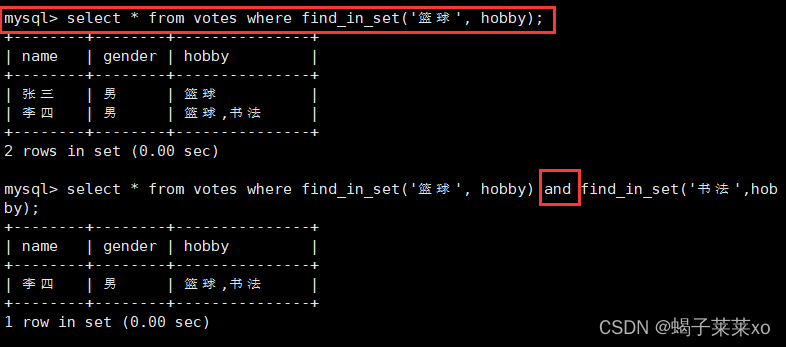
mysql索引为啥使用B+tree?
索引数据结构
二叉树
红黑树
Hash表
B-Tree
二叉树(Binary Tree)
每个节点最多只有两个子节点, 左边的子节点都比当前节点小,右边的子节点都比当前节点大。
一棵深度为k,且有2^k-1个结点的二叉树,称为满二叉树。
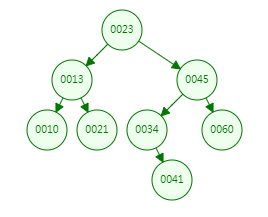
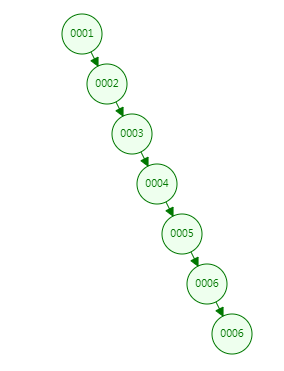
可能变成链表,查询效率低
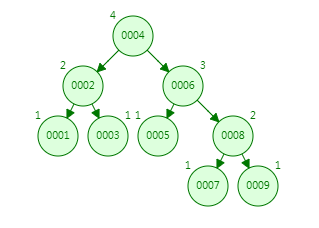
AVL树(平衡二叉树)
它是一种排序的二叉树。主要特征:左右子树的树高差绝对值不能超过1
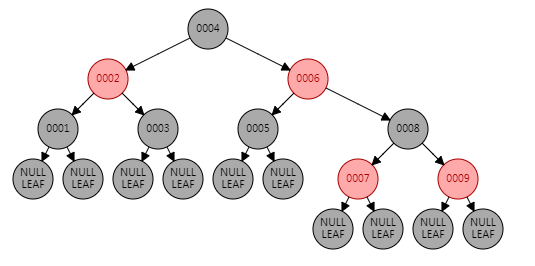
R-B Tree(Red/Black Tree)红黑树
本质上也是一种二叉树。
特性:
1)每个结点要么是红的,要么是黑的。
2)根结点是黑的。
3)每个叶结点(叶结点即指树尾端NIL指针或NULL结点)是黑的。
4)如果一个结点是红的,那么它的俩个儿子都是黑的。
5)对于任一结点而言,其到叶结点树尾端NIL指针的每一条路径都包含相同数目的黑结点。
* 新添加节点,均为红色。
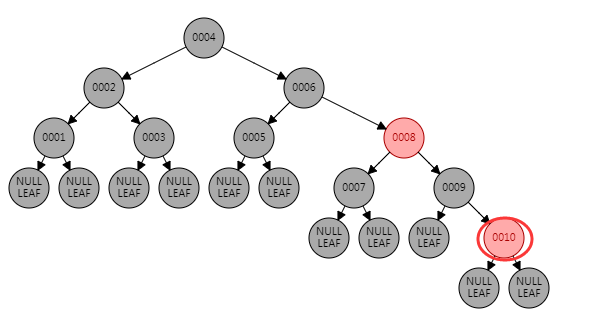
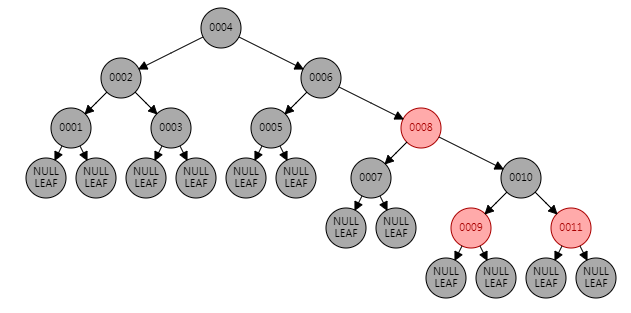
数据量大的情况下,树的高度很高,查询效率低。
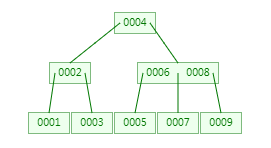
