx --minShapes=Input:0:1x3x200x200 --optShapes=Input:0:1x3x200x200 --maxShapes=Input:0:32x3x200x200 --saveEngine=models.trt --fp16
报错:
[10/24/2023-14:21:35] [W] [TRT] onnx2trt_utils.cpp:369: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
[10/24/2023-14:21:35] [I] Finish parsing network model
[10/24/2023-14:21:35] [I] [TRT] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +730, GPU +266, now: CPU 28526, GPU 3398 (MiB)
[10/24/2023-14:21:35] [I] [TRT] [MemUsageChange] Init cuDNN: CPU +126, GPU +58, now: CPU 28652, GPU 3456 (MiB)
[10/24/2023-14:21:35] [I] [TRT] Local timing cache in use. Profiling results in this builder pass will not be stored.
[10/24/2023-14:21:41] [E] Error[1]: [caskBuilderUtils.cpp::nvinfer1::builder::trtSmToCaskCCV::548] Error Code 1: Internal Error (Unsupported SM: 0x809)
[10/24/2023-14:21:41] [E] Error[2]: [builder.cpp::nvinfer1::builder::Builder::buildSerializedNetwork::636] Error Code 2: Internal Error (Assertion engine != nullptr failed. )
[10/24/2023-14:21:41] [E] Engine could not be created from network
[10/24/2023-14:21:41] [E] Building engine failed
[10/24/2023-14:21:41] [E] Failed to create engine from model or file.
[10/24/2023-14:21:41] [E] Engine set up failed
&&&& FAILED TensorRT.trtexec [TensorRT v8401] # trtexec.exe --onnx=model1023s.onnx --minShapes=Input:0:1x200x200x3 --optShapes=Input:0:16x200x200x3 --maxShapes=Input:0:32x200x200x3 --saveEngine=models.trt --fp16
这个报错原因网友说PointPillars-TensorRT部署:还是因为CUDA、cuDNN、TensorRT这些版本不能匹配
统计现有环境:
CUDA:11.1
cuDNN:8.4.1
TensorRT:8.4.15
(tensorrt) C:\Users\jiao\Desktop\推理加速环境准备\TensorRT-8.4.1.5.Windows10.x86_64.cuda-11.6.cudnn8.4\TensorRT-8.4.1.5\bin>conda list
# packages in environment at D:\software install location\anaconda\envs\tensorrt:
#
# Name Version Build Channel
appdirs 1.4.4 pypi_0 pypi
bzip2 1.0.8 h8ffe710_4 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
ca-certificates 2023.7.22 h56e8100_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
coloredlogs 15.0.1 pypi_0 pypi
common 0.1.2 pypi_0 pypi
flatbuffers 23.5.26 pypi_0 pypi
graphsurgeon 0.4.6 pypi_0 pypi
humanfriendly 10.0 pypi_0 pypi
libffi 3.4.2 h8ffe710_5 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
libsqlite 3.43.2 hcfcfb64_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
libzlib 1.2.13 hcfcfb64_5 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
mako 1.2.4 pypi_0 pypi
markdown-it-py 3.0.0 pypi_0 pypi
markupsafe 2.1.3 pypi_0 pypi
mdurl 0.1.2 pypi_0 pypi
mpmath 1.3.0 pypi_0 pypi
numpy 1.24.4 pypi_0 pypi
onnx 1.14.1 pypi_0 pypi
onnx-graphsurgeon 0.3.12 pypi_0 pypi
onnx-simplifier 0.4.35 pypi_0 pypi
onnxruntime 1.16.1 pypi_0 pypi
openssl 3.1.3 hcfcfb64_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
packaging 23.2 pypi_0 pypi
pip 23.3 pyhd8ed1ab_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
platformdirs 3.11.0 pypi_0 pypi
protobuf 4.24.4 pypi_0 pypi
pycuda 2022.2.2 pypi_0 pypi
pygments 2.16.1 pypi_0 pypi
pyreadline3 3.4.1 pypi_0 pypi
python 3.8.18 h4de0772_0_cpython https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
pytools 2023.1.1 pypi_0 pypi
rich 13.6.0 pypi_0 pypi
setuptools 68.2.2 pyhd8ed1ab_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
shapely 1.8.2 pypi_0 pypi
sympy 1.12 pypi_0 pypi
tensorrt 8.4.1.5 pypi_0 pypi
tk 8.6.13 hcfcfb64_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
typing-extensions 4.8.0 pypi_0 pypi
ucrt 10.0.22621.0 h57928b3_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
uff 0.6.9 pypi_0 pypi
vc 14.3 h64f974e_17 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
vc14_runtime 14.36.32532 hdcecf7f_17 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
vs2015_runtime 14.36.32532 h05e6639_17 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
wheel 0.41.2 pyhd8ed1ab_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
xz 5.2.6 h8d14728_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
(tensorrt) C:\Users\jiao\Desktop\推理加速环境准备\TensorRT-8.4.1.5.Windows10.x86_64.cuda-11.6.cudnn8.4\TensorRT-8.4.1.5\bin>pip list
Package Version
----------------- --------
appdirs 1.4.4
coloredlogs 15.0.1
common 0.1.2
flatbuffers 23.5.26
graphsurgeon 0.4.6
humanfriendly 10.0
Mako 1.2.4
markdown-it-py 3.0.0
MarkupSafe 2.1.3
mdurl 0.1.2
mpmath 1.3.0
numpy 1.24.4
onnx 1.14.1
onnx-graphsurgeon 0.3.12
onnx-simplifier 0.4.35
onnxruntime 1.16.1
packaging 23.2
pip 23.3
platformdirs 3.11.0
protobuf 4.24.4
pycuda 2022.2.2
Pygments 2.16.1
pyreadline3 3.4.1
pytools 2023.1.1
rich 13.6.0
setuptools 68.2.2
Shapely 1.8.2
sympy 1.12
tensorrt 8.4.1.5
typing_extensions 4.8.0
uff 0.6.9
wheel 0.41.2
再看这个帖子中的一个老外的回答tensorrt报错 [F] [TRT] Assertion failed: Unsupported SM.,里面提到GPU需要更高版本的cuda。另外根据一篇博客中说RTX4080比较适用cuda12.1版本
因此下载了以下版本。