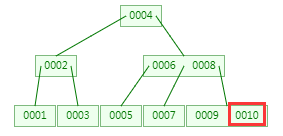
B-Tree(B树)
是一种自平衡的树,能够保持数据有序。与二叉树的区别,可以有多个子节点,每个节点可以存储多个值。
m 阶(根结点中关键字的个数为1~m-1)的B树具有特性:
1)每个节点最多有 m 个子节点,叶节点具有相同的深度,叶节点的指针为空
2)除根节点和叶子节点,其它每个节点至少有 [m/2] (向上取整的意思)个子节点
3)若根节点不是叶子节点,则其至少有2个子节点
4)所有NULL节点到根节点的高度都一样
5)除根节点外,其它节点都包含 n 个key,其中 [m/2] -1 <= n <= m-1
6)节点中的数据索引从左到右递增排列
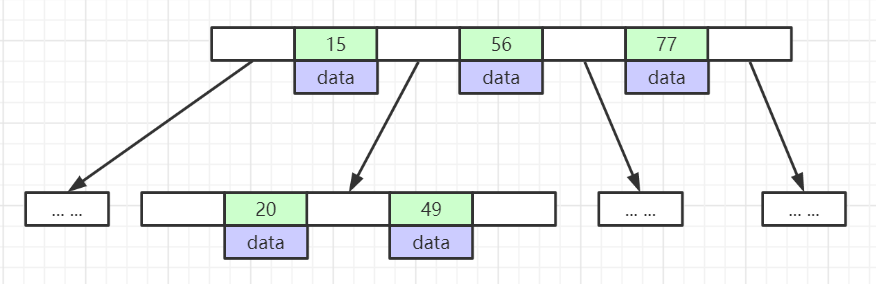
每个节点由三部分组成:key,指针,数据data;
key和指针互相间隔,节点两端是指针。
每个叶子节点最少包含一个key和两个指针,最多包含2d-1个key和2d个指针,叶节点的指针均为null(d 大于1的正整数,表示B树的度)
比如每个节点最大深度=3。(3阶B树)
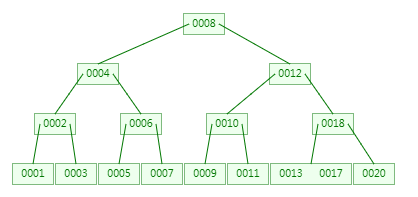
B+Tree(B+树)
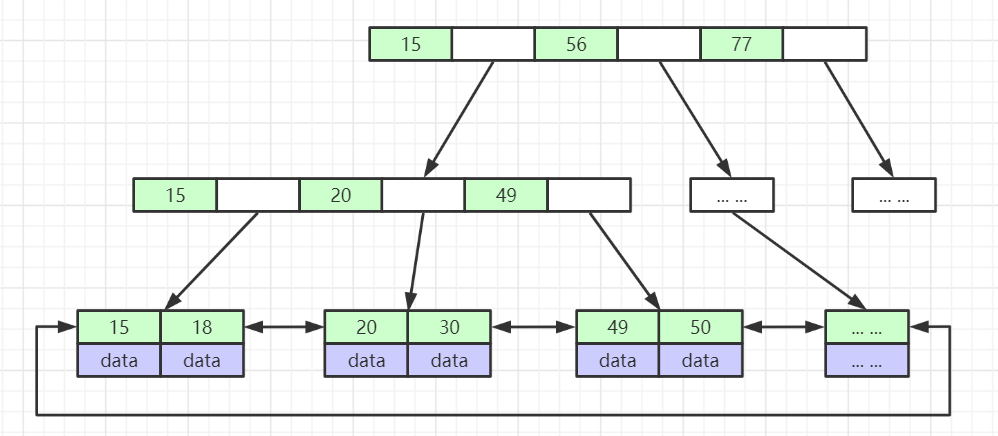
是B-Tree的一种变种树。自然也会满足B树相关特性。主要区别:B+树的叶子会包含所有的节点数据,并产生链表结构。
特征:
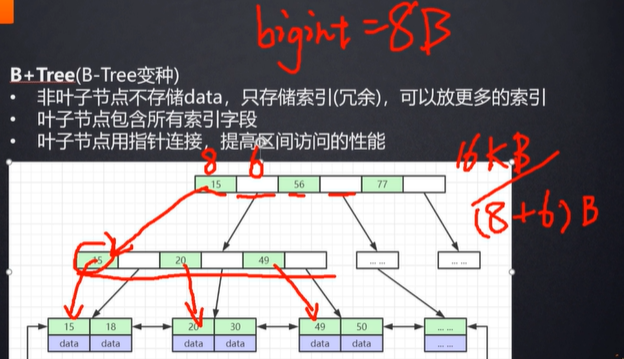
1、非叶子节点不存储数据,只存储索引(冗余),可以放更多的索引
2、所有数据都存储在叶子节点当中,叶子节点包含所有索引字段
3、每个叶子节点都存有相邻叶子节点的指针,提高区间访问的性能
4、叶子节点按照本身关键字从小到大排序。
每个非叶子节点由二部分组成:key,指针。
叶子节点没有指针,只有key、数据data。
指针可能数量不一致,但是每个节点的域和上限是一致的
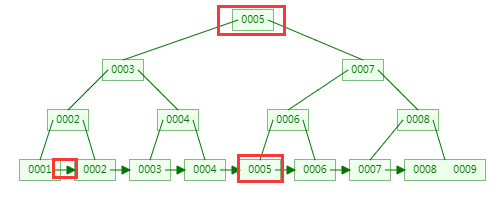
B树索引示例图
B+树索引示例图
mysql为什么使用了b+tree而不是b-tree
- 由于非叶子节点不存储 data,所以一个存储页可以存储更多的非叶子节点,也就是说使用 b+树单次磁盘 I/O拿到的同大小存储页中包含的信息量相比 b-树更大,所以减少了同样数据量下每次查询的io次数。
- MySQL 是关系型数据库,经常会按照区间来访问某个索引列,B+树的叶子节点间按顺序建立了链指针,加强了区间访问性,所以 B+树对索引列上的区间范围查询很友好。而 B 树每个节点的 key 和 data 在一起,无法进行区间查找。
查看mysql文件页大小(默认是16K)
SHOW GLOBAL STATUS like 'Innodb_page_size’;
假设主键是bigint类型,一个bigint占用8B,一个指针占用6B,一页可以存16kb/14B,大概是 1170个,一个非叶子节点也可以存1170个,叶子节点存储数据,假设数据是1k,一个叶子节点可以存储16个,所以3阶b+tree可以存储 1170 X 1170 X 16 = 21902400 ,2千多万
对于B-tree,因为叶子节点也存储数据了,假设一行数据是1k,存储2千万数据,需要 16的n次方 ,n肯定大于3